Command Palette
Search for a command to run...
HyperEyes:面向并行多模态搜索代理的双粒度效率感知强化学习
HyperEyes:面向并行多模态搜索代理的双粒度效率感知强化学习
Guankai Li Jiabin Chen Yi Xu Xichen Zhang Yuan Lu
摘要
现有的多模态搜索代理(agents)采用顺序处理目标实体的方式,即对每个实体发出一次工具调用。当查询分解为独立的子检索任务时,这种方法会导致交互轮次冗余的累积。我们认为,高效的多模态 agents 应当“拓宽”而非“拉长”搜索范围:即在单个轮次内并发分发多个基于视觉定位的查询。为此,我们提出了 HyperEyes,这是一种并行多模态搜索 agent,它将视觉定位与检索融合为单一的原子动作,能够在多个实体间进行并发搜索,并将推理效率作为首要的训练目标。HyperEyes 的训练分为两个阶段。针对冷启动监督,我们开发了一套“并行友好型数据合成流水线”(Parallel-Amenable Data Synthesis Pipeline),涵盖视觉多实体和文本多约束查询,并通过渐进式拒绝采样(Progressive Rejection Sampling)构建以效率为导向的轨迹数据。在此基础上,我们的核心贡献是“双粒度效率感知强化学习框架”(Dual-Grained Efficiency-Aware Reinforcement Learning framework),该框架在两个层面上运作:在宏观层面,我们提出了 TRACE(Tool-use Reference-Adaptive Cost Efficiency,工具使用参考自适应成本效率),这是一种轨迹级奖励机制。在训练过程中,其参考标准单调收紧,从而在不限制真实的多跳搜索的前提下,抑制多余的工具调用。在微观层面,我们自适应地采用在线策略蒸馏(On-Policy Distillation),从外部教师模型中注入密集的 token 级修正信号,以纠正失败 rollout 中的表现,缓解稀疏结果奖励导致的信用分配不足问题。鉴于现有基准测试仅将准确性作为单一指标,而忽略了推理成本,我们引入了 IMEB,这是一个由人工 curated 的包含 300 个实例的基准测试集,旨在联合评估搜索能力和效率。在六个基准测试中,HyperEyes-30B 在准确性上超过了最强的可比较开源 agent 9.9%,同时平均工具调用轮次减少了 5.3 倍。
