Command Palette
Search for a command to run...
超越语义相似性:通过直接与语料库交互重新思考代理搜索中的检索
超越语义相似性:通过直接与语料库交互重新思考代理搜索中的检索
摘要
现代检索系统,无论是基于词汇的还是基于语义的,都通过一个固定的相似度接口暴露语料库,在推理之前将访问压缩为单次 top-k 检索步骤。这种抽象方式虽然高效,但对于 agentic search 而言,却成为了瓶颈:难以通过调用传统的现成检索器来实现精确的词汇约束、稀疏线索的联合、局部上下文检查以及多步假设的细化;而早期被过滤掉的证据无法通过后端更强的推理能力予以恢复。Agentic 任务进一步加剧了这一局限性,因为这类任务要求 agent 协调多个步骤,包括发现中间实体、组合微弱线索以及在观察到部分证据后修正计划。为了解决这一局限性,我们研究了直接语料库交互(Direct Corpus Interaction, DCI)。在该方法中,agent 使用通用终端工具(例如 grep、文件读取、Shell 命令和轻量级脚本)直接搜索原始语料库,无需任何嵌入模型、向量索引或检索 API。这种方法无需离线索引,并能自然地适应不断演变的本地语料库。在信息检索(IR)基准测试和端到端 agentic search 任务中,这种简单配置在多个 BRIGHT 和 BEIR 数据集上显著优于强大的稀疏、密集和重排序基线模型,并在 BrowseComp-Plus 和多跳问答任务中实现了高精度,且完全不依赖任何传统的语义检索器。我们的结果表明,随着语言 agent 能力的增强,检索质量不仅取决于推理能力,还取决于模型与语料库交互界面的粒度(resolution)。DCI 为 agentic search 开启了一个更广阔的界面设计空间。
一句话总结
作者提出了直接语料库交互(Direct Corpus Interaction, DCI),这是一种 Agent 搜索框架。该框架以针对原始语料库的直接终端查询取代固定的相似度接口,利用通用终端工具替代向量嵌入,从而在不依赖离线索引的情况下,实现迭代式多步推理、恢复早期过滤的证据,并适应不断演变的本地数据集。
核心贡献
- 本文将直接语料库交互(DCI)形式化为一种替代性检索范式,该范式利用 grep 和 shell 命令等通用终端工具,使 agent 能够直接访问原始语料库,从而取代固定的 top-k 相似度接口。
- 消除离线索引需求使得细粒度模式匹配和精确证据定位成为可能,使 agent 能够迭代验证线索并适应不断演变的本地数据集。
