Command Palette
Search for a command to run...
快速字节隐式Transformer
快速字节隐式Transformer
Julie Kallini Artidoro Pagnoni Tomasz Limisiewicz Gargi Ghosh Luke Zettlemoyer Christopher Potts Xiaochuang Han Srinivasan Iyer
摘要
近期的字节级语言模型(LMs)在性能上已可与基于词元的模型(token-level models)相媲美,且无需依赖子词词表(subword vocabularies),但其效用仍受限于逐字节自回归生成(byte-by-byte autoregressive generation)导致的低效问题。我们通过新型的训练与生成技术,解决了字节潜变换网络(Byte Latent Transformer, BLT)中的这一瓶颈。首先,我们提出了 BLT Diffusion(BLT-D),这是一种新模型,也是目前速度最快的 BLT 变体。它采用标准的下一字节预测损失(next-byte prediction loss),并结合辅助性的块级扩散目标(block-wise diffusion objective)进行训练。这种方法使得推理过程能够在每个解码步(decoding step)中并行生成多个字节,从而显著减少生成序列所需的正向传播(forward passes)次数。其次,我们受推测解码(speculative decoding)的启发,提出了两种扩展方法,以牺牲部分速度换取更高的生成质量:一是 BLT Self-speculation(BLT-S),利用 BLT 的局部解码器(local decoder)在其正常补丁边界(patch boundaries)之外继续生成字节作为草稿(draft bytes),随后通过一次完整的模型正向传播进行验证;二是 BLT Diffusion+Verification(BLT-DV),它在基于扩散的生成(diffusion-based generation)之后增加了自回归验证步骤(autoregressive verification step)。评估表明,所有方法在生成任务上的内存带宽成本(memory-bandwidth cost)估计比 BLT 降低超过 50%。每种方法均具有独特的优势,共同消除了限制字节级 LLMs 实际应用的 key barriers。
一句话总结
针对逐字节自回归生成限制字节级语言模型速度的问题,本研究通过引入 BLT Diffusion (BLT-D)、BLT Self-speculation (BLT-S) 和 BLT Diffusion+Verification (BLT-DV) 增强了 Byte Latent Transformer (BLT)。这些方法利用并行生成和验证,预计内存带宽成本比 BLT 降低 50% 以上,同时消除了无子词模型实际应用的关键障碍。
