Command Palette
Search for a command to run...
均值模式尖叫:1000层扩散Transformer中的均值-方差分裂残差
均值模式尖叫:1000层扩散Transformer中的均值-方差分裂残差
Pengqi Lu
摘要
将扩散 transformer(DiT)扩展至数百层会引入结构脆弱性:网络可能陷入一种静默的、以均值为主导的崩溃状态,该状态会同质化 token 表示并抑制居中变异(centered variation)。通过机制审计(mechanistic auditing),我们将导致这种崩溃的触发事件界定为均值模式尖叫(Mean Mode Screaming, MMS)。即使训练看似稳定,MMS 仍可能发生,其对残差写入器(residual writers)施加的均值相干反向冲击(mean-coherent backward shock)会打开深层残差分支,并驱使网络进入以均值为主导的状态。我们表明,这种行为由梯度对均值相干分量和居中分量的精确分解所驱动,且在值(values)同质化后,由于 Softmax 雅可比矩阵的零空间对注意力 logits 梯度的结构性抑制,进一步加剧了这一现象。为解决这一问题,我们提出了均值-方差分离(Mean-Variance Split, MV-Split)残差机制,该机制将单独获取的居中残差更新与有损主干均值替换(leaky trunk-mean replacement)相结合。在 400 层单流 DiT 上,MV-Split 防止了导致未稳定基线崩溃的发散性崩溃;在完整训练过程中,它不仅紧密跟随基线崩溃前的轨迹,而且其性能显著优于 token 各向同性门控方法(如 LayerScale)。最后,我们展示了一个 1000 层的 DiT,作为边界尺度下的规模验证实验,确立了该架构在极端深度下仍具备稳定的可训练性。
一句话总结
作者提出均值-方差分离(MV-Split)残差,旨在防止均值模式尖叫(Mean Mode Screaming)。该现象是一种由均值主导的坍塌,会导致扩散Transformer中的token表征同质化。该方法通过将反向梯度分解为中心残差更新和泄漏的主干均值替换,从而在400层单流DiT上稳定训练。
