Command Palette
Search for a command to run...
Stream-T1:用于流式视频生成的测试时扩展
Stream-T1:用于流式视频生成的测试时扩展
Yijing Tu Shaojin Wu Mengqi Huang Wenchuan Wang Yuxin Wang Chunxiao Liu Zhendong Mao
摘要
尽管测试时扩展(Test-Time Scaling, TTS)为在无需承担高昂训练成本的前提下提升视频生成质量提供了极具前景的方向,但当前基于扩散模型的测试时视频生成方法仍面临候选者探索成本过高以及缺乏时间引导等结构性瓶颈。针对这些瓶颈,我们提出将研究重心转向流式视频生成。我们发现,流式视频生成的分块合成机制以及较少的去噪步骤天然契合 TTS 范式,从而在显著降低计算开销的同时,实现了对时间维度的细粒度控制。基于这一洞察,我们推出了 Stream-T1,这是首个专为流式视频生成量身定制的综合型 TTS 框架。具体而言,Stream-T1 由三个核心模块组成:流式缩放噪声传播(Stream-Scaled Noise Propagation):利用历史验证过的高质量前序块噪声,主动优化当前生成块的初始潜在噪声,从而有效建立时间依赖性,并利用历史高斯先验引导当前生成过程;流式缩放奖励剪枝(Stream-Scaled Reward Pruning):综合评估生成的候选结果,通过结合即时短期评估与基于滑动窗口的长期评估,在局部空间美学与全局时间连贯性之间寻求最优平衡;流式缩放内存下沉(Stream-Scaled Memory Sinking):根据奖励反馈动态路由从 KV-cache 中驱逐出的上下文信息至不同的更新路径,确保先前生成的视觉信息能够有效锚定并引导后续视频流的生成。在涵盖 5 秒和 30 秒视频的综合性基准测试中,Stream-T1 展现了卓越优势,显著提升了时间一致性、运动平滑度以及帧级视觉质量。
一句话总结
本文介绍了 Stream-T1,这是一种面向流式视频生成的测试时扩展框架。该框架通过利用少数去噪步骤的块级合成,显著降低了计算开销,同时实现了细粒度的时间控制,从而解决了当前基于扩散模型的方法中候选探索成本过高以及缺乏时间引导的问题。
核心贡献
- Stream-T1 被提出为首个将测试时扩展适配至流式视频生成的综合性框架。该框架以计算高效的块级合成过程取代了全局候选探索。这一架构转变在降低推理成本的同时,实现了自回归视频生成过程中的精确时间控制。
- 该框架通过三种集成机制优化生成轨迹:流式缩放噪声传播利用历史上成功的轨迹细化初始潜在噪声;流式缩放奖励剪枝平衡局部空间美学与全局时间连贯性;流式缩放内存下沉动态路由上下文内存以维持长期语义一致性。
- 在 5 秒和 30 秒视频生成基准上的综合评估表明,与现有基线模型相比,Stream-T1 确立了新的最先进水平,在时间一致性、运动平滑度以及扩展视觉保真度方面实现了可量化的提升。
引言