核心贡献
- 论文介绍了 BLT Diffusion (BLT-D),这是一种变体,在标准下一字节预测之外,使用辅助块级扩散目标进行训练,以实现并行字节生成。与传统自回归方法相比,该设计显著减少了生成序列所需的前向传播次数。
- BLT Self-speculation (BLT-S) 利用现有的局部解码器在正常块边界之外起草字节,无需单独的草稿模型进行验证。这一扩展减少了昂贵的编码器调用次数,同时保持了标准自回归解码的输出质量。
- BLT Diffusion+Verification (BLT-DV) 结合快速扩散起草与自回归验证步骤,在速度和性能权衡中占据中间点。总体而言,这些方法在生成任务中预计可实现比标准 BLT 低 50% 以上的内存带宽成本。
引言
字节级语言模型直接在原始字节上运行,以避免子词分词问题,如噪声敏感性和多语言差异。尽管有这些好处,先前的工作在推理效率方面存在不足,其中逐字节的顺序生成造成了内存带宽瓶颈。作者通过引入 BLT Diffusion 解决了这一问题,该方法通过块级扩散目标实现并行字节生成。他们进一步开发了 BLT Self-speculation 和 BLT Diffusion+Verification,在不依赖外部草稿模型的情况下平衡速度与质量。这些方法共同将内存带宽成本降低了 50% 以上,并消除了实际部署的关键障碍。
