Command Palette
Search for a command to run...
ZAYA1-8B 技术报告
ZAYA1-8B 技术报告
摘要
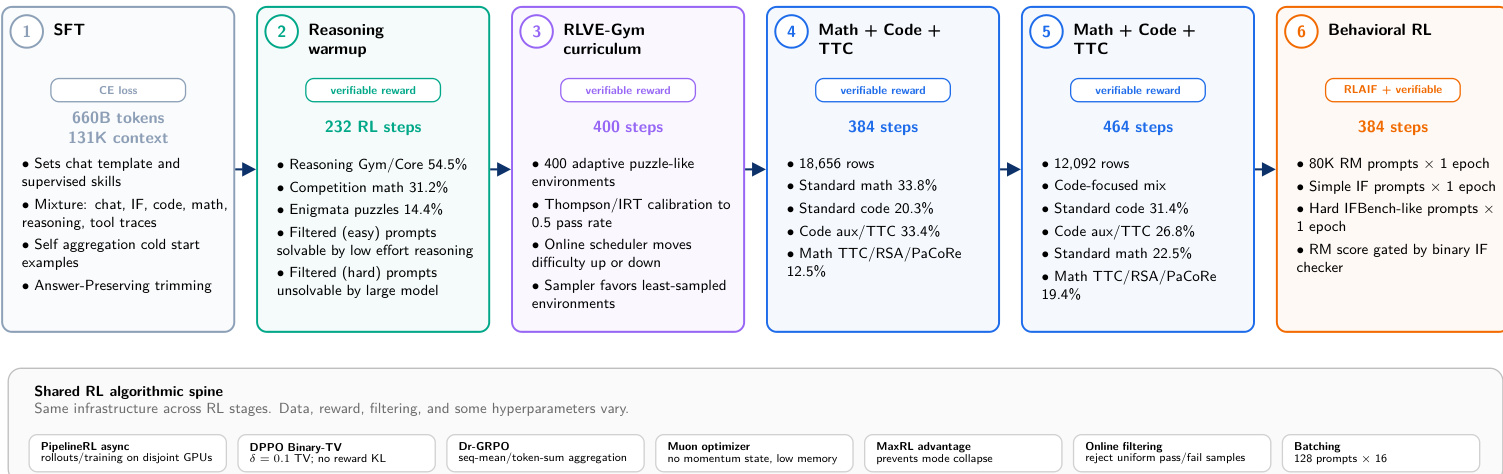
我们推出了 ZAYA1-8B,这是一款专注于推理能力的混合专家(MoE)模型,拥有 7 亿活跃参数和 80 亿总参数,基于 Zyphra 的 MoE++ 架构构建。ZAYA1-8B 的核心预训练、中期训练(midtraining)以及监督微调(SFT)均在由 AMD 提供的全栈计算、网络及软件平台上完成。凭借不到 10 亿的活跃参数,ZAYA1-8B 在多项具有挑战性的数学和代码基准测试中表现持平或超越 DeepSeek-R1-0528,且在与参数量大得多的开源权重视推理模型竞争中保持显著竞争力。ZAYA1-8B 从零开始专为推理任务训练,自预训练阶段起便通过一种保留答案的修剪(answer-preserving trimming)方案整合推理数据。后训练阶段采用四阶段强化学习(RL)级联策略:首先在数学和谜题上进行推理热身;随后执行包含 400 个任务的 RLVE-Gym 课程;接着进行结合测试时计算痕迹(test-time compute traces)和基于竞技编程参考构建的合成代码环境的数学与代码强化学习;最后进行用于聊天和指令跟随的行为强化学习。此外,我们还引入了马尔可夫逆向思维搜索(Markovian RSA)这一测试时计算(test-time compute)方法,该方法在轮次间仅向前传播有界长度的推理尾部,同时递归聚合并行推理轨迹。在测试时计算(TTC)评估中,Markovian RSA 使 ZAYA1-8B 在 AIME'25 上达到 91.9% 的正确率,在 HMMT'25 上达到 89.6%,同时仅向前传播 4K token 的尾部,从而显著缩小了与包括 Gemini-2.5 Pro、DeepSeek-V3.2 和 GPT-5-High 在内的更大型推理模型之间的差距。
