Command Palette
Search for a command to run...
LLMs改进LLMs:用于测试时缩放的Agent发现
LLMs改进LLMs:用于测试时缩放的Agent发现
摘要
测试时扩展(Test-time scaling, TTS)已成为通过在推理过程中分配额外计算资源以提升大语言模型性能的有效方法。然而,现有的 TTS 策略大多依赖人工设计:研究人员依靠直觉手动设计推理模式并调整启发式规则,导致大量的计算分配空间未被探索。为此,我们提出了一种由环境驱动的框架——AutoTTS,旨在改变研究人员的设计对象:从设计单一的 TTS 启发式规则,转变为设计能够自动发现 TTS 策略的环境。AutoTTS 的关键在于环境构建:发现环境必须使控制空间变得易于处理,并为 TTS 搜索提供低成本且高频的反馈。作为具体实例,我们将宽度-深度(width--depth)TTS formulate 为基于预收集的推理轨迹和探测信号的控制合成问题。在此设定中,控制器(controller)决定何时进行分支、继续、探测、剪枝或终止,并且可以在无需重复调用大语言模型(LLM)的情况下以低成本进行评估。此外,我们引入了 beta 参数化以使搜索过程易于处理,并采用细粒度的执行轨迹反馈,通过帮助 agent 诊断 TTS 程序失败的原因来提高发现效率。在数学推理基准测试上的实验表明,所发现的策略在整体准确率与成本的权衡上优于强大的手工设计基线模型。这些发现的策略能够泛化到未见过的基准测试和模型规模,且整个发现过程的成本仅为 39.9 美元和 160 分钟。我们的数据和代码将在 https://github.com/zhengkid/AutoTTS 开源。
一句话总结
作者提出了 AutoTTS,这是一种环境驱动框架,通过将宽度-深度扩展建模为基于预收集推理轨迹和探针信号的控制器综合问题,利用 beta 参数化和细粒度执行轨迹反馈,在无需重复调用 LLM 的情况下实现可处理的搜索与低成本评估,从而自动发现测试时扩展策略。
核心贡献
- 本文引入 AutoTTS,这是一种环境驱动框架,将测试时扩展策略的设计从手动启发式调优转变为在结构化控制空间上的自动控制器综合。
- 该方法基于预收集的推理轨迹和探针信号构建重放马尔可夫决策过程,从而在无需重复调用模型的情况下实现低成本的控制器评估。Beta 参数化和细粒度执行轨迹反馈进一步简化了搜索流程,通过确保可控性并支持针对性故障诊断来优化搜索过程。
