Command Palette
Search for a command to run...
采用 Judge 协调的大模型集成框架「Meno and Friends」进行高真实性多轮响应生成
采用 Judge 协调的大模型集成框架「Meno and Friends」进行高真实性多轮响应生成
Ivan Bondarenko Roman Derunets Oleg Sedukhin Mikhail Komarov Ivan Chernov Mikhail Kulakov
摘要
本文介绍了我们在 SemEval-2026 Task 8 (MTRAGEval) 的 Task B(带参考段落生成)中所采用的夺冠方案。我们的方法构建了一个由七种大型语言模型(LLMs)组成的异构集成系统,包含两种提示(prompting)变体,并采用 GPT-4o-mini 作为裁判模型,为每个实例选出最佳候选答案。最终,我们在26支参赛队伍中位列第一,条件调和均值达到0.7827,显著优于最强基线模型(gpt-oss-120b,得分为0.6390)。消融实验表明,模型家族、规模以及提示策略的多样性至关重要;集成方法始终优于任何单一模型。此外,我们引入了 Meno-Lite-0.1,这是一款参数量达7B的领域适应模型,在成本与性能之间取得了优异平衡,并对 MTRAGEval 进行了详细分析,指出了当前标注存在的局限性及未来改进方向。我们的代码已公开:https://github.com/RaguTeam/ragu_mtrag_semeval
一句话总结
RaguTeam 在 SemEval-2026 任务 8(MTRAGEval 任务 B)中的获胜系统采用了一种包含七个大型语言模型的异构集成方案,并搭配两种提示变体。其中,GPT-4o-mini 裁判会为每个实例选择最佳候选回答,从而达成 0.7827 的条件调和均值。此外,该系统还推出了 Meno-Lite-0.1,这是一款 7B 参数的领域自适应模型,在成本与性能之间取得了优异的平衡。
核心贡献
- 针对在提供参考段落的情况下为多轮查询生成忠实回答的挑战,本文提出了一种异构集成框架,该框架结合了不同架构和规模下的七个大型语言模型,并采用两种不同的提示策略。一个轻量级的 GPT-4o-mini 模型充当自动化裁判,为每个实例选择最合适的候选回答,从而简化了选择流程,无需进行广泛的模型对齐。
- 在 SemEval-2026 MTRAGEval 任务 B 基准上的评估结果表明,该集成架构始终优于单一模型,在 26 支参赛队伍中夺得第一名,条件调和均值达到 0.7827。该方法显著优于最强基线模型 gpt-oss-120b,而系统的消融实验证实,架构与提示策略的多样性是性能提升的主要驱动力。
