Command Palette
Search for a command to run...
MiA-Signature:近似全局激活以实现长上下文理解
MiA-Signature:近似全局激活以实现长上下文理解
Yuqing Li Jiangnan Li Mo Yu Zheng Lin Weiping Wang Jie Zhou
摘要
认知科学领域越来越多的研究表明,可报告的意识访问与分布式记忆系统中的全局点火(global ignition)密切相关,而此类激活仅能部分被个体访问,因为人们无法直接访问或枚举所有被激活的内容。这种张力表明,认知可能依赖于一种紧凑的表示形式,以近似激活对下游处理的全球影响。受此启发,我们引入了心智景观激活签名(Mindscape Activation Signature, MiA-Signature)的概念,即由查询诱导的全局激活模式的压缩表示。在大语言模型(LLM)系统中,这是通过基于子模数的选择来实现的,该选择覆盖被激活的上下文空间中的高层概念,并可选择性地通过轻量级迭代更新进行微调,这些更新使用工作记忆(working memory)进行。生成的MiA-Signature作为条件信号,近似全激活状态的效果,同时保持计算上的可行性。将MiA-Signatures集成到RAG和agent系统中,在多个长上下文理解任务中均带来了稳定性能提升。
一句话总结
作者提出了 MiA-Signature,这是一种受认知科学启发的条件信号,通过基于子模函数的概念选择和轻量级迭代优化,近似长上下文理解所需的全局激活模式。将其集成到检索增强生成和 Agent 系统中后,能在多项长上下文理解任务中带来一致的性能提升。
核心贡献
- 本文提出了心智景观激活签名(Mindscape Activation Signature, MiA-Signature),这是一种压缩表示形式,用于近似查询在语义记忆空间中激发的全局激活模式。
- 该框架通过基于子模函数选择高层概念来实例化该签名,以覆盖被激活的上下文,并可选地通过轻量级迭代工作记忆更新进行优化,以确保计算可行性。
- 将 MiA-Signature 集成到检索增强生成和 Agent 系统中,可在多项长上下文理解任务中带来一致的性能提升。
引言
大型语言模型和检索增强系统日益依赖外部记忆来处理复杂查询,这使得高效的长上下文理解成为现代 AI 应用的关键能力。当前架构通常将记忆访问视为一系列局部文档检索,这隐含地假设推理仅需一组直接获取的狭窄证据。这种局部化范式忽视了认知科学的见解,即人类认知实际上依赖于跨分布式记忆网络的短暂、大规模激活,随后被压缩为可处理的内部表示。为填补这一空白,作者提出了心智景观激活签名(Mindscape Activation Signature),这是一种压缩的查询条件信号,用于近似语义记忆空间上的全局激活。通过利用高层概念的子模函数选择以及可选的轻量级迭代优化,作者为下游检索和推理模块提供了整体的语义上下文。将该方法集成到检索增强生成和 Agent 工作流中,能够持续改善长上下文任务的性能,同时高效管理冗余记忆存储。