一句话总结
HyperEyes 是一款并行多模态搜索 Agent,通过将视觉定位与检索融合为单一原子操作,以并行的多实体检索替代顺序实体处理。该框架采用带有渐进式拒绝采样的并行适配数据合成流水线,以及双粒度效率感知强化学习框架,旨在降低可分解查询的冗余交互轮次。
核心贡献
- 提出 HyperEyes,一款并行多模态搜索 Agent,通过将视觉定位与检索融合为单一原子操作来执行并发多实体查询。
- 建立两阶段训练协议,利用并行适配数据合成流水线与渐进式拒绝采样进行冷启动监督,随后采用双粒度效率感知强化学习框架对冗余工具调用进行惩罚。
- 通过在 FVQA、MMSearch-Plus 和 BrowseComp-VL 上的评估证明,与顺序方法相比,该并行架构在保持检索精度的同时,显著降低了端到端推理延迟与 token 消耗。
引言
多模态搜索 Agent 对于通过主动检索实时信息来突破大语言模型静态知识截止期至关重要,但其实际部署仍受限于高延迟与过高的推理成本。既有框架主要依赖顺序工具调用,当查询自然分解为独立子检索时,会产生严重的交互冗余。即便具备并行能力,以精度为导向的训练目标也会无意中鼓励冗长的过度检索,而非紧凑高效的轨迹。为突破这些瓶颈,研究团队提出 HyperEyes,一款并行多模态搜索 Agent,通过将视觉定位与检索融合为单一原子操作来并发处理多个实体。该系统采用双粒度强化学习框架进行优化,动态收紧轨迹级效率奖励,并注入密集的 token 级修正信号以解决稀疏奖励信用分配问题。此外,研究团队还发布了 IMEB,这是一份由人工精心筛选的基准测试集,联合衡量答案准确率与搜索效率,结果表明该方法在达到最优准确率的同时,将工具调用轮次降低了五倍以上。
数据集
-
数据集构成与来源
- 研究团队构建了包含 271,000 个依赖工具的查询的训练语料库,旨在强制实现并行工具调用与效率感知优化。
