Command Palette
Search for a command to run...
列表策略优化:基于组的RLVR作为对LLM响应单纯形的目标投影
列表策略优化:基于组的RLVR作为对LLM响应单纯形的目标投影
摘要
带有可验证奖励的强化学习(RLVR)已成为大型语言模型(LLM)后训练阶段激励推理能力的标准方法。在现有的算法方案中,基于组的策略梯度方法尤为流行,该方法针对每个提示采样一组响应,并通过组内相对优势信号来更新策略。本研究揭示,这些优化策略共享一种共同的几何结构:它们均隐式地定义了响应单纯形上的目标分布,并通过一阶近似向该分布进行投影。基于这一洞察,我们提出了列表式策略优化(Listwise Policy Optimization, LPO)方法,以显式地执行目标投影。LPO通过将近端强化学习目标限制在响应单纯形上来揭示隐式目标,随后通过精确的散度最小化来投影策略。该框架提供了以下优势:(i)在有限、零和且具有自我纠正特性的投影梯度作用下,对列表式目标实现单调改进;(ii)通过解耦的投影步骤,在散度选择上具有灵活性,并展现出不同的结构特性。在多样的推理任务和LLM骨干网络上,在与典型策略梯度基线方法匹配目标分布的条件下,LPO consistently 提升了训练性能,同时内在保留了优化稳定性和响应的多样性。
一句话总结
本文提出列表式策略优化(LPO),这是一种强化学习框架,通过精确的散度最小化在 LLM 响应单纯形上显式执行目标投影,以解决以往基于组的方法中隐含的一阶近似问题,在保持优化稳定性和响应多样性的同时,在多种推理任务上持续超越策略梯度基线的训练性能。
核心贡献
- 本文建立了统一的几何视角,证明具有可验证奖励的强化学习中基于组的策略梯度方法在响应单纯形上隐式执行近似目标投影。
- 列表式策略优化(LPO)通过将近端强化学习目标限制为采样响应,并在响应单纯形上执行精确散度最小化,显式地将目标构建与策略投影解耦。
