Command Palette
Search for a command to run...
OpenSeeker-v2:通过信息丰富和高难度轨迹推动搜索智能体的极限
OpenSeeker-v2:通过信息丰富和高难度轨迹推动搜索智能体的极限
Yuwen Du Rui Ye Shuo Tang Keduan Huang Xinyu Zhu Yuzhu Cai Siheng Chen
摘要
深度搜索能力已成为前沿大语言模型(LLM)agents 不可或缺的核心能力,然而其研发目前仍主要由工业巨头主导。典型的行业研发流程涉及一个资源消耗极高的流水线,包括预训练、持续预训练(CPT)、监督微调(SFT)和强化学习(RL)。在本报告中,我们表明,在高质量且高难度的轨迹数据驱动下,一种简单的 SFT 方法在训练前沿搜索 agents 方面展现出令人惊讶的强大效力。通过引入三项简单的数据合成改进——扩大知识图谱规模以增强探索能力、扩展工具集规模以提升功能广度、以及严格的低步数过滤——我们建立了一个更强的基线。仅在 10.6k 数据点上训练,我们的 OpenSeeker-v2 在四个基准测试中(基于 ReAct 范式的 30B 参数规模 agents)取得了最先进的性能:BrowseComp 达到 46.0%,BrowseComp-ZH 达到 58.1%,Humanity's Last Exam 达到 34.6%,xbench 达到 78.0%,甚至超越了采用重型 CPT+SFT+RL 流水线训练的通义 DeepResearch(其得分分别为 43.4%、46.7%、32.9% 和 75.0%)。值得注意的是,OpenSeeker-v2 是首个由纯学术团队仅使用 SFT 方法开发,并在其模型规模和范式下取得最先进的搜索 agent。我们兴奋地开源了 OpenSeeker-v2 模型权重,并分享我们简单而有效的研究成果,以使前沿搜索 agent 的研究更加开放,惠及整个社区。
一句话总结
仅使用 10.6k 条通过扩展知识图谱规模、扩充工具集以及应用严格低步数过滤合成的信息丰富且高难度轨迹进行训练,OpenSeeker-v2 在仅采用监督微调(SFT)的情况下,便在 BrowseComp、BrowseComp-ZH、Humanity's Last Exam 和 xbench 等基准测试中,为 30B 参数规模的 ReAct Agent 取得了最先进(SOTA)的性能表现,成为首个超越资源密集型工业级流水线方案的学术开发搜索 Agent。