- 基础数据池汇总了来自公开基准测试与内部人工标注的 246,000 个多跳推理与视觉识别查询。
- 研究团队通过两条定制流水线补充了 25,000 个新型合成查询:包括 20,000 个视觉多实体问答对与 5,000 个文本多约束查询。
- 统一的工具必要性过滤器会剔除任何 Qwen3-VL-235B 无需外部工具即可解决的问答对,确保所有保留数据均真正需要检索。
-
关键子集详情
- 视觉多实体: 源自细粒度分类数据集,包括 CUB-200-2011、Oxford Flowers-102、Stanford Cars、FGVC-Aircraft 与 Oxford-IIIIT Pets。该流水线为每个类别构建知识库,并利用马赛克增强技术合成包含 2 至 8 个不同类别的图像。问答对要求整合共现实体间的跨实体信息,确保遗漏任一实体均会导致推理失败。
- 文本多约束: 数据源自 Wikidata,采用多跳随机游走收集候选实体。研究团队采样两个或多个谓词,其交集定义唯一的真实标签集合,从而生成满足多个独立属性约束的查询。
- IMEB 基准测试: 由具备博士级水平的标注员精心筛选的 300 个实例专用评估集,平均每张图像包含 4.6 个实体。该基准测试经过双盲交叉验证,以确保问题具有明确的可解性,且严格需要并发工具调用。
-
使用方式、划分与处理
- SFT 数据集: 研究团队将 271,000 个初始查询提炼为 30,000 条高保真轨迹,用于监督微调。
- 渐进式拒绝采样: 研究团队采用 Gemini-3.0-Flash 作为策略模型应用此技术。该方法在递增的交互轮次预算下采样轨迹,并为每个查询保留最短的成功轨迹,从而促进单轮精度与并行执行。
- 难度过滤: 采样前,研究团队会过滤掉 Qwen3-VL-235B 单次即可解决的简单查询,仅保留需要严格多步或并行规划的困难样本。
- 质量过滤: 采样后过滤会剔除存在格式违规、零信息增益、无依据推理、单模态捷径或低效顺序查询的轨迹。
- RL 数据集: 研究团队为强化学习隔离中等难度样本,为 30B 模型选取 6,056 个查询,为 235B 模型选取 9,337 个查询,这些样本在初始模型于 pass@1 下失败但在 pass@5 约束下成功的场景中被筛选出来。这些样本为奖励机制建立了动态效率边界。