数据集
-
数据集构成与来源: 作者基于四项成熟的长上下文基准测试构建评估套件,这些基准取自英文和中文侦探小说及叙事文本。该合集包括 DetectiveQA、NarrativeQA、NovelHopQA 和 NoCha。
-
子集详情: DetectiveQA 包含 13 部小说,分为马普尔小姐和赫尔克里·波洛系列,用于多项选择题推理。NarrativeQA 包含 37 本书,根据共享主角或连续故事线整合为 11 个系列,用于开放式问答。NovelHopQA 评估长篇小说节选的跨步推理能力,而 NoCha 则处理完整小说的声明验证任务。
-
数据使用与评估策略: 作者仅将这些基准用于评估,而非模型训练。论文未指定训练集划分或混合比例。性能评估采用多项选择题和声明验证任务的准确率、开放式回答的 F1 分数以及 NoCha 的成对准确率。当提供黄金证据标注时,作者还会报告 Recall@10。
-
处理与上下文构建: 作者未将单部小说视为孤立文档,而是将同一系列的小说合并为统一的多卷本合集。这种聚合扩大了检索空间,以包含相关角色、情节事件和故意设置的干扰项。每个问题仍锚定于特定章节的证据,但模型必须导航更广泛的合并上下文。该流水线还应用动态查询重写和证据签名优化,以支持检索过程中的复杂推理链。
方法
作者利用了一个以 MiA-Signature 为核心的框架。该签名是结构化记忆空间(称为心智景观,mindscape)中全局激活记忆区域的紧凑查询条件表示。此签名作为查询引发的完整激活模式的代理,使下游检索和推理能够访问全局记忆信号,而无需直接访问整个激活记忆池。心智景观被定义为与长源 D 关联的记忆池 M(D),其中每个记忆单元 mi 都基于更细粒度的证据。查询引发的激活 aq 是一个将记忆单元映射到相关性的函数,代表心智景观中被激活的语义区域。MiA-Signature σ∗(q) 被推导为高层记忆单元 H(D) 的紧凑子集,其选择旨在最佳近似激活区域 Hq,同时平衡相关性、覆盖率和多样性。该签名并非对源内容的摘要,而是一种与局部检索证据共存的全局状态。
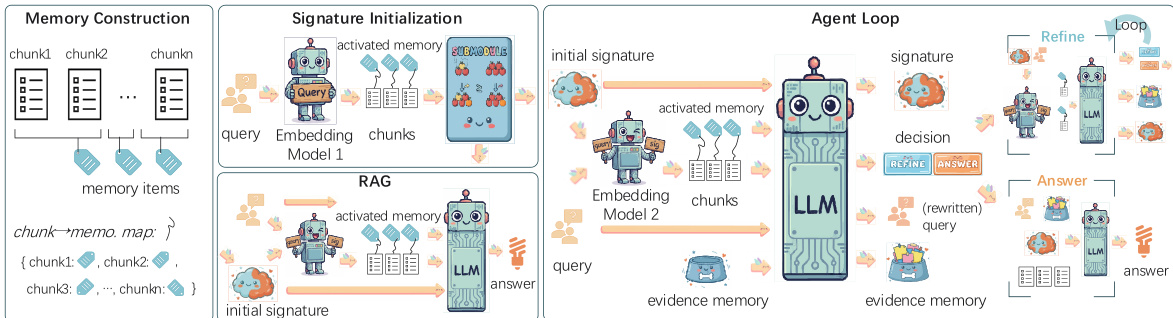
该框架通过两种主要检索机制运行:仅查询检索器 E1 和心智景观感知检索器 E2。仅查询检索器由 SFT-Emb-8B 实例化,仅通过编码查询提供相关证据的初始视图。相比之下,心智景观感知检索器由 MiA-Emb-8B 实例化,其查询表示同时以输入查询和全局记忆信号(即当前 MiA-Signature σt)为条件。这使得检索分布能够随着签名的更新而演变,使系统能够追踪激活记忆区域视图的变化。候选证据单元 c 的检索分数是查询相关性与签名一致性的加权组合,公式为 s(c∣q,σ)=(1−α)sqry(c∣q)+αssig(c∣σ),其中 α 控制全局信号的影响。
