Command Palette
Search for a command to run...
Flow-OPD:流匹配模型上的策略蒸馏
Flow-OPD:流匹配模型上的策略蒸馏
摘要
现有的流匹配(Flow Matching, FM)文本到图像模型在多维任务对齐方面面临两个关键瓶颈:由标量奖励引起的奖励稀疏性,以及由联合优化异构目标引发的梯度干扰,这两者共同导致了相互竞争指标的“跷跷板效应”以及普遍的奖励黑客(reward hacking)现象。受大语言模型社区中在线策略蒸馏(On-Policy Distillation, OPD)成功的启发,我们提出了 Flow-OPD,这是首个将在线策略蒸馏集成到流匹配模型中的统一后训练框架。Flow-OPD 采用两阶段对齐策略:首先,通过单奖励 GRPO 微调培养领域特定的教师模型,使每个专家在独立状态下达到其性能极限;随后,通过基于流的冷启动(Flow-based Cold-Start)方案建立稳健的初始策略,并通过在线采样、任务路由标注以及密集轨迹级监督的三步编排,将异构专业知识无缝整合到单一学生模型中。此外,我们引入了流形锚点正则化(Manifold Anchor Regularization, MAR),利用任务无关的教师模型提供全数据监督,将生成分布锚定在高质量流形上,有效缓解了纯强化学习驱动的对齐中常见的审美退化问题。基于 Stable Diffusion 3.5 Medium 构建的 Flow-OPD 将 GenEval 分数从 63 提升至 92,OCR 准确率从 59 提升至 94,相较于原始 GRPO 方案整体提升了约 10 分,同时保持了图像保真度和人类偏好对齐,并展现出涌现式的“超越教师”(teacher-surpassing)效应。这些结果确立了 Flow-OPD 作为一种可扩展的对齐范式,用于构建通用型文本到图像模型。
一句话总结
为缓解多任务文生图任务中的奖励稀疏与梯度干扰问题,作者提出了 Flow-OPD。这是一种统一的训练后框架,通过两阶段对齐策略将在线策略蒸馏(on-policy distillation)集成至 Flow Matching 模型中:该策略首先通过单奖励 GRPO 微调领域专用教师模型,随后利用任务路由标注与密集轨迹级监督整合异构专业知识,并在多目标优化过程中采用流形锚点正则化(Manifold Anchor Regularization)以维持美学质量。
核心贡献
- 本文提出了 Flow-OPD,这是一种统一的训练后框架,旨在将在线策略蒸馏集成至 Flow Matching 模型中,以缓解多任务对齐过程中的梯度干扰与奖励稀疏问题。该框架采用两阶段策略,首先通过单奖励 GRPO 微调训练领域专用教师模型,随后借助基于 Flow 的冷启动初始化、在线策略采样、任务路由标注以及密集轨迹级监督,将异构专业知识整合至单一学生模型中。
- 该研究提出了流形锚点正则化(Manifold Anchor Regularization),以对抗强化学习对齐过程中固有的美学退化现象。该机制利用任务无关型教师提供全量数据监督,将生成过程锚定于高质量视觉流形之上,从而有效稳定多目标竞争下的优化过程。
- 在 Pickscore、GenEval 和 OCR 基准上的综合评估表明,该框架显著提升了布局连贯性、文本渲染准确性及整体功能可靠性。定量结果证实,相较于现有的 Flow Matching 基线方法,该框架在多项对齐指标上均表现出更优的性能。
引言
Flow Matching 已成为一种更优越的生成建模范式,在采样效率与合成质量方面均超越扩散模型,然而当前的训练后方法难以支持现代应用(如精确文本渲染与复杂组合推理)所需的维度对齐。此前基于强化学习算法(如组相对策略优化 GRPO)的方法在多任务场景下面临严峻局限,其稀疏的标量奖励缺乏协调冲突目标的细粒度。这种稀疏性引发了零和博弈式的跷跷板效应:优化特定特征会通过奖励黑客攻击与梯度干扰损害美学表现,导致现有方法陷入指标权衡、训练不稳定或奖励归一化崩溃的困境。作者借鉴在大型语言模型中已被验证有效的在线策略蒸馏范式,提出了 Flow-OPD,这是首个将 OPD 集成至 Flow Matching 模型训练后流程的框架。该两阶段策略首先通过单奖励 GRPO 培养领域专用教师模型,随后借助基于 Flow 的冷启动初始化、任务路由标注与流形锚点正则化,将其密集的轨迹级监督蒸馏至统一的学生模型中。实验结果表明,Flow-OPD 相较于基础 GRPO 提升了 10%,使学生模型在保持强大分布外泛化能力的同时,达到或超越领域专家模型的水平。
方法
作者采用两阶段对齐框架 Flow-OPD,将在线策略蒸馏集成至 Flow Matching 模型中,以应对多任务文生图生成中的奖励稀疏与梯度干扰挑战。整体流程首先通过单奖励 GRPO 微调培养领域专用教师模型。每位教师独立针对特定任务进行优化,使其能够在不受其他目标干扰的情况下达到性能上限。此步骤确保各专家模型在其对应领域具备高度专业能力。

