Command Palette
Search for a command to run...
OpenSearch-VL:前沿多模态搜索代理的开放配方
OpenSearch-VL:前沿多模态搜索代理的开放配方
Shuang Chen Kaituo Feng Hangting Chen Wenxuan Huang Dasen Dai Quanxin Shou Yunlong Lin Xiangyu Yue Shenghua Gao Tianyu Pang
摘要
深度搜索已成为前沿多模态 agent 的关键能力,使模型能够通过主动搜索、证据验证和多步推理来解决复杂问题。尽管取得了快速进展,但顶级多模态搜索 agent 仍难以复现,这主要是由于缺乏开放的高质量训练数据、透明的轨迹合成流程或详细的训练方案所致。为此,我们推出了 OpenSearch-VL,这是一个完全开源的训练方案,用于使用 agentic 强化学习训练前沿多模态深度搜索 agent。首先,我们构建了一个专用流程,通过维基百科路径采样、模糊实体重写和来源-锚点视觉定位来构建高质量训练数据,这些数据共同减少了捷径和单步检索塌陷。基于此流程,我们准备了两个训练数据集:用于 SFT 的 SearchVL-SFT-36k 和用于 RL 的 SearchVL-RL-8k。此外,我们设计了一个多样化的工具环境,统一了文本搜索、图像搜索、OCR、裁剪、锐化、超分辨率和透视校正,使 agent 能够将主动感知与外部知识获取相结合。最后,我们提出了一种多轮致命意识 GRPO 训练算法,该算法通过在一侧优势钳位的同时遮蔽失败后的 token 并保留有用的前置推理,来处理级联工具失败。基于此方案,OpenSearch-VL 带来了显著的性能提升,在七个基准测试中平均提高超过 10 分,并在几项任务上达到了与专有商业模型相当的水平。我们将释放所有数据、代码和模型,以支持多模态深度搜索 agent 的开放研究。
一句话总结
OpenSearch-VL 是一项面向前沿多模态深度搜索 Agent 的开源训练配方,整合了源锚点视觉定位数据流水线、统一工具环境以及多轮致命感知 GRPO 算法。该算法通过保留故障前的推理过程来缓解级联工具故障,在七项基准测试中平均提升超过十分,性能媲美专有商业模型。
核心贡献
- OpenSearch-VL 提供了完全开放的训练配方,通过维基百科路径采样与源锚点视觉定位流水线构建了 SearchVL-SFT-36k 和 SearchVL-RL-8k 数据集。数据准备环节与多样化的工具环境相集成,统一了文本搜索、图像搜索、OCR、裁剪、锐化、超分辨率与透视校正功能,以实现主动感知。
