Command Palette
Search for a command to run...
Stream-R1:用于流式视频生成的可靠性-困惑度感知奖励蒸馏
Stream-R1:用于流式视频生成的可靠性-困惑度感知奖励蒸馏
Bin Wu Mengqi Huang Shaojin Wu Weinan Jia Yuxin Wang Zhendong Mao Yongdong Zhang
摘要
基于蒸馏的加速方法已成为使自回归流式视频扩散模型具备实用性的基石,其中分布匹配蒸馏(Distribution Matching Distillation, DMD)已成为事实上的标准选择。然而,现有方法在训练学生模型时,不加区分地让其模仿教师模型的输出,将每一次展开(rollout)、每一帧以及每一个像素都视为同等可靠的监督信号。我们认为,这种做法限制了蒸馏模型的质量上限,因为它忽略了 DMD 监督中两个互补的方差维度:跨展开可靠性(Inter-Reliability),即不同学生模型展开过程所受到的监督可靠性存在差异;以及局部困惑度(Intra-Perplexity),即空间区域和时间帧对质量改进潜力的贡献不均。因此,该目标函数在一个统一的权重下混淆了两个核心问题:是否应从每次展开中学习,以及在展开内部应将优化重点集中在哪些区域。为解决这一问题,我们提出了 Stream-R1,这是一种可靠性-困惑度感知奖励蒸馏(Reliability-Perplexity Aware Reward Distillation)框架,通过单一的共享奖励引导机制,在展开和时空元素两个层级自适应地重新加权蒸馏目标。在跨展开可靠性层面,Stream-R1 根据预训练视频奖励分数的指数对每次展开的损失进行缩放,从而使具有可靠监督的展开在优化过程中占据主导地位。在局部困惑度层面,它反向传播相同的奖励模型以提取逐像素的梯度显著性图,并将该显著性分解为空间和时间权重,从而将优化压力集中在那些优化后能带来最大预期收益的区域和帧上。一种自适应平衡机制防止了任何单一质量维度在视觉质量、运动质量和文本对齐方面占据主导。在标准的流式视频生成基准测试中,Stream-R1 在所有这三个维度上均优于蒸馏基线方法,且无需修改架构或增加推理成本。
一句话总结