一句话总结
基于 Zyphra 的 MoE++ 架构并在完整的 AMD 计算、网络和软件平台上训练,ZAYA1-8B 混合专家模型拥有 7 亿活跃参数和 80 亿总参数,通过四阶段 RL 级联,在具有挑战性的数学和编码基准测试中匹配或超越 DeepSeek-R1-0528,同时 Markovian RSA 测试时计算在带有 4K token 尾部的情况下在 AIME'25 上达到 91.9%,在 HMMT'25 上达到 89.6%,缩小了与包括 Gemini-2.5 Pro、DeepSeek-V3.2 和 GPT-5-High 在内的更大模型之间的差距。
核心贡献
- 这项工作介绍了 ZAYA1-8B,这是一个以推理为重点的混合专家模型,拥有 7 亿活跃参数,基于 Zyphra 的 MoE++ 架构构建。该系统在完整的 AMD 平台上从头训练,在数学和编码基准测试中匹配了更大模型如 DeepSeek-R1-0528 的性能。
- 该论文提出了 Markovian RSA,这是一种测试时计算方法,递归聚合并行推理轨迹,同时仅携带有界长度的推理尾部。该技术将 AIME'25 的性能提升至 91.9%,HMMT'25 的性能提升至 89.6%,同时保持上限注意力成本和可预测的吞吐量。
- 训练流程整合了该方法,使模型通过提供无验证器聚合示例进行监督微调,从而在推理时使用相同的工作流程。这种方法利用包含推理热身、课程学习和行为强化的四阶段 RL 级联。
引言
大型语言模型中的高级推理能力通常需要大量的参数数量和计算资源,这为注重效率的应用设置了障碍。先前的方法往往难以在训练期间管理长推理轨迹,并且未能将测试时计算策略直接整合到模型学习过程中。本文介绍了 ZAYA1-8B,这是一个基于增强型 MoE++ 架构构建的拥有 7 亿活跃参数的混合专家模型,完全在 AMD 硬件上训练。为了缩小与更大系统之间的性能差距,研究引入了 Markovian RSA,这是一种测试时计算方法,递归聚合具有有界上下文的并行推理轨迹,使模型能够匹配或超越显著更大的推理基准。