-
裁剪策略与元数据构建
- 马赛克布局: 视觉合成采用 2x1、1x4 与 2x4 等布局,将选定类别的图像拼接为复合图像。
- 空间元数据: 流水线为问题合成器提供每个目标实体的空间位置参考(如“左上角”或网格坐标),以便将空间参考与知识内容相融合。
- 统一接地检索: 数据支持一种接地检索机制,模型可指定区域坐标以实现并发定位,示例中使用了坐标数组来指定裁剪区域。
- 知识库构建: 针对视觉查询,研究团队整合了涵盖视觉特征、分类标识与行为特征的每类别结构化知识条目,模型需检索这些信息并将其与空间参考相融合。
方法
HyperEyes 框架作为一个遵循 ReAct 范式的迭代推理与执行 Agent 运行,针对给定查询 q 生成轨迹 τ=(q,(r0,a0,o0),(r1,a1,o1),ldots,(rT,aT,oT),y)。在每一轮 t,Agent 基于累积上下文 ht 生成推理轨迹 rt,从可用的多模态搜索工具中选择工具调用 at,并从检索环境中接收观测结果 ot。该过程持续进行,直至生成最终答案 y 或达到允许的最大轮次 T。
该 Agent 配备两种核心工具:通过 <text_search> 调用的文本搜索工具,用于检索自然语言查询的文本证据;以及通过 <image_search> 调用的图像搜索工具,用于检索接地视觉输入的视觉相关结果。为实现与现实互联网的高效交互,框架引入了统一接地检索(UGS),将视觉定位重构为检索动作的一个参数。这使得策略能够在单轮内跨模态分发并行搜索查询,通过同时预测所有目标实体的边界框,从而消除传统两阶段“先裁剪后检索”流水线中脆弱的依赖关系与顺序瓶颈。
训练过程包含两个主要阶段。第一阶段为并行适配数据合成流水线,负责构建多实体问答对并筛选高效轨迹。该阶段从多样化类别与信息收集开始,涵盖网络搜索与图像增强,以生成问答对。随后通过渐进式拒绝采样对轨迹进行筛选,在此过程中评估检索需求并过滤轨迹以提升效率。第二阶段为双粒度效率感知强化学习算法,用于优化并行搜索行为。该算法采用宏观级奖励与微观级修正信号。