- 在面向排序的信息检索、多跳问答以及端到端 agentic 搜索基准测试中的评估表明,DCI 实现了具有竞争力的性能。轨迹级分析揭示,这一优势源于检索接口分辨率的提升,它将表面化的证据转化为更高价值的本地检查与组合式搜索步骤。
引言
检索增强流水线通常在推理开始前,将语料库访问压缩为使用稀疏或稠密相似度模型的固定 top-k 检索步骤。这种抽象成为 agentic 搜索的关键瓶颈,因为 agent 需要精确的词汇约束、稀疏线索组合以及本地上下文验证,而标准检索器若要在过程中早期丢弃潜在有价值的证据,则无法支持这些需求。作者提出了直接语料库交互(DCI),在该范式中,agent 绕过传统检索 API,直接使用 grep 和 shell 命令等通用终端工具与原始语料库交互。该方法消除了对离线索引或嵌入模型的需求,使 agent 能够组合灵活的搜索操作以实现精确的证据定位和迭代优化,同时在多个基准测试中超越强大的基线模型。
数据集
-
数据集构成与来源 作者使用精心整理的封闭式与开放式领域基准测试集来评估检索增强推理。Agentic Search 套件依赖 BrowseComp-Plus,这是一个源自 BrowseComp 查询的固定语料库,并增加了人工验证的支持文档与挖掘出的难负样本。Knowledge-Intensive QA 套件整合了六个成熟数据集:NQ 和 TriviaQA 用于单跳事实检索,Bamboogle、HotpotQA、2WikiMultiHopQA 和 MuSiQue 用于多跳顺序推理。IR Ranking 套件在四个科学领域上采用了 BRIGHT,并包含异构 BEIR 基准测试中的两个子集。
-
各子集关键细节 BrowseComp-Plus 包含复杂的跨文档综合问题,需要深度证据检索。QA 数据集涵盖从维基百科衍生的单跳任务到人工构建的多跳挑战,后者强制要求精确的推理步骤或提供带标注的推理链。BRIGHT 提供针对生物学(103)、地球科学(116)、经济学(103)和机器人学(101)的领域特定查询。BEIR 评估从 ArguAna(共 1,406 个)和 SciFact(共 300 个)中各采样 50 个查询。作者明确过滤了模糊问题和时效性问题,以防止语料库漂移。
-