流式视频生成将自回归序列建模与基于扩散模型的保真度相结合,以合成超长且高质量的视频序列,使其成为可扩展内容创作与模拟的重要进展。尽管测试时扩展已成为通过动态分配推理算力来提升生成质量的经济策略,但此前针对视频的方法仍面临重大挑战。现有方法通常同时对整个序列进行去噪,这迫使计算昂贵的全局搜索成为必要,并阻碍了细粒度的时间引导。这种全局处理模型意味着任何局部瑕疵都会导致整个序列被拒绝,使得动态时间修正成为不可能,并严重限制了长期连贯性。为突破这些瓶颈,本文提出了 Stream-T1,这是一个专为逐块流式生成而设计的测试时扩展框架。该框架利用三种协同机制优化生成轨迹:一种将新块锚定至历史上成功轨迹的噪声传播策略,一种平衡局部视觉质量与全局时间一致性的奖励剪枝模块,以及一种动态路由上下文更新以保留长程语义连续性的内存下沉系统。该架构通过提供更平滑的运动、更强的时间对齐以及跨长视频序列的卓越视觉保真度,显著优于现有基线模型。
方法
Stream-T1 框架通过一个专为流式视频生成设计的三阶段流水线运行,利用测试时扩展来增强时间连贯性与视觉质量,同时将计算开销降至最低。整体架构围绕块级合成构建,每个视频片段按顺序生成并通过迭代过程进行细化。如框架示意图所示,流水线始于使用分布保持门控初始化第一个块的潜在噪声,随后采用束搜索机制扩展候选轨迹。在每一个生成步骤中,系统依次经过三个独立模块:流式缩放噪声传播、流式缩放奖励剪枝与流式缩放内存下沉,它们共同管理视频流的生成、评估与内存控制。
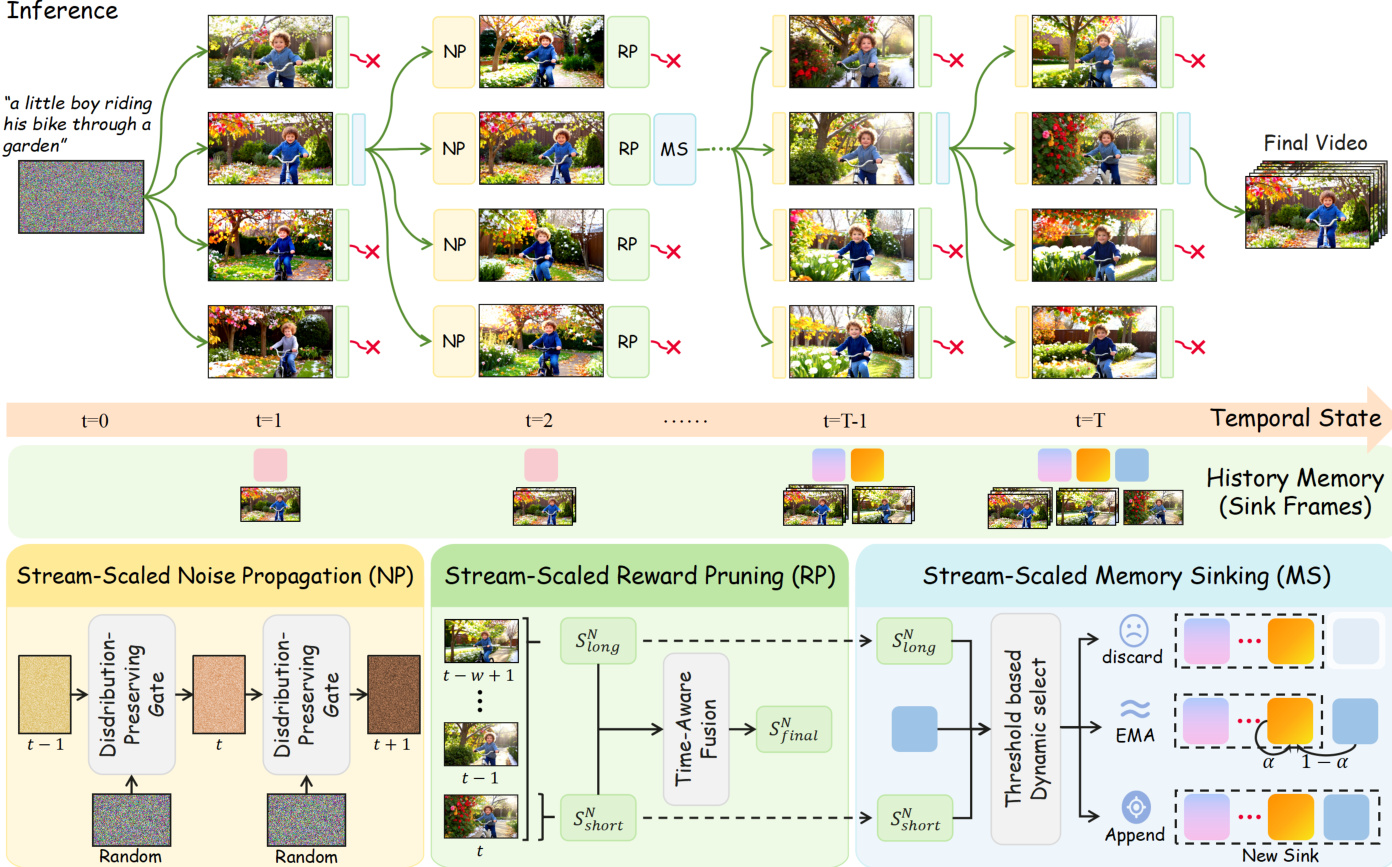
第一阶段为流式缩放噪声传播,该阶段利用前一块的最优噪声轨迹来细化当前块的初始噪声潜在变量。框架并非从标准高斯分布中采样噪声,而是通过对第 (n−1) 块的噪声与一个随机高斯变量进行球面插值来初始化第 n 块的噪声。该插值在建立强时间依赖性的同时保留了噪声的边缘分布,从而有效利用历史高斯先验指导当前生成。插值公式定义为 xTn=βxTn−1+1−β2ϵ,其中 β∈(−1,1) 控制时间相关程度,ϵ∼N(0,I)。该机制确保每个块的初始化均基于先前验证过的高质量噪声,从而降低发散风险并提升整体生成质量。
完成噪声初始化后,系统进入流式缩放奖励剪枝阶段。在此阶段,生成的块候选项经过评估与剪枝,以维持局部空间美学与全局时间连贯性之间的最佳平衡。评估过程分解为两个部分:短程得分,通过对块内每一帧应用图像奖励模型计算得出;长程得分,源自评估滑动窗口内时间连贯性的视频奖励模型。短程得分捕捉帧级视觉保真度,长程得分则评估多帧之间的运动平滑度及与文本提示词的对齐程度。为动态平衡这些目标,系统采用阈值约束的加权融合策略,分配给短程得分的权重随块索引线性增加,直至达到预设阈值 τ。第 n 块的最终得分公式如下:
Sfinaln={Nn⋅Sshortn+(1−Nn)⋅Slongn,τ⋅Sshortn+(1−τ)⋅Slongn,Nn≤τ,Nn>τ,其中 N 为块的总数。该机制通过强制在局部细节细化与全局运动对齐之间保持稳定的权衡,有效防止了帧重复与生成停滞。
最终阶段为流式缩放内存下沉,该阶段动态管理键值缓存,在维持短期连续性的同时保留长期语义。系统通过两个条件检测语义边界:质量门控确保仅保留高质量块,过渡检测器则识别时间连贯性的突变。基于这些条件,被驱逐的键值对会被路由至三条路径之一:丢弃、EMA-Sink 或 Append-Sink。若块未通过质量门控,则被永久丢弃以防止上下文污染。若块质量较高但未显示显著过渡,其键值对将通过指数移动平均整合至现有下沉结构中,以压缩冗余信息。当高质量块与检测到的过渡重合时,它将被作为离散锚点追加至全局下沉结构,从而保留独特的语义特征。这种自适应路由机制将短期连续性与长期记忆保留解耦,使得在长视频序列中能够保持一致的生成效果。更新后的内存状态随后用于条件化后续生成,确保先前合成的视觉信息能够有效锚定并引导当前流。
