Command Palette
Search for a command to run...
重思推理密集型检索:评估与推进智能体搜索系统中的检索器
重思推理密集型检索:评估与推进智能体搜索系统中的检索器
Yilun Zhao Jinbiao Wei Tingyu Song Siyue Zhang Chen Zhao Arman Cohan
摘要
推理密集型检索旨在获取能够支持下游推理的证据,而非仅仅匹配主题相似性。在代理式搜索(agentic search)系统中,检索器必须在迭代搜索与综合过程中提供互补性证据,这种能力日益重要。然而,现有研究在评估和训练方面仍存在局限:例如 BRIGHT 等基准仅提供狭窄的“黄金标准”集合(gold sets),且在孤立环境下评估检索器;而合成训练语料通常仅优化单段文本的相关性,忽视了证据组合(evidence portfolio)的构建。为此,我们推出了 BRIGHT-PRO,这是一个经过专家标注的基准测试,通过为每个查询扩展多维度的黄金标准证据,并在静态搜索和代理式搜索两种协议下对检索器进行评估。此外,我们构建了 RTriever-Synth,这是一种基于方面分解(aspect-decomposed)的合成语料库,能够生成互补的正例和基于正例条件的困难负例(hard negatives),并利用该语料库对基于 Qwen3-Embedding-4B 的 RTriever-4B 进行 LoRA 微调。在词汇型、通用型及推理密集型检索器上的实验表明,基于方面感知的评估和代理式评估揭示了标准指标所隐藏的行为特征,且 RTriever-4B 的性能相比其基础模型有显著提升。
一句话总结
针对现有推理密集型检索评估和训练的局限性,作者介绍了 BRIGHT-PRO,这是一个专家标注的基准,评估检索器在静态和 Agent 搜索协议下的表现,并提供多面金标准证据。同时介绍了 RTriever-Synth,这是一个方面分解的合成语料库,生成互补正样本和正样本条件化硬负样本,用于对基于 Qwen3-Embedding-4B 的 RTriever-4B 进行 LoRA 微调,从而在 Agent 搜索系统的证据组合构建中显著优于基座模型。
核心贡献