数据使用与处理 基准数据仅作为离线评估套件使用,而非训练语料库。检索基线使用官方 BrowseComp 语料库,结合 BM25 和 Qwen3-Embedding-8B(通过 FAISS)构建固定搜索索引。对于 DCI agent,作者完全跳过索引构建步骤,授予其直接访问同一文档存储的终端权限。BEIR 子集经过降采样处理,以在各基准测试中保持计算开销一致。
-
元数据构建与格式化策略 作者使用平均空格分割词长来跟踪文档统计信息,以标准化语料库比较。检索协议通过结构化的系统提示词强制执行,要求并行执行 grep 和 bash 搜索、穷举关键词变体以及强制置信度评分。输出格式化要求提供带完整相对路径、行内引用和逐步推理链的排序文档列表,以确保检索质量和最终答案生成的透明评估。
方法
作者利用双范式框架进行 agentic 搜索,对比了检索器中介访问与直接语料库交互(DCI)。在检索器中介范式中,agent 向已部署的检索器提交查询,该检索器访问预构建的语料库索引,并返回 top-k 片段排序列表。agent 的观察结果仅限于这些片段和文档标识符,所有证据均需通过检索器的评分与排序接口进行过滤。该方法依赖独立的索引构建流程,并限制了 agent 对检索接口的控制权。
相比之下,DCI 范式(即本文方法的焦点)使 agent 能够绕过检索器,直接使用通用命令行界面(CLI)与原始语料库交互。如图所示,agent 发出 grep、rg、find、glob、read 和 python 脚本等工具调用,以执行精确或正则表达式匹配、导航文件系统并检查匹配项周围的本地上下文。产生的观察结果是工具输出,包括带周围上下文的匹配片段、文件路径、计数和元数据,而非固定格式的排序列表。这种直接访问提供了更高分辨率的搜索接口,使 agent 能够探查特定术语、打开完整文件,并提取新的实体或约束,从而为后续搜索行动提供依据。
为了管理长轨迹中可能积累的大量工具输出,DCI-Agent-Lite 系统集成了一个轻量级运行时上下文管理层,如下图所示。该层围绕三种机制构建:截断(Truncation)在将每次工具调用的文本重新插入实时工作上下文之前对其进行长度限制,在保留观察发生记录的同时限制单轮冗长度。压缩(Compaction)是一种内存内、零大语言模型操作,当累积工具输出超过配置阈值时,清除旧工具结果轮次的内容,并用保留工具调用结构的简短占位符替换这些轮次。摘要(Summarization)是一种更高干预程度的策略,在额外上下文压力下,将压缩后的历史替换为模型生成的摘要,同时保持最新上下文完整。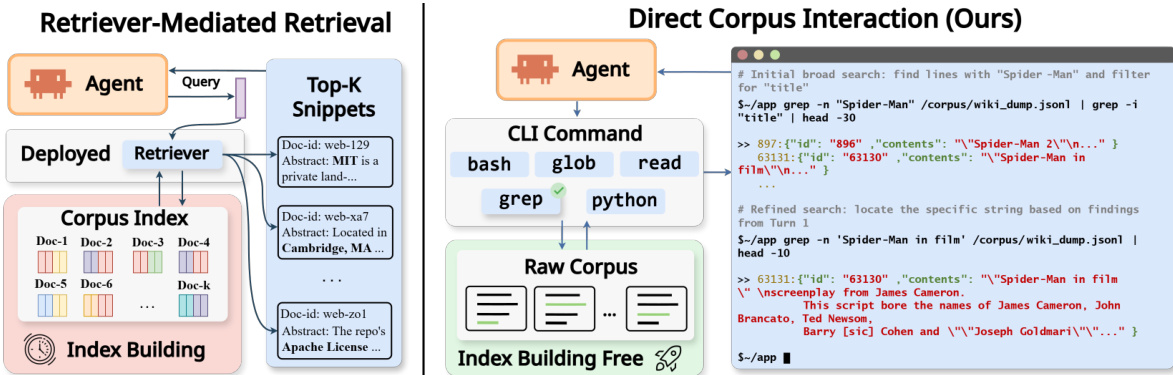 这些机制通过一系列上下文管理策略实现,每种策略启用不同子集机制并设定不同激进程度,从而允许对其性能影响进行可控分析。