实验
评估设置分别在短视频与长视频生成任务上测试该框架,以验证其相对于成熟基线模型与标准测试时扩展技术的性能。定性分析表明,尽管现有方法在长序列中性能显著下降,但所提方法仍保持了稳健的时空连贯性与高视觉保真度。消融研究进一步证实,动态内存管理、噪声传播与奖励剪枝等每个核心组件对于维持结构完整性与语义对齐均不可或缺。最终,该主动优化策略始终优于被动采样方法,在各类生成任务中均展现出更优的长期稳定性与美学质量。
{"summary": "作者将所提方法与基线模型及测试时扩展方法在长视频生成任务上进行对比,结合定量指标与定性评估进行分析。结果表明,该方法在时间一致性与视觉保真度方面表现更优,尤其在长序列中效果显著,且框架的每个组件均对整体质量有重要贡献。", "highlights": ["Stream-T1 在长视频生成的多项指标上超越基线模型,在主体一致性、背景一致性、运动平滑度、成像质量与美学质量方面取得最佳结果。", "与现有方法相比,该方法在时间连贯性与视觉保真度方面实现显著提升,尤其在长序列中表现突出。", "消融研究证实框架的每个组件均不可或缺,移除任一模块均会导致特定质量维度的明显下降。"]

本文使用评估视频质量多个维度的基准,在短视频生成任务上将所提方法 Stream-T1 与多个基线模型进行对比。结果表明,Stream-T1 在大多数指标上取得最佳性能,尤其在时间一致性与视觉保真度方面表现突出,并在短视频与长视频生成场景中均优于基线模型。与基线模型相比,Stream-T1 在短视频生成的多数质量指标上取得最佳结果。该模型在短视频生成的时间一致性与视觉保真度方面展现出优越性能。在短视频生成任务中,Stream-T1 在主体一致性、运动平滑度与美学质量等关键指标上领先于其他模型。

本文在短视频与长视频生成任务上评估 Stream-T1 方法,并与基线模型进行对比。结果表明,Stream-T1 在短视频与长视频的多个质量指标上均取得最佳性能,在时间一致性与视觉保真度方面提升尤为显著。该方法在定量评估与定性分析中均优于现有方案,展现出稳健的长期稳定性。与基线模型相比,Stream-T1 在短视频与长视频生成的多数指标上取得最佳结果。该模型显著提升了长视频的时间一致性与帧级视觉保真度。消融研究证实,Stream-T1 的每个组件对于维持高质量视频生成均必不可少。

本文开展消融研究以评估视频生成框架中各个独立组件的影响。结果表明,每个组件均对视频质量的不同方面有所贡献,完整模型取得最佳综合性能。移除任一组件均会导致特定指标显著下降,凸显了集成设计的重要性。移除流式缩放内存下沉会降低背景稳定性与一致性指标。省略流式缩放噪声传播会导致局部结构伪影及整体性能均匀下降。消除流式缩放奖励剪枝则引发语义错位以及美学与时间质量的下滑。

该评估在短视频与长视频生成任务中将所提 Stream-T1 框架与基线模型进行对比,采用全面的定性与定量分析。实验结果表明,Stream-T1 始终实现更优的时间连贯性与视觉保真度,尤其在长序列中维持主体与背景一致性方面表现卓越。消融研究进一步验证了各架构组件的必要性,揭示移除任一模块均会导致结构性伪影或语义错位等特定质量下降。最终,研究结果证实 Stream-T1 的集成设计对于跨不同时长的高质量稳健视频生成至关重要。