- 实证评估表明,自动发现的控制器能够在留集基准测试和多种模型规模上实现泛化。这些结果证实,环境驱动的发现机制为手工设计的推理策略提供了一种计算高效的替代方案。
引言
测试时扩展通过推理期间动态分配额外计算资源来提升大语言模型性能,因此高效的资源分配对于平衡准确率与运营成本至关重要。现有方法依赖手动启发式规则进行分支、剪枝和终止推理轨迹,迫使研究人员依靠直觉调整阈值,导致大量计算分配空间未被探索。作者利用一种名为 AutoTTS 的环境驱动范式来自动化这一发现过程。通过将策略设计建模为基于收集到的推理轨迹的控制器综合,该方法使 agent 能够在无需重复调用 LLM 的情况下评估并优化分配策略。该框架引入 beta 参数化以保持搜索的可处理性,并提供详细的执行轨迹反馈以协助 agent 诊断失败原因,最终发现计算成本仅为手动基线一小部分且性能更优的策略。
数据集
- 数据集构成与来源:提供的文本未描述数据集、数据来源或子集构成。
- 各子集关键细节:未包含子集大小、过滤规则或来源元数据。
- 论文如何使用数据:该片段实现的是控制流机制,而非训练或推理流水线。
- 处理细节:作者使用布尔值评估来验证所有分支均已结束或已被放弃,并在满足条件时中断执行循环。
方法
作者将测试时扩展(TTS)框架化为一个算法搜索问题,其目标是发现一种最优策略,以在多个推理分支间分配有限的推理预算。该策略(即控制器)动态管理分支的创建、扩展、探测、剪枝与聚合,在遵守计算约束的前提下最大化准确率。如图下所示,整体框架包含一个发现循环,该循环针对预收集的离线数据迭代评估候选控制器。该循环采用两阶段流程:离线重放环境支持在不调用基础大语言模型(LLM)的情况下对任意候选控制器进行快速且确定性的评估;反馈机制则提供详细的执行轨迹以指导发现 agent。该 agent 作为控制器设计者,通过分析先前提案的累积历史、性能表现及执行行为,提出改进的控制器实现方案。该过程在多轮迭代中持续进行,最终选出性能最优的控制器及其关联的超参数配置。
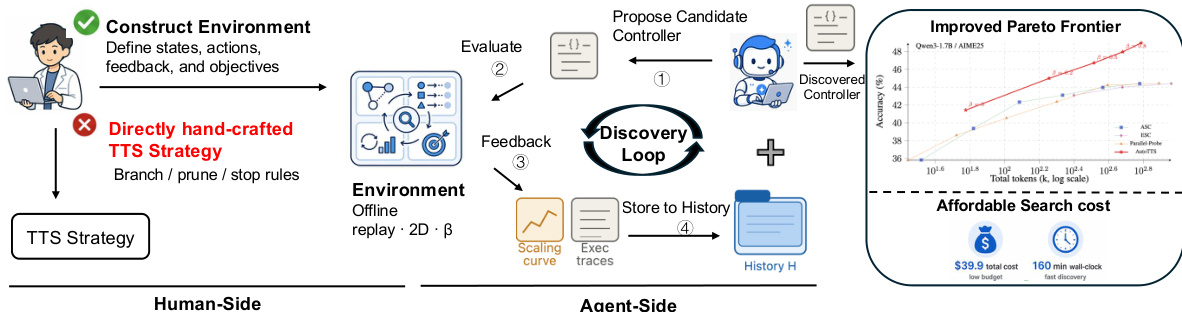