数据集
数据集组成和来源
- 该模型从包含代码、数学、多语言和推理数据的广泛网络爬取分布中初始化。
- 中期训练和 SFT 阶段利用粗略数据类别,重点强调长思维链推理轨迹。
- 具体的聚合数据来源包括 OpenMathReasoning、rStar-Coder 以及内部推理 gym 和 enigmata 数据集。
每个子集的关键细节
- 基础预训练包括第二阶段,在 4K 上下文长度下增加代码、数学、推理和指令格式数据的权重。
- 以推理为重点的中期训练阶段在 32K 上下文下运行 1.2T tokens,RoPE 基础频率为 1M。
- 监督微调在 131K 上下文下进行 660B tokens,RoPE 基础频率为 5M。
- 聚合示例构建于包含多个专家模型 rollout 的问题,通常每个问题有 n=8 个样本。
数据使用和混合比例
- 中期训练和 SFT 的数据混合百分比归一化于非零混合权重,而不是报告单个数据集名称。
- Markovian RSA 示例在强化学习阶段整合到标准提示分布中。
- 训练采用使用专家模型 rollout 的专家聚合,以及使用当前或先前检查点轨迹的自我聚合。
处理和构建策略
- 基于聚合的训练示例通过离线采样 C 次 rollout 并提取其推理尾部来构建。
- 包含问题和选定尾部的聚合提示使教师模型产生新的聚合 rollout 作为目标。
- 上下文扩展在 32K 时使用两个 rank 进行 all-gather KV 上下文并行,在 131K 时使用八个 rank。
- 压缩 KV 表示在保持激活和内存开销低的同时处理卷积和值移位边界条件。
方法
