Command Palette
Search for a command to run...
连续潜扩散语言模型
连续潜扩散语言模型
摘要
自回归范式下的语言模型取得了显著成功,然而高质量文本生成并不必然受限于固定的从左到右顺序。现有替代方案仍难以兼顾生成效率、可扩展的表示学习以及有效的全局语义建模。为此,我们提出了 Cola DLM——一种分层潜在扩散语言模型,通过分层信息分解来构建文本生成框架。Cola DLM 首先利用 Text VAE 学习稳定的文本到潜在空间映射,随后通过块因果 DiT 在连续潜在空间中建模全局语义先验,最终通过条件解码生成文本。从统一的马尔可夫路径视角来看,其扩散过程执行的是潜在先验传输,而非 token 级观测值的恢复,从而实现了全局语义组织与局部文本实现的解耦。这一设计产生了更加灵活的非自回归归纳偏置,支持连续空间中的语义压缩与先验拟合,并自然延伸至其他连续模态。通过涵盖 4 个研究问题、8 个基准测试、严格匹配的约 20 亿参数自回归基线模型 LLaDA,以及最高约 2000 EFLOPs 的扩展曲线实验,我们确定了 Cola DLM 的有效整体配置,并验证了其在文本生成方面强劲的扩展性能。综上所述,研究结果确立了分层连续潜在先验建模作为严格 token 级语言建模的规范替代方案;在此框架下,生成质量和扩展性能可能比似然值更能反映模型能力,同时也为离散文本与连续模态的统一建模提供了一条具体路径。
一句话总结
该研究提出 Cola DLM,一种分层潜在扩散语言模型。该模型利用 Text VAE 与块因果 DiT 执行连续潜在先验迁移,而非 token 级观测恢复,从而将全局语义组织与局部文本实现解耦,并在八个基准测试中展现出高达约 2000 EFLOPs 的强扩展性,对比严格匹配的约 2B 参数自回归模型与 LLaDA 基线。
核心贡献
- 该研究提出 Cola DLM,一种分层潜在扩散语言模型,将文本生成分解为用于稳定文本到潜在映射的 Text VAE、用于连续语义先验学习的块因果 DiT,以及用于最终输出的条件解码器。