- BRIGHT-PRO 被引入为专家标注基准,扩展了 BRIGHT,包含多面证据,并在静态和 Agent 搜索设置下评估检索器。
- RTriever-Synth 被提出为方面分解的合成流程,从参考答案推理中生成互补正样本,并为训练检索器生成正样本条件化硬负样本。
- RTriever-4B 通过在 RTriever-Synth 上对 Qwen3-Embedding-4B 进行 LoRA 微调来训练,专门用于推理密集型证据选择。实验表明,方面感知和 Agent 评估揭示了标准指标隐藏的行为,而模型相比其基座版本有显著提升。
引言
推理密集型检索对于 Agent 搜索系统至关重要,模型必须收集多样化证据以支持复杂的多步推理。然而,先前的基准如 BRIGHT 依赖狭窄的金标准集,并在孤立状态下评估检索器,而训练数据通常优化单段落相关性而非构建完整的证据组合。为了弥补这些差距,作者介绍了 BRIGHT-PRO,这是一个专家标注的基准,在多面监督下评估静态和 Agent 搜索协议中的检索器。他们进一步开发了 RTriever-Synth,这是一个合成语料库,旨在教导模型选择互补证据,并用于微调 RTriever-4B,以在推理密集型任务中显著提高性能。
数据集
- 作者基于 BRIGHT 数据集构建 BRIGHT-PRO 基准,选择 StackExchange 子集以专注于开放域自然语言推理,而非特定领域的编码或定理任务。
- 正样本段落通过追踪已接受答案中的超链接收集,而负样本则通过 Google Search 使用帖子标题或 LLM 关键词生成,以查找主题相关但不相关的页面。
- 领域专家将查询分解为推理方面,并使用 1 到 5 的 Likert 量表分配重要性权重,该量表被归一化以总和为 1。
- 原始正样本段落经过重新审核以确认主题保真度,如果重叠或来自同一 URL 则进行合并,以保留上下文并减少冗余。
- 新文档通过 Web 或 AI 辅助搜索获取,并使用 FireCrawl 框架处理,以剥离广告和导航菜单等样板内容。
- 提取的文本经过人工细化以去除噪声,并在文档支持多个推理需求时分割为特定方面的部分。
- 独立的第二标注员审查验证方面覆盖和文档证据,权重可靠性达到 0.742 的加权 Cohen's kappa。