本文提出 Stream-R1,一种可靠性-困惑度感知奖励蒸馏框架,通过共享的奖励引导机制,在 rollout 和时空区域上自适应地重新加权分布匹配目标,从而加速自回归流式视频生成,克服无差别监督并最大化蒸馏输出的质量。
核心贡献
- Stream-R1 引入了一种可靠性-困惑度感知奖励蒸馏框架,采用自适应的奖励引导重新加权机制,取代了分布匹配蒸馏中的统一监督。
- 该方法利用预训练的视频奖励分数动态缩放 rollout 损失,以优先保障可靠的监督信号,同时通过反向传播同一奖励模型提取逐像素梯度显著性,将优化集中指向需要改进的空间区域与时间帧。
- 在标准流式视频生成基准上的评估表明,与蒸馏基线相比,该方法在视觉质量、运动质量和文本对齐方面均实现了持续提升,且无需对学生模型进行架构修改或增加额外的推理开销。
引言
自回归流式视频模型支持任意时长的逐帧合成,但其多步去噪过程仍具有较高的计算成本。分布匹配蒸馏已成为将教师模型推理压缩为高效少步学生模型生成的标准加速技术。然而,现有方法在所有 rollout、帧和像素上施加统一的优化压力,忽略了梯度可靠性与区域改进潜力方面的关键差异。这种无差别的方法从根本上限制了蒸馏视频的质量上限。为解决这一问题,作者提出了 Stream-R1,一种奖励引导的蒸馏框架,能够在 rollout 和时空层面动态重新加权监督信号。通过利用预训练视频奖励分数缩放损失并提取逐像素梯度显著性,该方法将优化集中于高价值区域,同时过滤不可靠的梯度。自适应平衡机制进一步确保了视觉保真度、运动连贯性与文本对齐的均衡进展,在不修改架构或不增加推理开销的情况下,带来一致的质量提升。
数据集
- 数据集构成与来源:提供的摘要未列出特定的精选数据集。作者转而依赖标准流式视频生成基准,并利用教师-学生视频扩散架构合成训练数据。
- 各子集关键细节:未详细说明明确的数据集子集、规模或过滤标准。工作流程侧重于动态生成自回归 rollout,而非划分静态数据集。
- 论文的数据使用方式:作者利用合成的 rollout 通过分布匹配蒸馏将多步教师模型蒸馏为少步学生模型。基于 rollout 可靠性与时空困惑度动态重新加权蒸馏目标,确保学生模型在无统一监督的情况下继承高质量生成模式。
- 处理与元数据构建:作者未采用裁剪或传统元数据标注,而是通过算法推导处理权重。通过对预训练视频奖励模型进行反向传播生成逐像素梯度显著性体,并将其分解为空间与时间分量,形成自适应损失掩码,将优化集中于改进收益最大的区域。