该方法的核心在于控制器的状态表示与动作空间。决策步骤 t 的状态 st 封装了针对特定问题 q 的推理过程完整历史。它包括已实例化的分支数量 mt、当前活跃分支集合 It、各分支的深度(以固定长度的 token 间隔衡量)ℓt,以及迄今为止已揭示的探针反馈集合 Ωt。控制器的动作由一组原子操作定义:BRANCH 用于创建新的推理路径,CONTINUE(i) 用于扩展活跃分支 i,PROBE(i) 用于读取分支 i 的中间答案,PRUNE(i) 用于移除分支,ANSWER 用于终止推理并生成最终答案。控制器的策略 π(⋅∣s,β) 将当前状态 s 与单一超参数 β 映射为这些合法动作上的概率分布。参数 β 充当高层调节旋钮,控制预算分配策略的整体激进程度。
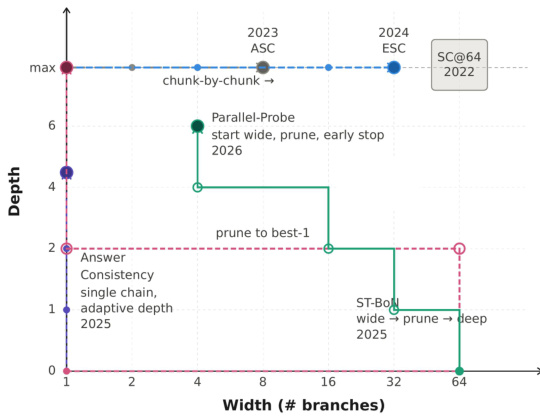
一项关键设计选择是使用单一超参数 β 控制所有内部决策阈值,这一概念称为 beta 参数化。这将搜索空间从高维简化为一维扫描,防止 agent 发现脆弱且过拟合的解决方案。控制器的内部超参数,如初始分支数量、剪枝耐心值与置信度阈值,均由 β 的平滑单调函数决定。这确保了随着 β 的增加,控制器会变得更加激进,将更多预算分配给探索与更深层次的推理,同时保持行为的一致性与可解释性。发现的控制器被称为置信度动量控制器(CMC),它利用该框架实现四项关键机制:采用置信度指数移动平均(EMA)的动量感知停止门控,以避免因瞬态尖峰而过早终止;耦合的宽深控制,将生成新分支的决策与置信度增长趋势相链接;感知对齐的深度分配,优先探测答案与当前共识一致的分支;以及保守的分支放弃策略,仅在分支出现持续偏离时才将其丢弃,确保始终保留至少两个活跃分支。
实验
实验在多个 Qwen3 模型上使用离线重放环境评估发现的推理控制器,并在分布内与留集的数学及非数学推理任务上,将其与成熟的手工设计扩展方法进行基准对比。主要结果与扩展分析验证了控制器能够将计算动态分配给高效分支,而非仅仅削减成本;泛化测试则确认了其在不同模型族与任务域上的鲁棒性。消融实验进一步验证了参数化预算控制与详细执行轨迹对于防止搜索过拟合至关重要,最终表明该自动化框架能够揭示复杂且协同的决策策略,在平衡推理效率与准确率方面持续优于手动设计。