- 该框架实现了多轮致命感知 GRPO 算法,通过掩码化故障后的 token 并在一侧优势截断机制下保留有效的故障前推理,从而缓解级联工具故障。
- 在七项多模态深度搜索基准测试上的综合评估表明,该方法实现了超过十分平均性能提升,并达到与专有商业模型相当的结果。
引言
多模态深度搜索将视觉语言模型从被动的视觉解释器提升为能够动态检索证据并执行多步推理的主动 Agent,这一能力对于解决复杂且知识密集型的视觉查询至关重要。尽管前景广阔,但复现前沿搜索 Agent 仍面临重大障碍,因为领先系统依赖专有数据,缺乏透明的训练流水线,且通常假设存在实践中极少出现的完美视觉输入。现有的 Agent 强化学习方法同样难以应对长周期工具使用场景,其中单个格式错误的调用或视觉退化会引发级联轨迹失败,迫使模型要么丢弃宝贵的故障前推理,要么从带有噪声的故障后 token 中学习。为应对这些挑战,研究团队利用基于维基百科的数据整理流水线生成高质量的多跳数据集,并部署了包含视觉增强与标准检索在内的综合工具环境。研究团队进一步引入了致命感知 GRPO 算法,该算法通过一侧优势截断机制选择性掩码无效的故障后 token,同时保留有效的故障前推理,最终实现了媲美专有商业模型的稳健多模态搜索性能。
数据集
-
数据集构成与来源
- 研究团队通过整合自定义整理的基于维基百科的 VQA 数据集与三个开源语料库(LiveVQA、FVQA 与 WebQA)构建了多模态推理数据集。
- 最终整理的数据集被划分为包含 36,592 条轨迹的监督微调(SFT)语料库与包含 8,000 个实例的强化学习(RL)数据集,统一发布为 SearchVL-SFT-36k 与 SearchVL-RL-8k。
-
子集详情与过滤规则
- 维基百科多跳 VQA: 通过对英文维基百科超链接图执行受限随机游走生成(2025年5月快照)。路径长度从偏好 2 到 4 跳的分类分布中采样。种子节点按五个视觉类别分层,并需满足信息框、图像分辨率与入度标准。流水线明确跳过消歧页面、列表、重定向页及高入度中心节点(入度 > 10,000)。
- 难度过滤: 冻结的 Qwen3-VL-32B 模型执行两阶段过滤,移除无需工具即可回答或仅凭单次图像搜索即可解决的样本,确保所有保留实例均需多步视觉到文本的检索链。