完成专家训练后,系统通过基于 Flow 的冷启动方案为学生模型建立稳健的初始策略。该初始化步骤对防止训练早期的轨迹发散至关重要。作者探索了两种策略:一是监督微调(SFT)协议,从专用教师中采样轨迹以继承专家知识分布;二是模型融合方法,将不同教师模型的各向异性先验叠加至统一的参数状态。这种以融合作为初始化的技术将学生模型置于损失景观的高能力区域,为后续的蒸馏过程奠定坚实基础。

该方法的核心多教师在线策略蒸馏,通过三步编排机制运行。首先,由学生模型执行在线策略采样,从其自身分布中生成轨迹。为充分探索状态空间,确定性概率流常微分方程(ODE)被转换为等效的随机微分方程(SDE),从而为学生模型的转移过程生成局部各向同性高斯策略。其次,采用任务特定的教师标注机制。在每个状态 xt,学生模型的文本条件 c 通过硬路由函数 R(c) 被路由至特定专家教师 k。该机制确保每次仅由一名教师提供监督,彻底消除跨域梯度干扰。学生模型策略的目标速度场因此定义为 vtarget(xt,t,c)=vϕk(xt,t,c)。
最后一步涉及推导用于策略优化的密集奖励信号。作者解析推导了学生模型与目标模型转移策略之间的反向 KL 散度。由于两种策略共享相同的各向同性协方差,该散度简化为两者向量场之间的时间加权 L2 距离。此距离被用于构建第 i 条轨迹的密集奖励 rt(i),并应用于裁剪策略梯度更新中。系统计算策略比率 ρt,i,j(θ),并优化裁剪后的代理目标以更新模型参数,确保在高频奖励下训练的稳定。该流程使学生能够无缝整合教师集成中的异构专业知识,最终形成单一的统一模型。
为进一步提升生成质量并防止美学退化,作者引入了流形锚点正则化(MAR)。该机制将功能对齐与美学保持解耦。它利用任务无关型且冻结的美学教师(例如通过 DeQA 优化的模型)提供高保真度的正则化向量场 vaesthetic。优化过程被表述为包含策略损失与密集 KL 惩罚的总损失函数,该惩罚为学生模型与美学教师向量场之间的时间加权 L2 距离。此正则化机制充当连续的弹性锚点,确保学生策略在吸收多教师集成功能智能的同时,始终被约束在高质量视觉流形范围内。
实验
该评估在组合生成、文本渲染与质量基准上,将 Flow-OPD 与单体及混合奖励 GRPO 基线方法进行对比,以验证标量奖励混合的根本局限性以及密集多专家监督的必要性。受控消融实验与冷启动实验证实,传统标量对齐会引发灾难性遗忘与梯度干扰,而所提框架成功整合了多样化的专家能力且未出现性能衰退。分布外基准上的泛化测试进一步表明,密集监督有效缓解了跨任务性能回退,并实现了稳健的多任务权衡。最终,与替代强化学习框架的对比分析凸显了该方法在规避奖励黑客攻击与幻觉伪影方面的能力,同时实现了更优的美学与功能一致性。
{"summary": "The authors evaluate a multi-task training approach on a foundation model, comparing it against baselines that use scalar reward mixing and single-reward optimization. Results show that their method achieves consistent performance across multiple tasks, surpassing or matching specialized teachers while avoiding the degradation seen in other approaches. The method leverages dense multi-expert supervision to resolve gradient interference and maintain capability stability.", "highlights": ["The proposed method outperforms scalar reward mixing and single-reward baselines across all evaluated tasks, achieving superior or comparable performance to specialized teachers.", "The method effectively mitigates catastrophic forgetting and capability degradation observed in other multi-task approaches, maintaining stable performance on all metrics.", "By using dense multi-expert supervision, the approach enables robust learning that surpasses individual teacher models in certain edge cases, demonstrating emergent superiority."]