- 该框架将扩散过程重新定义为潜在先验迁移,而非 token 级观测恢复,从而解耦全局语义组织与局部文本实现。此架构建立了一种灵活的自回归归纳偏置,支持连续空间中的语义压缩,并为多模态兼容性提供统一接口。
- 在八个基准测试、四项研究问题以及高达约 2000 EFLOPs 的扩展曲线上的广泛评估,并与严格匹配的约 2B 参数自回归模型及 LLaDA 基线进行对比,验证了该模型的强扩展行为。结果表明,生成质量与扩展轨迹比传统困惑度指标更能可靠地反映模型能力。
引言
大型语言模型长期通过自回归范式主导文本生成,但高质量输出并非必然依赖固定的顺序结构。这一区别至关重要,因为高效、可扩展且语义连贯的生成能力对于推进独立语言系统及未来多模态架构均不可或缺。先前方法难以平衡这些目标,因为自回归模型需承担高昂的序列推理成本,而扩散方法要么受限于昂贵的多步采样,要么未能显式建模全局语义先验。为填补这一空白,该研究提出 Cola DLM,一种分层连续潜在扩散语言模型,将生成过程解耦为全局语义组织与局部文本实现。该框架利用 Text VAE 实现稳定的文本到潜在映射,采用块因果 DiT 进行潜在先验迁移,并通过条件解码器生成最终输出,从而确立了一种灵活的非自回归范式,兼具强扩展特性与通向统一多模态建模的清晰路径。
数据集
-
数据集构成与来源: 模型训练采用外部开源预训练数据。评估阶段则从精心整理的知名开放基准中抽取,涵盖文本续写、阅读理解、事实知识与常识推理。
-
子集详情:
- LAMBADA:长上下文词预测基准,用于测试全局语义建模与长程上下文连贯性。
- MMLU:多任务多项选择基准,涵盖人文、STEM 与专业领域,以评估广泛的事实知识。
- SIQA:三项选择多项选择题基准,专注于社会常识推理与合理情境反应。
- SQuAD:阅读理解数据集,在生成式设置下应用,以评估开放式答案生成。
- Story Cloze:四句故事补全任务,衡量叙事连贯性与因果推理。
