Command Palette
Search for a command to run...
D-OPSD:用于持续微调步骤蒸馏扩散模型的策略自蒸馏方法
D-OPSD:用于持续微调步骤蒸馏扩散模型的策略自蒸馏方法
摘要
高性能图像生成模型的格局目前正从低效的多步模型向高效少步模型(例如 Z-Image-Turbo 和 FLUX.2-klein)转变。然而,这些模型给直接进行连续的监督微调(SFT)带来了巨大挑战。例如,应用常用的微调技术会损害其固有的少步推理能力。为解决这一问题,我们提出了 D-OPSD,一种面向步骤蒸馏扩散模型的新一代训练范式,能够在监督微调期间实现策略内(on-policy)学习。我们首先发现,采用 LLM 或 VLM 作为编码器的现代扩散模型能够继承其编码器的上下文学习能力(in-context capabilities)。这使得我们可以将训练过程转化为策略内自蒸馏(on-policy self-distillation)过程。具体而言,在训练过程中,我们让模型在不同语境下同时扮演教师和学生角色:学生仅以文本特征为条件,而教师则以文本提示和目标图像的多模态特征为条件。训练过程旨在最小化学生自身 rollout(轨迹生成)上两个预测分布之间的差异。通过对模型自身轨迹进行优化并在其自身监督下学习,D-OPSD 使模型能够学习新概念、新风格等,而不会牺牲原有的少步推理能力。
一句话总结
作者提出了 D-OPSD,这是一种针对步数蒸馏扩散模型的训练范式,通过最小化学生在自身轨迹上预测的分布,同时让学生基于文本特征进行条件设定,让教师基于文本提示和目标图像的多模态特征进行条件设定,从而保留固有的少步推理能力,实现了通过在线策略自蒸馏进行连续监督微调。
核心贡献
- 本文介绍了 D-OPSD,这是一种针对步数蒸馏扩散模型的训练范式,支持在监督微调期间进行在线策略学习。
- 该框架利用现代编码器的涌现上下文能力来促进自蒸馏,其中模型在不同多模态和纯文本条件下同时充当教师和学生。
- 跨 LoRA 适配和全量微调的实验表明,该方法在保留原始少步生成能力的同时,有效地学习了新概念和风格。
引言
文本到图像扩散模型取得了显著进步,但其迭代采样过程产生了高昂的计算成本,步数蒸馏技术旨在缓解这一问题。然而,持续微调这些高效模型面临重大挑战,因为传统的监督微调会通过训练 - 测试不匹配破坏已学习的少步动态。在线强化学习提供了一种解决方案,但通常需要开发人员难以实现的奖励函数。作者通过 D-OPSD 解决了这些问题,这是一种新颖的在线策略自蒸馏框架,利用基于现代 LLM 编码器的涌现上下文能力。通过使模型在训练期间同时充当学生和老师,该方法允许在模型自身的轨迹上进行监督适配,而无需外部奖励。因此,在保留原始少步推理能力的同时学习了新概念。