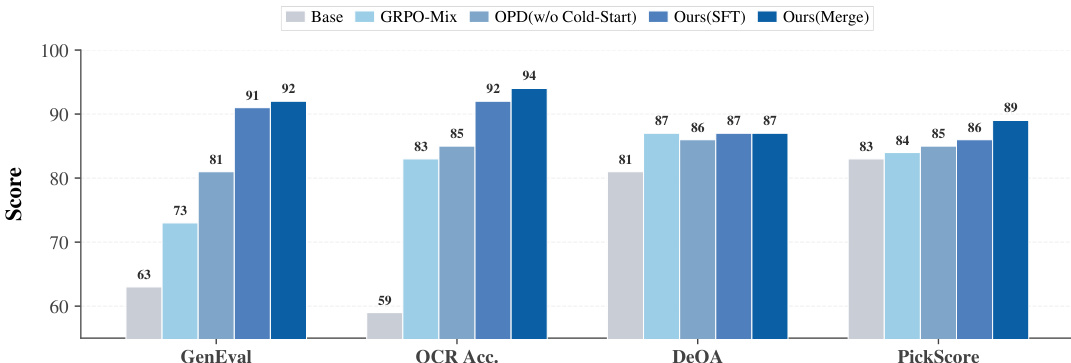
作者开展实验以评估不同训练方法在基础模型多奖励优化中的有效性。结果表明,标量奖励混合会导致跨任务能力退化,而所提方法通过利用密集的多专家监督实现了更优的性能。该框架在所有基准测试中达到或超越了单一专用教师模型的性能,且未受跨域干扰影响。标量奖励混合引发了显著的能力退化,无法在多项任务中维持稳定表现。所提方法借助密集的多专家监督,在所有基准上实现了持续且优越的性能。该方法在避免跨域干扰的同时,达到或超越了专用教师模型的表现。
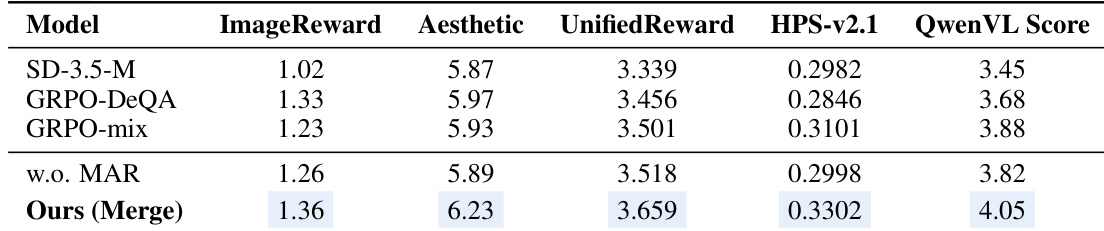
作者在多奖励优化设定下将所提方法与基线模型进行对比,重点考察其在各项评估指标上的表现。结果表明,该方法在美学与整体质量指标上取得了更高分数,同时在其他维度保持了具有竞争力的表现。该方法在图像质量与对齐等关键领域展现出改进,在多项基准测试中优于现有基线。与基线模型相比,所提方法获得了更高的美学与整体质量评分。它在图像质量与对齐等关键指标上持续优于其他方法。该方法在平衡多重奖励目标方面表现卓越,且未出现个体能力的显著退化。
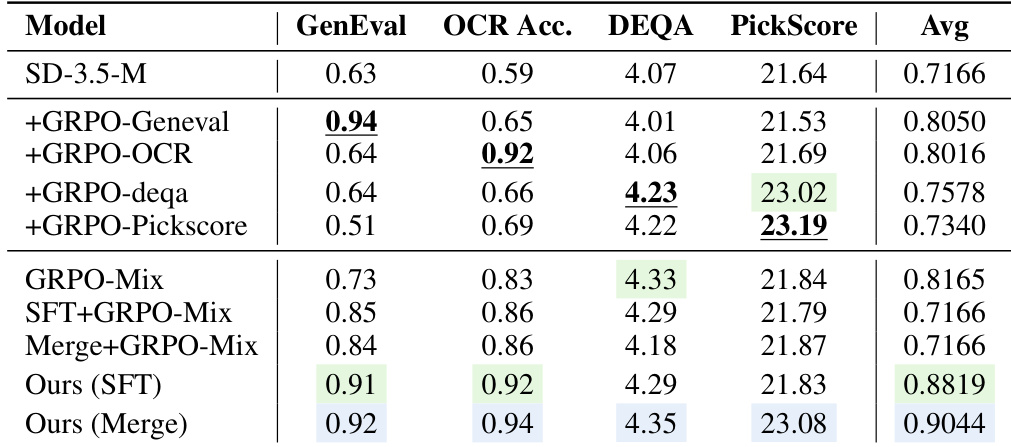