方法
作者提出了 Stream-R1,一种强化学习引导的视频蒸馏框架,通过奖励信号动态调节蒸馏损失,以提升学生生成器与预训练教师模型的对齐程度。该方法基于分布匹配蒸馏(DMD),学生生成器 Gϕ 通过最小化与预训练教师扩散模型 ϵθ 之间的基于 KL 散度的目标,学习在更少步数内生成高质量视频。在此设置中,学生模型根据文本提示 c 生成干净潜在变量 x0=Gϕ(c),并通过在随机时间步 t 添加噪声构建噪声版本 xt。蒸馏梯度 g 计算为两个判别网络的差值:ffake 估计学生输出分布的分数,freal 估计教师输出分布的分数。基础 DMD 损失定义为 LDMD=21∥x0−sg(x0−g^)∥2,其中 g^ 为归一化梯度,sg(⋅) 为停止梯度算子。

该框架旨在解决现有 DMD 方法的两个关键局限:不同 rollout 间梯度信号可靠性的波动,以及缺乏细粒度时空优化指导。为解决第一个问题,Stream-R1 引入了跨 rollout 可靠性加权机制。作者指出,梯度 g=ffake−freal 对所有生成样本的可靠性并非均等。当学生 rollout 接近教师的高质量模式时,g 提供缩小差距的可靠信号。然而,当 rollout 远离该模式时,g 反映的是低质量区域内的局部优化,而非通向高质量的路径。为缓解此问题,框架在学生生成的视频 V 上查询预训练视频奖励模型,并计算平衡后的总体奖励 rfinal。该标量奖励作为 DMD 监督可靠性的代理指标。随后,奖励通过指数重新加权转换为逐样本损失乘子:Winter=exp(β⋅rfinal),其中 β>0 为温度参数。这确保了高奖励(即更可靠梯度)的 rollout 对损失产生更强的贡献,而低奖励 rollout 则被衰减。
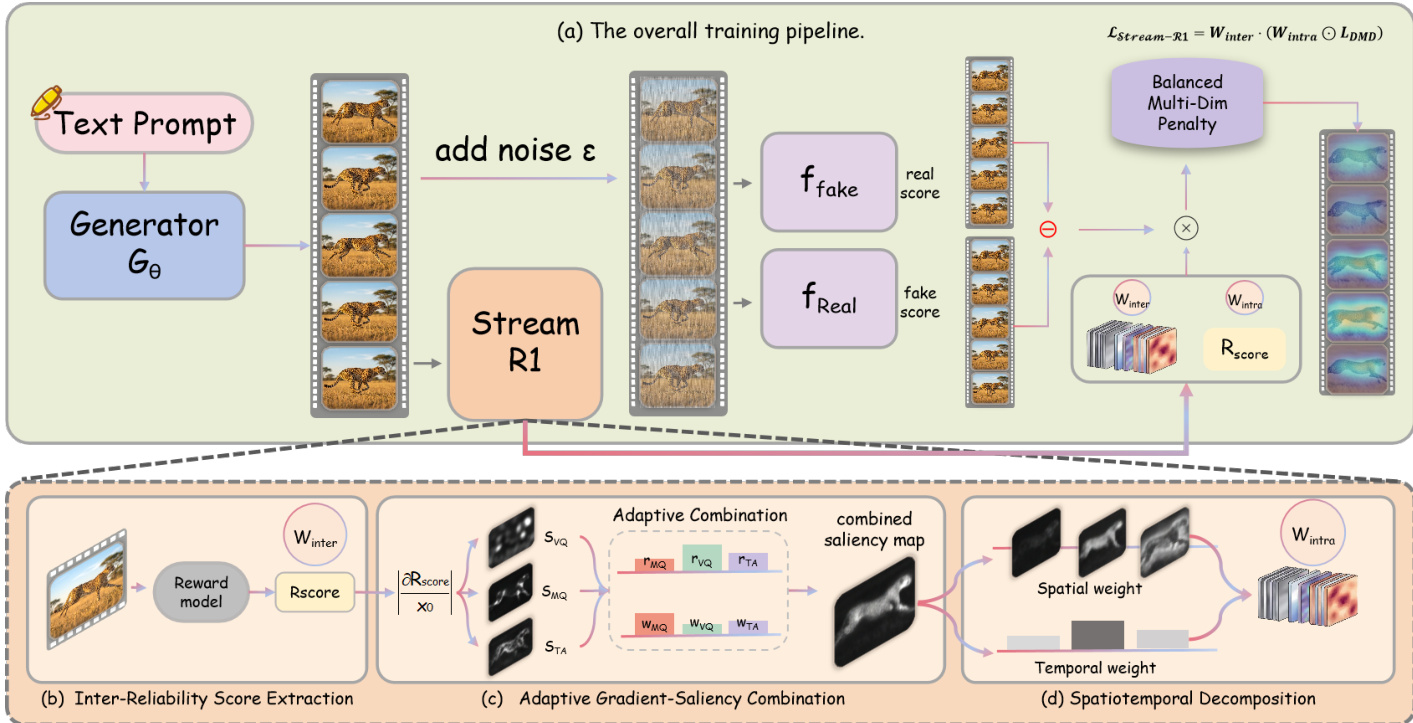
为解决第二个局限,Stream-R1 引入了内部困惑度加权机制,为优化提供逐元素时空指导。该机制通过对奖励模型梯度导出的显著性图进行因子分解实现。流程始于自适应梯度-显著性融合,将奖励相对于视频潜在变量 x0 在多个质量维度(如视觉质量、运动质量、时间对齐)上的梯度合并为单一显著性体 Scombined∈RF×H×W。该显著性体联合编码了空间与时间敏感性。