核心贡献
- 机制审计将均值模式尖叫(MMS)识别为超深扩散Transformer中静默的、均值主导的坍塌状态的触发因素,展示了将梯度精确分解为均值一致分量和中心分量如何系统地导致token表征同质化。
- 本文引入均值-方差分离(MV-Split)残差,这是一种结构修改方案,用于解耦残差路径,以便对均值和中心梯度分量应用独立的缩放比例。通过仅衰减均值路径同时保留中心更新,该方法规避了ReZero和LayerScale各向同性门控技术导致的收敛速度下降问题。
- 在400层单流扩散Transformer上的训练实验表明,MV-Split残差能够防止发散性坍塌并稳定优化过程,同时不会牺牲深层网络中的表征多样性。
引言
缩放定律确立模型深度作为生成性能的关键驱动因素,使得超深扩散Transformer极具价值,但也容易受到突然且无法解释的训练坍塌的影响。以往的深度稳定技术通过均匀收缩残差分支来解决这些失败问题,但这会无意中削弱空间特征学习所需的中心信号,并减缓收敛速度。作者将这种现象命名为均值模式尖叫,其中token子空间之间的几何不对称性导致表征同质化,并使梯度更新锁定在坍塌状态。为克服这一限制,作者利用MV-Split残差解耦均值和中心路径,应用目标门控机制,在稳定均值路径的同时保留中心信号。该方法使得超深架构的可靠训练成为可能,且不会牺牲收敛速度。
方法
作者利用极简的单流扩散Transformer(DiT)架构来研究超深模型的失效动力学。主干网络由后归一化残差链组成,其中每一层对输入与transformer块输出的总和应用RMSNorm。该模型处理由VAE编码的image tokens和文本嵌入拼接而成的序列,依赖自注意力机制处理所有多模态交互。位置编码使用RoPE的二维扩展应用于image tokens,而text tokens保持未编码状态。残差写入器,特别是注意力输出投影 WO 和前馈网络(FFN)输出投影 W2,均进行零初始化。这是一种标准做法,可将失效动力学隔离在残差传播路径上。训练采用Rectified Flow匹配目标,该目标沿线性插值路径预测从噪声到数据的向量场。 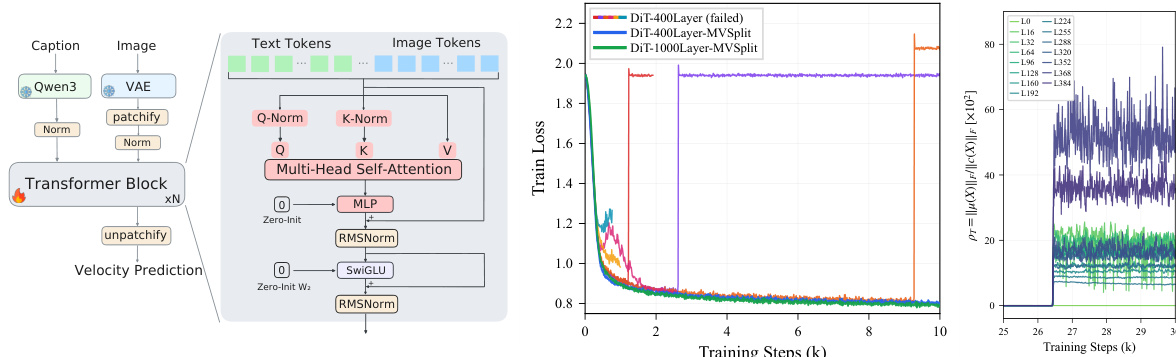