作者深入探讨了标量奖励混合在多奖励优化中的局限性,指出引入后续奖励会导致已习得能力出现显著退化。所提方法 Flow-OPD 通过采用密集的多专家监督成功规避了这一退化现象,在多项任务中实现了与单一专用教师模型相当甚至更优的性能。在单奖励训练模型上添加后续奖励会导致已习得能力大幅衰退。标量奖励混合因梯度干扰与灾难性遗忘,无法在多项任务中维持性能。所提方法借助密集的多专家监督,实现了与个体专用教师模型相当或更优的表现。
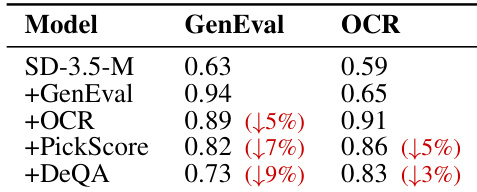
作者在多奖励优化设置下将所提方法与基线模型进行对比,重点关注其在各类视觉生成任务中的表现。结果表明,该方法在基线基础上实现了持续的性能提升,尤其在复杂推理与空间推理任务中表现突出,同时在多样化能力上保持了强劲水平。所提方法在多项视觉生成任务中优于基线模型,涵盖复杂推理与三维空间推理。结合冷启动初始化的所提方法比标准训练策略取得了更优结果。该方法在纹理与形状生成方面实现了显著提升,展现出稳健的多任务能力。

作者在多样化的视觉生成与推理基准上,将多奖励优化框架与标量奖励混合及单奖励训练等标准基线方法进行对比。这些实验验证了传统混合策略会导致严重的性能衰退与梯度干扰,而所提方法借助密集的多专家监督,在所有任务中均能维持稳定表现。定性分析表明,该方法成功缓解了灾难性遗忘与跨域干扰,在美学质量、对齐效果与复杂空间推理方面持续达到或超越专用教师模型,且未牺牲任何个体能力。