- 该工作还发布了 Meno-Lite-0.1,这是一款七百亿参数规模的领域自适应模型,专为检索增强生成工作流中高效平衡成本与性能而设计。此次发布附带了对 MTRAGEval 基准的详细评估,系统梳理了现有标注的不足之处,并为未来的数据集优化明确了路线图。
引言
检索增强生成技术正从单轮问答向复杂的多轮对话演进,在此过程中,系统必须将回答建立在外部证据之上,同时保持对话历史的连贯性。这一演进对于部署可靠的对话式人工智能至关重要,使其能够准确解析共指关系、处理信息不足的查询,并防止幻觉内容的延续。然而,现有系统在多轮对话后期的忠实度上持续下降,且所依赖的评估指标难以准确捕捉上下文适宜性。为克服这些局限,作者利用包含七种不同语言模型的异构集成来生成候选回答,随后部署轻量级 GPT-4o-mini 裁判自动为每个实例选择最忠实的输出。这种由裁判协调的集成策略,结合新推出的 7B 领域自适应模型,在 SemEval-2026 MTRAGEval 基准上取得了顶尖性能,并证明战略性模型多样性与基于大型语言模型的选择机制能显著超越单一模型基线。
数据集
- 数据集构成与来源: 作者采用了一个对话式问答数据集,将用户查询与检索到的文档上下文及多轮对话历史进行配对。该基准测试包含标准的可回答实例,以及 97 道旨在评估模型拒绝行为能力的不可回答题目。
- 子集详情: 训练示例根据上下文可用性和对话状态被划分为三个互斥类别。第一类包含无支持文档的空上下文。第二类具有空的对话历史,代表文档可用时的首轮交互。第三类涵盖非空上下文与非空对话历史,这是最常见且最复杂的需要跨轮推理的场景。为构建评估提示,作者利用嵌入距离从每个类别中选取具有代表性的中心点,并保留最大类别(第三类)中的两个示例以捕捉组内多样性。
- 数据使用与处理: 该数据集作为基于提示的模型评估基础,而非用于直接训练模型。第一组仅依赖系统提示,第二组则在基础提示上增加了四个感知类别的少样本示例。在开发过程中,作者还探索了一条可选的查询重写流水线,该流水线利用对话上下文解析共指关系并扩展相对时间表达式,尽管该预处理步骤最终未纳入提交版本。
- 元数据构建与标注说明: 每个实例的结构均清晰分离对话历史、当前用户查询和检索到的证据。作者指出,针对信息不足查询的金标准回答会明确要求澄清,而非猜测意图。他们还强调,原始基准测试因参考段落为空而在不可回答题目中存在标签泄露问题,建议未来版本加入干扰段落以更好地模拟真实检索场景。
方法
所提出的系统遵循一个三阶段流水线,旨在解决多轮检索增强问答面临的挑战,框架示意图已对此进行说明。第一阶段涉及提示构建,采用两种不同的策略来引导模型行为。第二阶段中,七个异构大型语言模型(LLM)利用构建好的提示并行生成候选回答。最终阶段由基于裁判的选择流程组成,轻量级 GPT-4o-mini 模型会对生成的候选项进行评估,并选择最忠实的回答作为系统输出。
