Command Palette
Search for a command to run...
你的语言模型是其自身的评论家:基于 Actor 内部状态的价值估计的强化学习
你的语言模型是其自身的评论家:基于 Actor 内部状态的价值估计的强化学习
Yunho Choi Jongwon Lim Woojin Ahn Minjae Oh Jeonghoon Shim Yohan Jo
摘要
基于可验证奖励的大推理模型强化学习(RLVR)依赖于基线估计以实现方差缩减,但现有方法代价高昂:PPO 需要与策略模型规模相当的评论家(critic),而 GRPO 需要针对每个提示(prompt)进行多次采样(rollouts)以保持其经验组均值的稳定性。我们提出了内部状态价值估计策略优化(Policy Optimization with Internal State Value Estimation, POISE),该方法通过利用策略前向传播过程中已计算出的策略模型内部信号,以极低的成本获得基线。一个轻量级探针(probe)从提示和生成轨迹的隐藏状态以及 token 熵统计量中预测预期的可验证奖励,并与策略模型同步在线训练。为了在使用轨迹条件特征时保持梯度无偏性,我们引入了一种跨采样(cross-rollout)构造方法,即利用独立采样的内部状态来预测每个采样的价值。由于 POISE 仅使用单次采样即可估计提示价值,因此在固定的计算预算下,训练期间能够实现更高的提示多样性。这降低了梯度方差,使学习更加稳定,并消除了为检测零优势提示而进行采样所带来的计算开销。在数学推理基准测试中,Qwen3-4B 和 DeepSeek-R1-Distill-Qwen-1.5B 上的 POISE 在达到与 DAPO 相当性能的同时,所需的计算资源更少。此外,其价值估计器的性能与独立的 LLM 规模价值模型相似,并能泛化至各种可验证任务。通过利用模型自身的内部表示,POISE 实现了更稳定且高效的策略优化。
一句话总结
作者提出了 POISE,一种强化学习方法。该方法通过训练轻量级在线探针,利用策略模型的隐藏状态和 token 熵统计来预测可验证奖励,从而替代外部 critic 和多次 rollout。该方法采用跨 rollout 构造以保持梯度无偏性并降低方差,在固定计算资源下支持更高的 prompt 多样性,并在 Qwen3-4B 和 DeepSeek-R1-Distill-Qwen-1 上验证了其有效性。
核心贡献
- 本文提出 POISE,一种强化学习算法。该算法利用基于策略模型内部隐藏状态和 token 熵统计训练的轻量级探针来估计期望可验证奖励。为保持梯度无偏性,该方法采用跨 rollout 构造,从独立 rollout 中预测每条轨迹的价值。