- 视觉增强子集: 过滤后数据集中的百分之十经历受控图像退化(模糊、下采样、透视畸变),并与对应的修复工具配对,用于训练稳健的视觉修复行为。
-
数据使用与训练处理
- 研究团队使用合并后的过滤与增强实例合成专家轨迹,用于监督微调。
- 每个 VQA 实例作为提示词,在实时工具环境中使用 Claude Opus 4.6 生成五次独立的 ReAct rollout。
- 两阶段拒绝采样流程对这些 rollout 进行过滤:首先使用 LLM 裁判验证答案正确性,随后使用第二裁判评估流程质量(工具使用、逻辑一致性与重复规避)。
- 最终 SFT 语料库由保留的轨迹构成,平均每条轨迹包含 6.3 次工具调用,更广泛的已处理集则支持后续的强化学习阶段。
-
元数据构建与视觉处理
- 流水线为采样路径中的每个节点分配明确的功能角色:用于视觉定位的锚点节点、用于关系推理的中间桥接节点以及最终答案节点。
- 标准问题被迭代重写为模糊版本以防止捷径学习,并严格检查答案不变性、实体唯一性与名称泄露。
- 视觉定位将锚点节点名称替换为指代表达式,并与来自 Wikimedia Commons 的代表性图像配对,通过 CLIP 相似度过滤以确保相关性。
- 所有最终实例均构建为多轮 ReAct 轨迹,内嵌跟踪工具调用、观测结果与推理步骤的元数据,以指导策略优化。
方法
OpenSearch-VL 的架构旨在支持基于多模态输入的多轮工具增强推理,将结构化 Agent 框架与双阶段训练流程相结合。该系统在模态环境 E 中运行,根据调用的工具返回视觉与文本观测结果,从而实现策略模型与外部资源之间的灵活交互。策略模型基于累积历史 hl=(Il,q,a<l,o<l) 生成动作序列 al=[zl,cl],其中 zl 为推理轨迹,cl 为工具调用或最终响应。该交互展开为多轮轨迹 τ,其中每一步均输出策略动作,随后跟随环境观测结果。轨迹似然采用自回归方式建模为 πθ(τ∣I0,q)=∏l=0LPθ(zl∣hl)Pθ(cl∣hl,zl),观测结果不包含在生成概率质量中。为确保训练稳定性,应用了 token 级生成掩码 Mgen(yt),将非生成 token(如来自文本观测或图像值输出的部分)从损失计算中排除。该掩码策略受前人工作启发,防止策略因噪声大且结构迥异的外部输出而失稳。
