Command Palette
Search for a command to run...
基于量规的在线策略蒸馏
基于量规的在线策略蒸馏
Junfeng Fang Zhepei Hong Mao Zheng Mingyang Song Gengsheng Li Houcheng Jiang Dan Zhang Haiyun Guo Xiang Wang Tat-Seng Chua
摘要
策略内蒸馏(On-policy Distillation, OPD)是一种强大的模型对齐范式,但其对教师模型 logits 的依赖限制了其在白盒场景中的应用。我们认为,结构化的语义评分标准(structured semantic rubrics)可以作为教师 logits 的可扩展替代方案,使得仅依赖教师生成的响应即可实施 OPD。为验证这一观点,我们提出了 ROPD,这是一个基于评分标准的 OPD 基础且简洁的框架。具体而言,ROPD 通过师生对比生成特定于提示(prompt-specific)的评分标准,并利用这些评分标准对学生模型的 rollout( rollout 指在强化学习中对策略进行采样生成的轨迹或响应序列)进行打分,以实现策略内优化。实验结果表明,在大多数场景下,ROPD 的性能优于先进的基于 logits 的 OPD 方法,并将样本效率提升了高达 10 倍。这些结果确立了基于评分标准的 OPD 作为一种灵活、兼容黑盒场景的替代方案,取代了目前主流的基于 logits 的 OPD 方法,并为专有和开源大语言模型(LLM)的可扩展蒸馏提供了一个简单而强大的基线。代码已开源,访问地址为:https://github.com/Peregrine123/ROPD_official。
一句话总结
ROPD 是一种基于评分标准的在线策略蒸馏框架,该框架使用从师生对比中提取的结构化语义评分标准替代教师 logits,用于对学生生成的 rollout 进行评分。该方法在实现黑盒兼容的同时,将样本效率提升最高达十倍,并为对齐专有和开源大语言模型建立了可扩展的基线。
核心贡献
{
"schema_version": "black_opd.rubric.v1",
"contributions": [