- 该架构消除了 LLM 规模 critic 的计算开销,并将每个 prompt 所需的 rollout 数量减少至单对,从而在固定计算预算下实现更高的 prompt 多样性。连续基线设计还消除了额外采样步骤以检测并丢弃零优势 prompt 的需求。
- 实验结果表明,POISE 在数学推理基准上达到了与最先进 DAPO 算法相当的性能,同时所需计算资源更少。该估计器还能泛化至代码生成、工具调用和指令遵循任务,并保持与全规模价值模型相当的性能。
引言
大型语言模型通过带可验证奖励的强化学习在复杂推理方面取得了显著进展,该过程依赖准确的基线来稳定训练并降低奖励方差。现有方法面临显著的计算瓶颈:PPO 需要 LLM 规模的 critic,导致内存消耗翻倍;而 GRPO 用组相对基线替代 critic,这需要多次 rollout,降低了 prompt 多样性并放大了梯度方差。为解决这些低效问题,作者利用策略模型自身的内部隐藏状态和 token 熵来训练轻量级探针,以估计期望奖励。该方法消除了对重型 critic 或大规模 rollout 组的需求,提供了稳定且计算高效的优化方案,并能有效泛化至数学推理、代码生成和指令遵循任务。
方法
作者利用策略模型的内部状态信号,为带可验证奖励的强化学习(RLVR)构建低成本且无偏的基线,构成了所提方法 POISE 的核心。该框架基于一个关键洞察:轻量级探针可直接从策略模型的隐藏状态中预测期望可验证奖励。这些隐藏状态在前向传播过程中已计算完成,因此无需辅助价值网络或大规模 rollout 组。如图所示,该流程始于策略模型为每个 prompt x 生成两个独立的 rollout,y(1) 和 y(2)。在前向传播期间,提取模型内部状态,具体包括最后十个 prompt token 和最后十个推理 token 的隐藏状态,随后进行池化以形成每个 rollout 的特征表示 ϕ(x,y(i))。这些特征结合 token 熵统计量,作为轻量级价值估计器 gf 的输入。
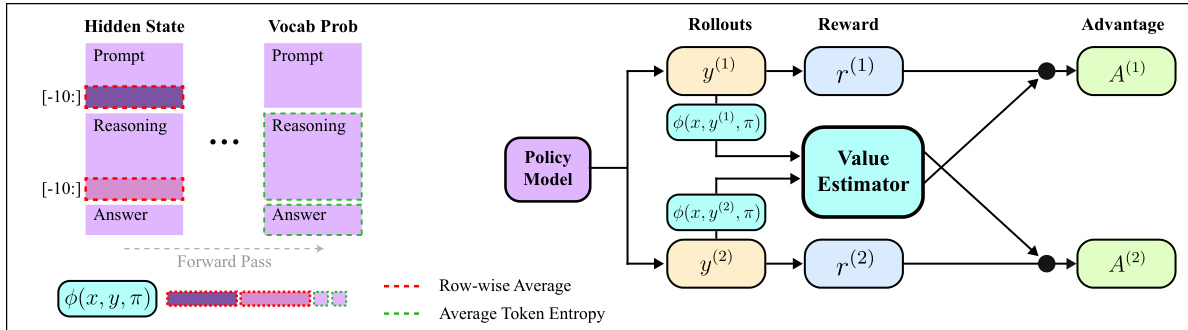
该价值估计器采用在线训练方式,并利用轨迹缓冲区稳定训练过程以应对策略漂移。对于包含两个 rollout 的每个 prompt,估计器在回归任务上进行训练,其中 rollout i 特征的目标值为另一个 rollout 的奖励,即 R(i)=R(x,y(j)),j=i。这种跨 rollout 构造确保了用于每个 rollout 优势计算的基线源自独立样本,保留了无偏梯度估计器所需的条件独立性。rollout i 的基线预测为 b(i)(x)=gf(ϕ(j)),j=i,从而得到跨 rollout 优势 A(i)(x)=R(x,y(i))−b(i)(x)。这些优势随后被用于 PPO 风格的截断代理目标函数中,以更新策略参数 θ。该设计使 POISE 能够在固定计算预算下支持更高的 prompt 多样性,因为价值估计仅需每个 prompt 单次 rollout,从而降低了梯度方差,实现了稳定学习。