- 在逻辑、数学、编程和多模态推理任务上的评估表明,LPO 在保持优化稳定性和响应多样性的同时,持续超越标准策略梯度基线的训练性能。
引言
具有可验证奖励的强化学习已成为提升大语言模型在复杂问题解决任务中推理能力的关键后训练策略。以 GRPO 为代表的基于组范式通过为每个提示采样多个响应,并通过相对优势评分更新策略,在此领域占据主导地位。然而,这些方法依赖于经验归一化技术,掩盖了底层优化动态,且由于依赖隐式近似,常导致训练不稳定和梯度方差较高。本文利用统一的几何视角揭示,基于组的策略梯度在有限响应单纯形上隐式构建奖励加权的目标分布。基于此洞察,作者引入列表式策略优化,这是一种显式目标投影框架,将目标构建与散度最小化解耦。通过在单纯形上直接进行优化,该方法生成有界且自校正的梯度,确保训练稳定、降低方差,并在多种推理基准上保证奖励单调提升。
数据集
-
数据集构成与来源 作者从 Hugging Face 上托管的四个成熟开源基准中汇编了一个领域特定的推理语料库。该集合涵盖逻辑算术、数学、代码生成和空间几何,为模型训练与评估提供了结构化基础。
-
子集详情与过滤规则
- 逻辑推理:从 Countdown 34 中采样 2,000 道问题,过滤后仅保留包含三个或四个源整数的问题。
- 数学:包含来自 MATH 的 7,500 道竞赛级问题,并补充约 53,000 个来自 Polaris 的高质量推理任务以支持延长训练。
- 编程:25,300 个代码生成任务,主要源自 PRIME 数据集的编程竞赛。
- 几何:来自 Geometry3k 的 2,100 个空间推理问题,每个问题均配有图表与自然语言查询。
-