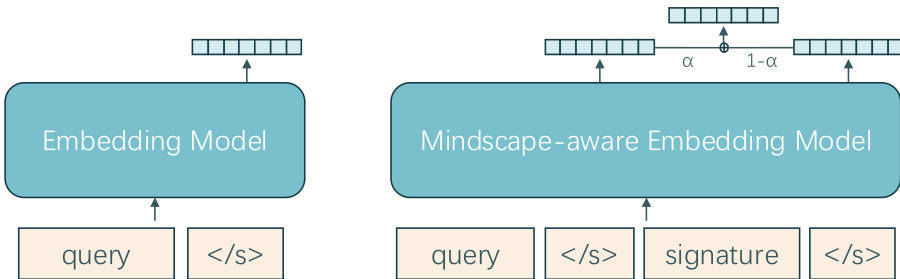
MiA-Signature 在静态和动态设置中的实例化方式不同。在静态 RAG 设置中,签名仅构建一次并作为固定条件信号使用。该过程始于使用 E1 进行 step-0 检索,以获取一组广泛的候选块。这些块被映射到高层记忆单元,形成摘要池 H0(q)。随后,通过考虑覆盖率的子模优化选择初始签名 σ0,以平衡查询相关性、激活区域的覆盖率以及摘要间的多样性。此选择使用目标函数 F(σ;q,H0(q)) 的贪心近似来完成。在动态 Agent 设置中,签名作为不断演变的全局状态进行维护。它使用相同的子模选择过程进行初始化,但在循环中迭代优化。在每个步骤 t,Agent 使用 E2 基于当前查询 qt 和签名 σt 检索证据。状态更新模型 Mupd 随后处理检索到的证据、当前状态和高层记忆单元,以更新查询、证据记忆和签名。Agent 持续此过程,直到做出回答决策或优化预算耗尽。最终答案由生成模型 Mgen 使用原始查询、最新检索到的证据、最终签名和累积的证据记忆生成。
实验
该评估在静态 RAG 流水线与迭代 Agent 框架中测试 MiA-Signature,以评估其作为紧凑全局条件信号和演变记忆状态的效用。实验针对多种基线、初始化策略和查询重写控制对接口进行了验证,证明该签名能有效维持全局上下文对齐,并在连续检索步骤中保留关键信息绑定。定性分析表明,尽管考虑覆盖率的初始化能为静态流水线带来一致的提升,但迭代 Agent 通过在线优化利用更简单的初始化,且查询重写的作用因任务而异而非普遍有益。最终,研究结果确立了 MiA-Signature 作为一种稳健的全局结构先验,成功缓解了长上下文叙事理解中过度完备记忆空间内的语义干扰。
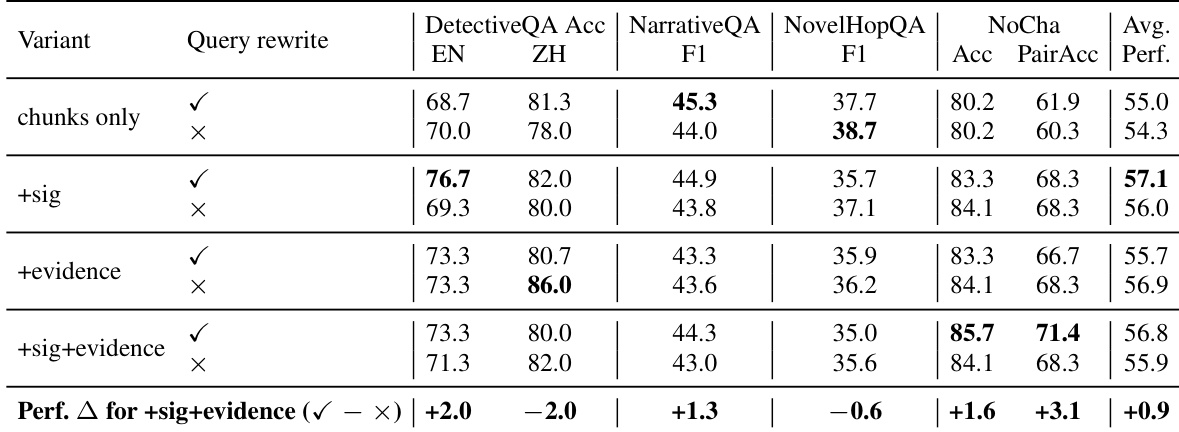
作者评估了记忆增强检索系统中不同组件的影响,重点关注查询重写以及签名和证据记忆的使用如何影响多项基准测试的性能。结果表明,将签名与证据记忆结合能持续改善平均性能,而查询重写的影响因任务而异。同时使用签名和证据记忆可在所有基准测试中实现最高的平均性能。查询重写在某些任务中提升性能,但在其他任务中降低性能,表明其收益具有任务依赖性。签名与证据记忆的组合相较于基线配置提供了最一致的性能提升。
作者评估了 MiA-Signature 在两种长上下文记忆访问设置中的表现:静态 RAG 流水线与迭代 Agent。结果表明,该签名在两种设置中均能提升性能,当签名同时用于检索和生成阶段时,性能提升最为一致。Agent 设置表明,演变的签名有助于在检索步骤间维持全局连贯性,尤其是在答案需要综合多源证据时。与无签名条件的基线相比,MiA-Signature 在静态 RAG 和迭代 Agent 设置中均改善了性能。Agent 设置中的演变签名有助于维持全局记忆状态,支持需要跨多步检索综合的准确回答。将签名与累积的证据记忆结合可取得最佳性能,表明两个组件均对长上下文理解有所贡献。