为解耦这些因素,执行时空分解。时间权重通过对每帧在空间维度上平均显著性提取,随后进行 min-max 缩放并钳位至最小值 τmin,以防止任何帧被抑制。这些时间权重随后进行均值归一化,以保留总体损失量级。空间权重通过独立对每帧内的显著性进行 min-max 缩放并钳位至最小值 σmin,随后将每帧的权重均值归一化为 1 来提取。最终的逐元素权重图 Wintra 通过相乘时空分量并应用全局均值归一化获得。
框架的关键组件之一是平衡多维奖励,用于防止优化器过度聚焦于单一质量维度。系统维护近期奖励历史的滑动窗口,并将每个维度的改进计算为近期平均奖励与基线平均奖励之差。平衡惩罚定义为所有维度改进的标准差,从基础奖励中减去该惩罚,以抑制发散的改进轨迹。该惩罚在预热期后激活,以便初始奖励估计稳定。
总体 Stream-R1 损失将这些组件整合为单一目标:LStream-R1=21Winter⋅mean(Wintra⊙∥x0−sg(x0−g^)∥2)。该公式确保优化不仅由整体样本的可靠性引导,还由奖励敏感性的细粒度时空分布引导,将计算资源集中于进一步优化能带来最大预期收益的区域与帧。
实验
评估采用自动化质量指标、VLM 评分与人类偏好研究,对短视频与长视频生成进行基准测试,以评估整体性能与时间稳定性。消融实验与受控退化实验验证了自适应梯度-显著性机制能有效将优化集中于时空缺陷区域,而非施加统一监督。定性比较与可视化确认,这种靶向加权缓解了长序列中的累积质量漂移,并自然凸显需要改进的区域。最终,该方法证明奖励引导的时空定位可使蒸馏模型在保持推理效率的同时,在生成质量上超越教师模型。
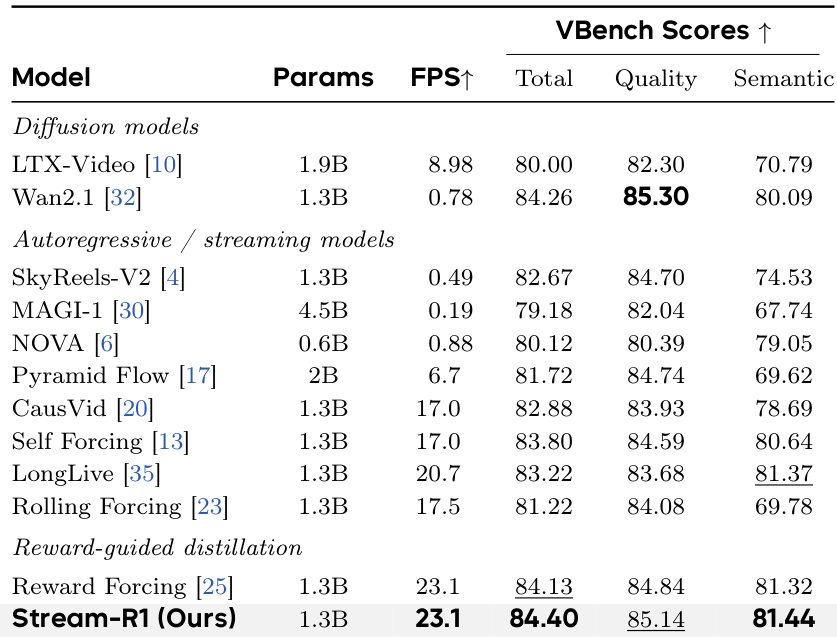
作者对提出的 Stream-R1 模型与多种最先进视频生成方法进行了全面评估,涵盖短视频与长视频生成。结果表明,Stream-R1 在各项质量指标上均实现卓越性能,尤其在视觉质量、运动动态与文本对齐方面,同时展现出改进的时间一致性与长视频质量衰减的降低。消融实验与可视化进一步验证了模型的有效性,确认时空权重能有效定位最具质量改进潜力的区域。Stream-R1 在所有评估指标(包括视觉质量、运动动态与文本对齐)上均优于现有方法,并在各维度取得最高分。模型在长时生成中表现持续改进,与基线的性能差距逐渐拉大,表明其对质量漂移的缓解效果更佳。消融研究证实,时空加权机制的每个组件均对整体性能有所贡献,其中时间分解带来的提升最为显著。