训练使用与评估处理 模型在这些精心筛选的领域划分上进行训练,而非使用固定混合数据,性能通过专用评估集进行跟踪。作者为每个提示生成多个独立响应,以计算 Pass@1 和领域特定的 Pass@k 指标。采样率根据基准难度进行校准:Countdown 为 64 个响应,AIME 和 AMC 为 32 个,Geometry3k 为 16 个,PRIME 代码为 8 个,Minerva Math 为 4 个,MATH500 和 OlympiadBench 为 1 个。训练曲线反映了这些评估套件的平均性能。
-
格式约束与奖励处理 作者未采用裁剪方式,而是强制实施严格的格式规范以统一模型输出。所有提示均要求包含用
<think>标签包裹的内部推理独白,随后是用领域特定标记(如<answer>或\boxed{})包裹的最终答案。奖励函数按领域定制:数学和编程依赖二元准确率或测试用例通过率,而逻辑推理和几何采用混合奖励机制,即使最终答案错误,只要结构格式正确即可获得部分分数(0.1)。
方法
本文提出列表式策略优化(LPO),该框架通过在响应单纯形上显式执行目标投影,对大语言模型(LLMs)的可验证奖励强化学习(RLVR)进行了重构。该方法与现有隐式近似该投影的基于组策略梯度方法形成对比。LPO 的核心架构围绕两个解耦步骤构建:目标构建与策略投影。如下图所示,流程始于提示 x,行为策略 πb 据此生成包含 K 个响应的组 {y1,…,yK}。验证器对这些响应进行评估,生成奖励向量 R=[R1,…,RK]⊤。 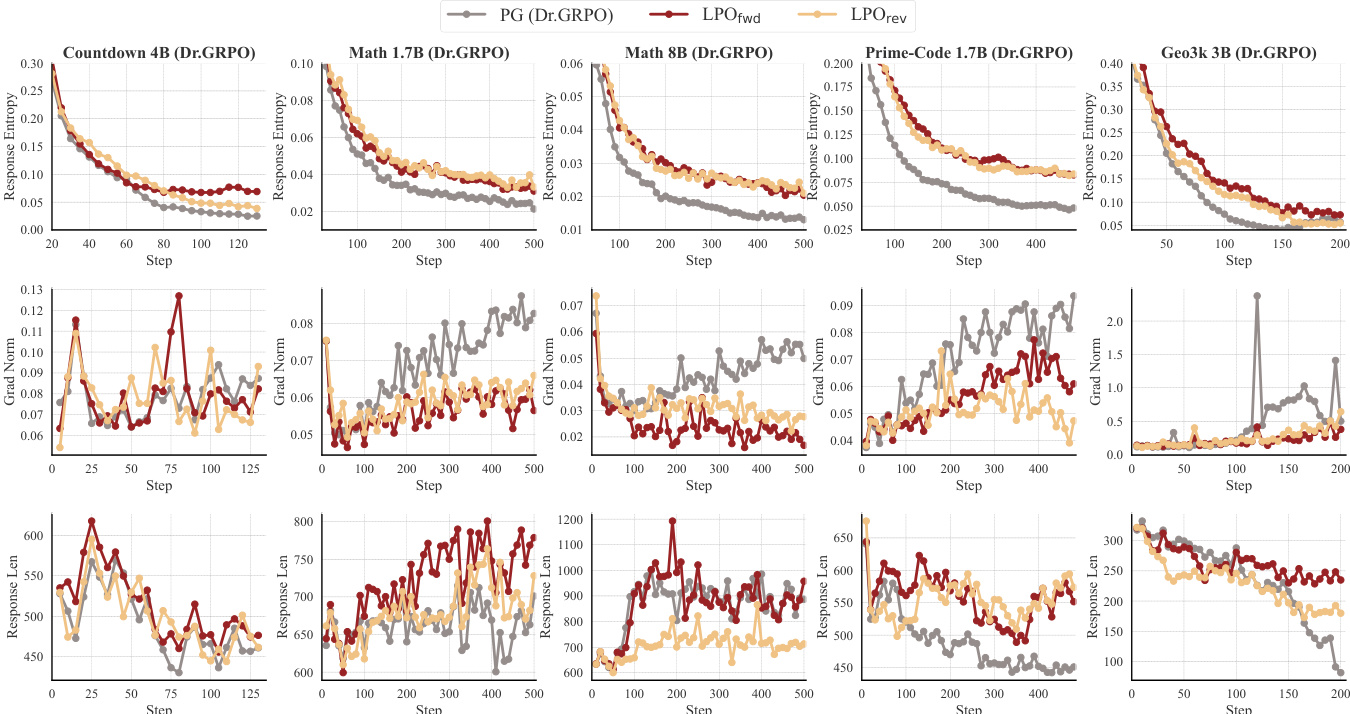
第一步为目标构建,即在 K 维响应单纯形 ΔK−1 上定义目标分布 w∗。该目标源自局部近端目标,在维持更新前策略信任区域的同时最大化期望奖励。定理 1 指出,最优目标分布为 wk∗=softmax(ϕ)k,其中 logit ϕk=Rk/τ+st,k,st,k 为来自更新前策略 πt 的 logit 偏移量,τ 为温度参数。该公式显式地将基线策略的列表式分布 Pt 向高奖励响应重新加权,τ 用于控制目标的锐度。