ZAYA1-8B 模型利用混合专家 (MoE) 架构,并进行特定修改以提高效率和性能。该设计结合了压缩卷积注意力 (CCA),在压缩潜在空间中执行序列混合。该模块减少了训练和预填充的计算需求,同时保持有竞争力的 KV-cache 压缩率。注意力机制的内部结构涉及查询、键和值的投影,随后进行深度和头卷积以及时延。
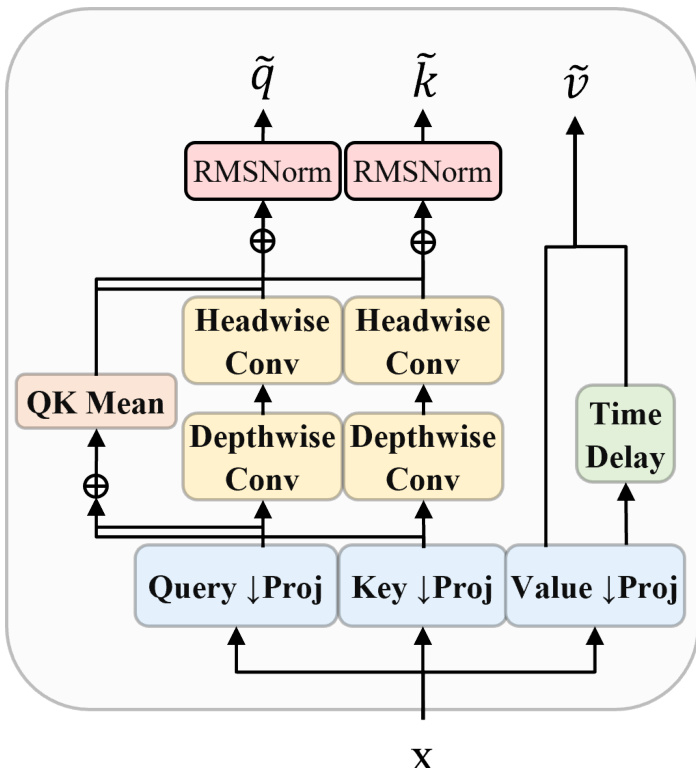
路由机制用增强指数深度平均 (EDA) 的基于 MLP 的设计取代了标准线性路由器。这使得路由器能够使用学习到的系数将当前层的表示与前一层的表示相结合。路由器首先通过 rl=Wdownxl 将残差流 xl 下投影到较小维度 R。整体框架具有 16 个专家,并包括残差缩放以控制信息流和残差范数增长。完整架构集成了嵌入层、自注意力块以及专门的路由器和 CCA 模块。
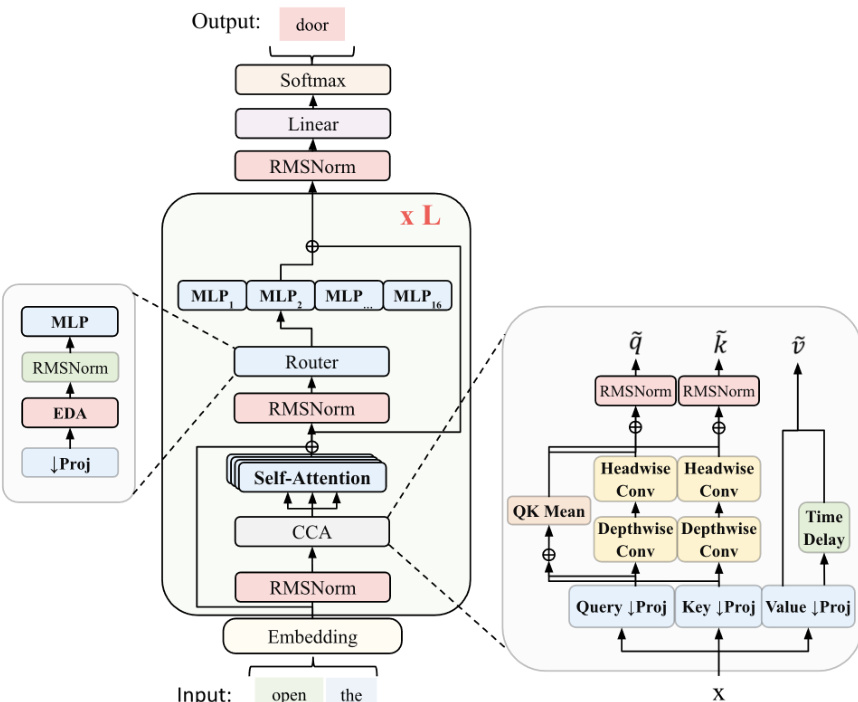
训练过程始于采用答案保留修剪的监督微调和预训练阶段。该策略通过截断推理轨迹的尾部同时保持最终答案完整来管理长思维链数据。这确保了模型即使在上下文长度短于完整轨迹时也能从连贯的推理序列中学习。在此阶段,模型被优化以在保留的答案部分内对正确 tokens 保持高概率。
训练后通过由六个阶段组成的结构化强化学习级联进行。流程从 SFT 开始,经过推理热身、RLVE-Gym 课程以及数学和编码任务,最后以行为 RL 结束。共享算法主干支持 RL 阶段,利用异步 rollout 生成和特定优化技术如无动量 Muon。这一进展优先考虑可验证的推理能力,然后再针对通用聊天和指令跟随进行调整。
对于推理,系统采用 Markovian RSA 利用测试时计算以提高准确性。该方法生成多个候选推理轨迹,并通过从总体中下采样尾部来聚合它们。该过程创建结合原始问题和候选尾部的聚合提示,使模型能够合成单个改进的解决方案。这种方法限制了聚合的上下文大小,同时支持跨多轮次的深度推理。