- OBQA:科学与常识问答基准,要求超越直接事实回忆的多跳推理。
- RACE:大规模考试型阅读理解测试,侧重推理与文章理解。
- HellaSwag:对抗性多项选择基准,用于接地常识推理与句子续写。
-
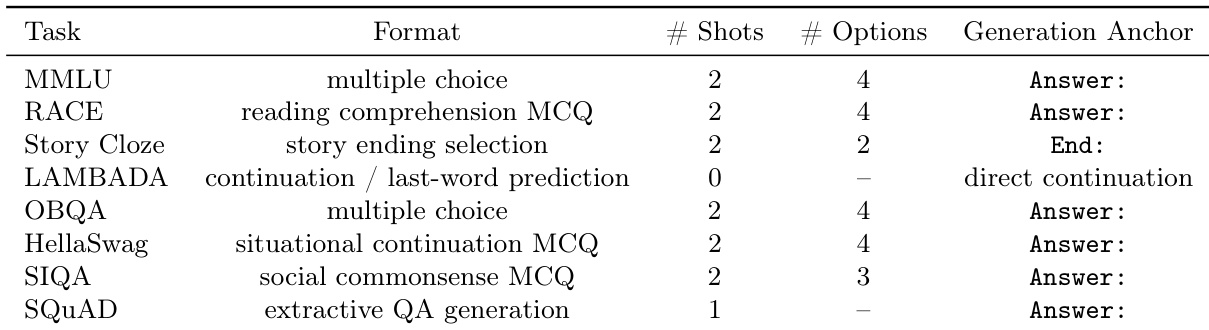
数据使用与处理: 为保持效率与可控对比,内部模型组件评估采用从 LAMBADA、MMLU 和 SIQA 测试集中随机抽样的子集。更广泛的横向对比则使用 SQuAD、Story Cloze、OBQA、RACE 和 HellaSwag 的完整测试集。所有评估均遵循统一的少样本协议,准确率通过预设提示模板下与标准答案的严格字符串匹配进行计算。
-
处理与设置详情: 正文未详述裁剪策略或元数据构建方法,此类数据准备细节已移至附录。训练与评估阶段,所有模型共享 OLMo 2 分词器、最大序列长度 512、相同随机种子及一致的优化调度。所有检查点均在固定 FLOPs 预算下进行评估,且未使用指数移动平均权重,以确保对比的一致性。
方法
Cola DLM 框架被设计为一种分层潜在变量语言模型,将全局语义信息与局部文本实现分离,从而实现灵活高效的文本生成。核心架构利用连续潜在空间对文本进行建模,其中离散文本序列 x 被映射至连续潜在变量 z0。生成过程由条件解码器 pθ(x∣z0) 与潜在先验 pψ(z0) 定义,二者共同构成联合分布 p(x,z0)=pθ(x∣z0)pψ(z0)。先验 pψ(z0) 采用连续流先验建模,由基础分布 p1(z1)=N(0,I) 与时间相关向量场 vψ(zt,t) 定义,后者支配常微分方程 dtdzt=vψ(zt,t)。该流映射诱导产生先验分布 pψ=(Φ0←1ψ)♯p1。潜在空间进一步被分解为多个块,z0=(z0(1),…,z0(B)),并采用因式分解 pψ(z0)=pψ(z0(1))∏b=2Bpψ(z0(b)∣z0(<b)),对应模型中使用的块因果先验学习与推理机制。