训练分两个阶段进行。首先,监督微调(SFT)阶段通过在筛选后的轨迹语料库上进行下一 token 预测来优化基础多模态语言模型(MLLM)。该阶段通过直接内化单次并行分发来植入基础并行检索行为,从而避免学习迭代查询重构。然而,该方法缺乏针对端到端推理效率的序列级优化。为解决此问题,采用强化学习(RL)阶段,其使用双粒度效率感知强化学习框架。该框架结合宏观级奖励(采用群体相对策略优化(GRPO)与新型参考自适应成本效率(TRACE)奖励)以显式优化工具使用效率,以及微观级信号(在线策略蒸馏(OPD))以提供密集的 token 级修正信号。

TRACE 奖励旨在适配特定查询的效率目标。它由三个部分组成:R=Racc+Rfmt+Rtool,其中 Racc 为二元正确性判定器,Rfmt 对模式解析失败进行惩罚,Rtool 为核心自适应效率奖励。效率由工具调用轮次 tc 与工具调用总数 ts 表征。针对每个中等难度样本,初始参考值 t^c(0) 与 t^s(0) 源自其成功轨迹。训练期间,主轮次参考值 t^c 按 t^c(e+1)=min(t^c(e),tc(e+1)) 逐 epoch 收紧,形成隐式课程。总调用参考值 t^s 同步更新以匹配最小轮次轨迹的工具消耗。随后,TRACE 奖励 Rtool 根据轨迹效率与正确性定义具体的惩罚与正向奖励条件。
关键在于,正向奖励仅分配给落入严格高效区域(tc≤t^c 且 ts≤t^s)的轨迹,从而防止奖励作弊。轮次 tc=0 的正确轨迹获得 Rtool=0 以避免参数化猜测。聚合奖励 Ri 在组内进行归一化,以计算 GRPO 目标的相对优势 A^i=(Ri−μR)/σR。为解决失败 rollout 中的信用分配缺陷,OPD 将冻结教师模型 πteacher 的 token 级监督知识蒸馏至学生模型 πθ,且仅应用于失败轨迹。该方法通过最小化完成 token 上的反向 KL 散度实现,促使学生模型聚焦于教师模型的高概率推理模式。最终学生损失函数结合 GRPO 损失与蒸馏损失,确保成功探索受 TRACE 塑造,同时 token 级修正由 OPD 提供。

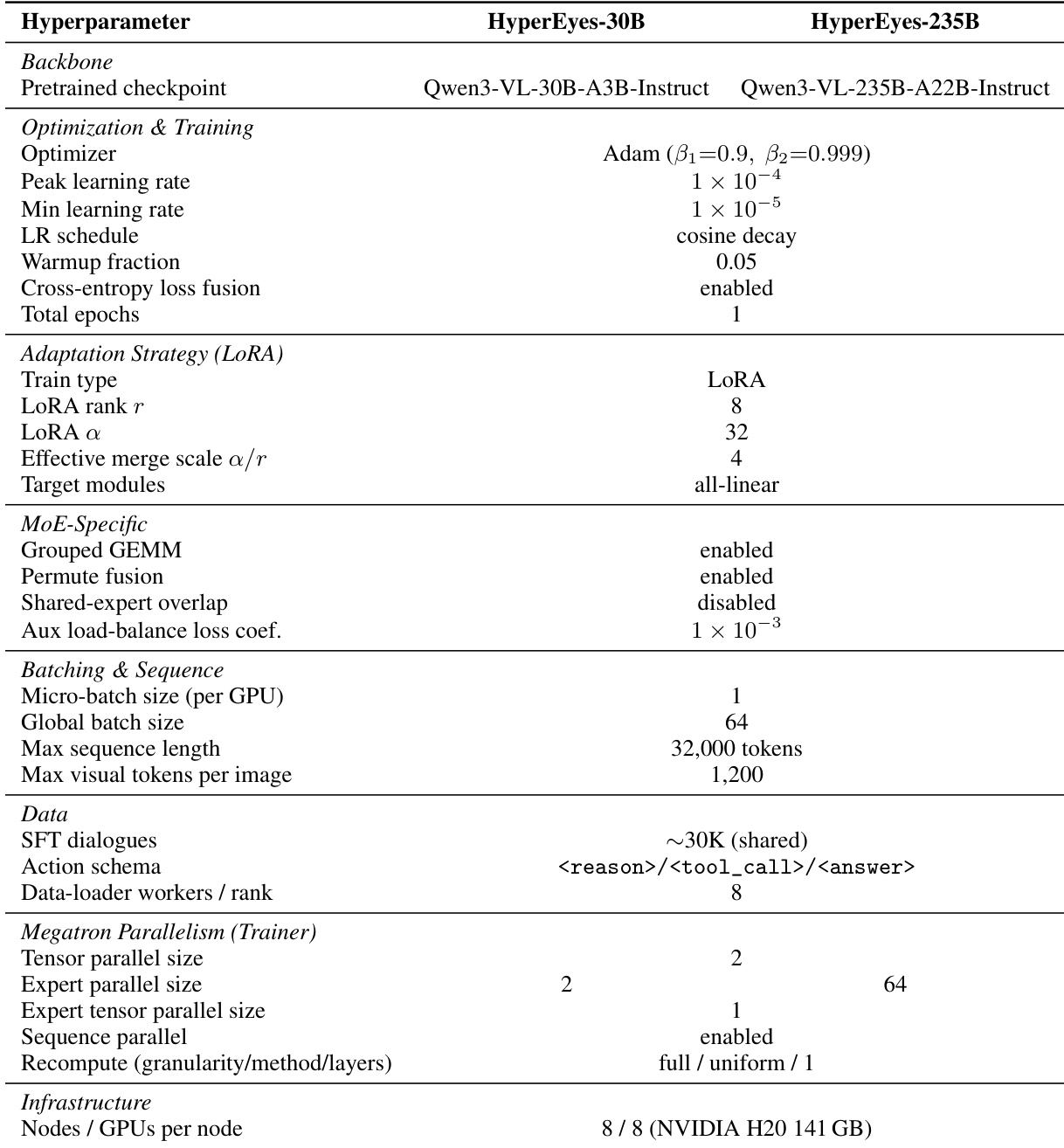