第二步为策略投影,即更新策略模型 πθ 以最小化当前列表式分布 Pθ 与构建目标 w∗ 之间的选定散度。该框架具有灵活性,允许选择不同的散度。例如,最小化前向 KL 散度 DKL(w∗∥Pθ) 会产生梯度更新,其中响应 yk 的系数为 ckfwd=Pθ,k−wk∗。类似地,最小化后向 KL 散度 DKL(Pθ∥w∗) 会得到系数 ckrev=Pθ,k(dk−dˉ),其中 dk 为 logit 差值,dˉ 为 Pθ 下的期望值。目标构建与投影的解耦为散度选择提供了丰富的设计空间,这是传统策略梯度方法无法实现的。 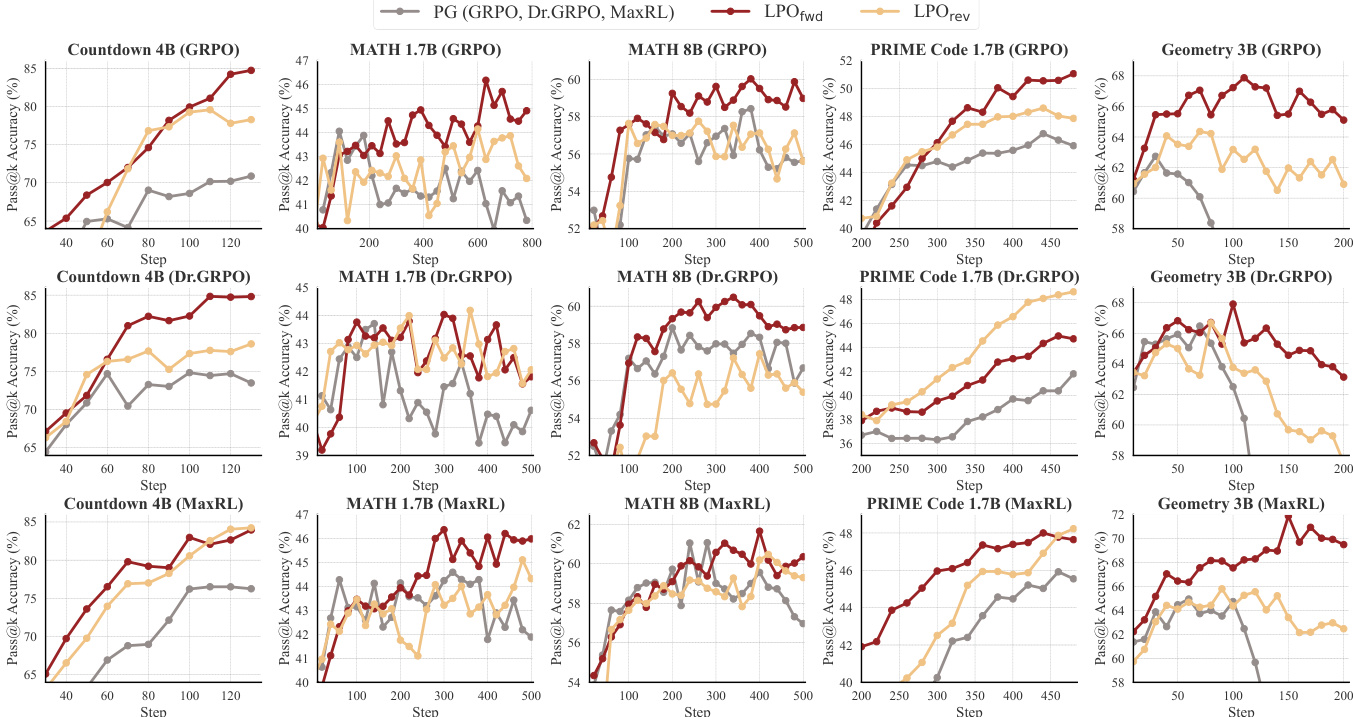
LPO 框架提供了多项关键的理论优势与实践益处。定理 2 建立了性能改进上界,表明在完美投影下期望奖励严格提升,因为目标增益即为 Jeffreys 散度。如推论 1 所述,前向 KL 的梯度系数具有有界、零和与自校正特性,这增强了优化稳定性并充当内置控制变量。零和特性是概率单纯形操作的直接结果,与缺乏此类平衡机制的点投影方法存在根本性的结构差异。该框架在实际实现中无需额外计算成本即可与标准基于组的强化学习算法兼容,如算法 1 所示。 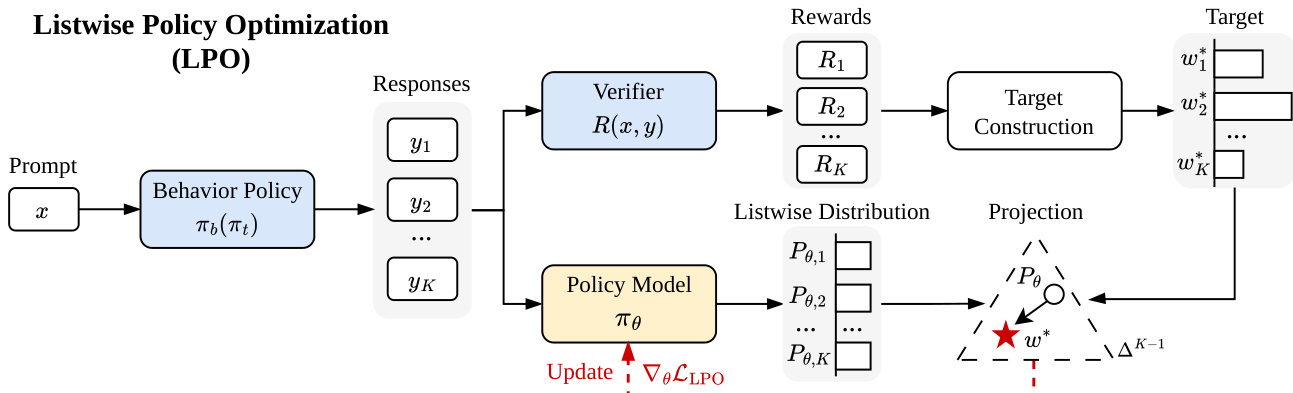
实验
本研究在逻辑、数学、编程和多模态几何任务上,使用多种 LLM 家族与规模对 LPO 进行评估,并在受控温度设置下将其与基于组的策略梯度基线进行对比。实验结果表明,LPO 在保持更高响应熵、稳定梯度范数及更长推理链的同时,持续提升训练效率与推理性能。消融研究证实,显式列表投影机制对降低方差和优化稳定性至关重要,前向与后向变体在多样性保持和样本效率方面各具优势。总体而言,研究结果确立了 LPO 作为一种稳健且模型无关的框架,通过解耦精确目标拟合与启发式温度调优,有效增强了推理任务的强化学习。
