Command Palette
Search for a command to run...
超越推理:强化学习解锁大语言模型中的参数化知识
超越推理:强化学习解锁大语言模型中的参数化知识
Wanli Yang Hongyu Zang Junwei Zhang Wenjie Shi Du Su Jingang Wang Xueqi Cheng Fei Sun
摘要
强化学习(RL)在大语言模型(LLM)推理方面取得了显著成功,但其是否也能提升参数知识的直接回忆能力,仍是一个未解之谜。我们在一个受控的零样本、单跳、闭卷问答设置中研究了这一问题,该设置不使用思维链(chain-of-thought),仅基于二元正确性奖励进行训练,并应用事实级别的训练-测试去重,以确保所获得的提升反映的是回忆能力的提高,而非推理或记忆能力的增强。在三个模型家族和多个事实性问答基准测试中,强化学习带来了约27%的平均相对增益,超越了训练时和推理时的基线方法。从机制上看,强化学习主要是在现有知识上重新分配概率质量,而非获取新的事实,它将正确答案从低概率尾部转移至可靠的贪婪生成中。我们的数据归因研究表明,最困难的样本最具信息量:那些答案在128个强化学习前样本中从未出现的样本(仅占训练数据的约18%)贡献了约83%的增益,因为在训练过程中仍会出现罕见的正确 rollout 并得到强化。综上所述,这些发现拓宽了强化学习在推理之外的作用,将其重新定位为一种解锁而非获取潜在参数知识的工具。
一句话总结
在受控的零样本、单跳、闭卷问答框架内,通过应用事实级别的训练-测试去重与二元正确性奖励,强化学习在多个模型系列与基准测试中实现了约27%的平均相对提升。该方法通过重新分配现有参数化知识的概率质量来解锁潜在的记忆能力,而非获取新事实,且无需思维链推理,从而将此项技术重新定位为超越复杂推理的事实准确性强大工具。
核心贡献
- 本研究提出了一种受控的零样本、单跳、闭卷问答框架,利用二元正确性奖励与严格的事实级别训练-测试去重机制,隔离出直接参数化知识召回过程。该设计明确排除了性能提升源于思维链推理或记忆伪影的可能性。
- 机制分析表明,强化学习通过重新分配现有参数化知识的概率质量来增强事实召回,而非获取新信息。这种训练动态放大了罕见的正确输出轨迹,将准确答案从低概率输出尾部转移至可靠的贪婪生成中。
- 在三个模型系列与多个事实问答基准上的评估显示,该方法相较于既定基线实现了约27%的平均相对提升。数据归因分析进一步表明,仅占训练数据18%的困难样本贡献了约83%的总性能提升。
引言
大语言模型依赖直接的事实召回,但经常无法提取已编码在参数中的信息,导致模型所知与所表达之间存在持续差距。尽管强化学习已成功优化多步推理,但此前改善事实召回的努力依赖于推理时的提示或训练时的对齐方法,这些方法要么无法泛化至未见查询,要么需要显式的推理链。该工作利用带有二元正确性奖励的强化学习,测试强化学习是否可直接优化非推理型知识检索。研究证明,强化学习通过重新分配模型的输出分布,显著提升了闭卷事实准确性,有效将已编码但低概率的答案转化为可靠的贪婪生成。结果表明,强化学习解锁了潜在的参数化知识而非获取新事实,且最困难的训练样本推动了大部分性能提升。
数据集
- 数据集构成与来源: 该工作使用四个事实问答基准进行测试:Natural Questions、TriviaQA、PopQA 与 SimpleQA。
- 子集详情与划分: 针对原本各包含超过80,000个训练示例的 Natural Questions 与 TriviaQA,该工作随机采样10,000个实例用于训练,并保留一小部分验证集。由于 Natural Questions 缺乏官方测试集且 TriviaQA 测试标注未公开,原验证集划分被重新用作测试集。针对仅提供单一评估集的 PopQA 与 SimpleQA,数据被随机划分为训练、验证与测试子集。