模型训练分为两个独立阶段。第一阶段预训练 Text VAE 以建立稳定的文本与潜在映射关系。编码器将文本映射至潜在空间,解码器则基于潜在变量重构原始文本。该目标函数 LVAE 包含重构损失、KL 散度正则化以及类 BERT 掩码损失,以防止 VAE 发生语义坍塌。VAE 并非最终的生成先验,而是用于稳定文本与潜在表示之间的接口。第二阶段联合预训练 Text VAE 与 Text DiT(扩散Transformer),以在稳定后的潜在空间上学习条件先验。Text DiT 采用 Flow Matching 目标 LFM 学习块级条件先验,通过将向量场 vψ 回归至从聚合后验 qˉϕ 到基础分布 p1 的桥路径上速度场的条件均值来实现。该阶段还包含正则化项,用于保持自编码结构并抑制潜在漂移,确保潜在表示与所学流先验之间的可控协同适应。
推理阶段,模型首先将前缀编码为干净的潜在条件。随后逐块生成响应潜在变量,每个块均通过在历史条件下迁移噪声种子获得。解码器基于前缀与生成的潜在块输出文本响应。如下图所示的 Cola DLM 工作流程,通过两个训练阶段与一个推理阶段实现了该分层概率模型,而非 VAE、DiT 与解码器组件的机械级联。
实验
实验在统一的少样本生成协议下,将 Cola DLM 与严格匹配的自回归及离散扩散基线进行对比,系统验证了连续潜在空间中存在全局语义结构。消融研究表明,最优生成依赖于精细校准的噪声调度、适中的处理粒度以及平衡的推理引导,以使去噪过程与语义信息域对齐;扩展性对比则揭示了模型在推理与全局语义任务上的持续性能提升。这些发现共同凸显了基于似然的指标与实际生成质量之间的根本性脱节,证实了潜在空间的语义平滑度与连续先验 formulation 能够驱动稳健且可扩展的语言建模。