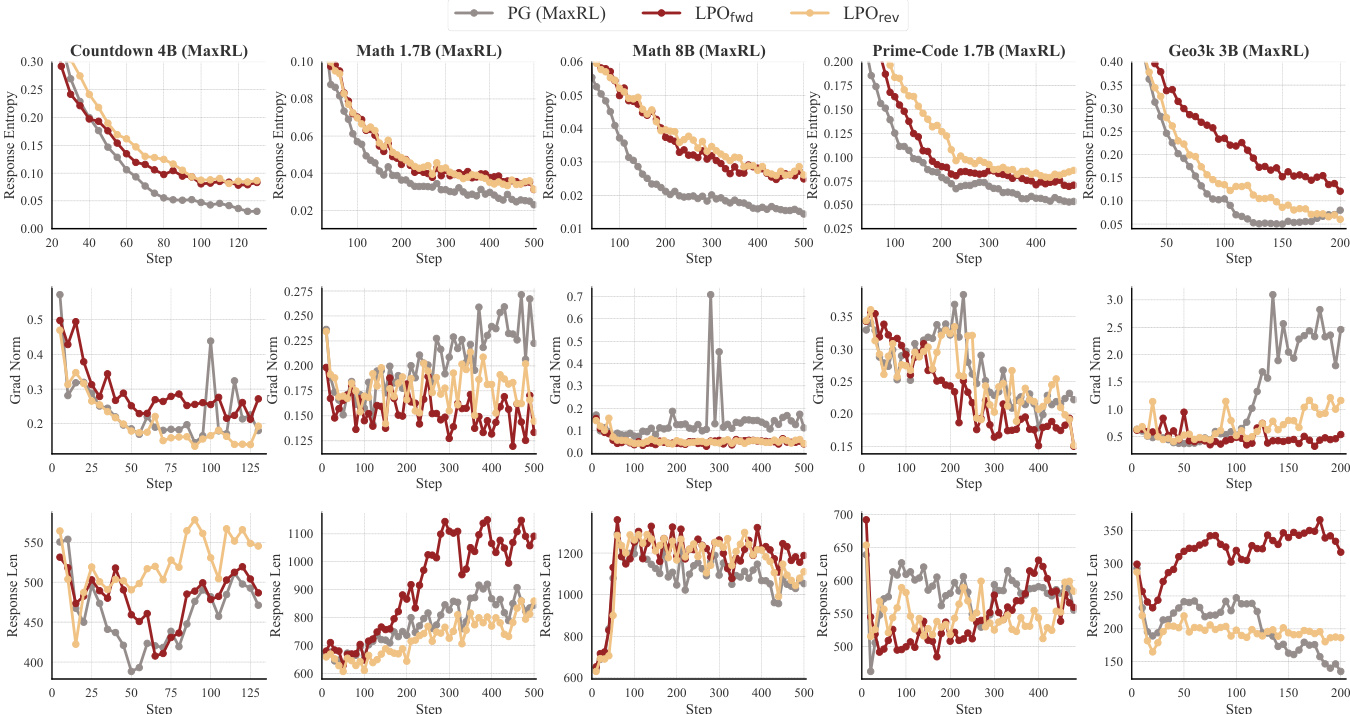
作者在多种推理任务与模型架构上将 LPO 变体与基于组的策略梯度基线进行对比。结果表明,LPO 在训练效率与性能上持续优于基线,两种变体均展现出比 PG 方法更稳定的优化动态、更高的响应熵及更长的响应长度。该提升在不同模型家族与任务领域保持一致,印证了列表投影框架的稳健性。LPO 变体在所有测试任务与模型规模上均持续超越基于组的策略梯度基线。LPO 维持更高的响应熵与更稳定的梯度范数,表明探索能力与优化稳定性得到改善。LPO 生成更长的响应,并在 Pass@k 评估中表现更优,尤其在较小分组规模下更为明显。
作者在多个推理领域与模型规模上将 LPO 与基于组的策略梯度基线进行对比,展现出训练性能的持续提升。与基线相比,LPO 变体表现出更稳定的优化动态、更高的响应多样性及更长的推理链,且在不同模型家族与任务类型中均取得增益。结果凸显了精确列表投影在提升推理任务强化学习效率与稳健性方面的优势。LPO 在各类推理任务与模型规模上持续超越基于组的策略梯度基线。LPO 变体维持更高的响应熵并呈现更稳定的梯度范数,从而改善探索与优化稳定性。LPO 在不同模型家族与训练配置中展现稳健的性能提升,表明其作为模型无关方法的泛化能力与有效性。
作者将 LPO 变体与基于组的策略梯度方法在多种推理任务与模型家族中进行对比,展现出一致的性能提升。结果表明,与基线相比,LPO 维持更高的响应熵、更稳定的梯度范数并生成更长的响应,表明探索能力与优化稳定性得到增强。该框架在不同模型架构上表现出稳健性,并能随更大模型与数据集有效扩展。LPO 变体在多样化的推理任务与模型家族中持续超越基于组的策略梯度基线。LPO 维持更高的响应熵与更稳定的梯度范数,进而改善探索与优化稳定性。该框架能随更大模型有效扩展,并在不同模型架构中展现稳健的性能增益。