实验
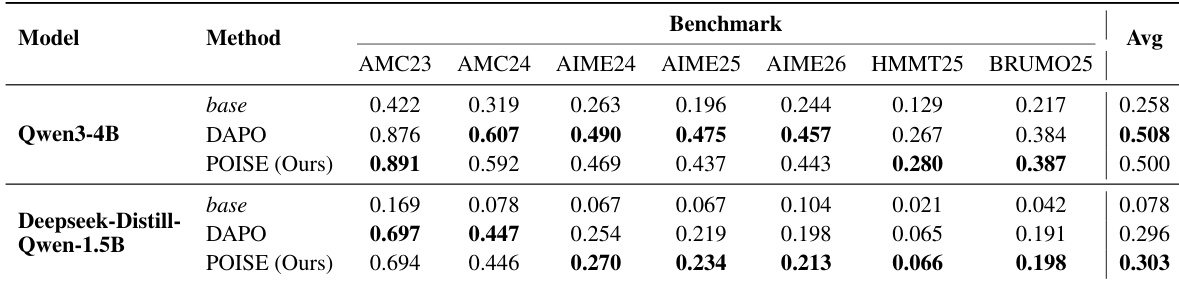
实验在 Qwen3-4B 和 DeepSeek-R1-Distill-Qwen-1.5B 模型上进行,这些模型使用数学推理数据训练,并在多个奥林匹克级别基准上针对最先进 DAPO 算法进行评估。基准评估验证了用轻量级内部状态价值估计器替代组相对基线,可在显著缩短训练时间并通过降低梯度方差稳定优化过程的同时,获得相当的推理性能。对价值估计器的进一步分析证实,它能可靠地追踪不断演化的策略奖励,持续降低优势方差,并泛化至不同领域和模型规模,性能达到或超过单独训练的 critic 模型。这些发现共同验证了模型内部激活信号能为带可验证奖励的强化学习提供稳健且计算高效的可靠价值估计基础。
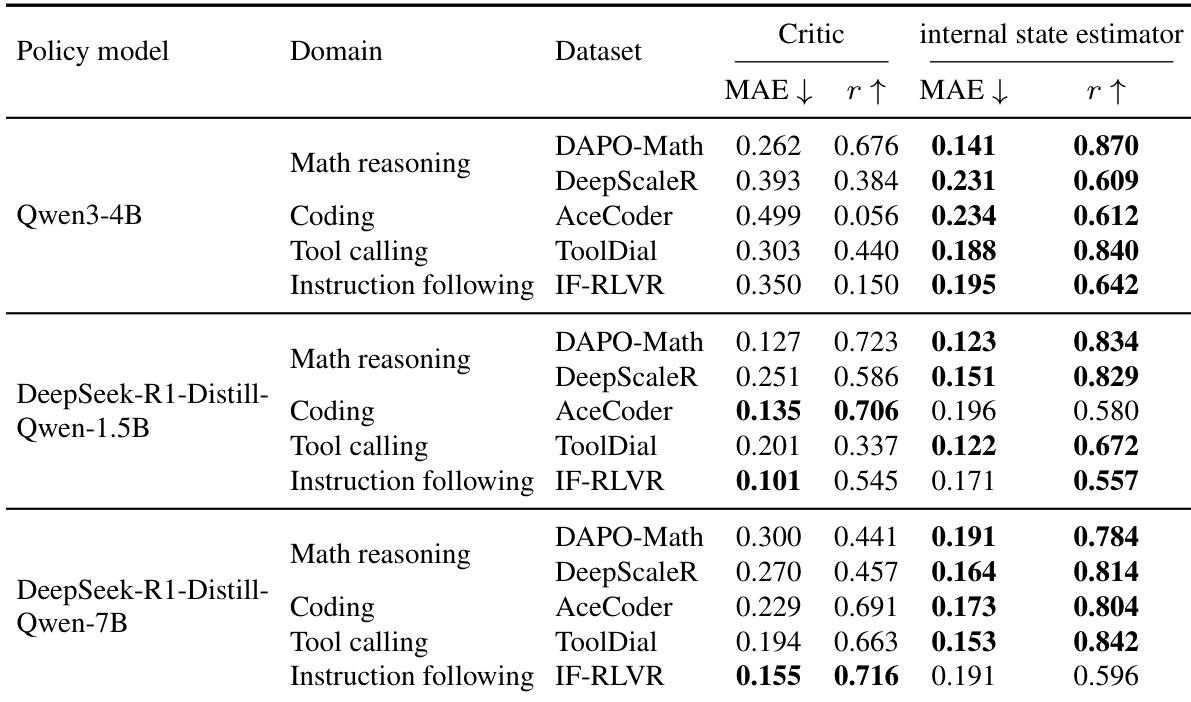
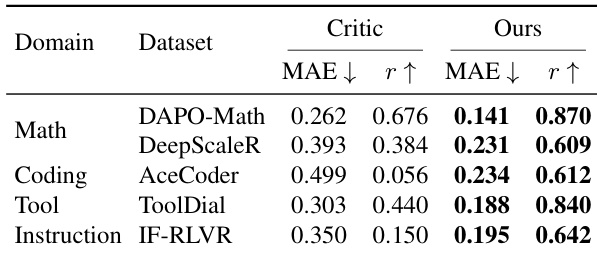
作者在多个领域和策略模型上,将轻量级内部状态价值估计器与单独训练的 critic 模型进行了对比。结果表明,该内部状态估计器在平均绝对误差和皮尔逊相关系数方面取得了具有竞争力或更优的性能,尤其在代码生成和指令遵循任务上表现突出,同时所需计算开销显著降低。该估计器在不同模型规模和领域下均保持稳定,并能良好适配不断演化的策略。内部状态估计器在多个领域和模型尺寸上均表现出与全规模 critic 模型相当或更优的性能。该估计器展现出强大的泛化能力,尤其在代码生成和指令遵循任务中,其在相关性上优于 critic 模型且误差更低。在训练期间,该估计器保持稳定并与不断演化的策略保持良好校准,在不同模型规模和领域间表现一致。
作者在数学推理基准上评估了所提方法 POISE,使用了两种模型规模,展示了与最先进基线相当的性能,同时实现了更快的训练速度和更稳定的优化。该方法用轻量级内部状态价值估计器替代了组相对基线估计,该估计器采用在线训练,并在整个训练过程中持续与不断演化的策略保持校准。估计器使用策略隐藏状态和熵的特征,其设计对超参数和探针架构的变化具有鲁棒性。POISE 在使用轻量级内部状态价值估计器的同时,达到了与最先进强化学习算法相当的性能。与基线相比,该方法训练速度更快,优化过程更稳定,整个训练期间的梯度范数更低。内部状态价值估计器持续与不断演化的策略保持校准,并在优势计算中提供一致的方差降低。