核心贡献
- OpenSeeker-v2 是一款仅通过监督微调训练的 30B 参数搜索 Agent,证明了精简的流水线足以与资源密集型工业方案相媲美。该能力通过三项数据合成改进实现:扩展知识图谱规模、扩充工具集,以及实施严格的低步数过滤以保障高难度轨迹。
- 该方法构建了一个包含 10.6k 条精心筛选轨迹的紧凑数据集,证明了定向数据合成能够有效替代大规模的持续预训练与强化学习阶段。
- 该模型在 ReAct 范式下,于 BrowseComp、BrowseComp-ZH、Humanity's Last Exam 和 xbench 四项 Agent 基准测试中均取得最先进性能。这标志着首款同规模学术开发的最先进搜索 Agent 的诞生,且所有权重与代码均已公开。
引言
深度搜索已成为前沿大语言模型 Agent 的核心能力之一,但当前进展主要局限于资金雄厚的工业界玩家,其依赖堆叠持续预训练、监督微调与强化学习的资源密集型流水线。这种复杂性带来了高昂的计算与数据门槛,实质上阻碍了学术界与开源社区推进搜索 Agent 能力。作者采用以数据为核心的策略推动技术普及,推出了 OpenSeeker-v2。该搜索 Agent 仅通过单一监督微调阶段即取得最先进结果。团队通过扩展知识图谱规模、扩充可用工具以及应用严格低步数过滤来确保高难度,从而构建了一个包含 10.6k 条轨迹的紧凑数据集,迫使模型掌握持续的多跳推理能力。因此,其 30B 参数模型在多项基准测试中超越了通义 DeepResearch 等工业级方案,标志着学术团队首次仅凭纯 SFT 工作流便实现了顶级搜索 Agent 性能。
方法
作者提出了 OpenSeeker-v2,这是一种基于监督微调(SFT)的增强型搜索 Agent 训练框架。核心假设在于,足够具有挑战性且信息丰富的训练数据,能够促使简单的 SFT 目标激发出强大的长程搜索与推理能力。该框架在原始 OpenSeeker 架构基础上,通过优化数据生成流水线来产出更高质量的训练样本,从而更好地支持复杂推理。