这些机制通过一系列上下文管理策略实现,每种策略启用不同子集机制并设定不同激进程度,从而允许对其性能影响进行可控分析。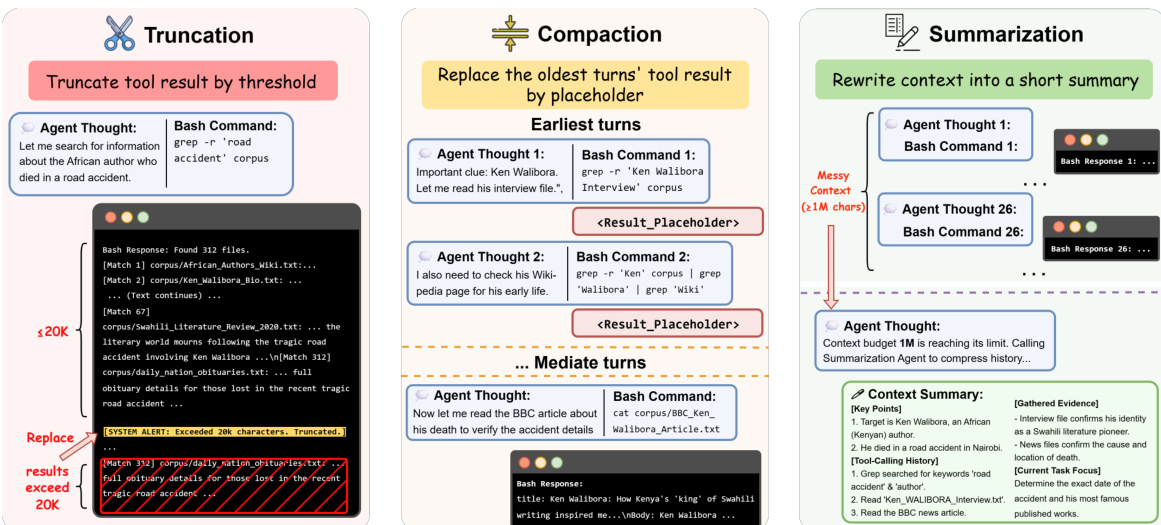
实验
评估在 agentic 搜索、知识密集型问答和 IR 排序基准测试中,将两种 DCI agent 实现与传统检索基线进行对比,以验证该范式的整体有效性与运行机制。主要结果证实,DCI 通过利用组合式 bash 交互迭代缩小搜索空间并验证精确证据片段,而非依赖全面文档召回,从而在准确性和成本效率方面持续优于传统流水线。受控消融实验进一步验证了该方法以广泛的语料库覆盖换取高分辨率本地检查,在搜索深度上展现出强可扩展性,但在极端语料库广度下性能显著下降。最后,工具与上下文管理分析表明,最小化表达能力与选择性调优的压缩策略捕获了大部分性能提升,凸显了 DCI 作为高效直接语料库交互框架的地位。
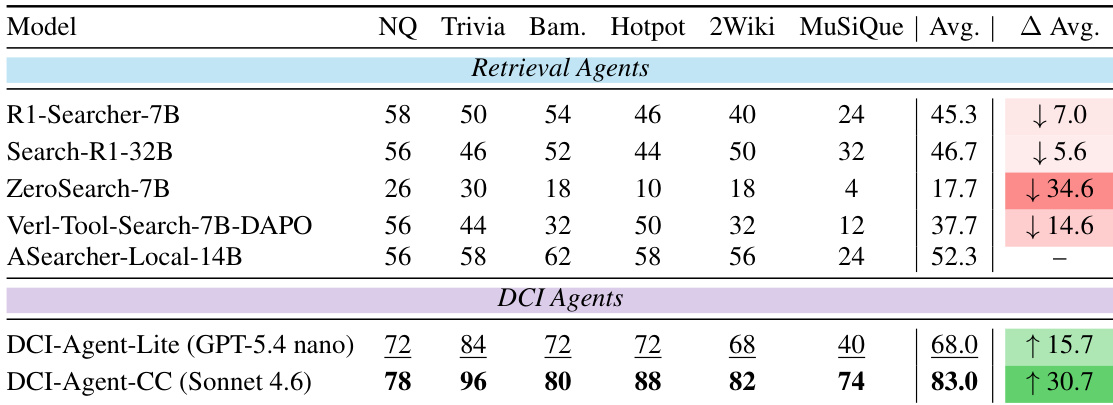
作者在不同知识密集型问答任务中将 DCI agent 与基于检索的基线进行对比,结果显示 DCI agent 在多个数据集上实现了更高的准确率。DCI-Agent-CC 持续优于所有检索 agent,而 DCI-Agent-Lite 即使使用最小化工具集也取得了具有竞争力的结果。DCI agent 在知识密集型问答任务中显著优于基于检索的基线。DCI-Agent-CC 在所有评估数据集上取得最高准确率。DCI-Agent-Lite 以最小化工具集提供强劲性能,展现了高效性与竞争力。
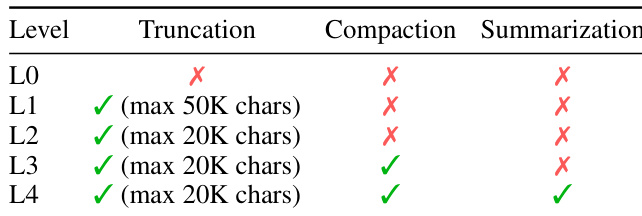
作者通过调整截断、压缩和摘要的不同程度,评估了 DCI-Agent-Lite 的多种上下文管理策略。结果表明,更激进的上下文管理并不能持续提升性能,策略强度与准确率之间存在非单调关系,在中间程度达到最佳平衡。表现最佳的策略结合了截断与压缩,但不包含摘要。上下文管理策略对性能产生非单调影响,中间程度优于最小化与最大化策略。最优策略结合截断与压缩,不包含摘要。更高的上下文保留率并不必然带来更好的准确率,表明选择性遗忘能够支持持续的多步推理。