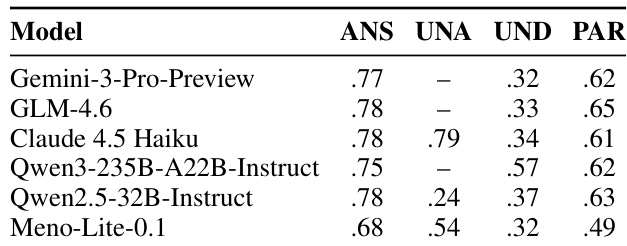
集成构成详见表 1,该表根据提示策略将七种模型分为两组。第一组模型使用优化后的系统提示 P,而第二组模型采用少样本策略。模型的选择旨在最大化架构、训练数据和规模上的多样性,涵盖专有模型与开源权重模型。这种多样性旨在生成具有不同失败模式的候选回答范围,从而增加至少有一个候选回答忠实且准确的可能性。
第一组模型的系统提示 P 是通过基于 Gemini 的流程进行迭代优化得出的。该过程包括分析训练实例样本以识别一致的行为模式,将这些模式提炼为简洁的提示,并评估提示的有效性。最终提示 P 强调严格遵循上下文、提取式表述、去人格化综合、直接交付以及对源文档结构的忠实还原。该提示旨在确保模型仅依赖提供的证据,避免幻觉,并生成简洁客观的回答。
对于第二组模型,少样本策略通过添加感知类别的示例来增强提示。训练实例被聚类为三个结构类别:完整上下文、空上下文和空历史。作者采用基于中心点的方法从这些类别中选取四个示例,以确保在不同对话模式(尤其是不回答问题)下的鲁棒性。该策略旨在为模型提供处理各种输入配置的清晰示例,从而提升其在特定场景下的表现。
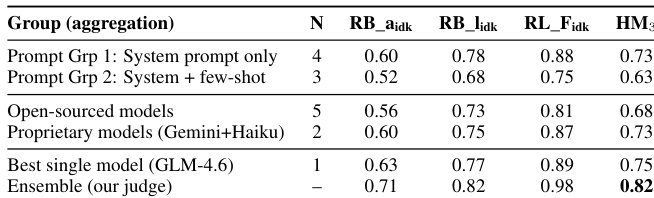
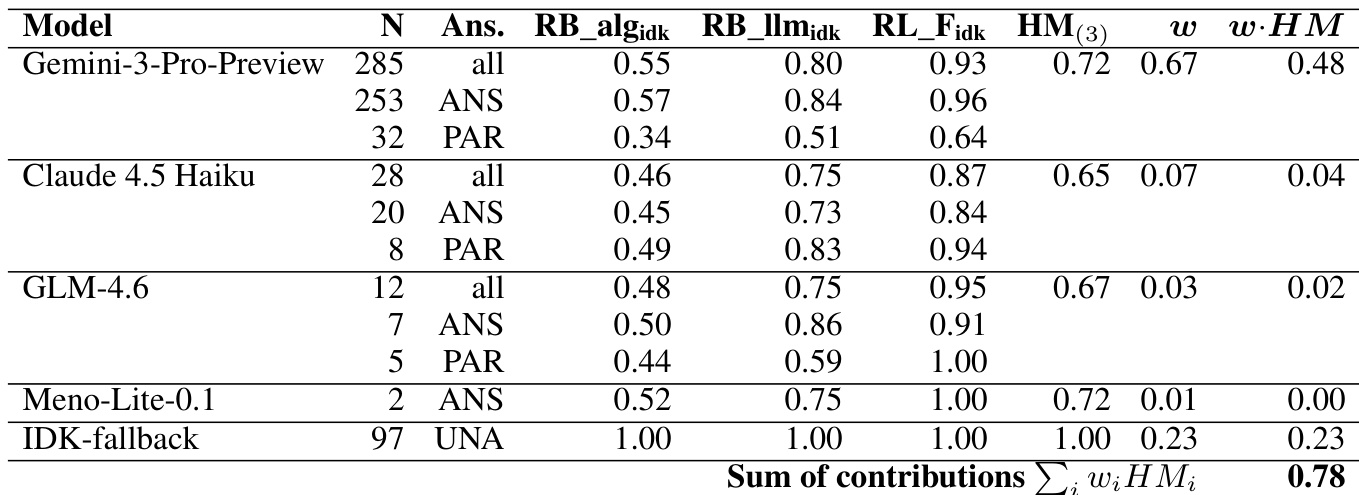
流水线的最终阶段涉及一个忠实度裁判 GPT-4o-mini,该裁判会对所有候选回答进行评估。裁判基于提供的文档评估每个答案的忠实度,并选择表现最佳的回答。这一选择过程对于确保系统输出建立在证据之上至关重要,尤其在复杂的多轮对话中,必须正确整合上下文与检索段落。系统性能采用条件指标进行评估,并分析各模型对最终加权调和均值的贡献,凸显了多样化候选生成与有效选择的重要性。
实验
该评估使用精心整理的对话数据集来测试包含七种语言模型的异构集成,并借助专用裁判为每个查询选择最忠实的回答。对比实验与消融实验证实,基于判断的选择成功利用了模型的互补优势,确认架构多样性与具体的少样本演示始终优于更大的单一模型或抽象的系统指令。这些发现表明,尽管忠实度是必要条件,但最优生成需要在基于证据与务实响应之间取得平衡,尤其针对模糊查询,同时突显了通过领域自适应较小架构所能实现的高性价比优势。
作者展示了各模型在不同可回答性类别中的性能对比,突出了模型处理可回答、不可回答、信息不足及部分可回答问题的差异。结果表明,模型在根据问题类型正确回答或拒绝回答的能力上存在显著差异,部分模型在特定类别中表现优异,但在其他类别(尤其是信息不足和不可回答情况)中表现不佳。模型在不同可回答性类别中展现出不同的优势,有些模型在处理可回答问题时表现良好,但在处理不可回答或信息不足问题时则较为吃力。模型在不可回答问题上的表现高度依赖于其拒绝回答的能力,各模型的 IDK 率存在显著差异。在信息不足问题上存在明显的性能差距,所有模型均难以生成恰当的澄清请求,这表明该任务仍面临挑战。