实验评估了不同 VAE logSNR 设置在两种计算预算下对模型性能的影响。结果表明,可学习的 VAE logSNR 在两种预算下均稳定优于固定设置,且在高计算预算下达到最高性能。各任务的性能趋势总体一致,表明去噪过程的校准稳定且有效。与固定设置相比,可学习的 VAE logSNR 在所有任务与计算预算下均取得最佳性能。性能随计算预算增加而提升,其中可学习 VAE logSNR 设置带来的增益最为显著。不同 logSNR 设置与计算预算下的任务相对排名保持一致,表明趋势稳定且可预测。
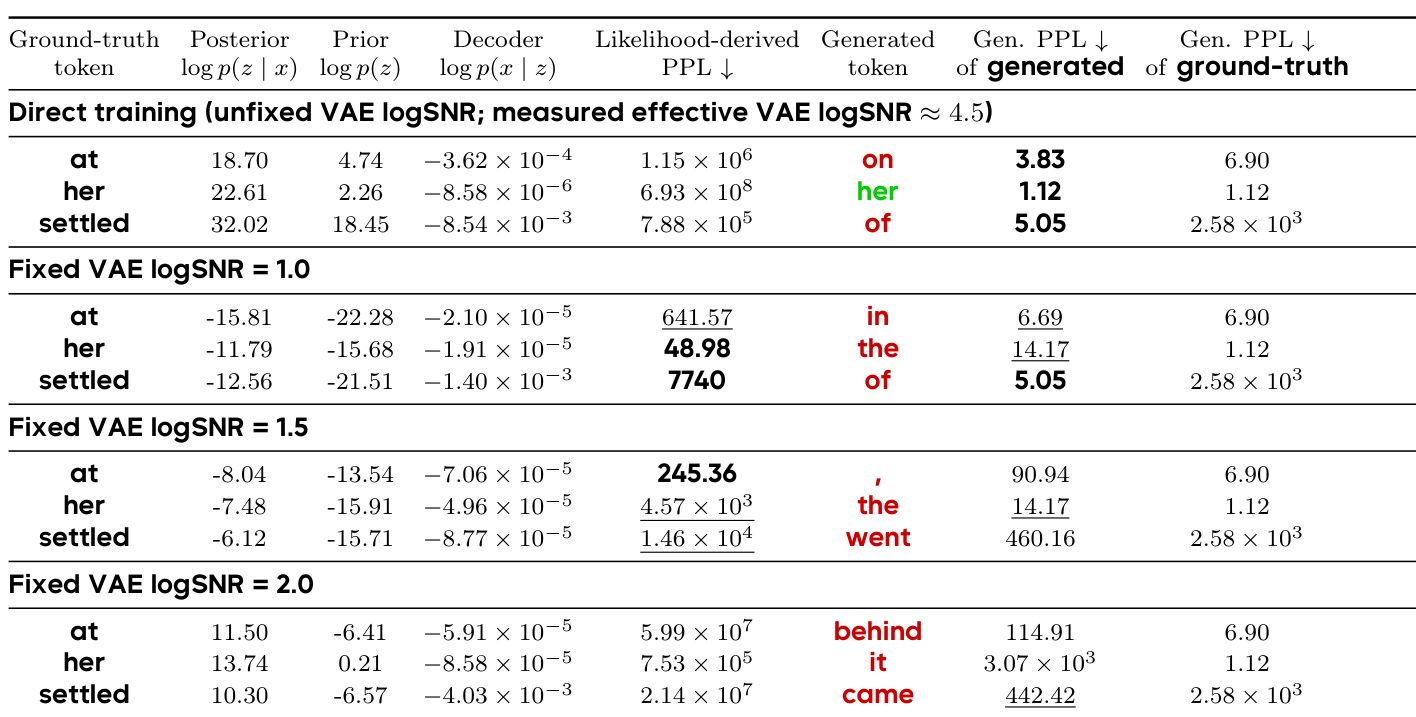
下表展示了不同 VAE logSNR 设置下 token 级生成结果的对比,揭示了潜在空间平滑度变化对似然派生 PPL 与实际生成 tokens 的影响。结果证实了似然估计与生成质量之间存在结构性差距,较低的 PPL 并不必然带来更好的生成效果,表明生成成功更取决于是否抵达语义有效的潜在区域,而非精确的局部概率校准。不同 VAE logSNR 设置下 PPL 值与生成 tokens 的不匹配现象表明,较低的似然 PPL 无法保证更高的生成质量。在不同 VAE logSNR 条件下,生成的 tokens 差异显著,部分设置输出语义合理的文本,而另一些则生成错误或无意义的续写。结果支持生成质量更紧密依赖于潜在空间的语义平滑度,而非由 VAE logSNR 塑造的概率空间平滑度这一观点。
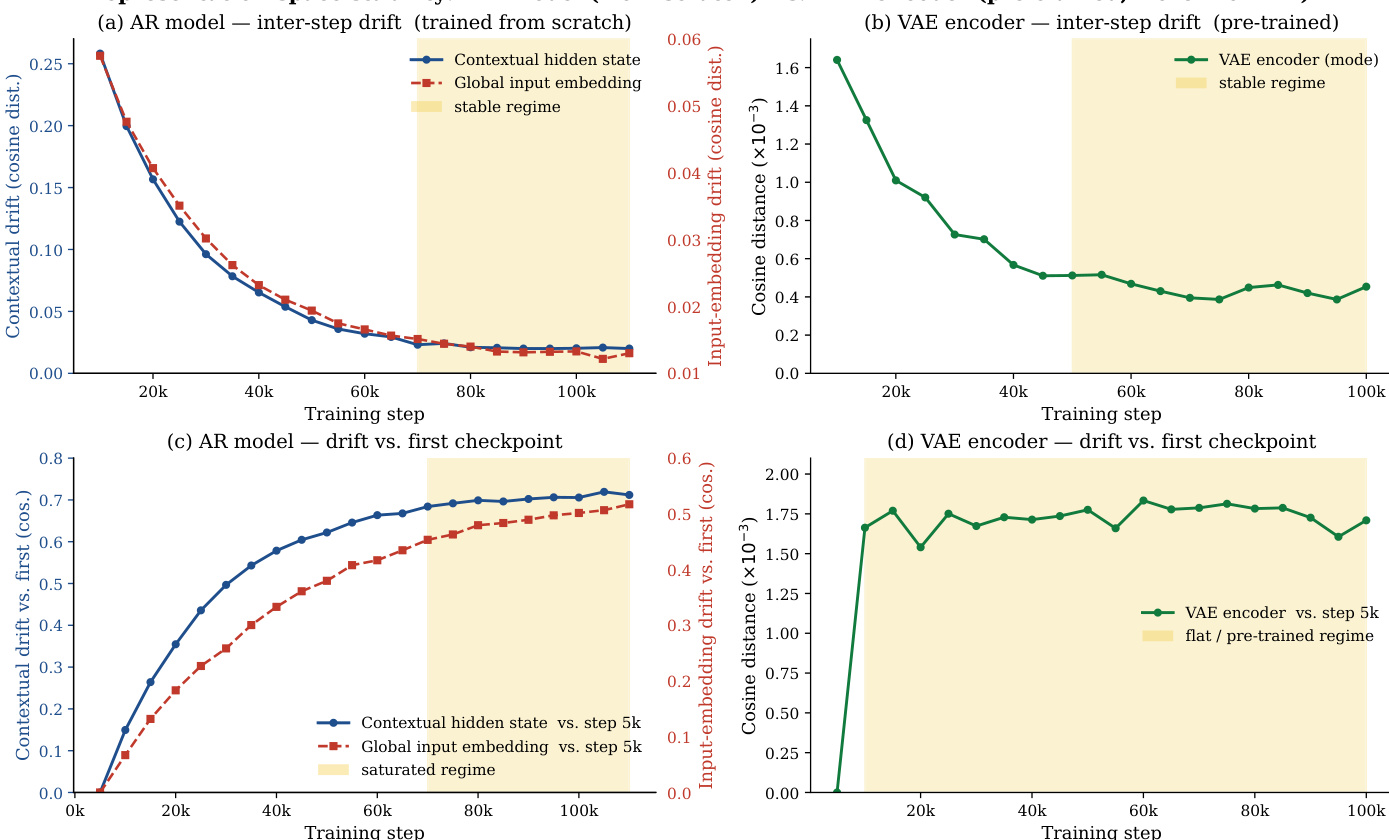
该研究分析了 Cola DLM 潜在空间中最优时间偏移随潜在维度变化的漂移情况,观察到维度增加时系统性地趋向更大值。该趋势在多种语义指标中保持一致,并与理论预测相符,暗示了共享全局语义结构的存在。结果还显示,最优时间偏移在特定训练节点后趋于稳定,不同阶段反映了从初始学习到稳定状态的过渡。最优时间偏移随潜在维度增加系统性地漂移至更大值,进一步支持了共享全局语义结构的存在。漂移趋势在多项语义指标中保持一致,表明其并非单一任务的偶然现象。最优时间偏移在特定训练点后稳定,不同阶段清晰映射了模型学习的不同时期。