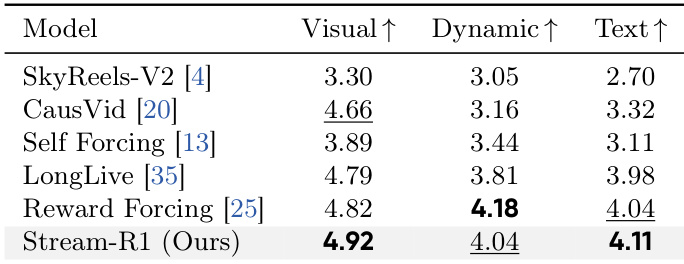
作者将 Stream-R1 方法与多种最先进视频生成模型进行对比,涵盖基于扩散与自回归/流式模型,以及奖励引导蒸馏基线。结果表明,Stream-R1 在多项指标上取得最高分,尤其在质量与语义性能方面,同时保持高推理速度。消融研究证实,各提出组件均对整体改进有所贡献,其中时间显著性分解带来的增益最大。在所有对比方法中,Stream-R1 取得最高的总分与语义分,优于扩散模型与自回归模型。该方法在质量上超越其自身的多步扩散教师模型,且推理速度显著提升。消融研究中,时间显著性分解贡献了最大改进,同时提升了质量并降低了长视频生成的漂移。
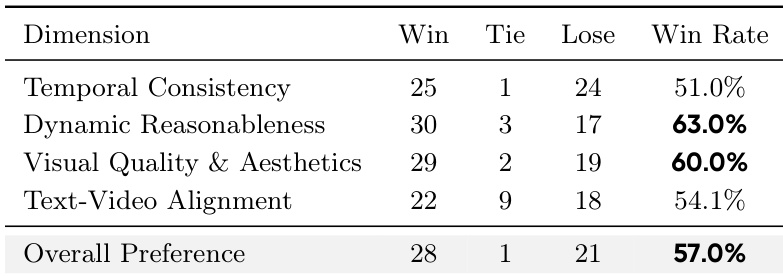
作者开展了人类偏好评估,将方法与基线进行对比,在 50 个长视频上评估五个维度。结果表明,该方法在所有维度均获偏好,其中动态合理性与视觉质量的领先幅度最大,表明感知质量与运动连贯性得到改善。人类评估者对所有五个评估维度均更倾向于提出方法。动态合理性与视觉质量取得最大优势,表明运动与美学性能更优。整体偏好胜率为 57.0%,证明人类对该方法具有一致的偏好。
作者开展消融研究以评估不同组件对视频生成质量的影响,重点关注空间与时间奖励加权。结果表明,将空间显著性与平衡多维奖励及时间分解相结合,在短视频与长视频基准上均取得最高性能,显著提升质量并降低漂移。相比基线,添加空间显著性改善了质量指标。引入时间分解带来总分最大的单项提升并降低漂移。当所有组件结合时,模型达到最优性能,优于调整超参数的变体。
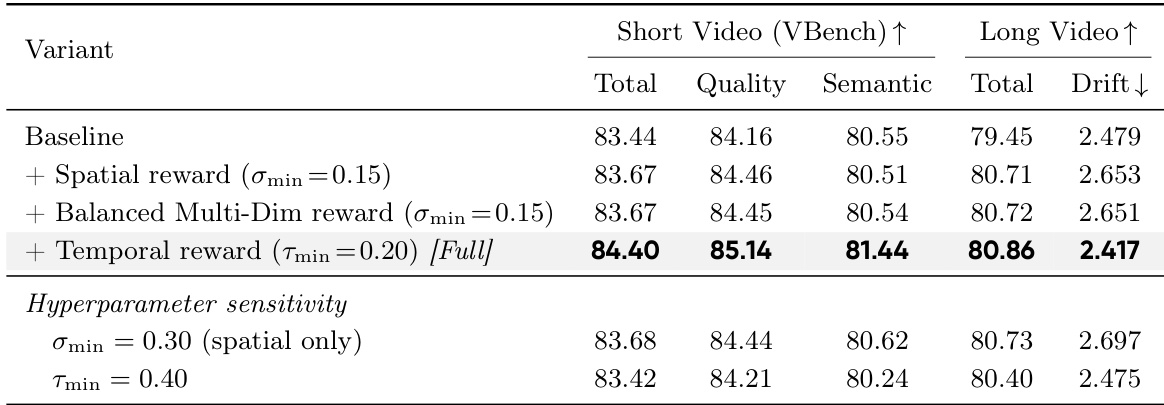
评估在短视频与长视频生成任务中,将 Stream-R1 与最先进的扩散、自回归及奖励引导基线进行对比。综合基准测试表明,该模型持续提供卓越的视觉保真度、连贯的运动动态与精确的文本对齐,同时在长序列中有效保持时间一致性。消融研究验证了所提空间与时间加权机制的独立贡献,确认时间分解驱动了最显著的性能提升。人类偏好评估进一步佐证了这些结果,凸显相比现有方法在感知质量与运动合理性方面的明确优势。