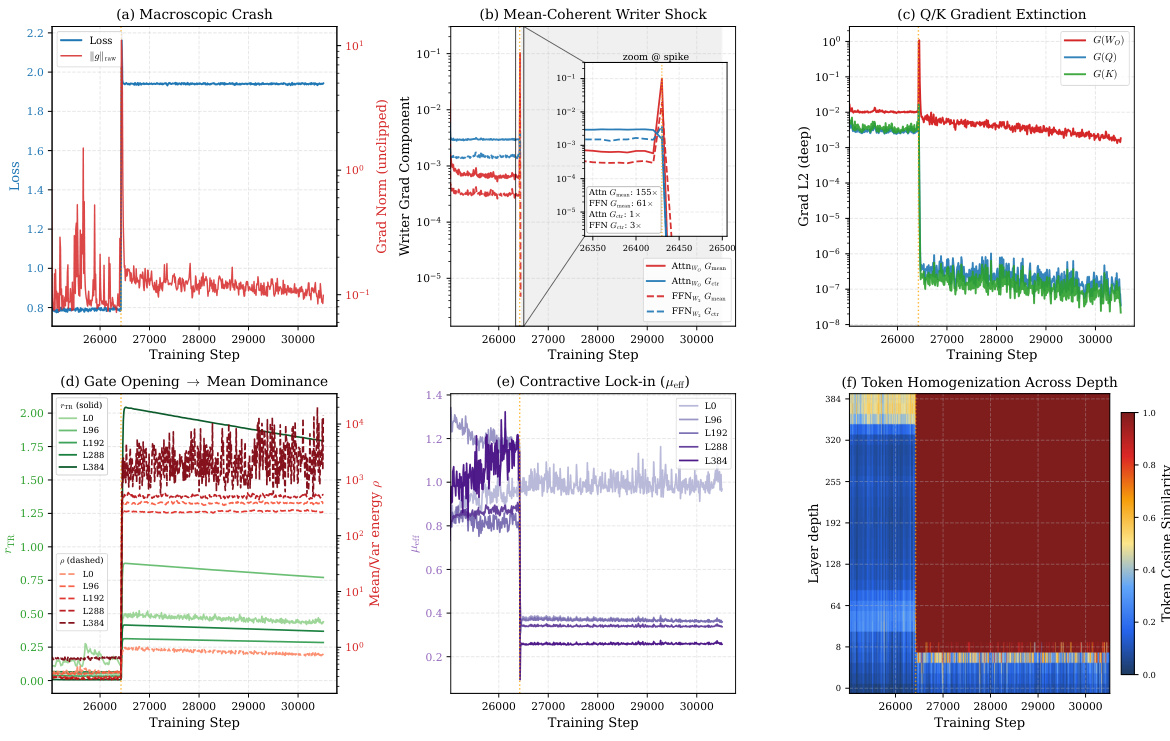
识别出的核心失效模式是一种均值主导的坍塌,由称为均值模式尖叫(MMS)的现象触发。当残差写入器上的梯度被均值一致分量主导时就会发生这种情况,当token表征及其伴随矩阵对齐时,该分量的规模缩放为 O(T)。作者证明,token级线性映射 W 的梯度可精确分解为均值一致秩1分量 ΔWμ=Tδˉyˉ⊤ 和中心分量 ΔWc=∑tδ~ty~t⊤。当表征和伴随矩阵趋于对齐时,均值一致分量随之增长,导致梯度范数出现剧烈尖峰。该尖峰随后引发前向坍塌,token表征发生同质化,且由于值向量变为常数,注意力logit梯度通过Softmax雅可比矩阵的零空间被抑制。 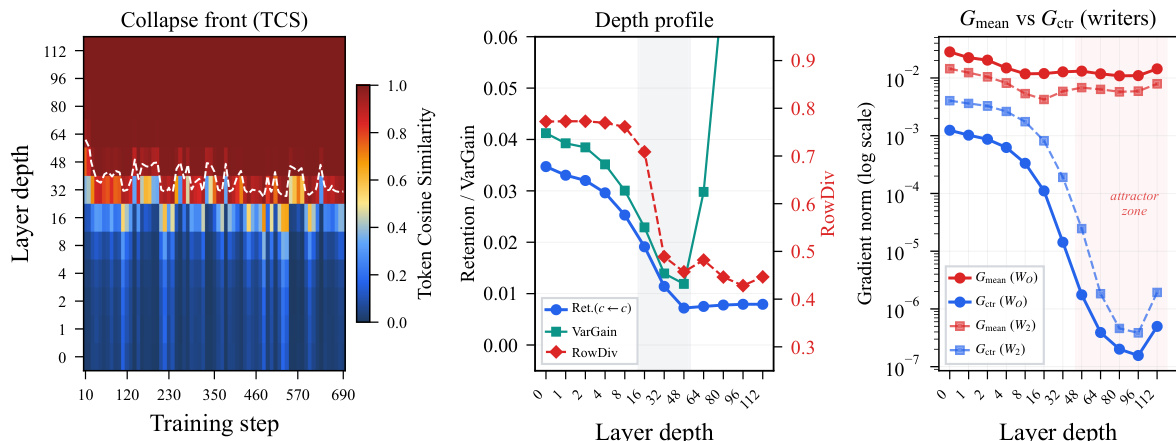
为解决此问题,作者提出均值-方差分离(MV-Split)残差。该方法将残差合并解耦为两条独立路径:中心路径和均值路径。标准的后归一化合并 Xl+1=RMSNorm(Xl+Fl) 被替换为子空间路由合并:Zl=Xl+β⊙(PFl)+α⊙J(Fl−Xl),随后应用RMSNorm。其中,J 和 P 分别是投影到序列均值和中心变化子空间的投影算子,α,β 为逐特征可学习向量。具有增益 β 的中心路径更新token特异性变化,而具有增益 α 的均值路径作为主干均值的泄漏积分器,在添加新的均值校正之前将其收缩 1−αd。该设计确保均值一致梯度分量独立于中心更新进行衰减,从而中断自增强放大循环。流回分支的梯度同样被分割,均值和中心分量分别获得独立的增益。 
实验
实验评估了在ImageNet潜空间上训练的400层和1000层DiT架构,在明确稳定性约束下对比了未稳定基线、LayerScale以及本文提出的MV-Split方法。机制追踪与梯度分解验证了训练坍塌源于结构子空间失衡,其中残差写入器失去符号抵消能力,导致均值一致更新占据主导并使tokens同质化。MV-Split通过选择性地约束问题性的均值一致梯度模式并保留中心变化,成功解决了该问题,从而在均匀抑制学习信号的同时,推动了受稳定性约束的质量前沿。后续控制实验证实该发散机制与初始化方案无关,而时间步探测验证了该方法目标增益限制设计的合理性,1000层运行结果表明该几何干预在更深网络中依然稳健有效。