该方法的核心是一个扩展图规模的过程,旨在丰富任务合成所需的上下文。设 G=(V,E) 表示用于生成训练任务的原图。对于每个种子节点 vseed∈V,原始流水线会构建以 vseed 为中心的局部子图 Gsub。在 OpenSeeker-v2 中,扩展预算从 k 提升至 K(其中 K>k),从而生成更大的证据子图:
Gsub(K)=Expand(G,vseed,K).该扩展子图捕获了更多样化的拓扑相关节点,从而增加了可行推理路径的数量与多样性。随后基于此丰富上下文生成合成查询:
q∼Pgen(q∣Gsub(K)).通过增大 K,生成的问题更可能需要在多个节点间进行证据聚合,而非依赖直接或缺失的连接。
为进一步提升 Agent 的功能库,作者将可用工具集 A 扩展至超出 OpenSeeker-v1 所使用的范围。该扩充工具集借鉴了近期 Agent 设计的前沿进展,使 Agent 能够执行更复杂的多步推理轨迹。给定生成的问题 q,搜索 Agent 将生成类 ReAct 轨迹:
τ=(r1,a1,o1,r2,a2,o2,…,rT,aT,oT,rT+1,y),其中每个动作 at∈A 对应来自扩充工具集的工具调用,ot 表示被调用工具返回的观测结果。推理轨迹 rt 位于每个动作之前,用于记录 Agent 的内部思维过程。该轨迹包含 T 次工具调用步骤,随后是最终推理步骤 rT+1 与答案 y。扩充的工具集鼓励 Agent 探索多样化的交互模式并利用互补工具,从而产生更灵活且功能丰富的解决问题行为。
为确保训练数据反映有意义的推理复杂度,OpenSeeker-v2 应用了严格的低步数过滤机制。该机制移除了仅需极少或浅层推理即可解决的样本。过滤后的数据集定义如下:
Dv2={(q,τ)∈Draw∣T(τ)≥Tmin}.此处,Tmin 为工具调用次数的预设阈值。步数 T(τ)<Tmin 的轨迹将被丢弃,因为它们通常代表可通过直接检索或关键词匹配解决的过于简单的案例。

实验
评估设置通过在多项具有挑战性的深度研究基准测试中,将模型与采用复杂多阶段流水线训练的同等规模 Agent 以及更大的专有系统进行对比。这些实验验证了,在高质量且计算密集的合成轨迹驱动下,直接的监督微调方法能够稳定超越资源更密集的训练方案。研究结果凸显了该框架巨大的扩展潜力,并确立精心构建的数据质量作为推进长程 Agent 搜索能力的主要驱动力。