作者在多个领域和策略模型上,将轻量级内部状态价值估计器与单独训练的 critic 进行了对比。结果表明,所提估计器在平均绝对误差和皮尔逊相关系数方面均取得了具有竞争力或更优的性能,尤其在非数学领域表现突出,同时所需计算开销显著降低。该估计器在整个训练过程中保持稳定并与策略良好校准,证明了其在为强化学习提供可靠价值信号方面的有效性。所提估计器在多个领域(尤其是代码生成和指令遵循任务)中,性能达到或优于更大规模的 critic 模型。该估计器仅使用策略前向传播的内部状态特征,即以较低的计算成本维持稳定性能。估计器在训练期间展现出一致的校准效果和方差降低,表明其作为策略优化基线的可靠性。
作者使用两种模型规模(Qwen3-4B 和 DeepSeek-R1-Distill-Qwen-1.5B),在奥林匹克级别数学推理基准上评估了方法 POISE,并将其与 DAPO 基线进行对比。结果表明,POISE 在大多数基准上达到了与 DAPO 相当或略优的性能,在特定任务上有所提升,同时展现出更快的训练速度和更稳定的优化过程。该方法利用轻量级内部状态价值估计器提供稳定基线,从而降低训练方差并减少计算时间。POISE 在不同模型规模的多个数学推理基准上,性能达到或略优于 DAPO。POISE 通过使用提供稳定基线的轻量级内部状态价值估计器,缩短了训练时间并提升了优化稳定性。内部状态估计器持续与不断演化的策略保持校准并降低奖励方差,从而带来更稳定的训练动态。
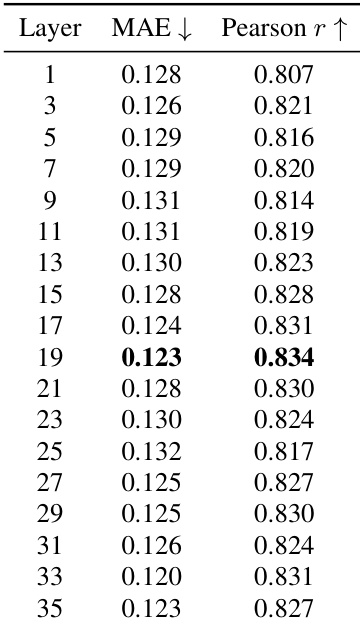
{"summary": "作者分析了不同 transformer 层索引对其价值估计器性能的影响,该估计器利用内部状态特征来预测验证器奖励。结果表明,性能随层的选择而变化,第 19 层实现了最低的平均绝对误差和最高的皮尔逊相关系数,表明其提供了最准确且相关性最强的预测。估计器在相邻层间的性能保持相对稳定,说明其对层的选择具有鲁棒性。", "highlights": ["第 19 层为价值估计器实现了低平均绝对误差与高皮尔逊相关系数的最佳平衡。", "性能在各层间保持稳定,在最优层附近误差和相关性的变化极小。", "估计器的准确性对层的选择敏感,但在一定范围的层内均能保持强劲性能。"]}
实验在多样化领域、模型规模和 transformer 层配置下,将轻量级内部状态价值估计器与单独训练的 critic 模型及最先进强化学习基线进行了对比评估。这些评估验证了估计器的预测准确性、计算效率以及与不断演化的训练策略的一致性。定性结果表明,所提方法在显著降低计算开销和训练时长的同时,始终能够匹配或超越更重的基线。此外,该估计器在不同任务和架构设置下均展现出稳健的校准效果、稳定的优化动态以及可靠的方差降低能力。