HyperEyes 的训练分两个阶段进行,针对 30B 与 235B 模型规模独立运行,但共享相同的数据配方。在 SFT 阶段,基于 LoRA 的微调在 30,000 条筛选轨迹上执行,使用 Qwen3-VL-30B-A3B-Instruct 与 Qwen3-VL-235B-A22B-Instruct 作为骨干模型。每次 SFT 运行在 8 个节点(64 张 NVIDIA H20-141 GB GPU)上进行,30B 变体约 10 小时收敛,235B 变体约 20 小时收敛。在 RL 阶段,两种变体在中等难度子集上使用提出的 TRACE 奖励结合 GRPO 进一步优化。训练配置在变体间存在差异:HyperEyes-235B (RL) 仅使用 TRACE 训练,并作为 30B 变体的冻结教师模型;而 HyperEyes-30B (RL) 在 TRACE 基础上增加 OPD。RL 阶段对 HyperEyes-30B 耗时约 48 小时,对 HyperEyes-235B 耗时约 72 小时。
搜索后端基于统一异步搜索适配器实现,支持单轮内的并行批量查询。文本搜索后端是由 SerpAPI 驱动的真实网络规模检索服务,封装了 Google Web Search 引擎。图像搜索后端采用 SerpAPI 的 Google 反向图片搜索接口,允许 Agent 在全图或用户指定的归一化裁剪区域上运行。每次 rollout 上限为每轮 8 次工具调用与 9 轮模型交互,检索服务并发请求数限制为 64。两种变体共享相同的生成设置:rollout 由 SGLang 生成,采样温度为 0.8,top-p 为 0.95,提示词最大长度为 15,000 token,单轮响应最大长度为 1,524 token。每张图像最多消耗 1,200 个视觉 token,每次 rollout 最多可附加 50 张图像。
实验
评估涵盖六个多模态搜索基准测试,旨在对比开源与专有 Agent 的准确率与运行效率。主要结果与消融研究验证,并行统一接地检索通过将实体识别与推理解耦,显著优于传统串行检索范式,从而将冗余工具调用与级联错误降至最低。附加实验证实,严格的数据过滤结合自适应强化学习能有效抑制过度检索,同时增强对噪声证据的鲁棒性。最终,这些发现确立了一个高效框架,优化了复杂视觉推理任务中的准确率与效率权衡。