下表对比了 Cola DLM 首生成块的不同条件控制与填充策略,评估了其在多项任务中的性能影响。干净条件重绘 consistently 取得最高性能,表明强效且持续的条件控制比局部噪声修正或单纯的位置布局更有效。结果表明,干净条件控制较其他方法带来显著提升,尤其在 LAMBADA 与 SIQA 等语义任务上。干净条件重绘在所有任务中均优于其他条件控制策略,证明其在生成过程中维持提示词条件区域的有效性。局部重绘策略效果明显较弱,且降低接收引导的去噪轨迹比例会进一步损害性能。左右填充策略优于局部重绘,但仍不及干净条件控制,说明仅靠位置布局不足以实现稳定的去噪。

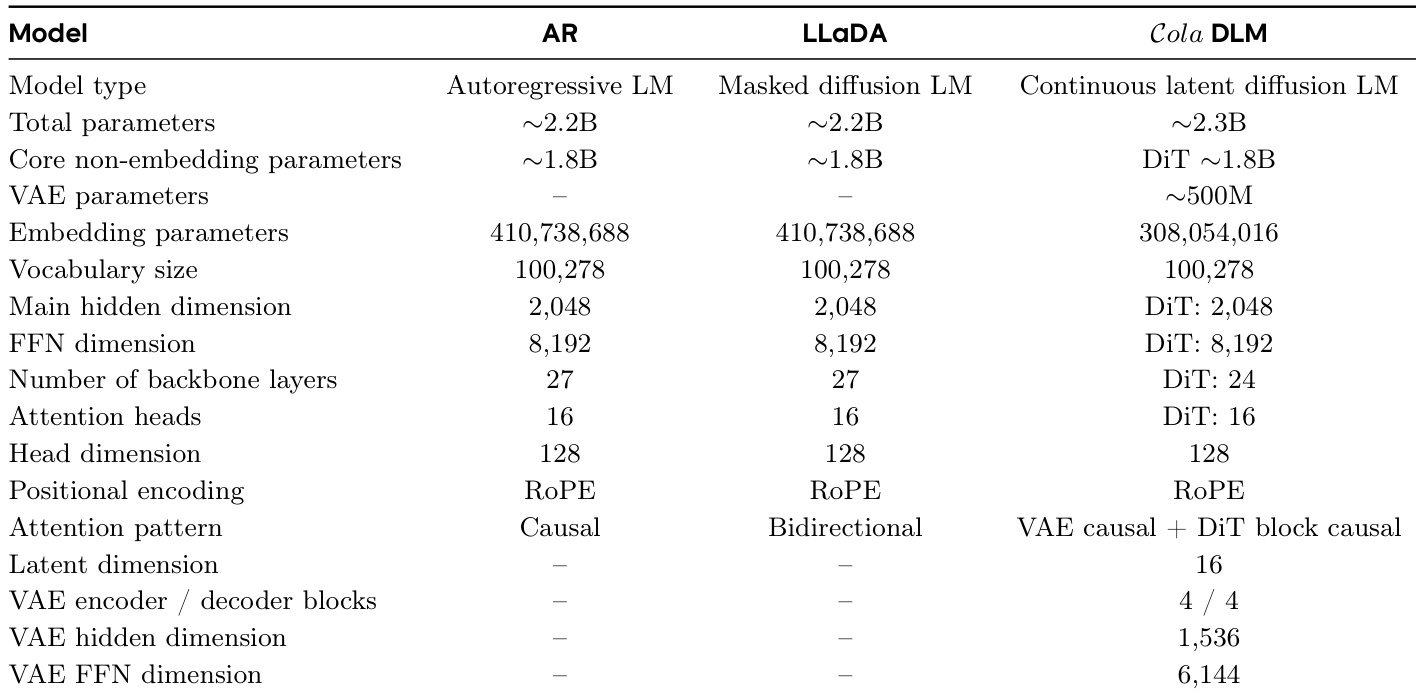
下表对比了三种语言建模方法的架构细节:自回归语言模型(AR)、掩码扩散语言模型(LLaDA)与连续潜在扩散语言模型(Cola DLM)。Cola DLM 采用包含 VAE 与 DiT 主干的独特架构,总参数量高于其他模型,同时与它们共享核心主干参数。该模型使用具有特定因果注意力模式与明确潜在维度的连续潜在空间。由于引入 VAE 组件,Cola DLM 的总参数量大于 AR 与 LLaDA。Cola DLM 采用具有特定因果注意力模式与明确潜在维度的连续潜在空间。AR 与 LLaDA 共享相似的主干架构,而 Cola DLM 引入了具有不同参数配置的 VAE 与 DiT 主干。
实验在变化的 VAE logSNR 配置、生成质量指标、潜在空间动力学、条件控制策略及架构基线等多个维度评估 Cola DLM,以验证去噪校准、生成保真度与结构连贯性。结果表明,可学习的 logSNR 设置稳定优于固定方案,并能随计算资源有效扩展,而实际生成质量依赖于潜在空间的语义平滑度,而非精确的概率校准。此外,最优时间偏移随潜在维度系统性地漂移以揭示共享的全局语义结构,强效且持续的条件控制在生成过程中对维持提示词保真度至关重要。这些定性结果共同证实,连续潜在扩散架构为下一个 token 预测提供了稳定且语义鲁棒的框架。