"- 本文提出 ROPD,一种基于评分标准的在线策略蒸馏框架,该框架使用结构化的语义评分标准替代受限的教师 logits,从而实现黑盒模型的对齐。",
"- 该方法从师生响应对比中提取特定于提示词的评估标准,并将针对这些标准的加权通过率转换为在线策略奖励,用于直接优化。",
"- 实证评估表明,该方法在大多数场景下均优于先进的基于 logits 的蒸馏方法,将样本效率提升最高达 10 倍,并在多种模型架构上展现出稳健的性能。"
]
}
引言
在线策略蒸馏已成为对齐大语言模型的基础后训练范式,该方法通过使用针对学生生成轨迹的密集反馈替代稀疏奖励来实现对齐。尽管该方法显著提升了样本效率并缓解了暴露偏差,但其传统上依赖于教师 logits 或对齐的 token 空间,将其应用范围限制在白盒环境中,并阻碍了对专有或架构差异较大的模型进行蒸馏。现有的黑盒替代方案试图克服这一局限,但它们依赖于偏好对或标量评估分数等隐式信号,这些信号掩盖了实际的质量标准。本文提出 ROPD,一种基于评分标准的在线策略蒸馏框架,该框架使用从师生对比中提取的显式结构化语义评分标准替代 logit 监督。通过针对这些动态标准对学生 rollout 进行评分,该框架实现了可扩展的黑盒蒸馏,将样本效率提升最高达十倍,并为对齐开源与专有语言模型建立了稳健的基线。
数据集
- 数据集构成与来源: 本文构建了一个结构化问答集合,其中每条数据将核心提示词与两组不同的响应进行配对:参考回答与探索性 rollout。
- 子集详情: 参考组包含作为真实标签的高质量教师响应,而 rollout 组则捕捉了多个学生生成的尝试。教师回答与学生 rollout 的具体数量因样本而异,以反映多样的推理路径与答案分布。
- 训练使用与混合: 本文将这些配对序列直接输入模型进行监督微调与对齐。教师响应指导主要学习目标,而学生 rollout 被混合输入以教授比较推理与自我纠错能力。
- 处理与元数据构建: 每个样本均遵循固定模板,明确标注问题、教师输出与学生 rollout。该格式作为内置元数据,使模型能够区分权威文本与生成文本。完整序列被保留且未进行裁剪,以维持完整的上下文与推理链。
方法