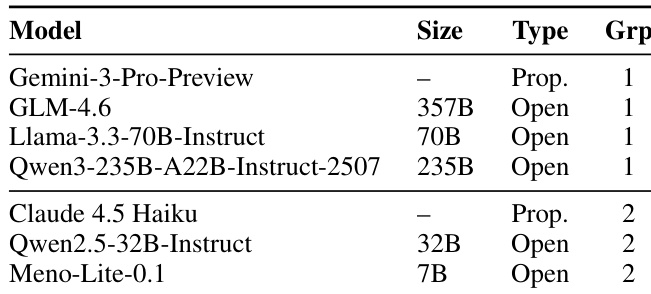
该表列出了实验中使用的模型,按规模、类型和提示组进行分类。模型根据提示策略分为两组,第一组包含较大的开源权重模型,第二组则混合了专有模型与开源权重模型,其中包括一款尽管规模较小但表现强劲模型。模型分为两种提示策略,第一组仅使用系统提示,第二组采用系统提示结合少样本设置。模型规模从 7B 到 357B 参数不等,涵盖专有模型与开源权重模型。Meno-Lite-0.1(一款 7B 模型)被纳入第二组,凸显了其相较于其他模型规模更小却表现出色的特点。
作者通过比较系统提示的三个版本来分析提示工程对模型性能的影响:原始提示、LLM 合成提示以及自我批评修订版。结果表明,LLM 合成提示相较于原始提示提升了性能,而自我批评修订版导致性能显著下降,主要原因是模型在不可回答问题上减少了拒绝回答的行为。LLM 合成提示优于原始提示,表明从回答中提取行为模式有助于提升性能。提示的自我批评修订版降低了性能,可能是因为其抑制了模型在不可回答问题上的拒绝行为。最终选定的提示为 LLM 合成版本,因其在性能与恰当的响应行为之间取得了平衡。

作者展示了一种集成系统,该系统采用基于裁判的选择机制在基准测试中取得顶尖性能,大幅领先于最佳基线。结果突显了将多样化模型与专注于忠实度的裁判相结合,在提升基于证据的回答生成方面的有效性。该集成系统通过显著超越最佳基线夺得第一名。基于裁判的选择通过利用多样化的模型输出并优先考虑忠实度来增强性能。系统的成功证明了将多个模型与专用评估机制相结合的价值。

作者评估了一种采用基于裁判选择方法的集成系统,用于从多个模型中选择最佳回答。结果表明,该集成系统优于单一模型和基线系统,当裁判基于忠实度及其他指标选择回答时,性能达到最高。该系统利用多样化的模型与提示策略,最佳结果来源于开源权重模型与专有模型的组合。集成系统在评估指标上取得最高分,显著超越单一模型与基线系统。相较于随机选择,基于裁判的选择大幅提升了性能,凸显了忠实度在回答生成中的价值。开源权重模型与专有模型均对集成有所贡献,最佳结果来自不同提示策略与模型类型的组合。
实验在不同问题可回答性类别下评估大型语言模型,以检验其正确回答或恰当拒绝的能力,同时考察不同提示策略与系统架构对整体性能的影响。定性分析表明,模型在输入为可回答、不可回答或信息不足时表现出明显的优势与劣势,且在为模糊查询生成有效澄清请求方面 consistently 面临挑战。研究进一步证明,相较于基线或自我批评版本(后者会无意中抑制必要的拒绝行为),LLM 合成提示能更好地增强行为对齐性。最后,实施结合多样化模型输出与专注于忠实度选择机制的基于裁判的集成系统,显著优于单一基线,凸显了战略性模型聚合的有效性。