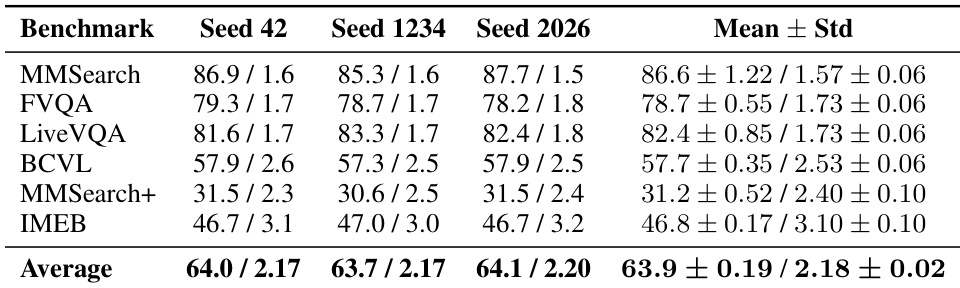
研究团队在不同随机种子下评估 HyperEyes-30B (RL) 模型的鲁棒性,以检验其性能稳定性。结果表明,模型在不同初始化下的准确率与工具调用效率保持一致,所有基准测试的标准差均较低。平均准确率与平均工具轮次保持稳定,表明报告的性能对随机种子的选择不敏感。模型性能在不同随机种子下保持稳定,准确率与工具调用轮次的标准差较低。平均准确率与工具调用效率保持一致,表明对初始化具有鲁棒性。结果证实,报告的数据并非源于有利的随机种子。
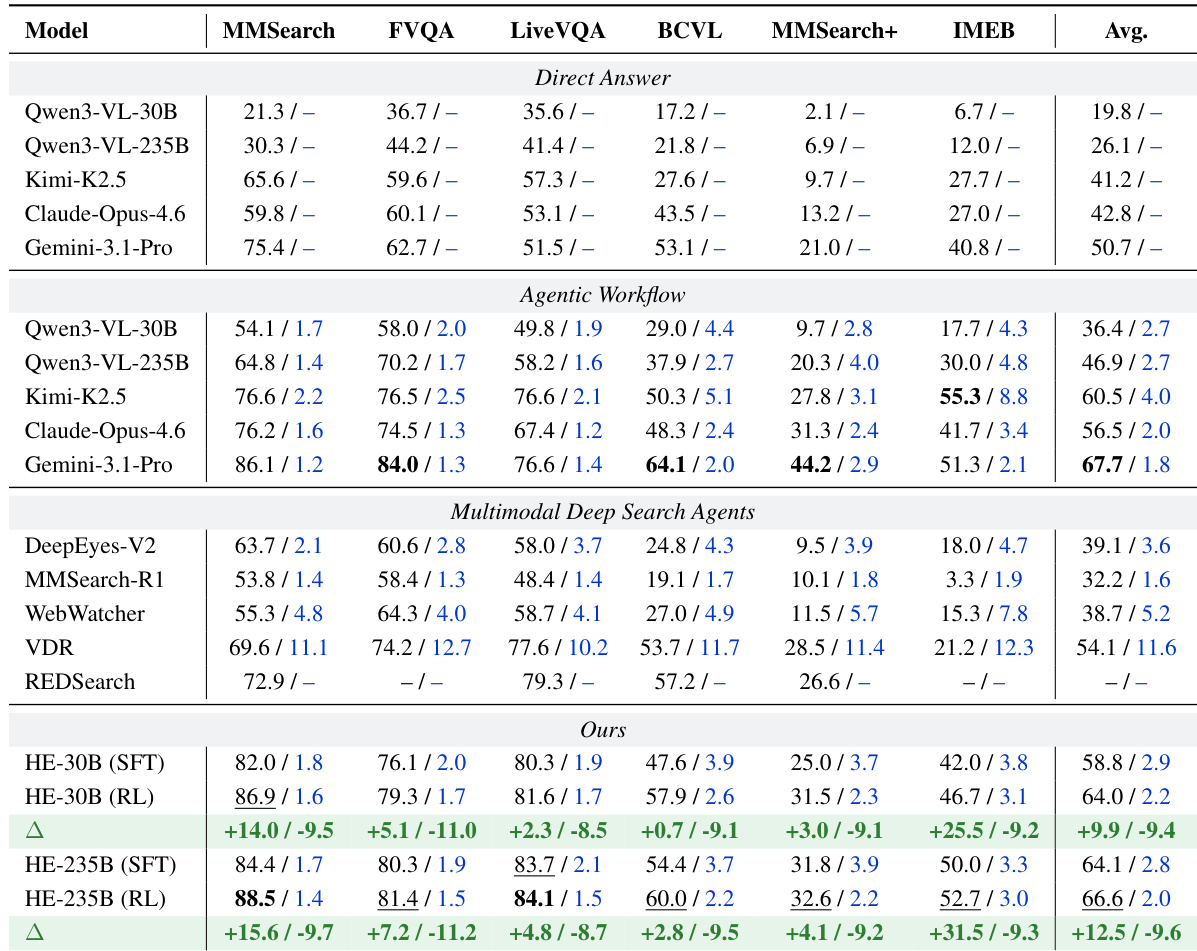
研究团队在六个基准测试上评估了 HyperEyes 这款多模态搜索 Agent,证明其相比现有开源与专有模型实现了更高的准确率与更低的工具调用轮次。结果显示,HyperEyes-235B (RL) 的性能已接近领先商业模型,同时在准确率与效率上显著超越开源 Agent。该框架结合监督微调与强化学习的双阶段训练机制,使其能够以极低的冗余度提供稳健高效的多实体接地检索。HyperEyes 在准确率与工具调用次数上均优于领先的开源与商业模型,为开源搜索 Agent 树立了新标准。强化学习阶段同时提升了准确率并降低了工具调用冗余,证实了自适应效率约束与蒸馏方法的有效性。HyperEyes 展现出卓越的效率与鲁棒性,其并行接地检索范式相比串行方法有效减少了工具使用轮次并提高了准确率。
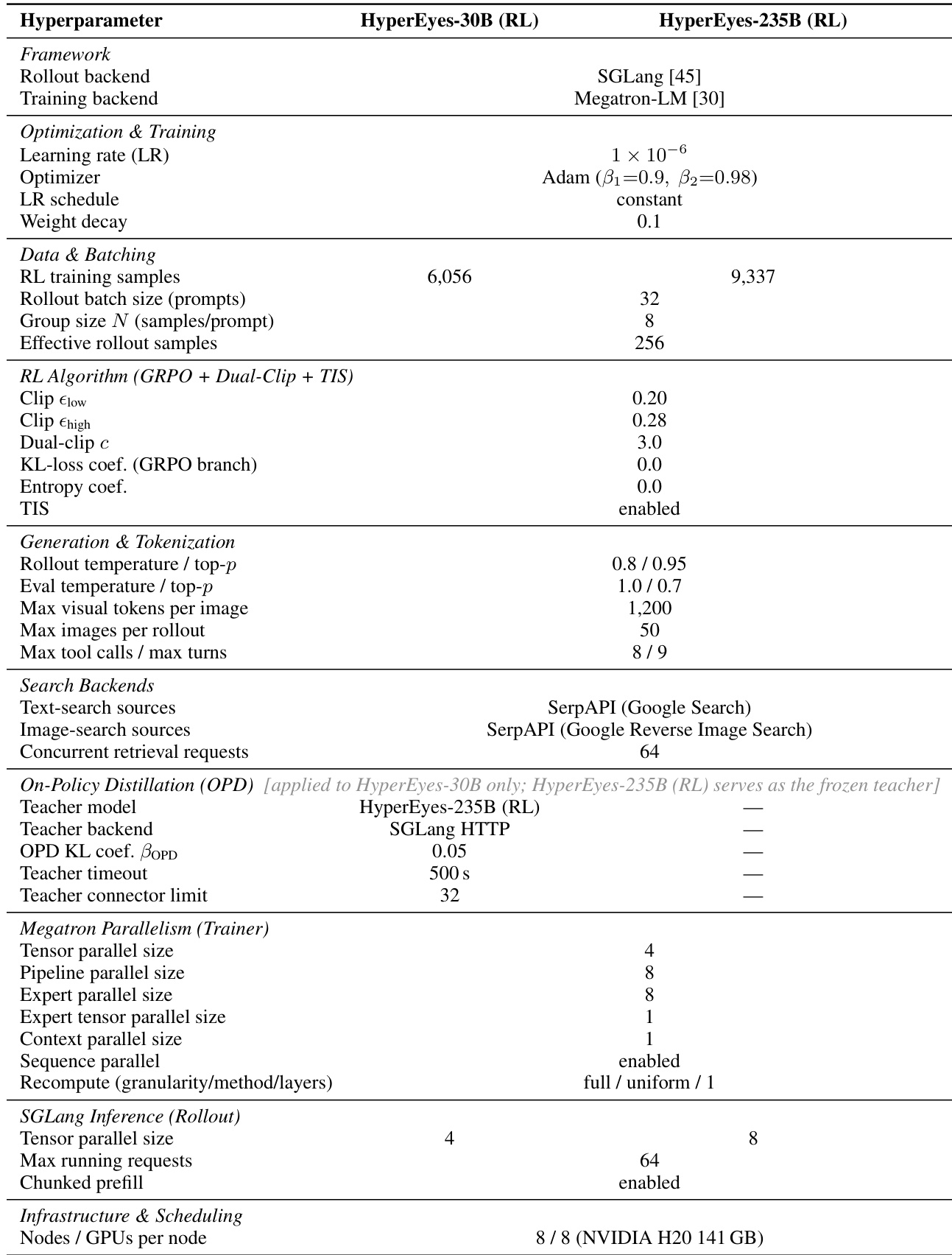
该表格详细说明了 HyperEyes 模型两个变体(HyperEyes-30B (RL) 与 HyperEyes-235B (RL))的超参数与训练配置,突出了其在训练后端、优化设置与强化学习算法组件上的差异。配置显示,较大模型采用不同的训练后端,拥有更多的训练样本与 rollout 批次大小,而较小模型则结合了使用独立教师模型的在线策略蒸馏。两种模型均利用包含双裁剪与 TIS 的相似强化学习框架,但在推理与训练并行策略上存在差异。与 HyperEyes-30B (RL) 相比,HyperEyes-235B (RL) 使用不同的训练后端且具有更大的 rollout 批次大小。较大模型采用带有独立教师模型的在线策略蒸馏,而较小变体未使用此设置。两种模型使用相似的强化学习算法,但在推理与训练并行策略上有所不同,较大模型具备更广泛的并行化能力。