本文采用一个两阶段框架用于基于评分标准的在线策略蒸馏,旨在实现从教师模型到学生模型的知识迁移,且无需访问教师内部的 token 级输出。整体架构在完全黑盒模式下运行,教师模型、Rubricator 与 Verifier 仅通过文本提示词与结构化 JSON 输出进行访问,不接触任何内部 logits 或隐藏状态。如图下方所示,流程始于输入问题 x,教师与学生模型分别独立处理该问题以生成一组 rollout。教师模型生成 m 个响应 YxT={yjT}j=1m,而学生模型从其当前策略 πθ 生成 n 个 rollout YxS={yiS}i=1n。这些 rollout 随后被输入至 Rubricator 模块,该模块综合生成一个共享的、特定于问题的评分标准集合 Cx={ck}k=1K。每个评分标准项 ck 包含一个文本标准 ρk 及其关联的重要性权重 wk>0,这些内容源自对师生响应的对比分析。该评分标准旨在捕捉教师行为中一致的质量维度,同时识别学生输出中的系统性弱点,确保标准具体、可衡量,且能在单个响应上独立评估而无需参考其他响应。
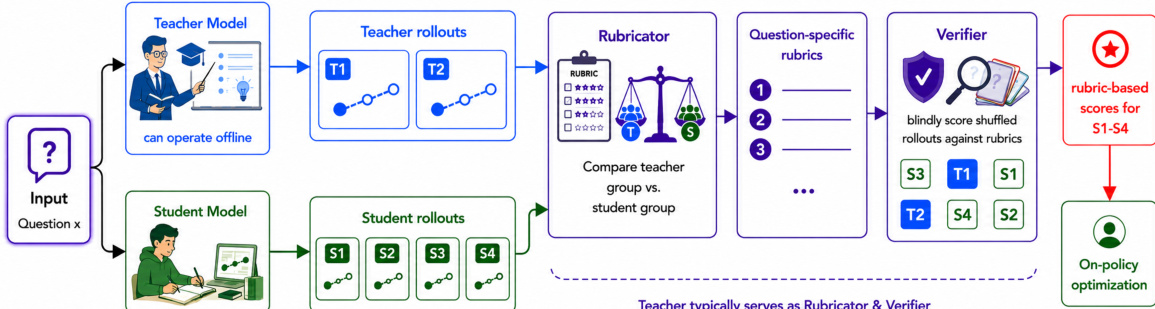
生成的评分标准集合随后由 Verifier 用于针对各项标准评估每个学生 rollout。针对每个学生响应 yiS 与评分标准项 ck,Verifier 会生成一个二元判断 vi,k∈{0,1},指示该响应是否满足标准。响应级得分 si 计算为加权通过率 ∑k=1Kwkvi,k/∑k=1Kwk,该得分作为在线策略优化的奖励信号。该奖励计算设计具备对不同题目难度的鲁棒性:Verifier 以盲评方式同时为教师与学生 rollout 打分,从而校准因任务复杂度差异产生的任何偏差。该框架采用组相对策略优化(GRPO)来更新学生策略,该方法基于奖励的均值与标准差对组内每个 rollout 的优势进行归一化,从而避免使用独立的值函数。如算法 1 所述,最终训练流程迭代执行 rollout 收集、评分标准生成、奖励计算与学生策略参数更新,即使在黑盒设置下也能实现高效且有效的蒸馏。
实验
评估设置采用数学与科学基准测试,涵盖黑盒与白盒蒸馏两种场景,以验证该方法将复杂推理能力从教师模型迁移至学生模型的能力。实验结果表明,引入评分标准的监督方法持续优于静态与基于 logits 的基线方法,其通过将响应质量分解为可验证的标准,直接对齐逻辑正确性,而非表面上的风格模仿。此外,该方法展现出更优的数据效率、稳定的收敛性以及稳健的跨架构泛化能力,证实了基于结构化标准的指导能有效规避传统蒸馏瓶颈,同时保持广泛的指令遵循对齐能力。