- 处理与元数据构建: 为确保评估的严谨性,该工作实现了一个基于大语言模型的去重流水线,将测试问题与候选训练示例进行比对。模型生成包含
is_contained标志与推理字段的结构化 JSON 元数据,以区分精确的事实同义改写与答案匹配但主体实体不同的情况。该过滤过程在保留事实泛化示例的同时,消除了冗余的语义重叠。 - 使用与评估策略: 整理后的数据划分同时用于模型训练与基准测试。在评估环节,采用大语言模型作为裁判的框架,将预测答案与标准答案进行比对。评估提示词基于语义等价性强制执行严格的二元评分(正确为1.0,错误为0.0),所有输出均限制为数值,以统一各基准的评分标准。
方法
该工作利用强化学习(RL)框架增强大语言模型(LLM)的直接事实召回能力,聚焦于无需中间推理步骤的零样本、单跳、闭卷问答。问题设定限制模型直接生成简洁答案,确保任何性能提升均归因于事实召回能力的增强,而非推理能力。模型参数化为 πθ,针对给定查询 q 生成答案 a∼πθ(⋅∣q),正确性由二元指示器 E(a,a∗) 判定。训练过程采用组相对策略优化(GRPO),通过在轨迹组内进行相对奖励比较来计算优势值,从而无需单独的价值网络。该方法特别契合事实召回的结果导向特性,其奖励为基于正确性的二元值。

如图所示,直接事实问答设置采用提示词指导模型生成单一简洁答案,不包含推理步骤。该非思维链(non-CoT)约束旨在将事实召回效果与推理轨迹隔离。相比之下,CoT 设置包含鼓励逐步推理的提示词,随后生成最终答案,该设置作为基线用于评估推理对性能的影响。
强化学习过程中的奖励函数为二元形式,正确答案奖励为1,否则为0。正确性采用基于大语言模型的语义验证进行评估,而非精确字符串匹配,此举可防止奖励稀疏性,并确保语义正确的答案得到恰当识别。该验证流程详见附录 D。强化学习训练在所有模型-数据集组合中保持统一的超参数配置,以确保鲁棒性与泛化能力。具体而言,学习率设置为 1×10−6,全局批大小为128,训练轮数为8。策略目标包含 β=0.001 的 KL 散度正则化系数与 ϵ=0.2 的 PPO 裁剪比例。轨迹生成使用 vLLM,温度参数为 T=1.0,top-k=−1,top-p=1.0,每组查询生成 n=5 个样本。

实验
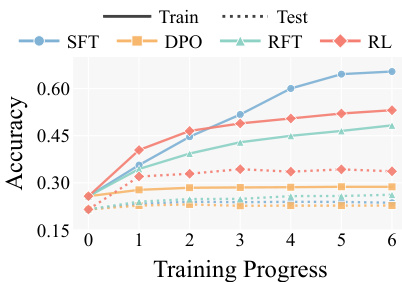
该评估在多个事实问答基准上利用三个开源大语言模型系列,在严格数据去重条件下对比强化学习与监督微调、偏好优化及推理时扩展策略。实验验证证实,基于策略的探索结合对比反馈独特地增强了直接事实召回,持续超越离线训练基线与测试时采样技术。定性分析表明,强化学习作为潜在知识优化器运行,通过系统重新分配概率质量来修复并放大被抑制的参数信号,训练提升主要由初始难以访问的样本驱动。这些发现共同确立强化学习在模型架构、数据集与算法变体上具有强泛化能力,可在不依赖思维链推理或外部知识注入的情况下增强事实召回。
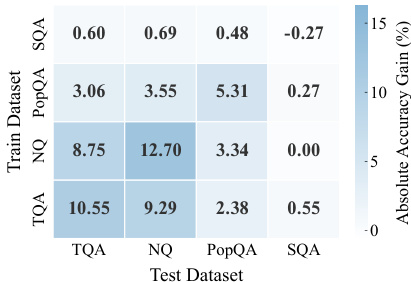
该工作对比了多种用于提升大语言模型事实召回的训练方法,涵盖多个基准与模型系列。结果表明,强化学习在多样数据集与模型架构上均能显著提升准确率,持续优于监督微调与测试时扩展等其他方法。性能提升主要源于增强此前难以检索的潜在知识的可访问性,而非引入新事实。相较于其他训练与推理方法,强化学习在所有评估模型与基准上均带来显著且一致的事实召回改进。强化学习的主要机制为概率质量重新分配,使此前被抑制的正确答案在贪婪解码与随机解码中更易获取。在模型初始难以访问的样本上进行训练可产生最强的学习信号,表明强化学习有效放大了潜在知识,而非依赖易检索的事实。