Agent 利用多样化的工具集 T=Tv∪Ts,包含用于图像增强与解析的视觉工具(如 CROP、OCR、SHARPEN、SUPERRESOLUTION、PERSPECTIVECORRECT)以及用于外部知识检索的工具(如 TEXTSEARCH、IMAGESEARCH)。这些工具被集成至统一框架中,支持单轮与多轮交互。策略模型基于大型语言模型(LLM)实现,旨在训练其进行有效推理并调用这些工具。训练流程包含两个连续阶段:监督微调(SFT)与强化学习(RL)。在 SFT 阶段,模型在包含 36,592 条专家轨迹的整理数据集上进行训练,优化联合监督推理轨迹与后续工具调用或响应的标准目标。这为工具使用行为与基础推理能力提供了强有力的初始化。
RL 阶段在此基础上进一步探索,通过多轮搜索增强优化发现更高效的探索策略。研究团队采用了一种扩展版分组相对策略优化(GRPO)变体,以应对多模态与工具交错环境的复杂性。这一多轮搜索增强 GRPO 框架被称为致命感知 GRPO,引入了几项关键创新。首先,该框架采用复合轨迹级奖励 r(τ),平衡终端准确率(racc)、流程级搜索质量(rquery)与算法格式(rfmt)。格式奖励通过惩罚格式错误的动作来维护结构完整性,准确率奖励则通过 GPT-4o 裁判评估最终答案的正确性。查询质量奖励为推理过程提供密集反馈,评估语义相关性、逻辑推进与跨模态工具互补使用情况。其次,为解决长周期任务中级联失败的挑战,该方法引入了致命感知掩码策略。当轨迹遭遇 K=3 次连续工具执行错误时,被视为“致命”,且策略对该致命步骤索引 fi 之后生成的所有 token 的梯度被置零。这防止了模型从故障后不连贯的推理中学习。最后,为保留部分成功轨迹中的有用学习信号,该方法应用了一侧优势截断:针对致命轨迹,优势 A^i 被设为 max(ri,0),确保仅部分奖励超过组均值的轨迹对策略更新产生正向贡献。该策略通过恢复更多有用学习信号并避免标准组归一化的病态惩罚,对硬掩码基线进行了泛化。
第二张图展示了整体训练框架,图中策略模型并行生成多个 rollout τi,每个 rollout 均通过工具调用与环境 E 进行交互。随后使用复合奖励对 rollout 进行评估,并利用致命感知 GRPO 目标更新策略参数。该流程使模型能够学习稳健的多模态推理策略,在复杂现实场景中兼具高效性与可靠性。
实验
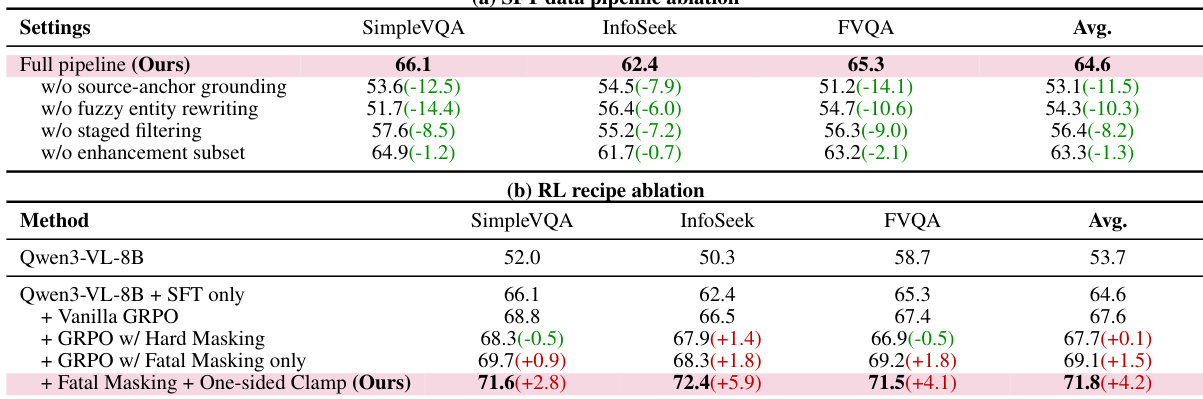
在七项多模态知识密集型基准测试上,与直接推理、RAG 及 Agent 基线进行对比,主要实验验证了复杂视觉查询对自主工具交错循环的必要性。结果证实,该 Agent 方法在所有模型规模下均稳定优于静态方法,展现出有效的可扩展性及在重度搜索任务上的卓越性能。反事实分析进一步验证了特定架构选择(如查询模糊化与中心节点规避)的合理性,这些选择对维持稳健的多跳推理至关重要。最后,定性案例研究展示了模型如何可靠地串联视觉检查与定向检索以逐步验证而非盲目猜测,仅在跨模态确认收敛时终止。