作者在多个基准测试中评估了 DCI agent 的两种实现:最小化脚手架与增强版。结果表明,与基于检索的基线相比,DCI agent 使用更少的工具和更低的成本实现了高准确率,尤其在知识密集型问答和信息检索任务中。最小化的 DCI-Agent-Lite 变体在工具集受限且保持成本效率的同时,表现出强劲的竞争力。DCI agent 与基于检索的基线相比,使用更少工具和更低成本实现高准确率。DCI-Agent-Lite 即使在最小化工具集和低成本模型下,在知识密集型问答任务中仍具竞争力。最小化 DCI 实现在多个基准测试的准确率与成本效率上均优于检索 agent。
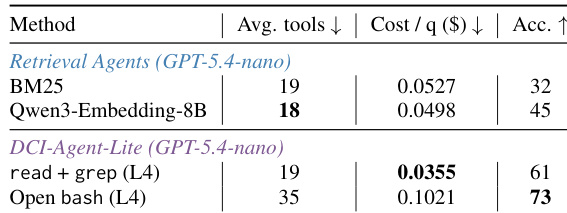
作者在包含 agentic 搜索、知识密集型问答和 IR 排序的多个基准测试中,评估了 DCI agent 的两种实现:轻量版与增强版。结果表明,两种 DCI agent 均取得强劲性能,增强版优于基于检索的基线,轻量版则提供高成本效益的替代方案。轻量版 agent 以低成本实现高准确率,而增强版 agent 尽管资源消耗较高,仍展现出卓越性能。DCI-Agent-CC 在所有评估 agent 中取得最高准确率,优于基于检索的基线及其他强模型。DCI-Agent-Lite 以显著更低的成本提供强劲准确率,确立了其高成本效益替代方案的地位。轻量级 DCI 实现以最小化工具使用达成高性能,证明了其在严格预算约束下的有效性。
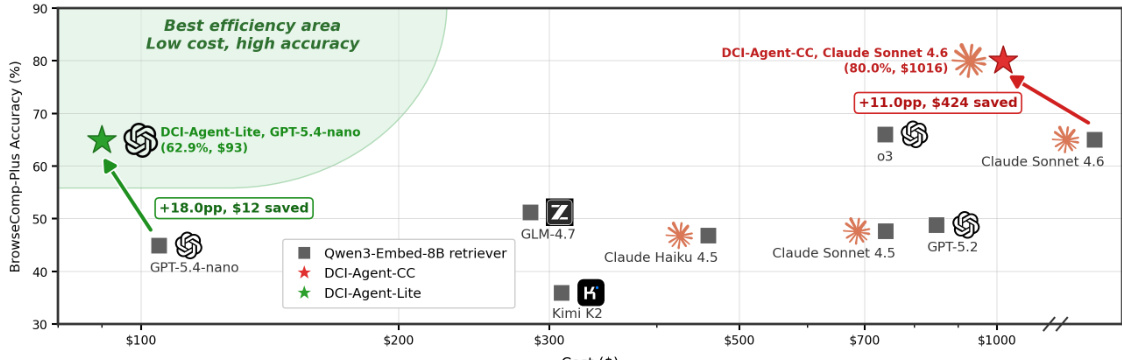
作者将最小化终端 agent DCI-Agent-Lite 与使用传统方法的检索 agent 进行对比。DCI-Agent-Lite 在精度与定位能力上表现更优,但使用了更多工具并产生更高成本,表明精度与效率之间存在权衡。结果表明,与传统检索方法相比,与语料库的直接交互能够实现更高效的证据检索与推理。DCI-Agent-Lite 尽管使用更多工具且成本更高,在准确率与定位能力上仍优于检索 agent。与语料库的直接交互相较于基于检索的方法带来了更好的证据定位与更高准确率。工具使用与性能之间的权衡凸显了 DCI 在细粒度证据组合与验证方面的有效性。

评估在多个知识密集型问答、搜索和信息检索基准测试中,将 DCI agent 与基于检索的基线进行对比,同时验证了不同的上下文管理策略。结果表明,直接语料库交互实现了更优的证据定位与推理能力,完整 DCI 变体持续取得最高准确率,轻量变体则提供极具竞争力的高成本效益替代方案。上下文策略实验验证了适度截断与压缩(不含摘要)能够在信息保留与持续多步推理之间实现最佳平衡。总体而言,研究结果表明,选择性上下文处理与直接交互在精度与效率方面均优于传统检索方法。