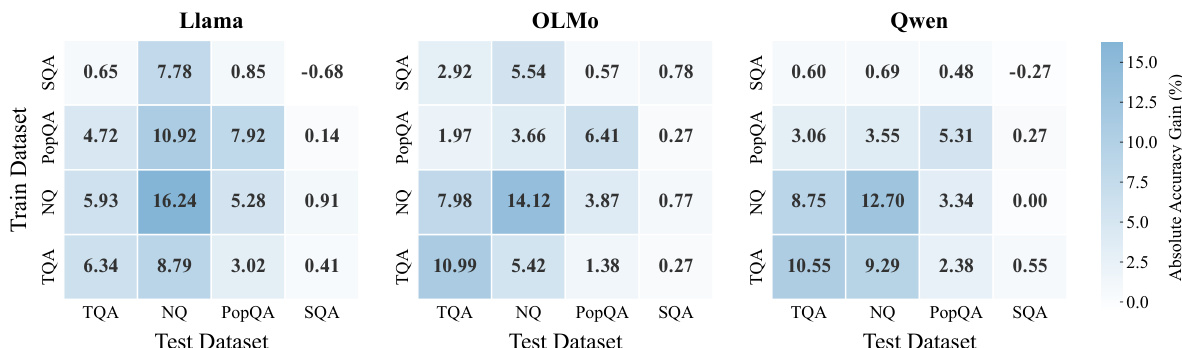
{"summary": "该工作研究了强化学习(RL)在提升多个大语言模型与基准测试直接事实召回方面的有效性。结果表明,强化学习持续优于替代训练与推理时方法,通过增强模型检索此前难以访问的潜在事实知识的能力,实现了准确率的显著提升。该改进在不同模型、数据集与训练配置下均表现稳健,且强化学习在恢复标准解码下初始难以获取的事实方面尤为有效。", "highlights": ["强化学习显著优于监督微调、偏好优化与拒绝采样,证明其在增强事实召回方面的优越性。", "强化学习通过重新分配概率质量改善事实召回,使此前被抑制的正确答案在贪婪解码与随机解码下更易获取。", "最具价值的训练信号来自模型初始无法回忆的事实,表明强化学习具备放大潜在知识的能力,而非依赖易获取的信息。"]
{"summary": "该工作对比了强化学习(RL)与多种训练及推理时基线方法,用于提升大语言模型的事实召回能力。结果表明,强化学习持续优于其他方法,在多个基准与模型上实现显著且持续的准确率提升。性能提升归因于强化学习通过重新分配概率质量放大潜在知识,使此前难以访问的事实更可靠地可被检索。", "highlights": ["强化学习在多个基准与模型上均取得远高于所有基线方法的准确率。", "强化学习通过重新分配概率质量改善事实召回,在不注入新事实的情况下使被抑制的知识更易获取。", "强化学习的优势在不同数据集、模型架构与训练算法下均表现稳健,表明其具备可泛化的优化机制。"]
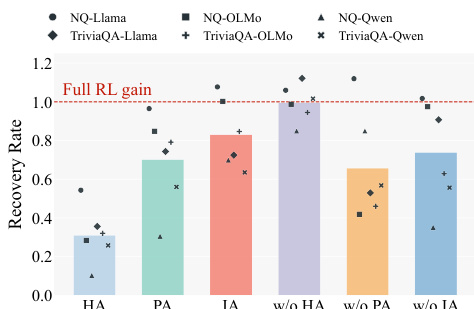
该工作对比强化学习(RL)与多种训练及测试时基线,评估其在提升多个大语言模型与数据集直接事实召回方面的有效性。结果表明,强化学习持续优于所有基线,包括监督微调、拒绝采样与测试时扩展方法,带来显著且稳健的准确率提升。该改进不仅限于域内设置,还可迁移至不同数据集与模型架构,表明事实召回能力得到普遍增强。强化学习在所有测试模型与基准上均达到最高准确率,显著优于其他训练方法。强化学习改善事实召回的机制是多数投票或思维链提示等测试时扩展策略无法复制的。强化学习带来的性能提升在不同数据集、模型规模与架构下均表现稳健,其核心在于模型恢复标准解码下此前难以访问事实的能力。
该工作评估了不同奖励指标对三个语言模型强化学习实验事实召回准确率的影响。结果表明,采用基于大语言模型的裁判进行奖励分配,相较于强化学习前基线与精确匹配奖励指标均带来显著提升,其中 Qwen 模型获得的提升最大。研究指出,奖励函数的选择对强化学习增强事实召回的有效性具有关键影响。基于大语言模型的奖励分配相较于强化学习前与精确匹配奖励设置,均带来实质性准确率提升。Qwen 模型在基于大语言模型裁判的奖励下达到最高准确率,体现了强化学习有效性在不同模型间的差异。相较于基于大语言模型的奖励,精确匹配奖励带来的增益极小,凸显了语义评估在强化学习训练中的重要性。
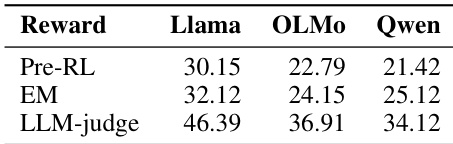
该工作在不同大语言模型与数据集上,将强化学习与多种训练及推理时基线进行对比,以评估其对事实召回的影响。第一组实验验证了强化学习通过重新分配概率质量来检索此前难以访问的潜在知识(而非引入新事实),持续优于替代方法。第二组实验验证了采用基于大语言模型的裁判进行语义奖励分配,相较于僵化的精确匹配标准,显著提升了训练有效性。总体而言,这些发现确立强化学习作为一种稳健且可泛化的方法,可在不同模型架构与解码策略下放大事实召回能力。