研究团队通过消融实验分析了流水线中关键设计选择的影响,表明每个组件均对性能提升有所贡献。结果表明,完整流水线优于缺少组件的变体,最终模型在各项基准测试中取得最高分数,印证了集成方案的有效性。与消融版本相比,完整流水线在所有基准测试中均实现最高性能。移除源锚点定位或模糊实体重写等单个组件会导致性能显著下降。集成致命掩码与一侧截断的最终模型优于其他变体,凸显了这些设计选择的重要性。
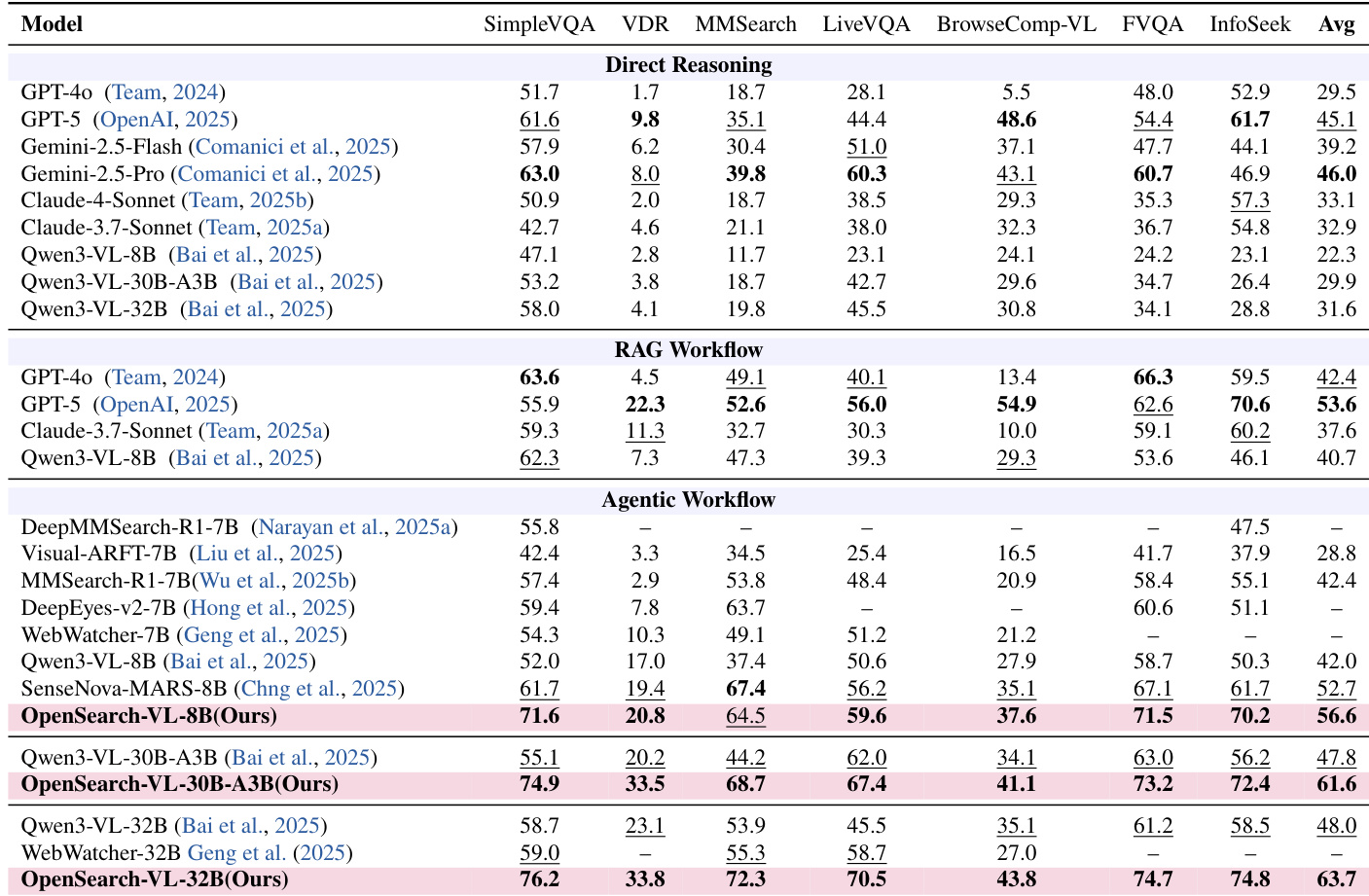
研究团队在多项基准测试中评估了 OpenSearch-VL,将其性能与直接推理、RAG 工作流及 Agent 工作流模型进行对比。结果显示,OpenSearch-VL 在所有模型规模的 Agent 工作流中均实现优越性能,尤其在需要工具使用与推理的复杂多模态任务上表现突出。最大规模模型变体优于开源与专有基线,证明了 Agent 训练方法的有效性。OpenSearch-VL 在所有基准测试上显著优于直接推理与 RAG 工作流模型,尤其是在 Agent 工作流中。最大规模模型变体取得最高平均分数,超越所有开源与专有模型。OpenSearch-VL 在多样化基准测试中展现出强劲性能,表明其处理复杂多模态查询的稳健性。
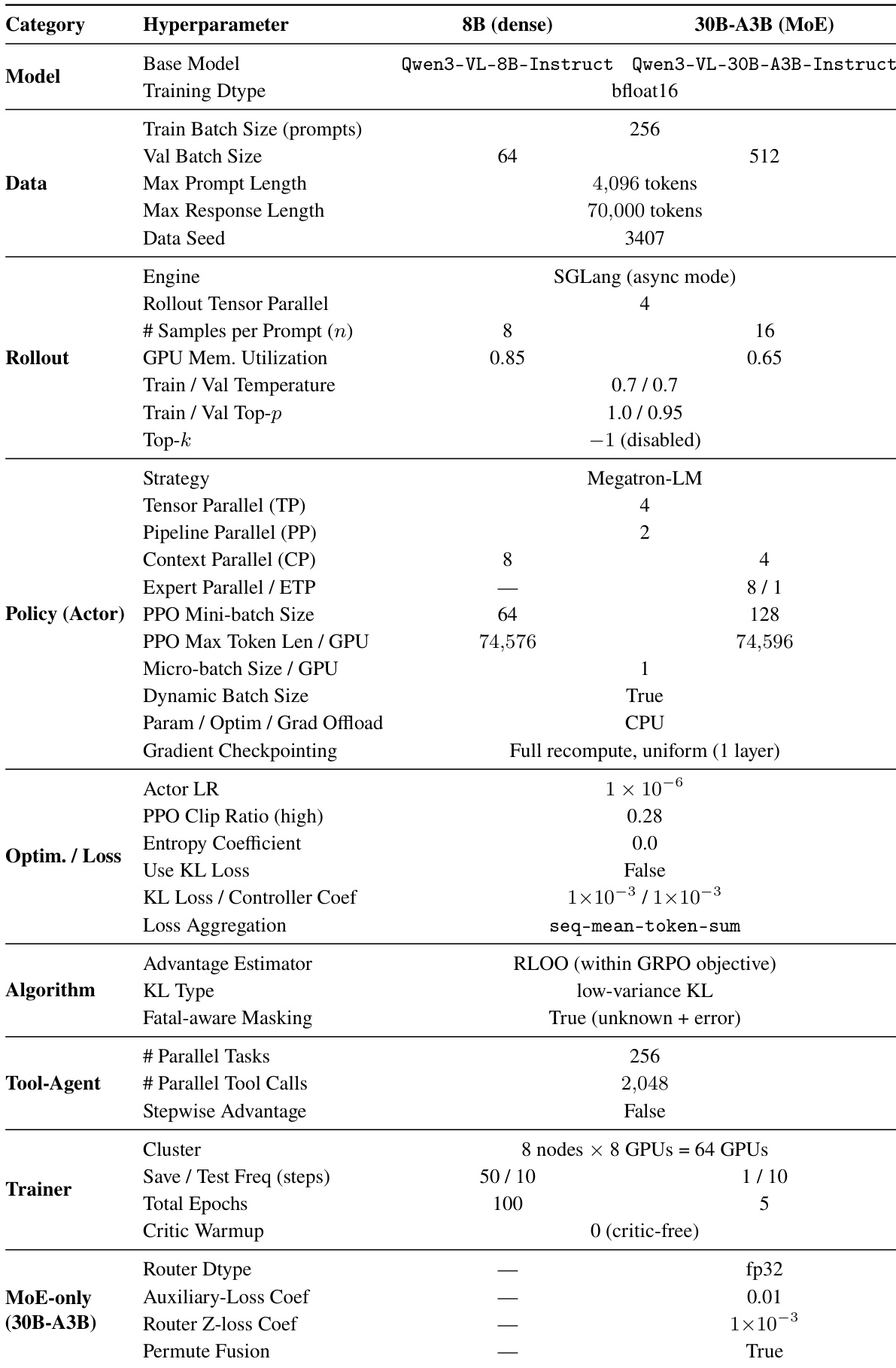
研究团队详细列出了 OpenSearch-VL 模型的训练配置,突出了 8B 稠密模型与 30B-A3B MoE 变体之间的超参数差异。表格显示,两种模型采用不同的训练策略与硬件配置,MoE 模型使用更复杂的设置,涉及专家并行与更多并行工具调用。8B 稠密模型与 30B-A3B MoE 模型采用不同的训练策略与硬件配置。与稠密模型相比,MoE 模型支持更多并行工具调用。训练配置包含针对 rollout、策略与优化的具体设置,两种模型变体在批次大小与并行设置上存在差异。
研究团队通过全面的基准评估、消融实验及针对不同模型架构的详细训练配置验证了该方法。消融实验证实每个流水线组件对维持峰值性能不可或缺,基准评估则展示了框架在复杂多模态推理与工具使用上的卓越能力。这些结果一致表明,完整流水线在不同模型规模与硬件设置下均优于所有基线方法。最终,研究结果确立了所提 Agent 训练策略的稳健性与可扩展性。