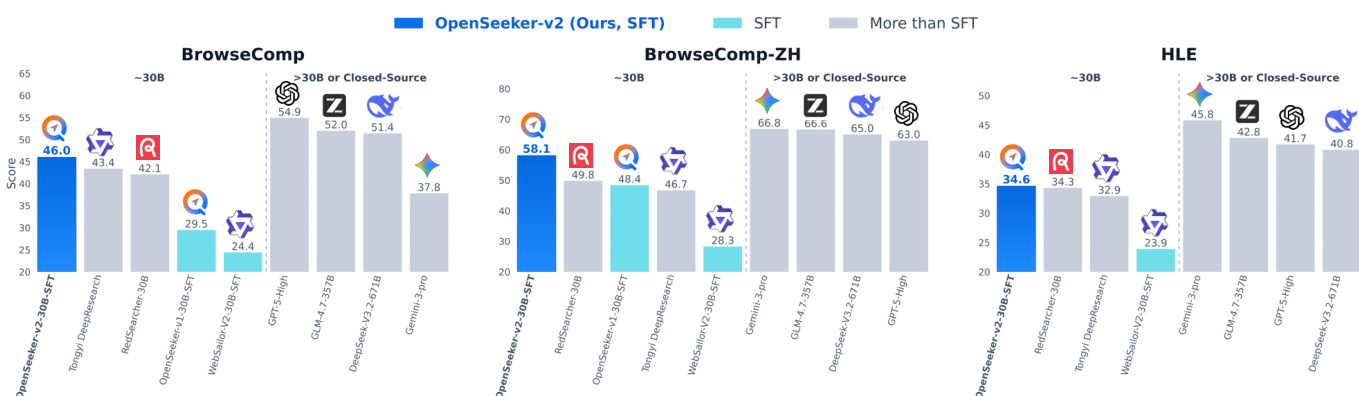
作者在多项基准测试中评估了仅使用简单监督微调训练的搜索 Agent OpenSeeker-v2,并将其与其他 Agent(包括采用更复杂流水线训练的模型)进行对比。结果表明,OpenSeeker-v2 取得了优异的性能,超越了几款同等规模的模型甚至更大规模的模型,证明了高质量数据能够在无需大量资源的情况下实现有效训练。该模型相较于前代取得了显著提升,表明更优的数据质量与复杂度能够带来更强的能力。在多项基准测试中,OpenSeeker-v2 均优于采用更复杂流水线训练的同等规模 Agent。OpenSeeker-v2 的性能高于更大规模的模型,表明其具备强大能力,尽管训练流程更为简单。该模型相较于前代展现出实质性改进,说明更高质量的数据能够提升搜索 Agent 的性能。
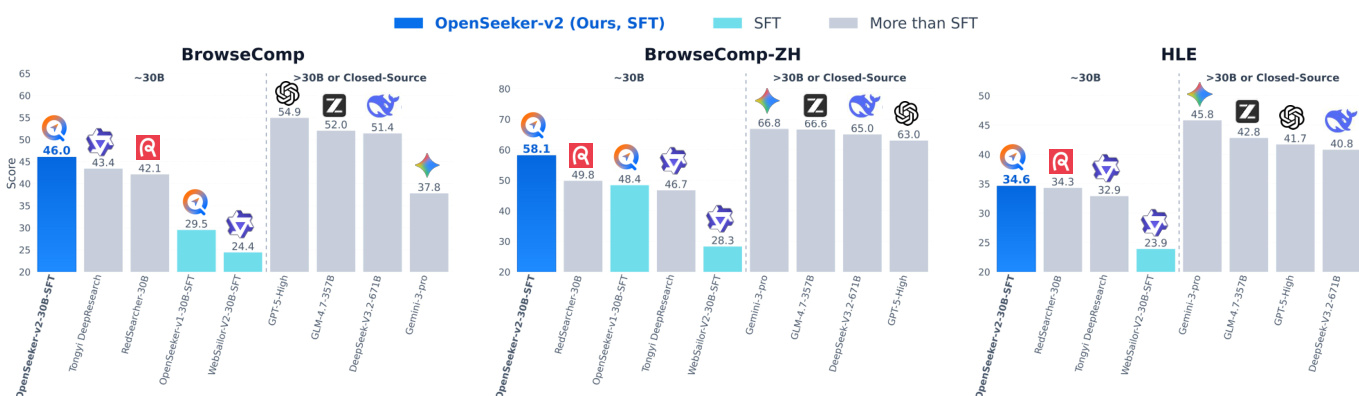
作者将仅通过监督微调训练的 30B 规模搜索 Agent OpenSeeker-v2 置于多项基准测试中进行评估,并与其他模型进行对比。结果显示,OpenSeeker-v2 在多项任务中均表现强劲,超越了多款采用更复杂流水线训练的同等规模模型,其中包括使用持续预训练与强化学习的方案。该模型不仅超越了更大规模的模型,且相较于前代取得显著改进,表明高质量数据与长程推理任务是其性能优越的关键因素。在同等训练方式下,OpenSeeker-v2 的性能高于其前代,说明通过提升数据质量可实现模型扩展。尽管仅使用 SFT 进行训练,OpenSeeker-v2 仍在多项具有挑战性的基准测试中超越更大规模模型并取得优异结果。
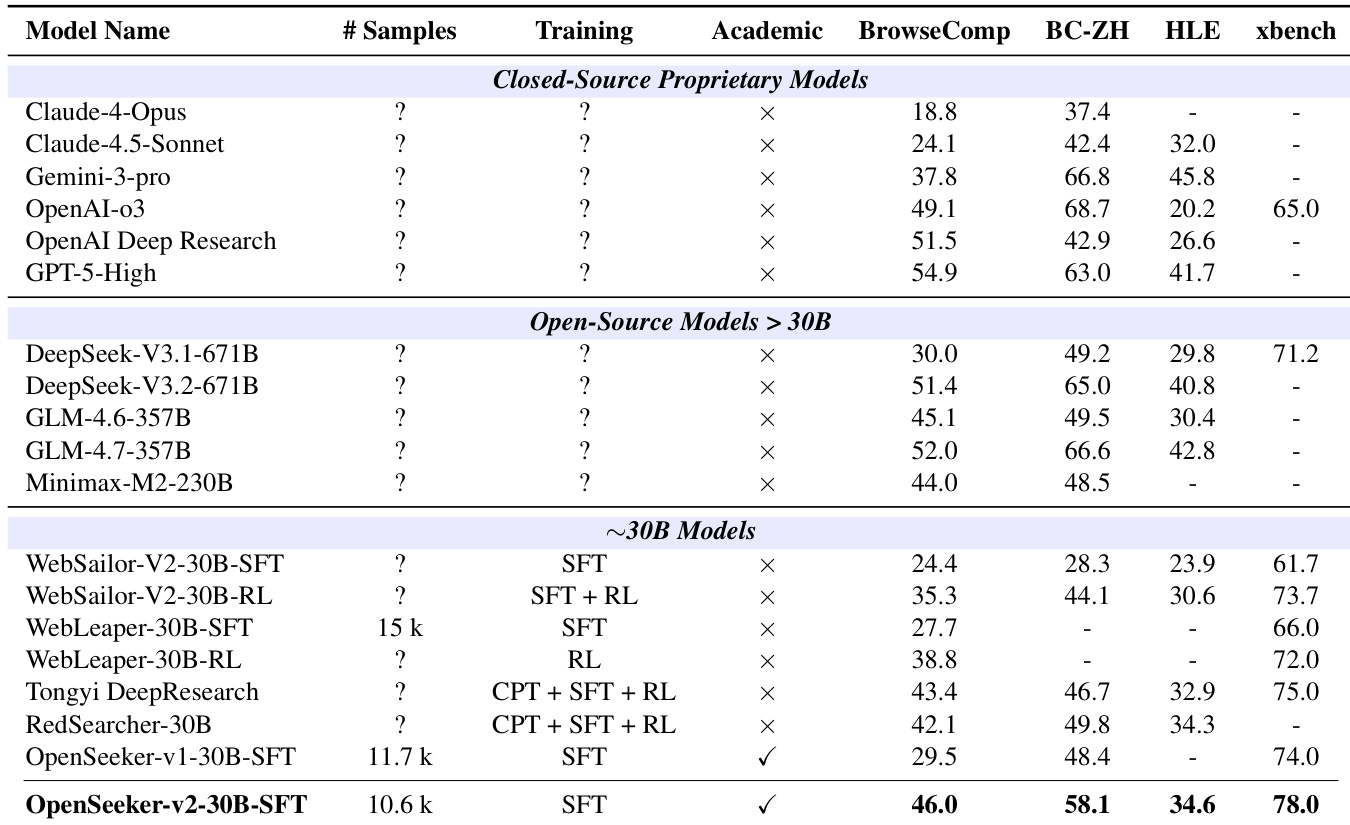
作者在多项基准测试中评估了仅通过监督微调训练的 30B 规模搜索 Agent OpenSeeker-v2,并与采用复杂流水线、更大架构的同等规模模型及其前代进行对比。与同等规模及更大规模系统的对比验证了,高质量训练数据与长程推理任务能够在无需先进训练方法的情况下驱动卓越能力。该模型持续超越竞争对手,并相较于前代展现出实质性改进,凸显了数据集优化对 Agent 性能的直接推动作用。最终,研究结论指出,在开发高效搜索 Agent 的过程中,数据质量的重要性高于训练复杂度。