数据集
- 数据集组成与结构
- 作者使用格式化为字节序列的原始训练样本,分割为可变长度块。
- 数据结构由这些块构建的固定长度块组成,以实现块级掩码预测。
- 预处理与构建细节
- 熵分块器动态分割输入以定义块边界。
- 块是通过从块索引处获取连续字节创建的,通常超出原始块大小。
- 当块超过序列长度时,应用特殊的 padding tokens。
- 记录原始字节位置索引,以确保解码器中正确的 RoPE 位置编码。
- 训练使用与掩码策略
- 模型采用扩散过程,在训练期间采样连续时间步。
- 字节根据采样概率独立替换为 [MASK] tokens 以创建损坏的输入。
- 此设置允许模型在推理期间从损坏的输入重建干净序列。
方法
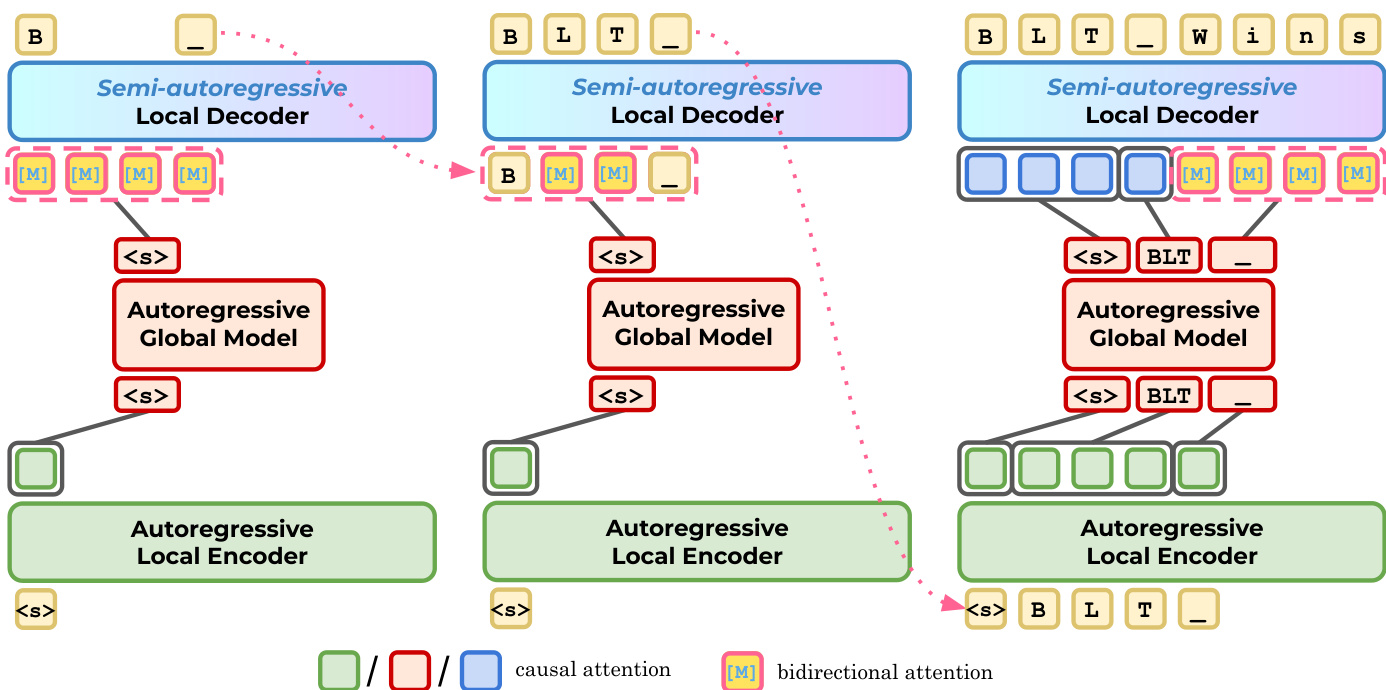
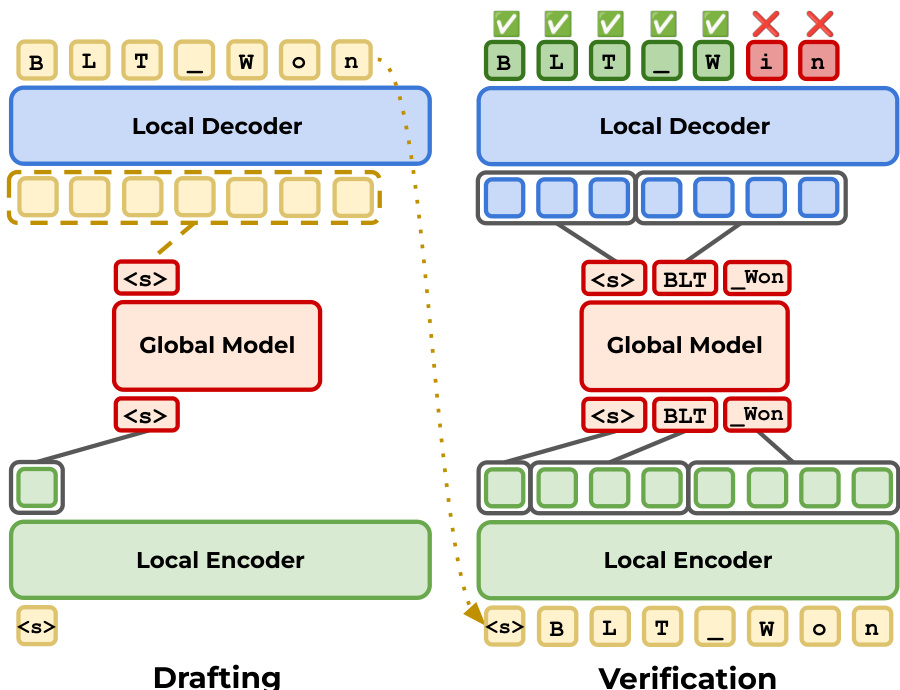
字节级 Transformer (BLT) 直接在原始字节序列上运行,利用分层架构平衡效率与性能。模型由三个主要组件组成:局部编码器 E、全局 Transformer G 和局部解码器 D。局部编码器将输入字节序列嵌入到初始表示中,然后由全局模型处理为 latent token 表示。这些 latent tokens 随后由局部解码器解码回字节。参考下方的框架图以可视化局部和全局组件之间的交互。