- 该数据集作为评估推理密集型检索系统的统一检索语料库,查询和文档数量的详细统计信息见表 1。
方法
作者利用专门的合成流程为 RTriever 模型构建高质量训练包。如下图中所示,该框架,特别是右侧的 RTriever Training 模块,通过两个主要阶段运行:查询合成和段落合成,最终完成检索器的微调。
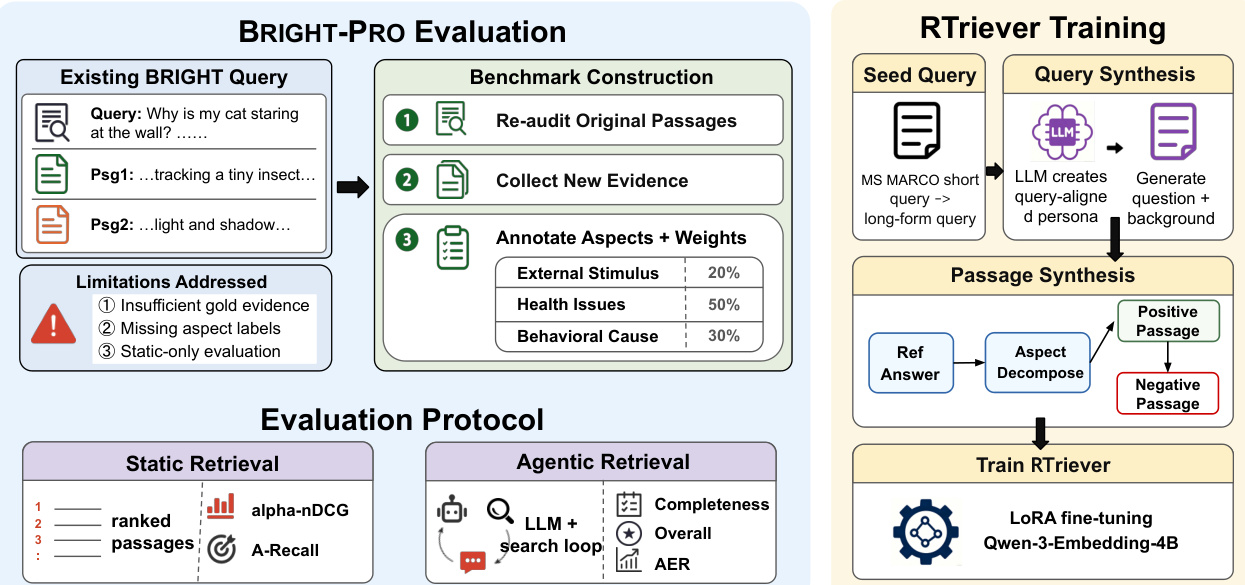
查询和段落合成流程 数据构建过程旨在创建真实的深度研究查询和互补证据集。参考以下详细工作流程:
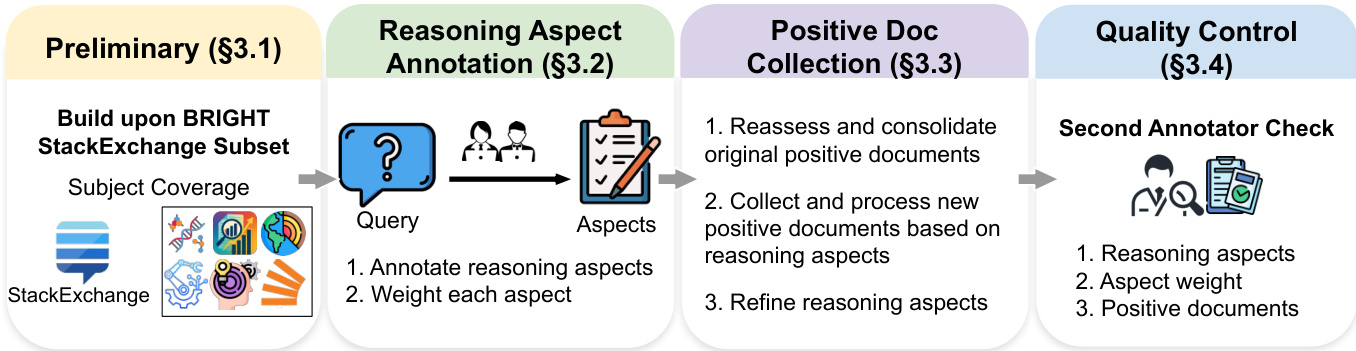
流程始于基于 BRIGHT StackExchange 子集的初步阶段。随后进入推理方面标注,查询被标注关键方面和权重。此后,正文档收集涉及重新评估原始文档并根据推理方面收集新证据。最后,质量控制步骤通过第二标注员检查确保方面、权重和文档的有效性。
具体而言,合成涉及三个关键组件:
- 真实查询表面: 从 MS MARCO 种子开始,作者从 PersonaHub 采样角色,并提示 LLM 将种子重写为带有问题和背景的 DeepResearch 风格帖子。分类器随后将查询标记为事实性或分析性。
- 方面分解的金标准段落: 对于分析性查询,强大的 LLM 首先生成全面的参考答案。第二次 LLM 调用将此答案分解为两到三个不重叠的推理方面。对于每个方面,生成包含理由、段落类型和 TL;DR 的蓝图。这些蓝图随后被实例化为完整的正样本段落。这确保了每个正样本段落都承载负荷,并且与包中的其他段落互补。
- 正样本条件化硬负样本: 固定正样本蓝图后,系统合成同等数量的硬负样本。这些样本以查询和正样本摘要为条件,设计为共享主题线索,但通过省略正样本所需的具体方面来满足信息需求。
RTriever 训练细节 训练利用合成的包,将初始 140K 查询样本过滤至 140K 完整集。作者通过对 Qwen3-Embedding-4B 模型进行 LoRA 微调获得 RTriever-4B。LoRA 适配器附加到所有线性投影层,秩为 r=16,缩放因子为 α=32,而原始嵌入参数保持冻结。