作者在多种推理任务与模型规模上将 LPO 变体与基于组的策略梯度基线进行对比,观察到 LPO 在训练效率与准确性方面持续取得性能提升。结果表明,LPO 维持更高的响应熵、更稳定的梯度范数并生成更长的响应,表明探索与优化稳定性更佳。这些优势在不同模型家族与任务领域具有稳健性,LPO 变体在多数设置下均优于基线。LPO 在各类推理任务与模型规模上持续超越基于组的策略梯度基线。LPO 变体维持更高的响应熵与更稳定的梯度范数,表明探索与优化稳定性得到改善。LPO 在不同模型家族与任务领域展现出稳健的性能增益,体现其泛化能力与可扩展性。
作者在多种 LLM 与推理任务上将 LPO 变体与基于组的策略梯度基线进行对比,观察到 Pass@1 与 Pass@k 指标均取得一致的性能提升。LPO 展现出更优的训练效率与稳定性,具备更高的响应熵与更稳定的梯度范数,表明探索与优化动态更佳。结果表明,LPO 在不同模型家族与任务领域维持其优势,凸显其泛化能力与稳健性。LPO 变体在所有评估任务与模型规模上持续超越基于组的 PG 基线。LPO 维持更高的响应熵与更稳定的梯度范数,表明探索与优化稳定性更佳。LPO 在多样化的 LLM 家族与任务领域展现稳健的性能增益,证明其具备强大的泛化能力。
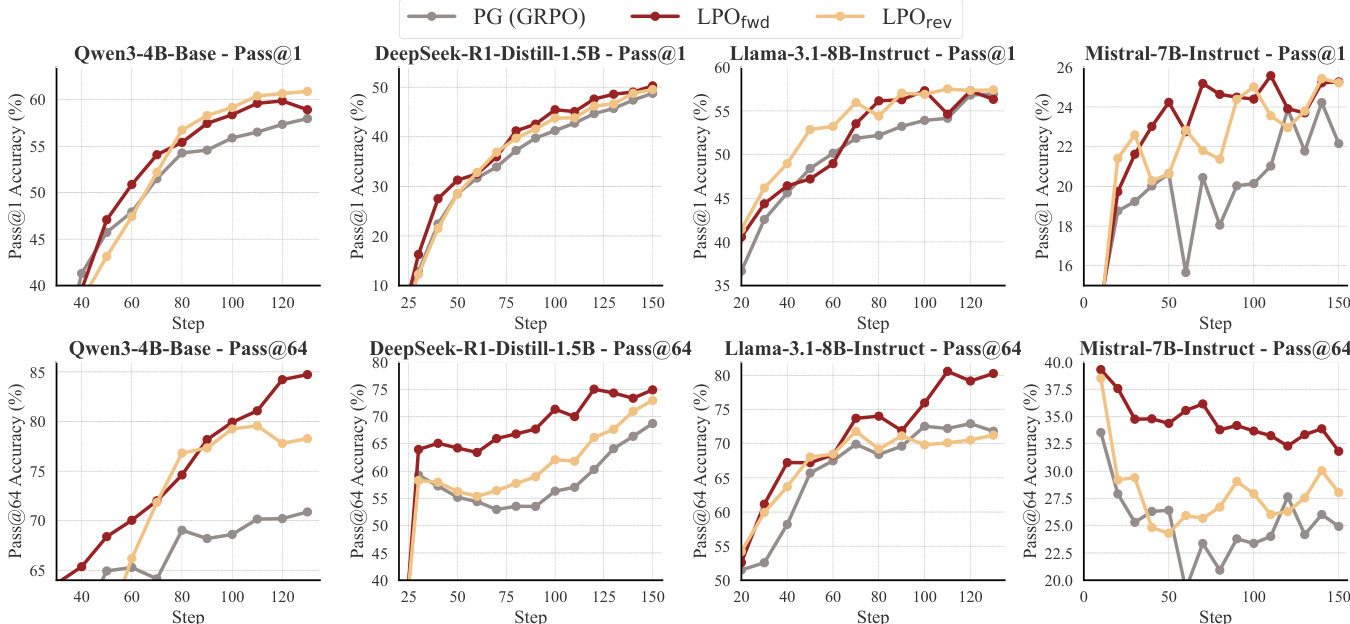
实验在多样化的推理任务与模型架构上将列表投影优化变体与基于组的策略梯度基线进行对比,以验证该框架在复杂推理强化学习中的有效性。结果一致表明,所提方法在保持更高响应多样性与更稳定优化动态的同时,实现更优的训练效率与准确性。这些定性改进表明,在不同模型规模与任务领域下,探索能力与梯度行为均得到增强。最终,研究结果证实该方法可作为推理任务中高度可泛化且模型无关的解决方案。