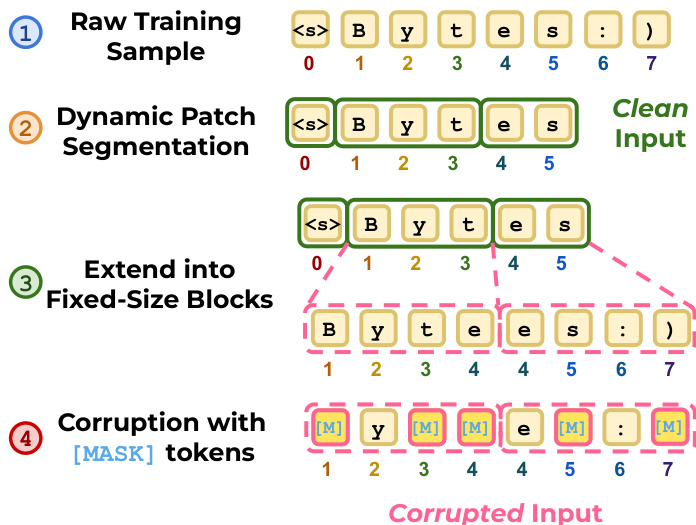
为了实现高效的块扩散解码,BLT-D 引入了专门的训练流程。该过程从动态分块开始,原始训练样本基于熵被分割为可变长度块。然后将这些块扩展为固定大小的块,并用 [MASK] tokens 损坏以创建训练输入。参考下图以了解逐步数据预处理工作流。
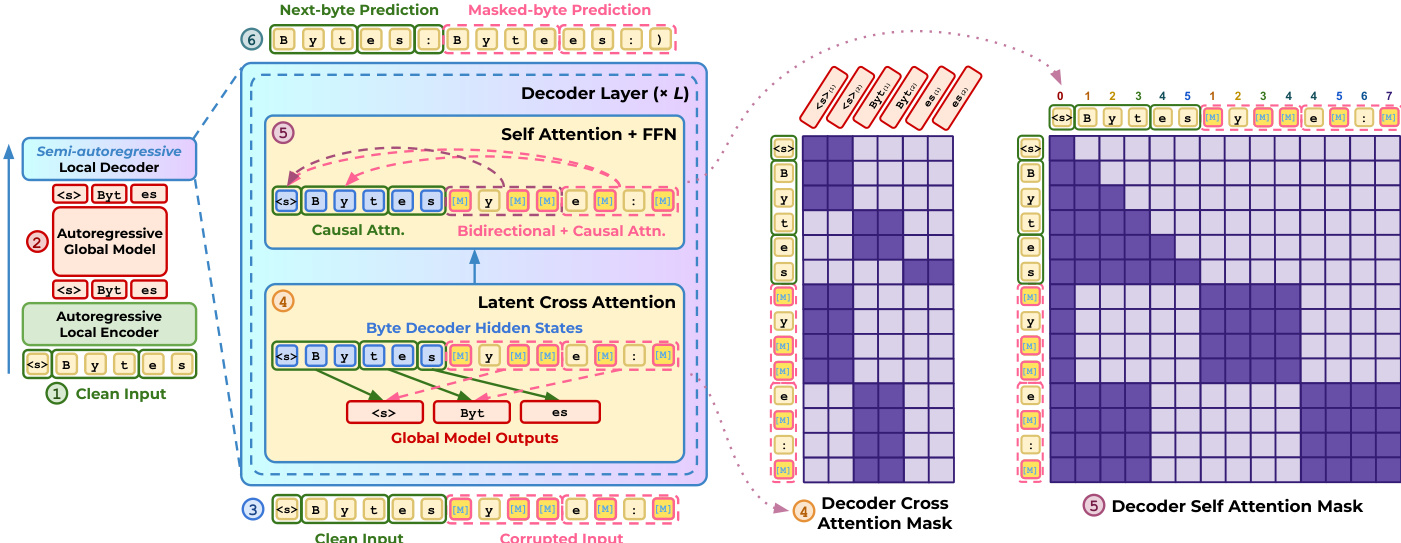
在训练前向传播期间,模型处理干净和损坏的输入。编码器和全局模型处理干净输入以产生潜在表示,然后由解码器使用。解码器对这些 latent tokens 应用交叉注意力,同时使用特定的注意力掩码:干净序列的因果注意力以及损坏块内的双向注意力。总训练目标结合了干净序列的下一字节预测损失和损坏块的掩码扩散损失。完整的训练架构如下所示。
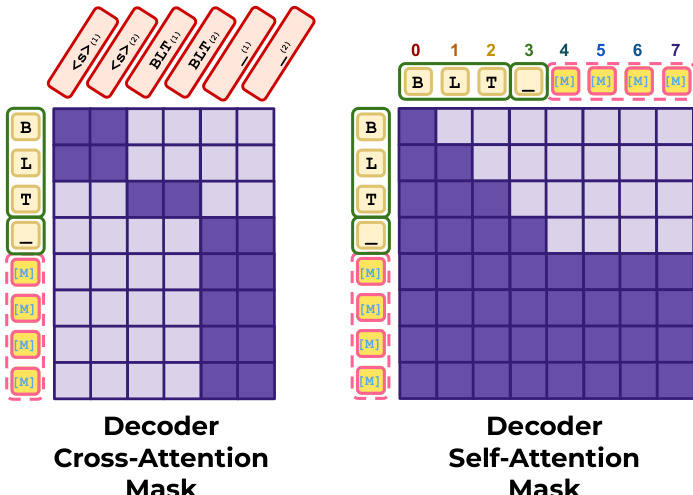
BLT-D 的推理依赖于精心构建的注意力掩码以支持块扩散。对于解码器的交叉注意力,干净位置关注其对应的 latent tokens,而掩码块位置关注最后一个可用的 latent token。对于自注意力,干净前缀使用因果掩码,而损坏块使用完全双向掩码。这些模式在下方的掩码图中可视化。