优化针对对比 InfoNCE 目标,温度为 τ=0.02。在每个训练步骤中,一个查询与一个随机采样的正样本段落和一个合成的硬负样本配对,批次中的其他文档作为批次内负样本。模型训练 5 个 epochs,峰值学习率为 1×10−5,5% 线性预热,并使用 bf16 混合精度优化。有效批次大小为 768,在 2 张 NVIDIA B200 GPU 上处理,序列截断至 2,048 tokens。
实验
研究采用双评估协议,包括测量方面覆盖多样性的静态设置和测试迭代深度研究工作流程中检索器的 Agent 设置。发现表明,推理密集型检索器在静态任务中优于通用模型,但由于搜索动态不同,静态排名并不总是转化为 Agent 成功。定性分析揭示了特定的失败模式,如方面隧道视野和证据剥夺,强调了需要优先考虑完整证据组合而非单段落相关性的评估框架。
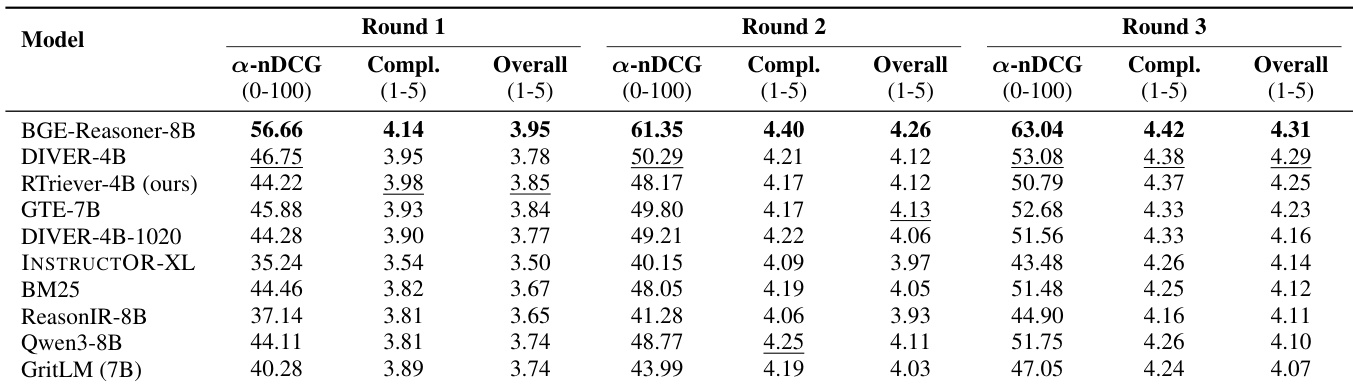
作者在固定轮次 Agent 搜索工作流程中评估检索器,其中 Agent 在三轮中迭代搜索并生成答案。结果表明,虽然静态检索排名松散地转化为 Agent 循环,但 BGE-Reasoner-8B 在所有轮次中始终优于其他模型。BGE-Reasoner-8B 在所有交互轮次中始终实现最高的检索多样性和整体答案质量得分。提出的 RTriever-4B 在整体答案质量中位居第三,优于通用嵌入器,同时与其他推理密集型模型保持竞争力。低层模型表现出检索效果与最终答案质量之间的分歧,一些基线在最后一轮表现出改进的检索多样性,尽管初始排名较低。
该表格详细说明了特定案例研究中的检索统计信息,其中 Agent 由于重复偏差未能覆盖所有推理方面。它显示检索器频繁获取与灵长类动物和人类一夫一妻制相关的相同非金标准文档,消耗了大量搜索预算。相比之下,相关的金标准文档被检索的频率低得多,表明搜索循环固定于离题集群。非金标准文档的检索显著多于金标准文档的检索。检索器在多个搜索轮次中反复出现相同的离题文档。相关金标准文档在结果中很少出现,表明证据收集的多样性差。

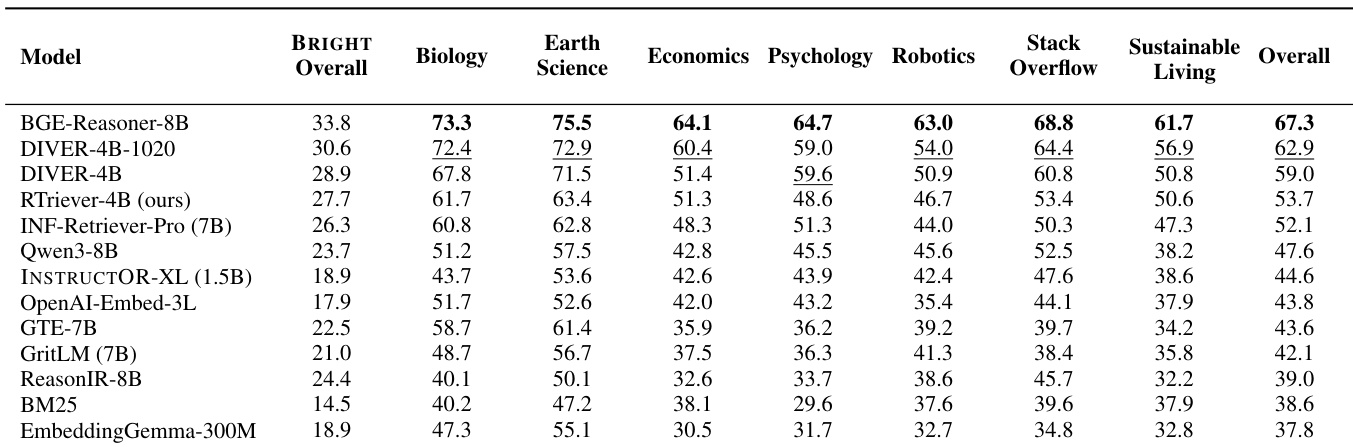