作者在留集基准测试上将发现的控制器与手工基线进行对比,结果表明发现的控制器在多种模型与任务上实现了更优的准确率-成本权衡。结果显示,发现的控制器在训练集之外表现出良好的泛化能力,并在大多数设置中优于手工方法,同时在保持具有竞争力的准确率的同时显著降低了 token 使用量。在留集基准测试上,发现的控制器相比手工基线实现了更优的准确率-成本权衡。发现的控制器对不同模型及非数学任务具有良好的泛化能力,在降低 token 使用量的同时维持了具有竞争力的性能。在大多数设置中,发现的控制器优于手工方法,在保持准确率的同时显著降低了 token 消耗。
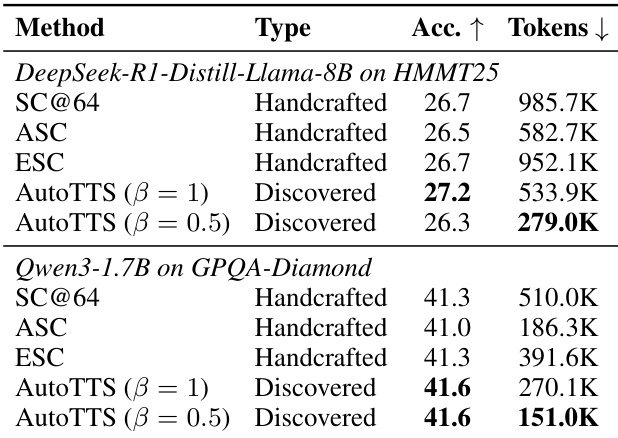
作者在多个基准测试上将发现的控制器与手工基线进行对比,结果表明该控制器在多种模型与数据集上实现了更优的准确率-成本权衡。结果显示,该控制器在留集环境中泛化良好,在大多数设置中优于基线,同时对模型与任务域的变化表现出鲁棒性。消融研究表明,关键设计选择(如 beta 参数化与执行轨迹)对于有效发现与泛化至关重要。在多个基准测试与模型上,发现的控制器相比手工基线实现了更优的准确率-成本权衡。该控制器在留集基准测试与不同模型族上泛化良好,表明其在训练设置之外具备鲁棒性。Beta 参数化与执行轨迹对于有效发现不可或缺,移除它们会导致性能显著下降。
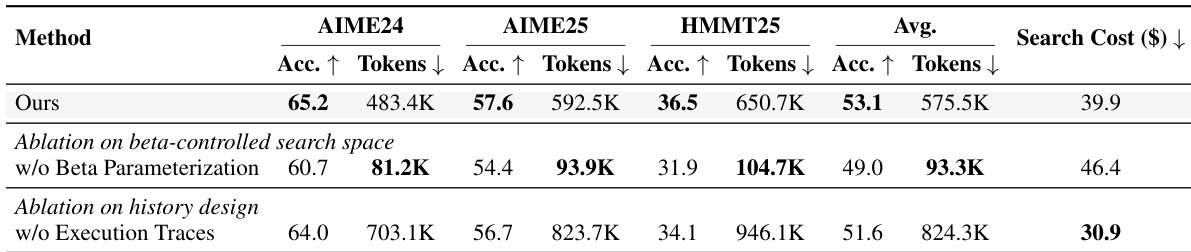
作者在多种模型与基准测试上将发现的控制器与手工基线进行对比,表明该控制器在大多数设置中实现了更优的准确率-成本权衡。该控制器在留集基准测试上泛化良好,在准确率与推理效率方面均优于手工方法,尤其在较小模型上表现更为突出。结果表明,发现的控制器能够有效平衡计算分配以提升性能,同时避免过度的 token 使用。在多种模型与基准测试上,发现的控制器相比手工基线实现了更优的准确率-成本权衡。该控制器在留集数据集上泛化良好,在大多数设置中优于基线,并在较大模型上保持强劲性能。发现的控制器在保持或提升准确率的同时显著降低了 token 消耗,表明计算分配高效。
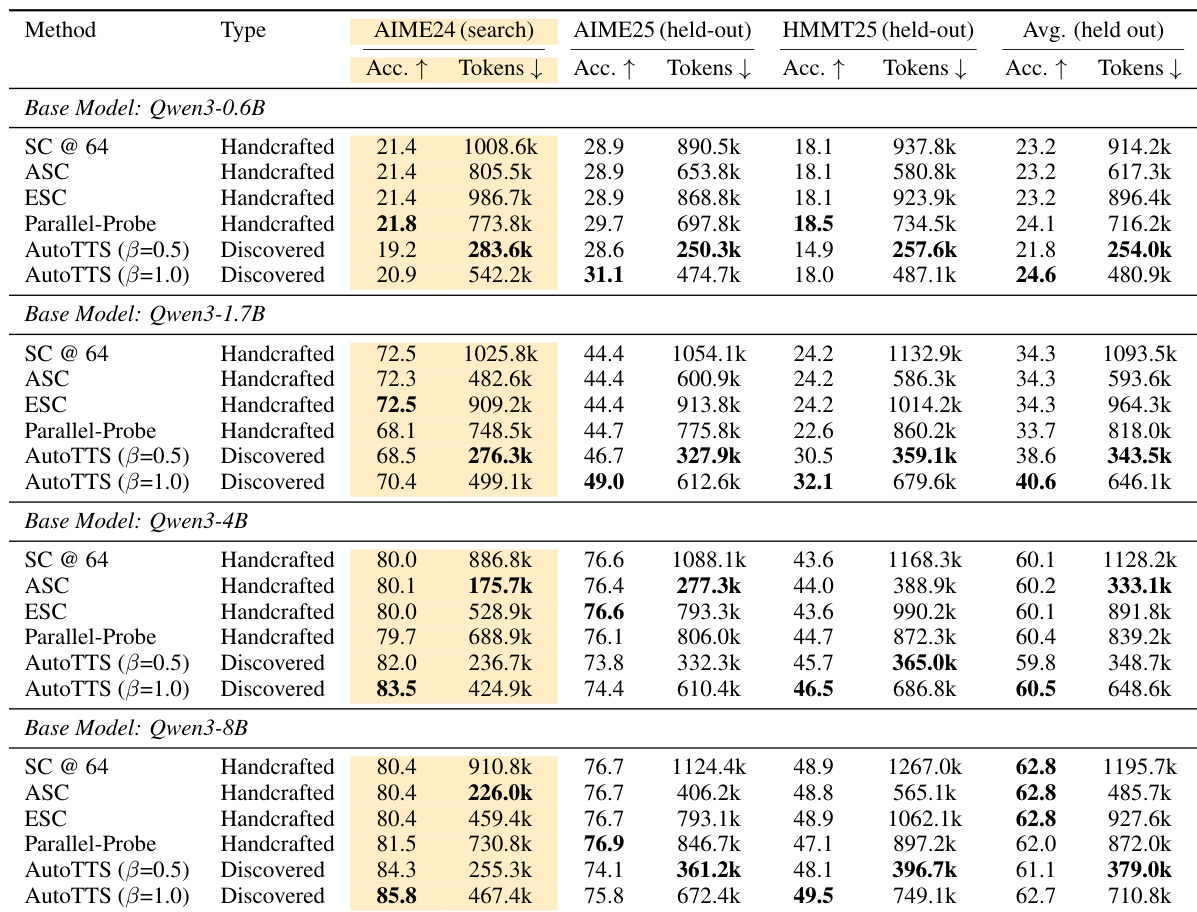
实验在多样化模型与留集基准测试上将发现的控制器与手工基线进行对比,以验证其泛化能力与计算效率。定性结果表明,发现的控制器通过在不同领域显著降低 token 消耗的同时保持或提升性能,始终实现更优的准确率-成本权衡。消融实验进一步证实,特定设计选择(尤其是 beta 参数化与执行轨迹)对于推动有效发现与鲁棒的跨任务适应至关重要。总体而言,研究结果确立了自动化控制器发现为传统手工方法提供了更高效、更具适应性的替代方案。