研究团队分析了工具调用预算对模型性能的影响,观察到增加调用次数并不能持续提升准确率,且常导致性能下降。在浅层多跳任务中,准确率在最低预算下达到峰值,随后随调用次数增加而下降;而在复杂多跳任务中,性能在中等预算下达到峰值后回落。工具调用平均数量与设定预算呈线性缩放,表明更高的成本并未带来更好结果,且在特定场景下可能引发性能下降。增加工具调用次数无法提升准确率,常在浅层与复杂多跳任务中导致性能退化。浅层任务的准确率在低预算下达峰,复杂任务在中等预算下达峰,之后均呈下降趋势。平均工具调用次数随设定预算线性增加,证明更高成本并未转化为更优的准确率。

研究团队在多个多模态搜索基准测试上评估了 HyperEyes,并将其性能与各类开源及商业模型进行对比。结果表明,HyperEyes 相比竞品模型实现了更高的准确率与更少的工具调用,在多实体接地检索任务中展现出卓越的效率与有效性。消融研究凸显了数据筛选、结合自适应效率约束的强化学习,以及来自效率对齐教师模型的蒸馏的重要性。HyperEyes 在多个基准测试上均实现了优于竞品模型的准确率与更少的工具调用。强化学习阶段同时提升了准确率与效率,在减少冗余工具使用的同时增强了性能。数据筛选与来自效率对齐教师模型的蒸馏对实现高性能至关重要。
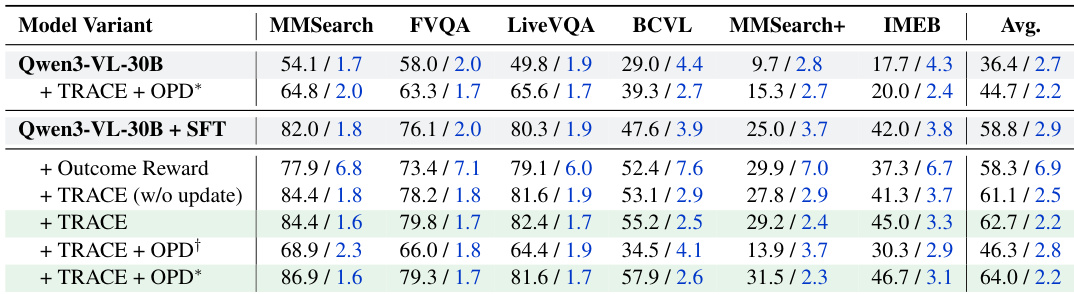
研究团队在多个多模态搜索基准测试上评估了 HyperEyes,以验证其相比现有开源与商业模型的准确率与效率。跨随机种子的稳定性测试证实该框架对初始化具有鲁棒性,而消融研究则表明双阶段训练、自适应效率约束与教师模型蒸馏对达到最优性能至关重要。此外,工具调用预算分析显示,性能在低至中等检索限制下达到峰值,过度使用会导致性能下降,从而证实了受限工具策略的必要性。综合而言,这些实验确立了 HyperEyes 作为一款高效且鲁棒的搜索 Agent,成功实现了高准确率与极低运行开销之间的平衡。