最后,作者提出了 BLT-S 和 BLT-DV 等扩展,以通过推测解码进一步提高效率。在此范式中,模型使用快速机制(如扩散或扩展自回归解码)起草 token 序列,然后使用较慢、更准确的传递验证这些草稿。起草阶段提出候选字节,验证阶段根据模型的预测接受或拒绝它们。这一迭代过程如下图所示。
实验
实验评估了字节级语言模型在翻译和代码生成任务上的表现,使用 1B 和 3B 参数规模以评估推理速度与生成质量之间的权衡。结果表明,与标准自回归基线相比,BLT-D 框架通过减少内存带宽和网络函数评估显著提高了效率,尽管较大的块大小可能会轻微降低编码性能,同时保持翻译准确性。额外的评估证实,这些基于扩散的方法在推理基准上保留了自回归能力,并允许对输出多样性与计算成本之间的平衡进行可调整的控制。
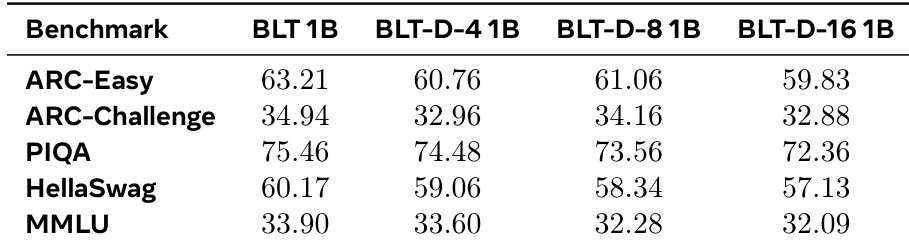
下表呈现了 1B 参数模型在五个标准语言理解和推理基准上的基于似然的评估结果。基线模型始终优于基于扩散的变体,尽管变体保持了接近基线性能的竞争力分数。这表明尽管在准确性上有轻微权衡,扩散机制仍保留了强大的自回归能力。与扩散变体相比,基线模型在所有五个评估基准上均取得了最高分数。增加扩散块大小通常会导致数据集上的性能分数略有下降。扩散变体在推理任务上表现出稳健的性能,尽管架构发生变化,但仍接近基线。
作者比较了标准自回归生成与基于扩散和推测推理方法的效率和质量。数据显示,与基线相比,扩散模型显著减少了内存带宽和网络函数评估,随着扩散块大小的增加,效率提高。