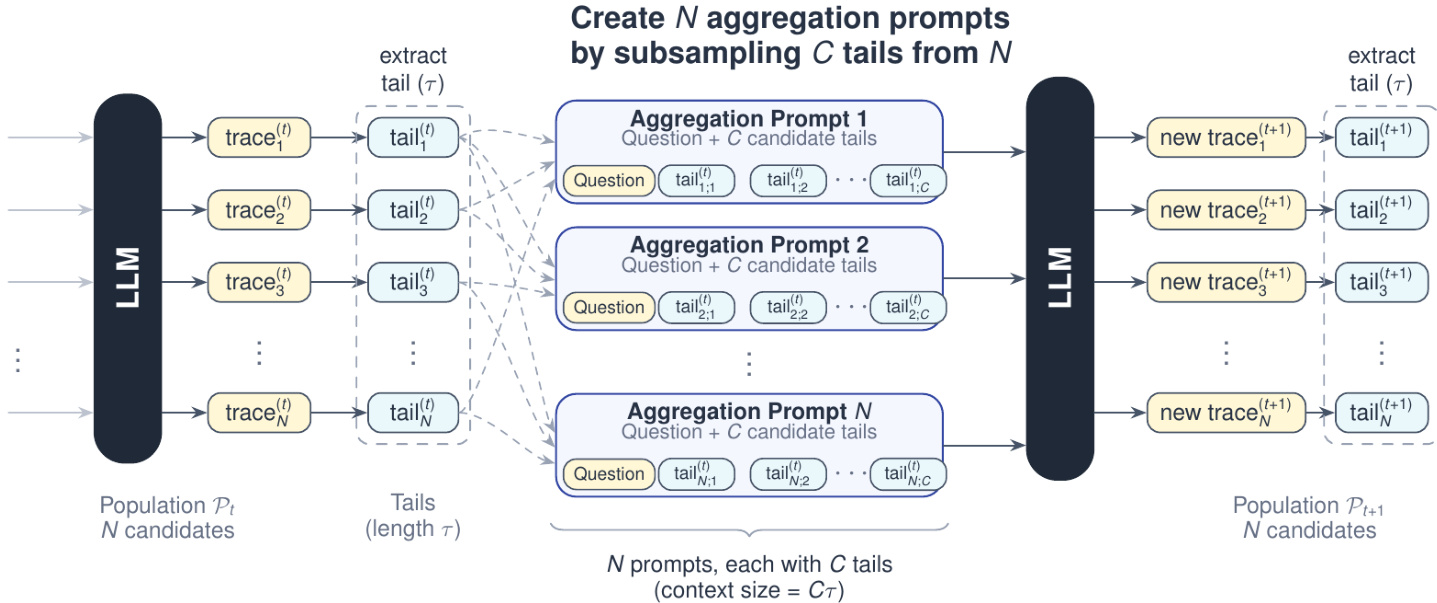
实验
利用 Zyphra harness 的评估将 ZAYA1-8B 与显著更大的开源权重模型进行比较,以评估在标准和测试时计算设置下的推理能力。结果表明,Markovian RSA 实现了高效的推理扩展,使紧凑模型在保持有界上下文长度的同时接近前沿数学性能。训练后实验显示,强化学习在监督微调之上产生了显著收益,且优化步骤最少,突显了模型的样本效率。最终,研究得出结论,小型活跃参数模型在辅以结构化测试时计算的情况下,可以在推理任务上与更大系统媲美,尽管在 agentic 和事实基准方面仍存在差距。
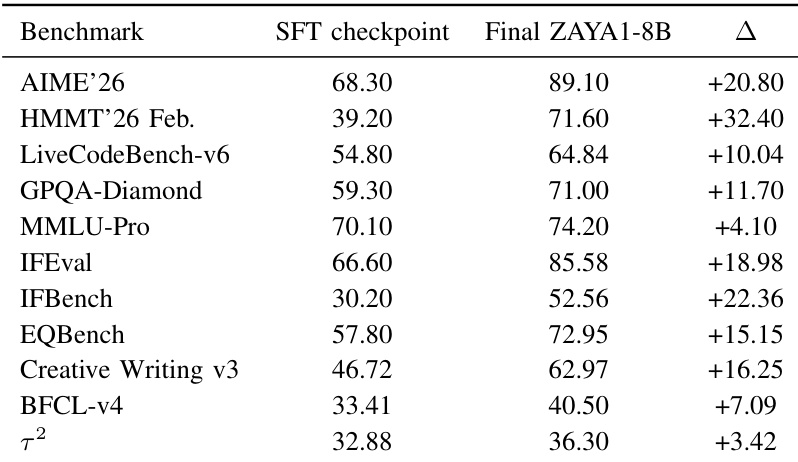
比较 SFT 检查点与最终 ZAYA1-8B 模型以测量训练后 RL 级联的聚合效应。结果表明,在所有评估的基准测试中性能普遍提升,最显著的改进发生在数学推理和编码任务中。数学推理基准相对于 SFT 基线表现出最大的性能增益。编码任务显示出显著改进,而指令跟随基准也记录了强劲收益。通用知识和 agentic 基准显示出一致的积极增长,尽管程度不如推理任务。
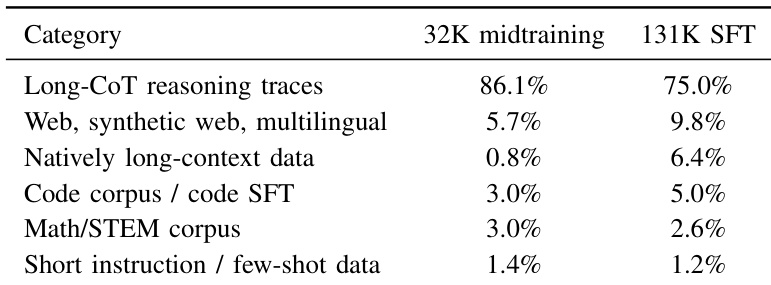
该表格比较了 32K 中期训练阶段和 131K SFT 阶段之间的数据组成。Long-CoT 推理轨迹主导中期训练数据集,而 SFT 阶段通过增加原生长上下文数据和基于网络内容的份额来多样化训练混合。Long-CoT 推理轨迹占中期训练数据集的多数,但在 SFT 阶段减少。与中期训练相比,SFT 阶段中原生长上下文数据显著增加。SFT 阶段包含比中期训练阶段更高比例的 web、合成和多语言数据。
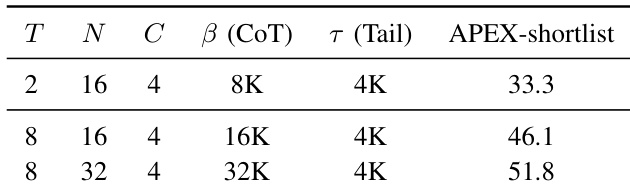