实验设置在数学、科学与医学赛道中采用一致配置,黑盒场景下学生模型为 Qwen3-4B,教师模型为 GPT-5.2-chat-latest。训练利用共享超参数的 GRPO,ROPD 特定设置(如多个教师回答与评分标准项)在各领域统一应用。硬件配置包含 8 张 A100-80GB GPU,解码参数在无思考模式与思考模式下保持一致。该实验在数学、科学与医学赛道中采用一致设置,以 Qwen3-4B 作为学生模型,GPT-5.2-chat-latest 作为教师模型。ROPD 特定参数(如多个教师回答与评分标准项)在所有领域统一应用。训练与解码超参数在各赛道间共享,硬件配置统一为 8 张 A100-80GB GPU。
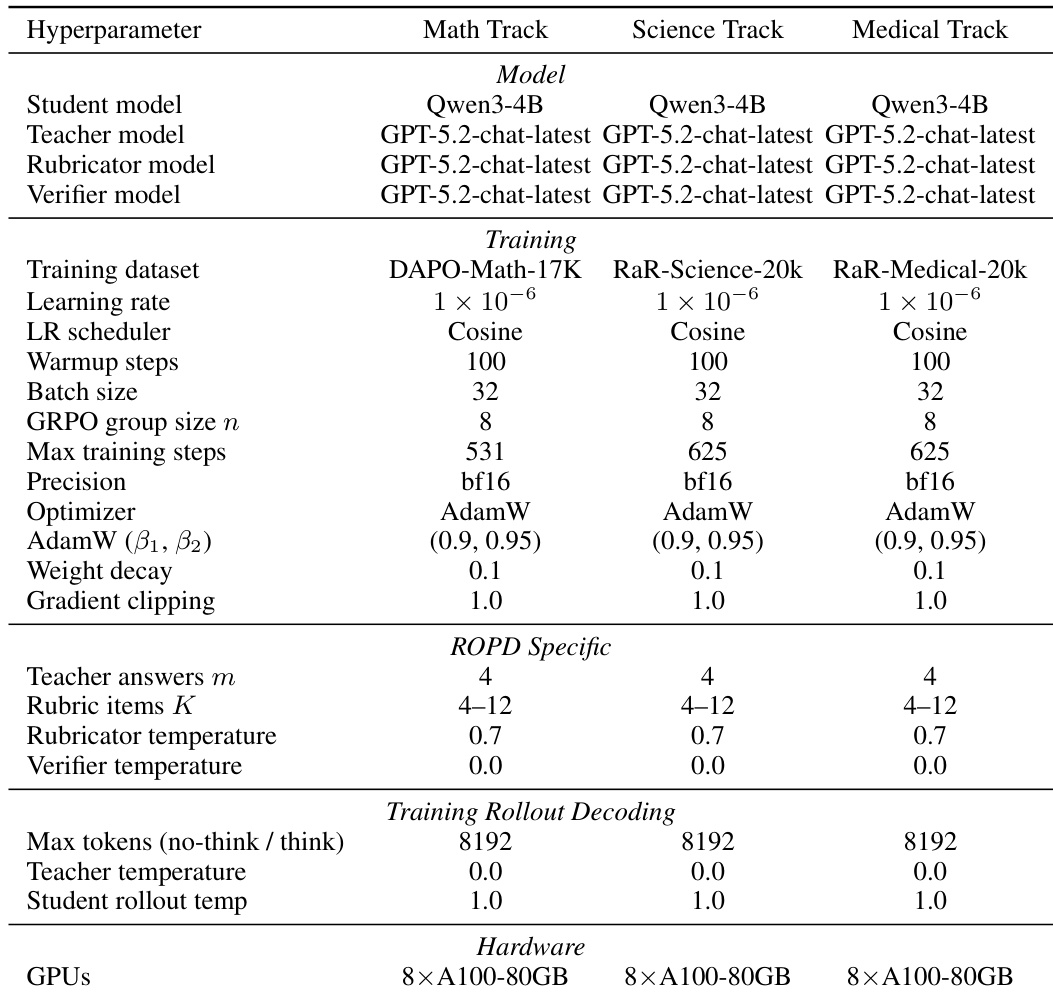
本文通过在主要实验的相同条件下使用能力较弱的学生模型 Gemma3-4B 进行测试,以评估 ROPD 的跨架构泛化能力。结果表明,ROPD 在所有基准测试中持续提升基础模型的性能,证明即使学生模型能力显著较弱,该方法仍能提供有效监督。该方法在最困难的基准测试 HMMT (Nov.) 上取得显著增益,并在所有领域保持性能提升,表明其具备稳健的迁移能力。ROPD 在所有基准测试(包括最困难的测试)上均较基础模型取得显著性能提升。该方法展现出强大的跨架构泛化能力,即使面对能力显著较弱的学生模型也能保持有效性。ROPD 在所有评估配置中均持续优于基线方法。
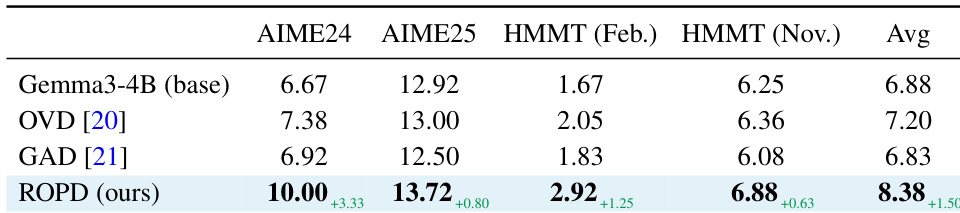
实验评估 ROPD 中不同奖励设计组件对模型性能的影响,采用 AIME24 作为评估指标。结果表明,完整的 ROPD 设置(包含多教师种子注入、跨 rollout 评分标准共享与盲评)取得最高性能,显著超越基础模型及省略其中一项或多项组件的消融变体。完整的 ROPD 设置在 AIME24 上取得最高性能,优于所有消融变体。移除多教师种子注入会导致性能大幅下滑,表明其对生成稳健标准的重要性。省略盲评同样会降低性能,说明带有身份感知的评估会对奖励质量产生负面影响。
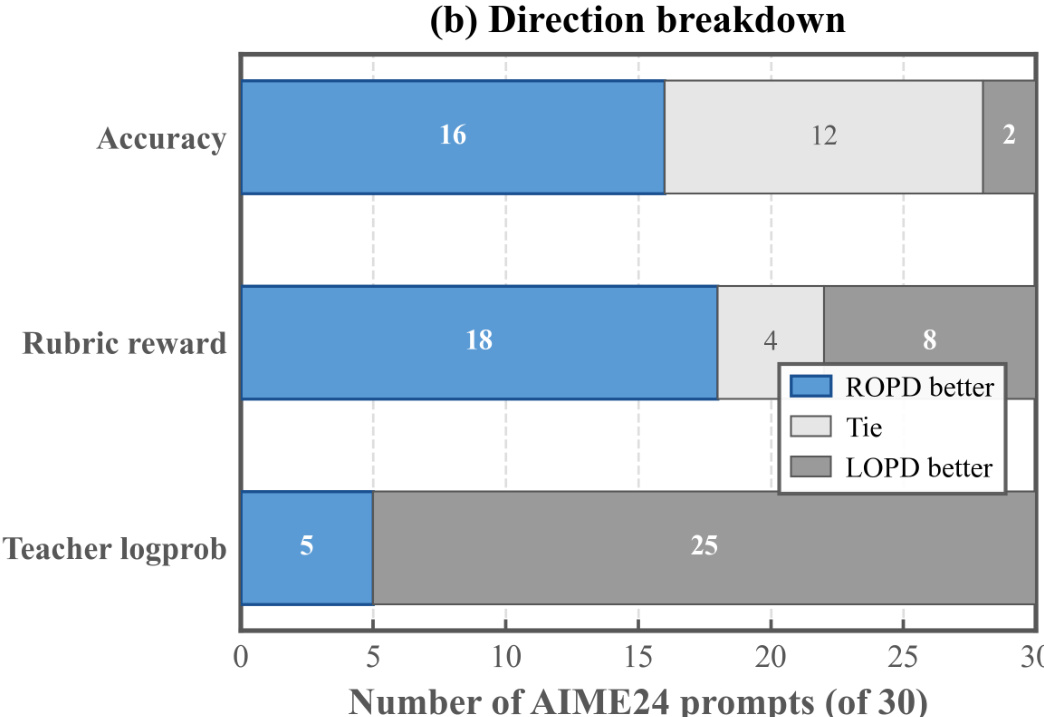