然而,这种速度提升与任务性能下降相关,可以通过添加验证步骤部分恢复。推测推理在不损害相对于基线的任务性能的情况下实现了显著的内存节省。较大的扩散块大小产生更大的计算成本降低,但导致生成质量较低。验证机制提高了扩散模型的准确性,但与仅扩散设置相比需要额外的计算资源。
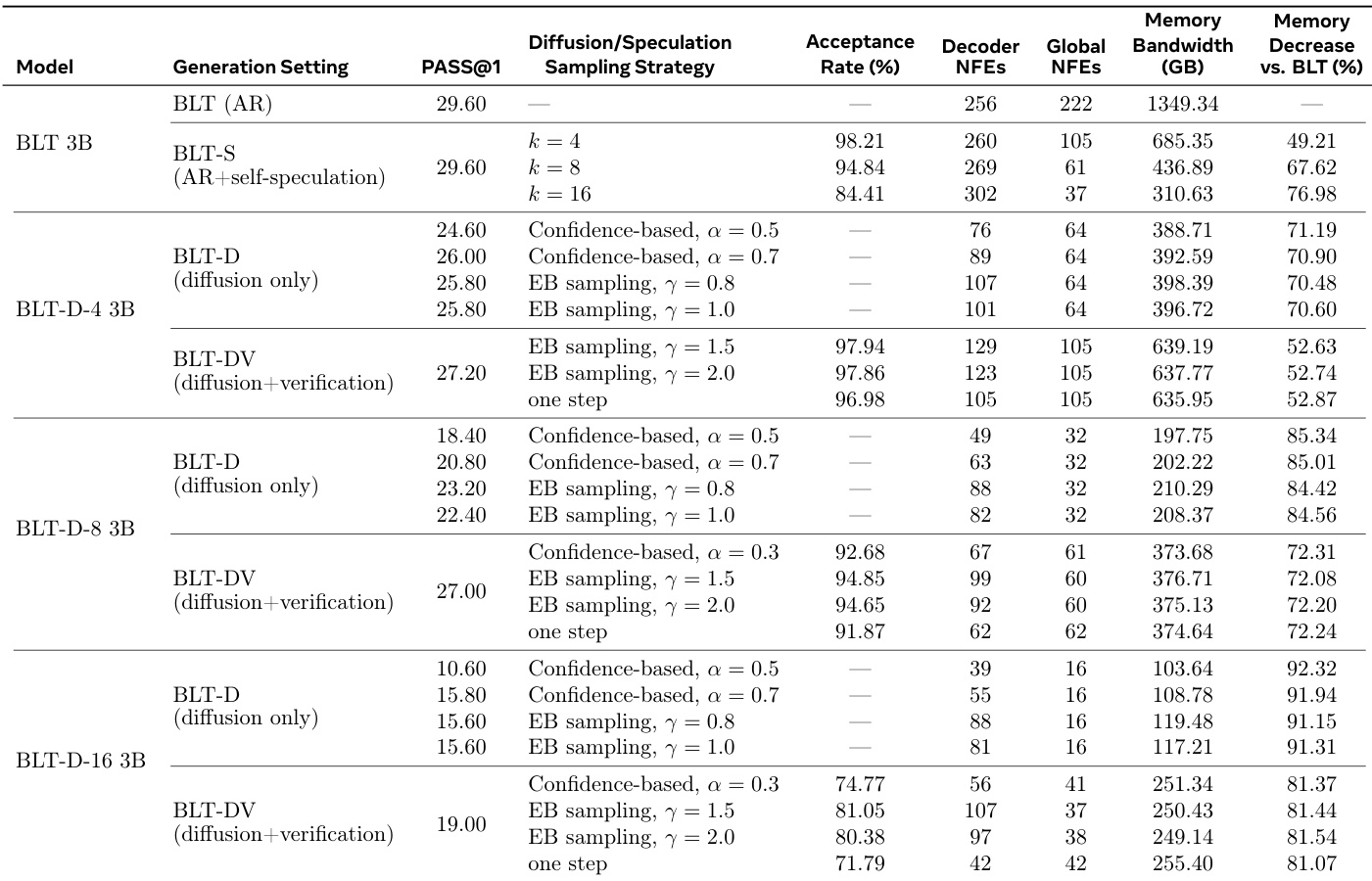
下表比较了基线 BLT 3B 模型与基于扩散的变体和推测扩展,突出了推理效率与生成质量之间的权衡。虽然仅扩散模型显著减少了内存带宽和网络函数评估,但它们通常表现出低于自回归基线的 BLEU 分数。基于验证的扩展恢复了许多性能损失,同时保持了显著的效率提升,而自推测方法以改进的效率匹配基线性能。增加扩散块大小提高了内存带宽和 NFEs 等效率指标,但导致任务性能分数下降。基于验证的 BLT-DV 变体比仅扩散的 BLT-D 模型实现了更高的生成质量,同时与基线相比仍提供了显著的内存使用减少。自推测 BLT-S 方法保持了基线模型的任务性能,同时大幅减少了内存带宽和全局网络函数评估。
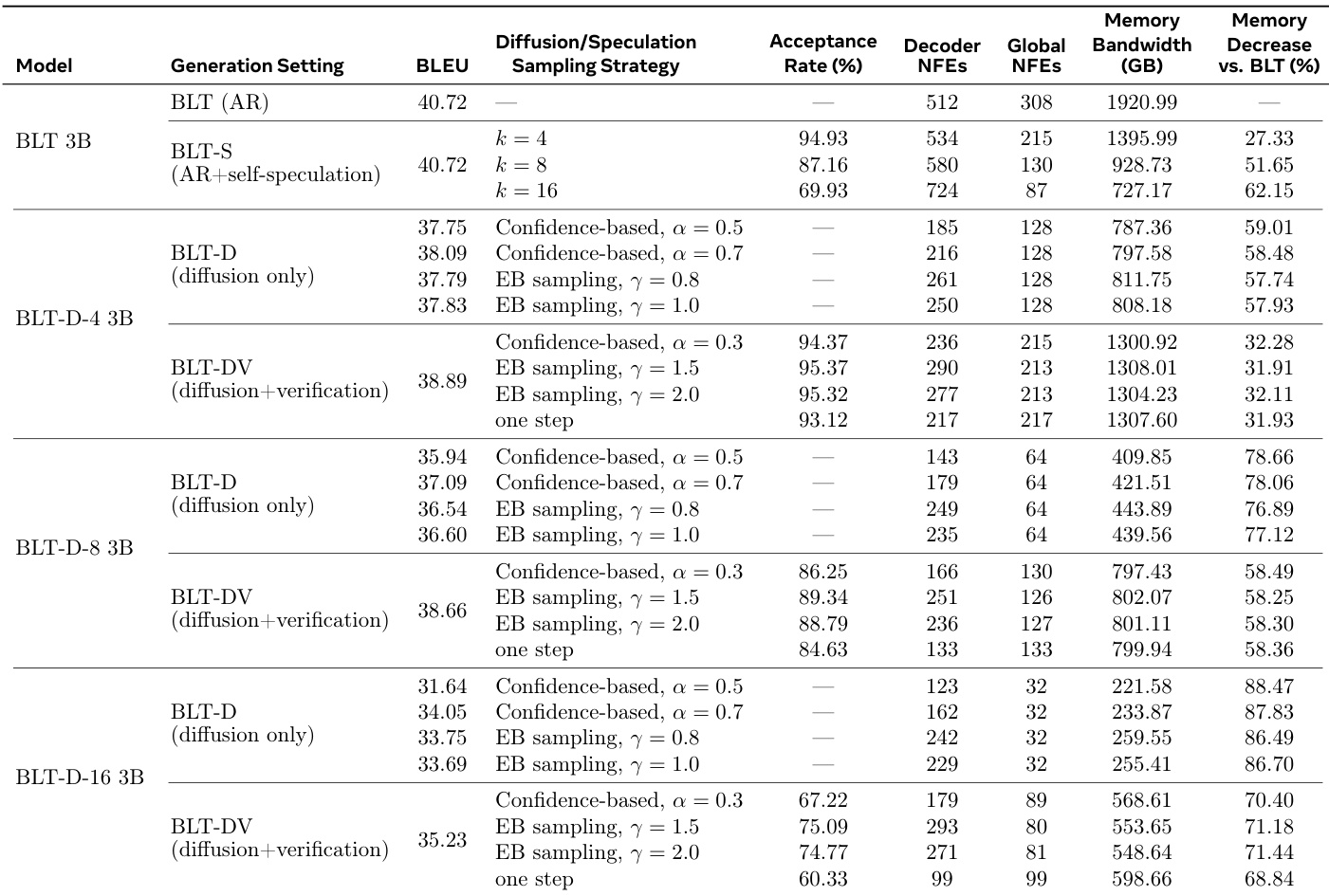
作者评估了包括 BLT-S、BLT-D 和 BLT-DV 在内的推理扩展,以针对基线自回归模型表征速度 - 质量权衡。结果表明,基于扩散的方法大幅减少了内存带宽和网络函数评估,尽管通常以任务性能指标为代价。基于验证的方法有助于恢复扩散模型中的一些性能损失,同时保留了比标准基线显著的效率改进。