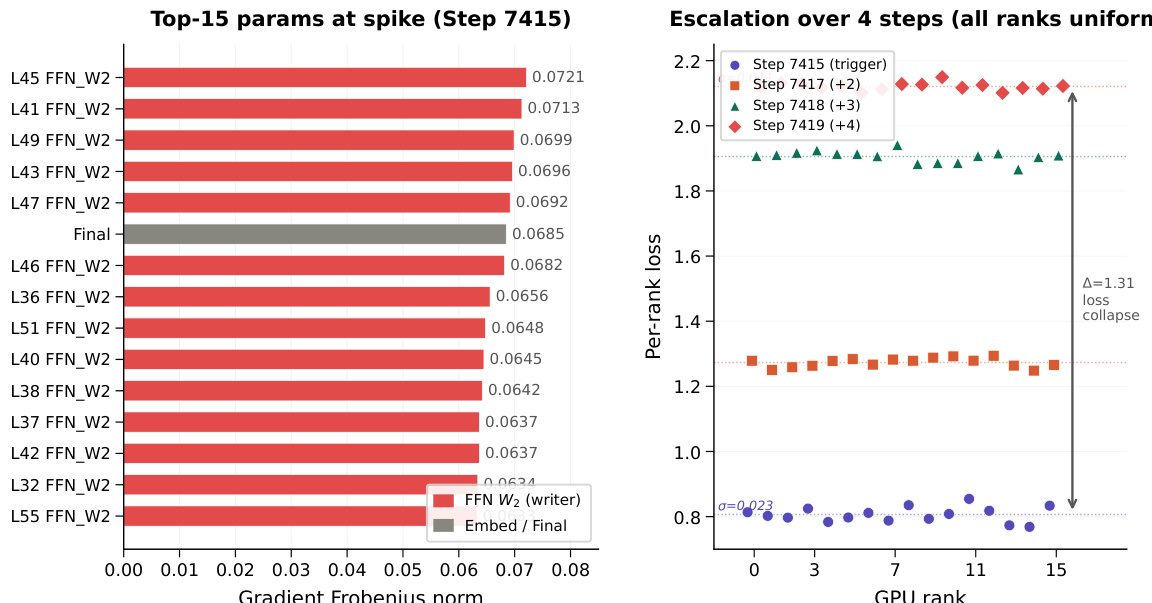
作者分析了400层模型的发散事件,重点关注训练期间发生的梯度尖峰。分析揭示了写入器梯度的均值一致分量出现模式选择性放大,导致跨深度的token变化发生坍塌。结果表明,针对均值和中心分量采用独立增益控制的残差设计能够维持稳定的梯度行为并保留token变化,从而支持更深层次的训练且不会坍塌。梯度尖峰放大了写入器梯度的均值一致分量,同时抑制中心分量,进而导致token同质化。针对均值和中心分量采用独立增益控制的残差设计维持了稳定的梯度行为,并避免了其他设计中出现的坍塌。该模型在深层网络中保持训练稳定,均值一致梯度分量保持有界,而中心分量维持在较高的稳定区间。
作者分析了不同残差稳定方法在深层模型中的行为,重点关注训练期间的梯度动力学。结果表明,尽管未稳定基线表现出均值一致写入器梯度的剧烈尖峰随后发散,但MV-Split有效约束了该分量并保留中心梯度,从而实现稳定训练。LayerScale同样约束了均值一致梯度,但以抑制中心梯度为代价,导致收敛速度变慢。与LayerScale相比,MV-Split在约束均值一致写入器梯度的同时,保留了更高水平的中心梯度活跃度。未稳定基线显示均值一致写入器梯度的剧烈尖峰,导致发散,而MV-Split避免了这种坍塌。LayerScale均匀降低均值一致和中心梯度,导致相比MV-Split收敛更慢。
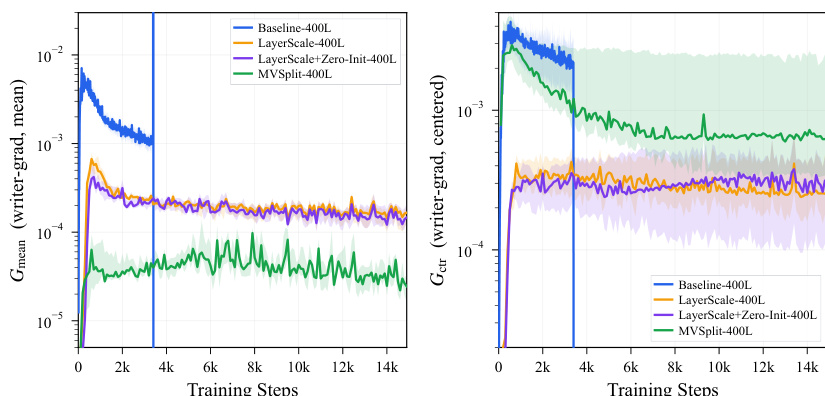
作者在ImageNet-2012潜空间上对比了多个深层transformer模型,重点关注超深训练下的稳定性和收敛性。结果表明,未稳定基线在训练期间发散,而MV-Split维持稳定的梯度范数,且随时间推移相比LayerScale取得更好的质量指标。分析强调MV-Split在不抑制中心变化的情况下有效控制均值一致梯度模式,使得在1000层持续训练成为可能。未稳定基线在训练期间发散,而MV-Split维持稳定的梯度范数并避免发散。与LayerScale相比,MV-Split随时间推移取得更好的质量指标,在保持早期收敛速度的同时避免坍塌。MV-Split约束均值一致梯度分量,同时为中心梯度保留更高的稳定区间,从而支撑其稳定性控制机制。