该图展示了 ROPD 与 LOPD 在三项指标(准确率、评分标准奖励与教师 logprob)上的提示词级性能对比分解。ROPD 在大部分提示词上的准确率与评分标准奖励均优于 LOPD,而 LOPD 在教师 logprob 上占据优势。结果凸显了 ROPD 在推理准确率与奖励满意度方面的优越表现,LOPD 在教师 logprob 上得分更高,表明其侧重于模仿教师的输出分布。ROPD 在大部分提示词上的准确率与评分标准奖励优于 LOPD。LOPD 在教师 logprob 上得分高于 ROPD,表明其侧重于模仿教师的输出分布。与 LOPD 相比,ROPD 展现出更优的推理准确率与奖励满意度。
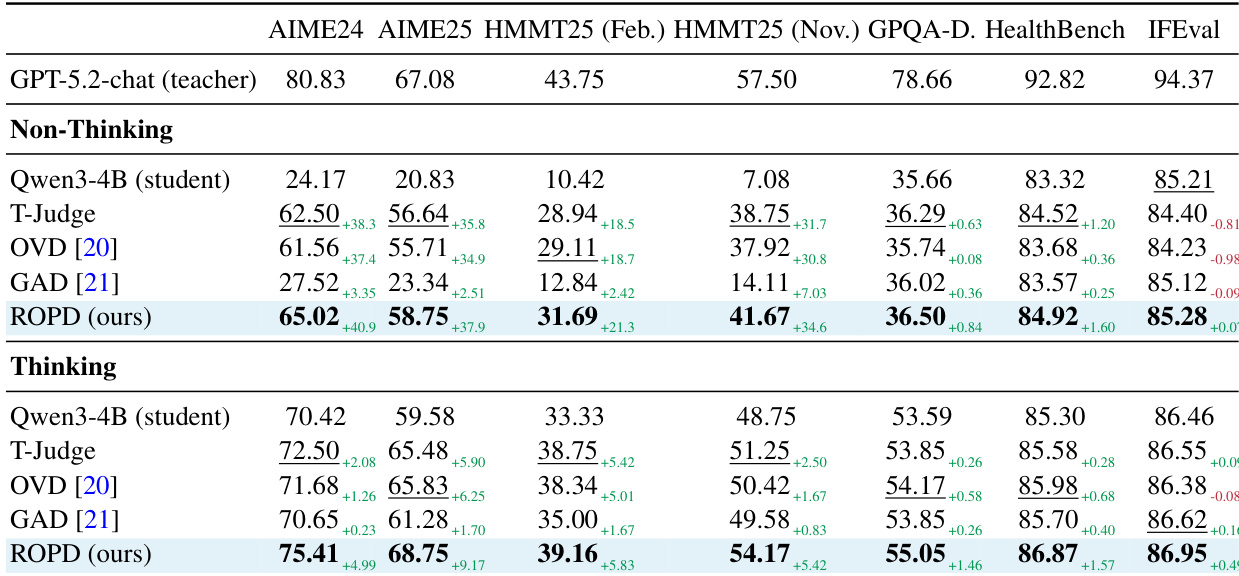
本文在 black-box 与 white-box 设置下评估 ROPD 方法,证明其在多个基准测试中相比基线方法均能实现一致的性能提升。在黑盒场景中,ROPD 在所有基准测试中取得最高分数,显著优于学生模型与其他蒸馏方法,在困难任务上取得显著增益。在白盒设置中,ROPD 仅使用基于文本的教师信息便超越了先进的基于 logits 的方法,展现出更优的数据效率与收敛稳定性。结果表明,基于评分标准的监督相较于密集的 logit 信号能提供更有效且更具区分度的反馈,使学生能够超越对教师的模仿,实现更高的推理准确率。ROPD 在无思考模式与思考模式下于所有基准测试中均取得最高性能,持续优于其他蒸馏方法。与基于 logits 的方法相比,ROPD 展现出更优的数据效率与收敛稳定性,使用显著更少的训练样本即可取得更好结果。基于评分标准的监督使学生能够超越教师模仿,通过聚焦于正确性而非表面模仿来实现更高的推理准确率。
评估在多个 STEM 领域采用一致的黑盒师生框架,利用共享的训练超参数与硬件以评估 ROPD 的有效性。实验结果验证了该方法强大的跨架构泛化能力,即使应用于能力较弱的学生模型也能展现一致的性能提升。消融研究证实,特定的奖励设计组件(尤其是多教师种子注入与盲评)对于生成稳健的评估标准至关重要。此外,与分布匹配基线的对比测试,以及在黑盒与白盒设置下的综合测试表明,基于评分标准的监督能提供更具有区分度的反馈,使学生能够在保持优异数据效率与收敛稳定性的同时,优先关注推理准确率而非表面模仿。