仅扩散模型实现了最高的效率提升,特别是随着块大小增加,导致最低的内存带宽使用。向扩散模型添加验证提高了与仅扩散变体相比的生成质量分数,尽管它增加了全局网络函数评估。自推测方法保持了与基线相似的任务性能水平,同时仍提供了内存带宽要求的显著降低。
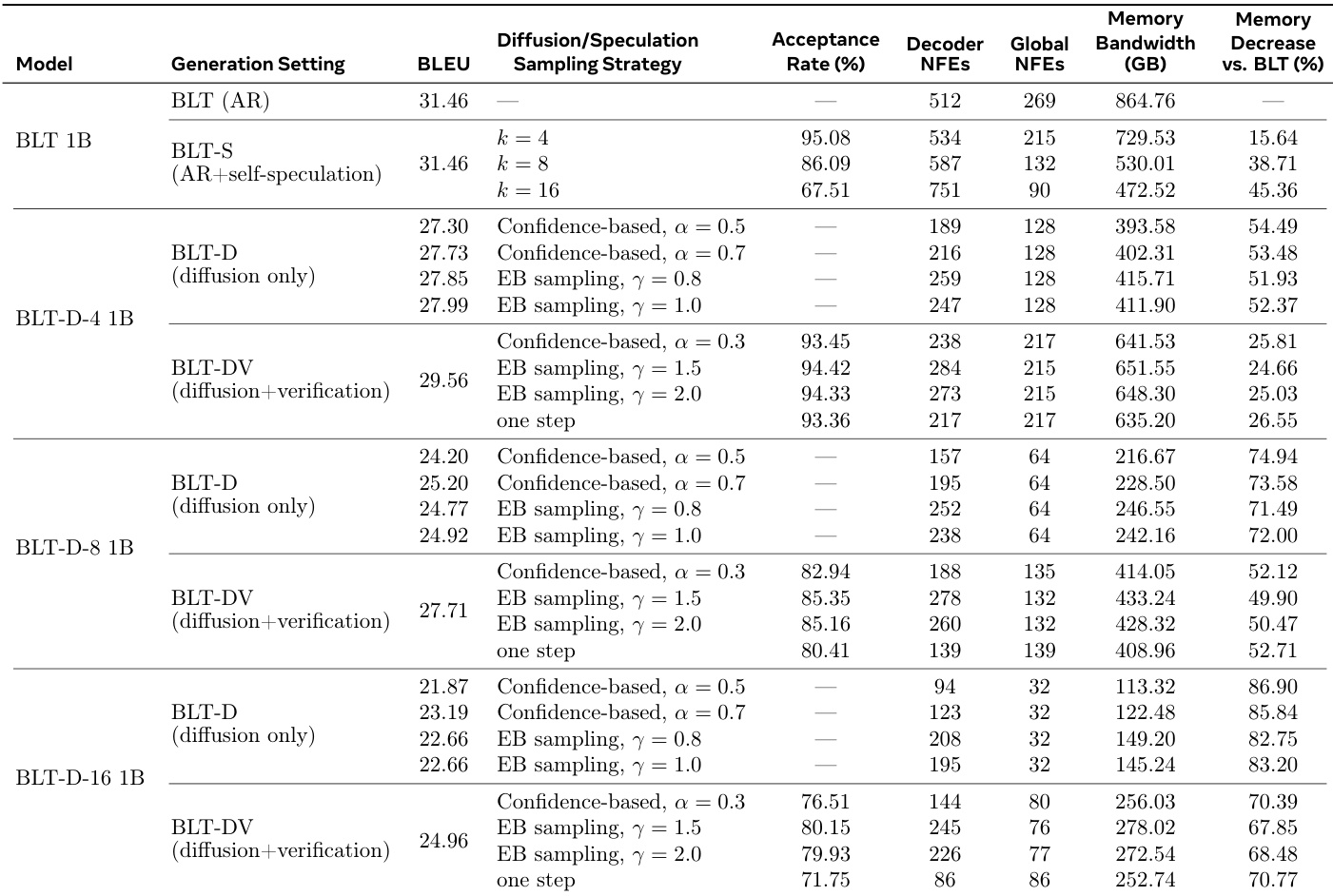
作者评估了语言模型的各种推理策略,将基于扩散和推测的方法与标准自回归基线进行比较。结果表明,基于扩散的方法显著减少了内存带宽和计算步骤,随着块大小增加,效率增益增加。基于验证的扩展有助于恢复纯扩散设置中损失的任务性能,同时保留了大部分效率优势。基于扩散的模型始终比自回归基线实现更低的内存带宽使用和更少的网络函数评估。向扩散生成添加验证提高了任务质量,但比仅扩散方法需要更多的计算资源。推测生成保持了与基线相当的性能,同时提供了内存带宽要求的显著降低。
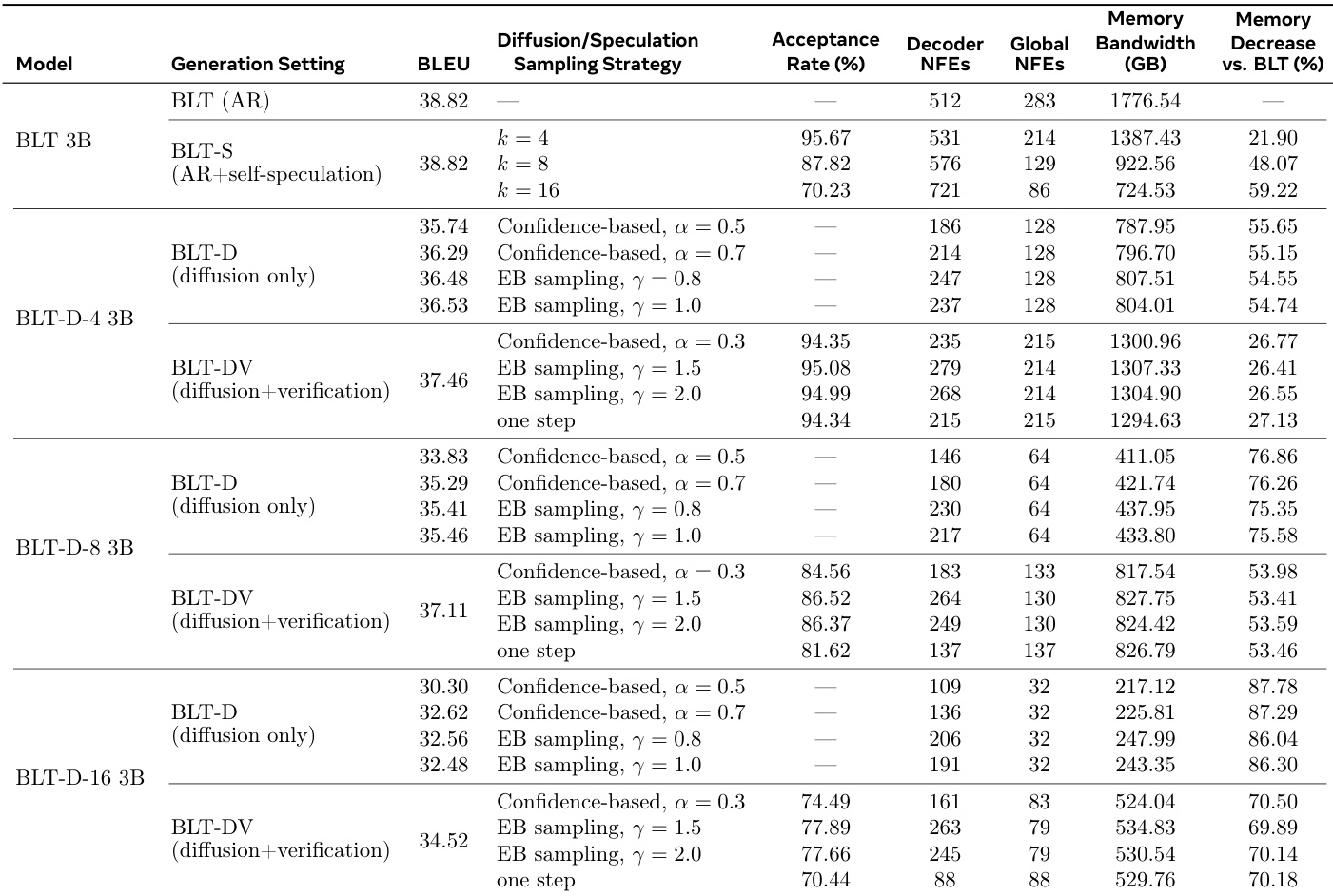
实验评估了标准自回归基线与基于扩散和推测推理方法在语言理解和生成任务上的表现。尽管基线始终实现了最高的准确性,但扩散变体显著减少了内存带宽和计算评估,较大的块大小产生更高的效率但质量较低。验证机制有助于恢复扩散模型中的性能损失,而推测方法在提供显著效率提升的同时保持了基线性能水平,最终突出了可以通过架构扩展平衡的推理速度与生成质量之间的权衡。