作者在静态设置中使用 BRIGHT-PRO 基准评估检索器,该基准测量七个专家领域的方面感知检索质量。结果表明存在明显的性能差距,其中推理密集型检索器始终优于通用嵌入模型和经典基线。提出的 RTriever-4B 模型取得有竞争力的结果,尽管参数少于一些领先的通用模型,但仍排名靠前。推理密集型检索器在性能上形成一个独特的上层,在所有评估领域显著超过通用嵌入器。提出的 RTriever-4B 模型在生物学和地球科学等专门领域表现出强大能力,与较大的推理模型竞争激烈。经典词汇基线和较小的嵌入模型占据较低排名,凸显了复杂检索任务进行方面感知训练的必要性。
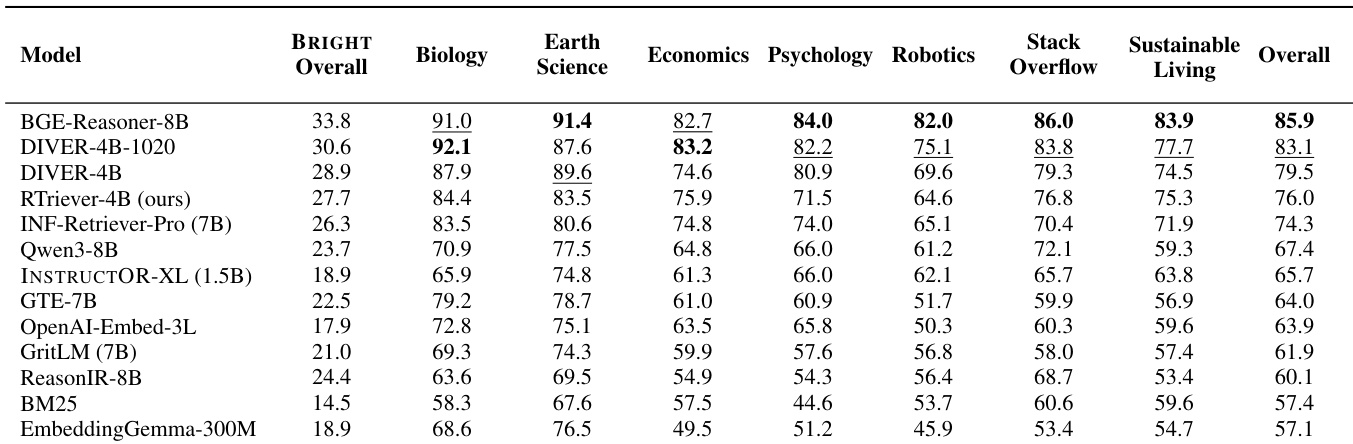
作者在静态设置中使用方面感知指标评估检索器,以评估多个领域的推理方面覆盖情况。结果表明,推理密集型模型始终优于通用嵌入基线,形成独特的性能上层。提出的 RTriever-4B 模型取得强劲结果,尽管参数少于一些竞争对手,但在专业检索器中排名靠前。推理密集型检索器在所有领域建立了明显高于通用嵌入模型的性能层级。BGE-Reasoner-8B 在大多数领域和整体聚合指标上取得最高分。RTriever-4B 优于较大的通用基线,证明了其特定训练目标在参数数量上的有效性。
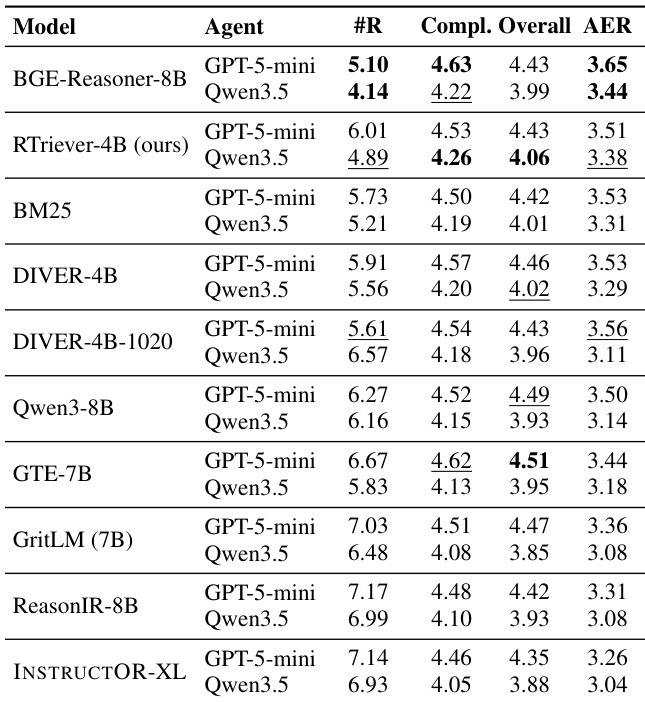
该表格展示了自适应轮次 Agent 检索评估的结果,衡量不同检索器支持 LLM Agent 在深度研究工作流程中的效率。它突出了权衡,即最高的整体答案质量并不总是与最佳效率得分相关,因为需要更多搜索轮次的模型在效率 - 质量奖励指标中会受到惩罚。BGE-Reasoner-8B 通过在最少搜索轮次中收敛答案获得最高效率得分。RTriever-4B 在不同 Agent 后端中保持效率第二名的稳定排名,表明在较低计算成本下具有稳健性能。像 GTE-7B 这样的模型实现了峰值整体答案质量,但由于依赖更多检索轮次,在效率指标中受到惩罚。
作者在静态基准和 Agent 搜索工作流程中评估检索器,以评估方面感知检索质量和最终答案生成。推理密集型模型始终形成一个独特的上层,在检索多样性和答案准确性上优于通用嵌入基线,BGE-Reasoner-8B 在更少的搜索轮次中收敛。虽然较弱的模型通常因重复偏差而失败,但提出的 RTriever-4B 仍然是一个有竞争力的替代方案,证明了专门训练在参数数量上的有效性。