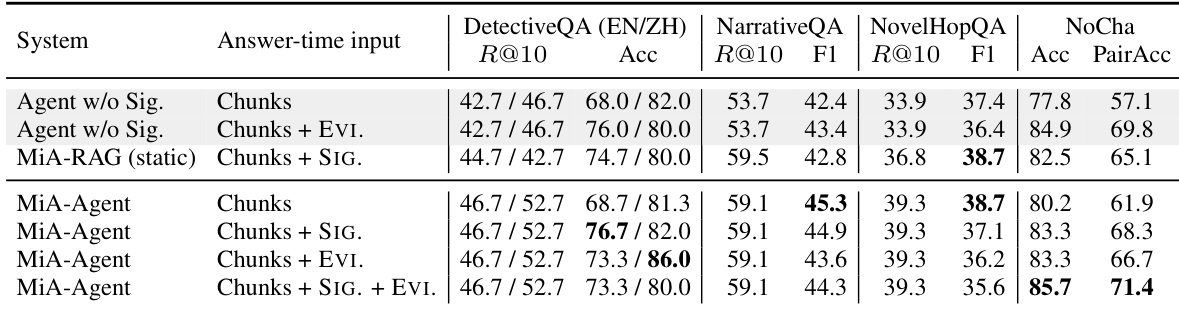
作者评估了 MiA-Signature 在两种长上下文记忆访问设置中的表现:静态 RAG 流水线与迭代 Agent。结果表明,完整的签名感知接口在多项基准测试中持续优于仅查询和仅检索的变体,在需要综合分散证据的任务中提升幅度最大。演变的签名被证明是一种有效的全局记忆状态,能够对齐检索与生成过程,尤其在复杂叙事场景中表现突出。与仅检索和仅查询基线相比,完整的签名感知接口在所有基准测试中取得了最高性能。演变签名维持了全局记忆状态,支持迭代 Agent 设置中检索与生成之间的对齐。基于签名的方法在具有广泛冗余上下文的场景中展现出显著增益,此类场景对维持全局连贯性至关重要。

作者评估了 MiA-Signature 在两种长上下文记忆访问设置中的表现:静态 RAG 流水线与迭代 Agent。结果表明,签名感知接口在各类基准测试中提升了性能,完整的签名感知系统优于未使用签名或仅将其用于检索的基线方法。签名在不同初始化策略和查询重写设置下的有效性保持一致,尽管收益因任务对全局上下文和证据综合的需求而异。MiA-Signature 在静态 RAG 和迭代 Agent 设置中均增强了性能,完整的签名感知系统展现出持续改进。该签名改善了检索与生成的对齐,尤其在需要综合分散证据的任务中。不同的初始化策略和查询重写具有不同影响,表明签名的作用与其他机制呈互补关系。
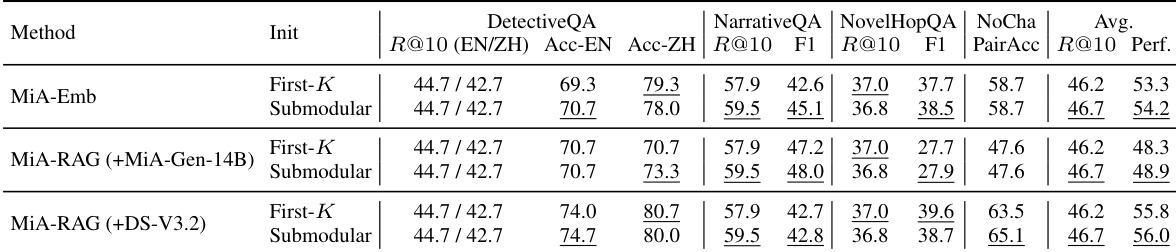
作者比较了两种索引策略下的检索性能:单本书与系列书,其中系列书中的书籍被合并为单一文档。结果表明,合并书籍导致所有基准测试的检索召回率下降,这表明跨书上下文引入了语义干扰而非有用信息。这支持将系列书设置作为记忆对齐和证据选择的更具挑战性的测试。将书籍合并为单一索引会降低检索召回率,表明跨书上下文引入了语义干扰。系列书设置比单书设置更具挑战性,因为它测试在更大、过度完备的记忆空间中识别相关区域的能力。从单书索引转向系列书索引时,所有基准测试的检索性能均一致下降。
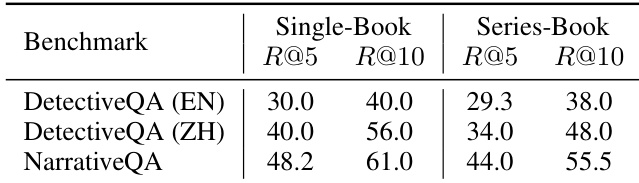
实验在静态 RAG 和迭代 Agent 设置中评估了记忆增强检索系统,考察查询重写、签名记忆和证据记忆如何与不同索引策略相互作用。研究结果证明,结合签名与证据记忆能通过维持全局连贯性和对齐检索与生成过程来持续增强性能,尤其在需要跨分散上下文综合的任务中。尽管查询重写带来的收益参差不齐且因任务而异,但完整的签名感知接口仍是最稳健的配置。此外,将相关文本合并为单一索引会因语义干扰而降低检索召回率,这证实了系列书设置为复杂记忆对齐提供了更严格的测试。