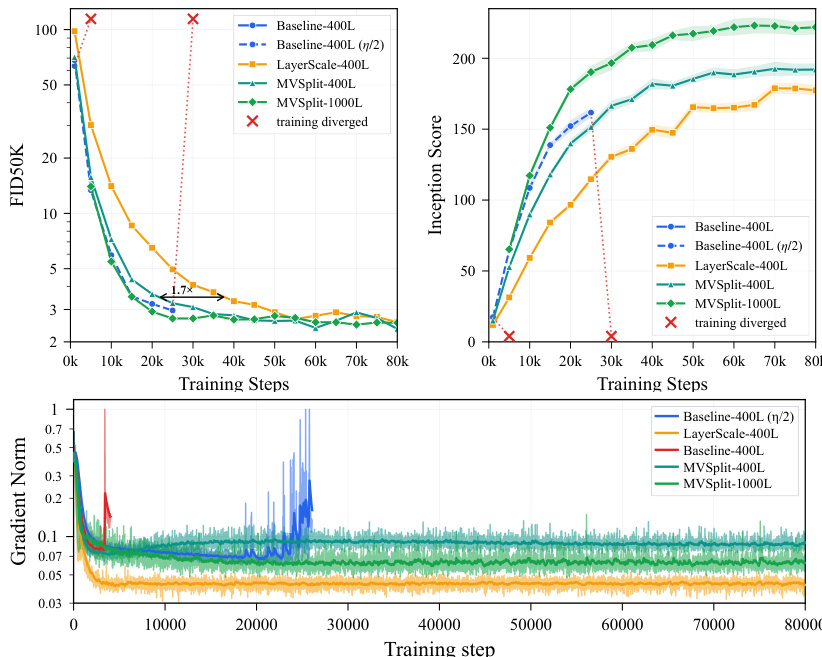
作者分析了超深模型中的发散行为,识别出一种模式选择性梯度冲击,该冲击在均值一致方向放大,同时Q/K梯度发生坍塌,导致token同质化和均值主导的失效状态。他们评估了稳定方法,表明MV-Split在保持更高梯度稳定性和更好收敛性方面优于基线方法,且未牺牲早期学习速度,并证明该稳定机制可延伸至1000层模型,同时保留文本条件生成质量。梯度冲击在均值一致写入器方向选择性放大,导致Q/K梯度坍塌并引发跨深度的token同质化。MV-Split通过约束均值一致梯度分量并保留更高的稳定中心梯度区间来稳定模型,在不牺牲早期速度的前提下提升收敛性。该稳定机制延伸至1000层模型,在其他方法失效的深度之外,依然维持稳定训练和可用的文本条件生成质量。
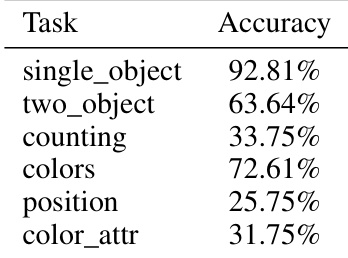
{"summary": "作者使用GenEval和DPG-Bench任务评估了1000层MV-Split模型的文本条件生成性能。结果表明,在单对象和计数任务上具有较高准确率,在颜色和位置任务上表现中等,在颜色属性识别上准确率较低。视觉样本显示该模型在各类别中均展现出稳健的生成能力。", "highlights": ["该模型在单对象和计数任务上实现高准确率,表明其在基础视觉理解方面表现强劲。", "在颜色和位置任务上表现中等,表明在处理更复杂视觉属性方面存在局限。", "该模型在颜色属性识别上准确率较低,凸显了细粒度属性预测面临的挑战。"]}
实验通过对比未稳定基线、LayerScale以及本文提出的MV-Split方法,在数百至数千层范围内评估了超深transformer模型的训练稳定性和生成质量。分析表明,未稳定架构因梯度尖峰导致token表征同质化而发散,而LayerScale以抑制梯度变化和减缓收敛为代价来遏制不稳定性。MV-Split成功隔离并约束了问题性的均值一致梯度,同时保留必要的中心梯度活动,从而在极端深度下实现稳健训练,且不损害早期学习动力学或文本条件生成能力。