研究评估了使用 Markovian RSA 时,变化推理时计算参数如何影响 APEX-shortlist 基准的性能。通过调整聚合轮次、种群大小和推理预算,观察到计算强度与模型准确性之间存在明显的正相关。资源最密集的配置产生最高性能,证明了为困难推理任务扩展测试时计算的有效性。增加聚合轮次和种群大小显著提升了基准性能。最强的配置利用最大的推理预算和最深的聚合深度。性能在所有测试参数上随更高的计算分配呈正相关扩展。
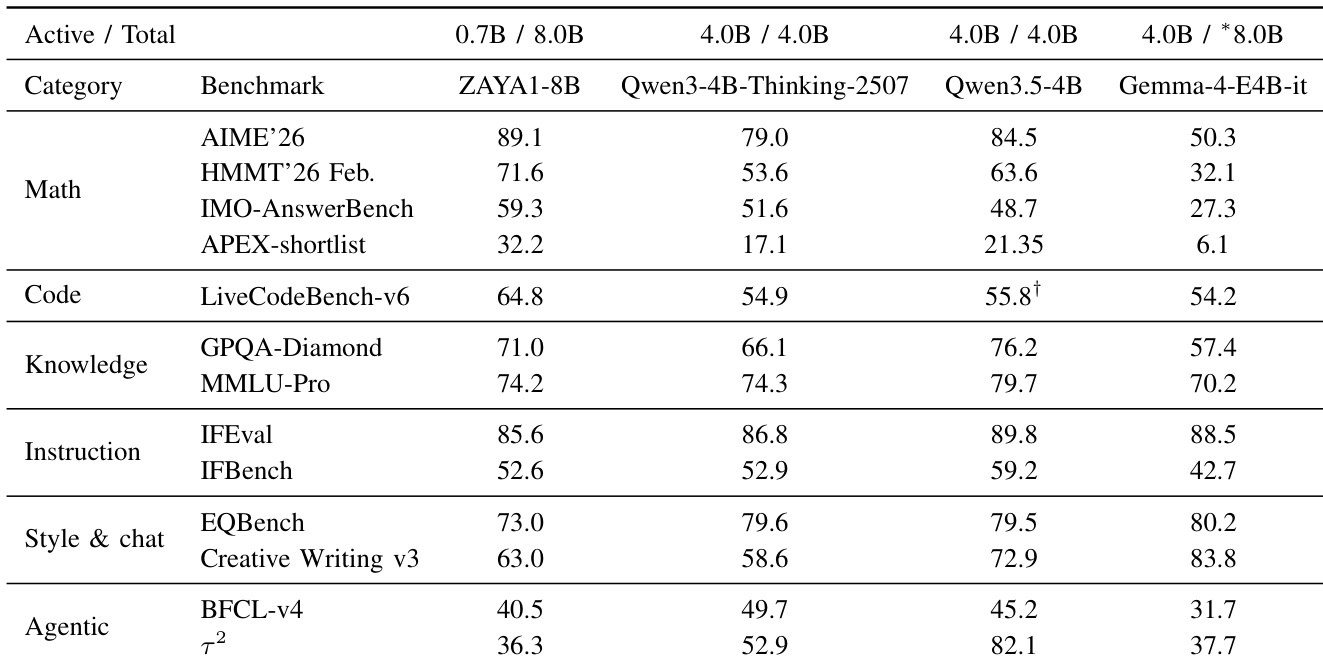
数据说明了两个不同强化学习阶段之间提示类别的分布。虽然通用阶段具有更高比例的标准数学和辅助代码提示,但代码重点阶段转向标准代码和高级推理提示。标准代码提示在第二阶段显著增加。标准数学提示在代码重点阶段大幅下降。Math TTC 和 RSA 等高级推理提示在后期阶段变得更加常见。
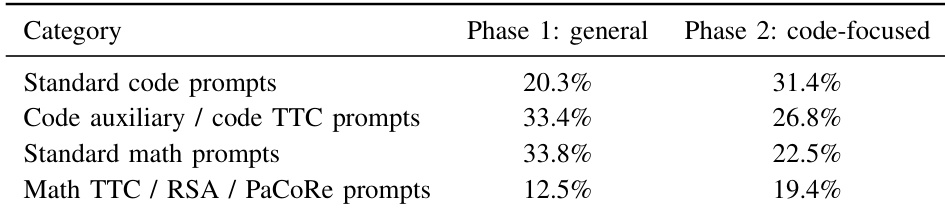
研究将 ZAYA1-8B 与可比规模的开源权重推理模型进行比较,重点关注活跃和总参数数量。结果显示,尽管 ZAYA1-8B 使用的活跃参数少于比较模型,但在数学和编码任务中仍实现了领先性能。相反,与 4B 活跃参数基线相比,该模型在知识密集型和指令跟随基准上的得分较低。ZAYA1-8B 在所有列出的数学基准测试中超越比较器,包括 AIME 和 HMMT。该模型在 LiveCodeBench-v6 编码评估中实现了最高分。Qwen3.5-4B 通常在知识和指令跟随指标上优于 ZAYA1-8B。
通过比较最终状态与 SFT 基线并分析训练阶段之间的数据组成变化,评估了 ZAYA1-8B 模型。结果证实,训练后 RL 级联带来了普遍的性能提升,特别是在数学推理和编码任务中,扩展测试时计算参数与准确性呈正相关。尽管该模型在使用更少活跃参数的情况下在数学和编码方面相对于比较器实现了领先分数,但与具有更高活跃参数数量的基线相比,它在知识密集型和指令跟随基准上表现出较低性能。