方法
作者提出了 D-OPSD,这是一种旨在为步数蒸馏扩散模型启用在线策略学习的训练范式。该方法解决了标准监督微调损害现代高效模型固有少步推理能力的挑战。核心思想利用在线策略自蒸馏,其中模型在不同上下文条件下同时充当教师和学生。
参考框架图以获取方法的视觉概述。
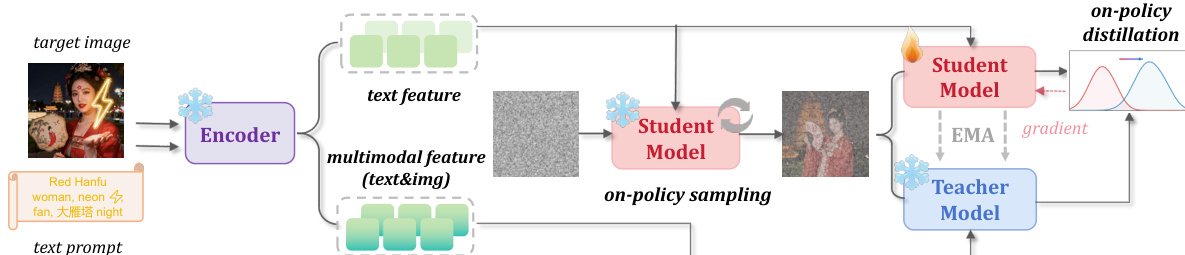
该过程始于一个编码器,它处理输入文本提示和目标图像。对于每个训练对,系统构建两个不同的条件向量。学生条件 cs 仅源自文本提示,确保学生分支遵循原始文本到图像生成路径。相比之下,教师条件 ct 结合了来自文本提示和目标图像的多模态特征。这种多模态上下文允许教师在不干扰学生采样轨迹的情况下,提供关于目标概念或风格的更强监督。
在训练期间,学生模型通过从使用少步求解器的高斯噪声中采样来生成在线策略轨迹。令 xtks 表示第 k 步的潜在状态。学生预测速度场 uks=vθ(xtks,tk,cs)。同时,由学生权重的指数移动平均 (EMA) 参数化的教师模型,在学生生成的完全相同的状态上预测速度 ukt=vθˉ(xtks,tk,ct)。此设置确保监督是在模型自身的轨迹上计算的,而不是外部离线分布。
优化目标最小化学生速度预测与这些共享状态上教师预测之间的均方误差。损失函数表述为:
LD-OPSD=E(x0,y)[K1k=1∑Kuks−sg(ukt)22]其中 sg(⋅) 表示停止梯度操作。通过将学生的条件生成动态与教师的更强多模态引导对齐,模型在学习新概念或风格的同时保留了原始的少步采样行为。训练完成后,丢弃教师分支,推理仅使用基于文本的标准化少步流程进行。
实验
评估利用 Z-Image-Turbo 和 FLUX.2-klein 模型,将所提出的方法与 Vanilla SFT 和 Dreambooth 等基线进行比较,涵盖小规模 LoRA 和大规模全量微调场景。实验结果表明,虽然标准训练方法往往会损害少步生成质量或遭受过拟合,但所提出的方法有效地学习了新概念并适应新领域,且没有灾难性遗忘。此外,消融研究验证了与离线策略变体相比,在线策略自蒸馏对于保持高生成质量和实现更快收敛至关重要。
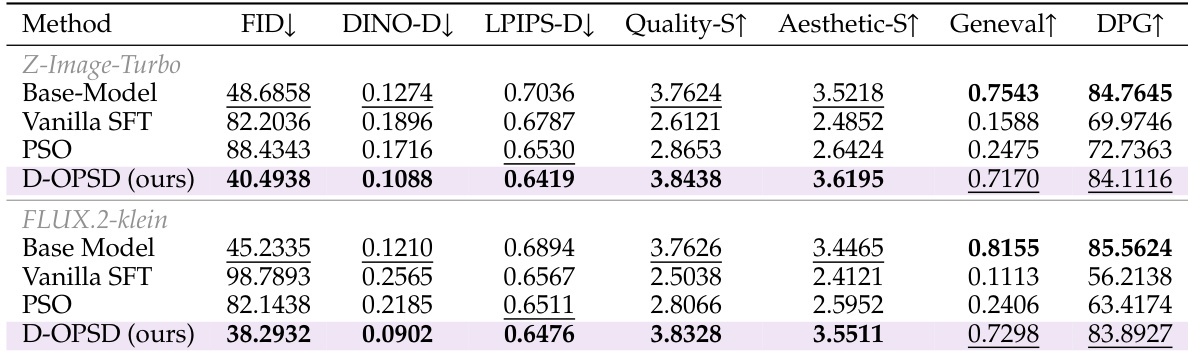
作者将提出的 D-OPSD 方法与 Vanilla SFT 和 PSO 等基线在 Z-Image-Turbo 和 FLUX.2-klein 架构上进行了比较。结果表明,D-OPSD 实现了与目标图像更好的对齐,同时保留了模型原始的少步生成质量和通用知识保留能力。相比之下,基线方法在图像质量和能力保留方面遭受显著下降。D-OPSD 在图像相似度指标中实现了比 Vanilla SFT 和 PSO 更低的错误率。所提出的方法保留了少步采样能力,质量得分接近或超过基础模型。基线方法在通用知识基准测试中表现出显著下降,而 D-OPSD 保留了这些能力。
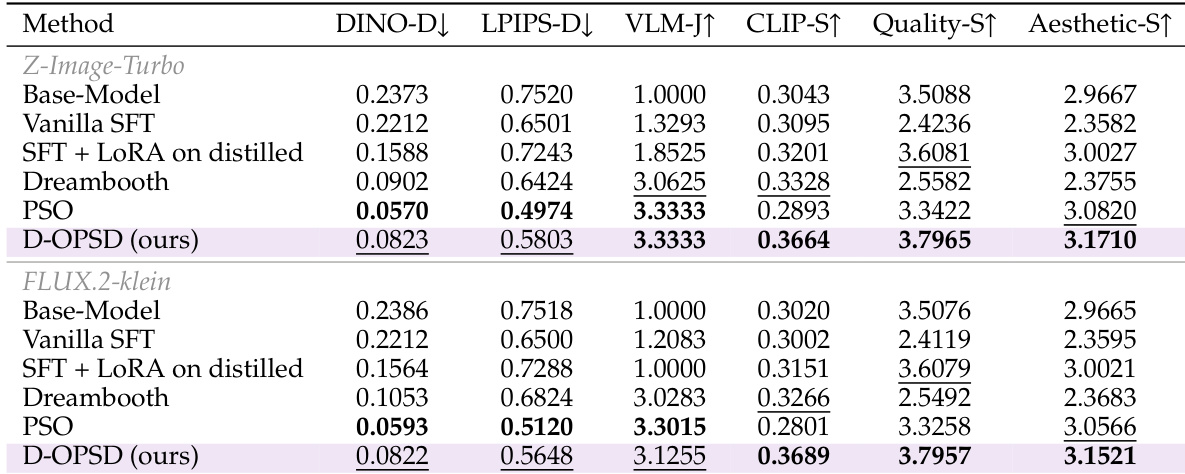
作者使用 Z-Image-Turbo 和 FLUX.2-klein 模型将提出的 D-OPSD 方法与 Vanilla SFT、Dreambooth 和 PSO 等几个基线进行了比较。结果表明,D-OPSD 有效地平衡了学习新概念与保持高图像质量和美学标准,优于那些降低生成能力的方法。D-OPSD 在两种模型配置中均取得了最高的 Quality-S 和 Aesthetic-S 得分,表明其比 SFT 和 Dreambooth 更好地保留了少步采样能力。所提出的方法获得了最高的 CLIP-S 得分,并在 VLM-J 得分上并列第一,证明了强大的泛化能力和主体一致性。虽然 PSO 实现了低距离指标表明强目标对齐,但 D-OPSD 通过保持显著更高的泛化和质量得分避免了过拟合。
该表根据监督信号和训练属性对比了提出的 D-OPSD 方法与标准 SFT、离线 RL 和在线 RL 基线。它表明 D-OPSD 独特地结合了在线策略训练与自蒸馏速度,以确保训练分布与推理分布匹配,而无需外部奖励模型。D-OPSD 是列出的唯一一种实现训练和推理条件匹配的方法。该方法利用带有自蒸馏速度的在线策略采样,而不是真实标签或外部奖励。与在线 RL 方法不同,D-OPSD 不需要单独的奖励模型进行监督。

作者评估了 D-OPSD 与各种基线(包括 Vanilla SFT 和 PSO)在 Z-Image-Turbo 和 FLUX.2-klein 架构上的表现,以评估对齐度和能力保留。结果表明,所提出的方法有效地平衡了学习新概念与保持高图像质量和通用知识,而基线方法遭受显著下降或过拟合。此外,该方法通过在线策略采样独特地对齐了训练和推理分布,无需外部奖励模型。