Command Palette
Search for a command to run...
AGENTIC-IMODELS:通过自动研究进化智能代理可解释性工具
AGENTIC-IMODELS:通过自动研究进化智能代理可解释性工具
Chandan Singh Yan Shuo Tan Weijia Xu Zelalem Gero Weiwei Yang Michel Galley Jianfeng Gao
摘要
遗传数据科学(Autonomous Data Science, ADS)系统正在迅速提升其自主分析、拟合和解读数据的能力,未来有望实现由智能体(Agents)承担绝大多数数据科学工作的愿景。然而,当前的 ADS 系统使用的是旨在供人类解读的统计工具,而非旨在供智能体解读的工具。为解决这一问题,我们引入了 AGENTIC-IMODELS,这是一种智能体自研循环(agentic autoresearch loop),能够演化出专为智能体解读设计的数据科学工具。具体而言,该框架开发了一个与 scikit-learn 兼容的回归模型库,适用于表格数据,并在预测性能和一种基于 LLM 的新型可解释性指标方面均进行了优化。该指标基于一套由 LLM 评分的测试套件,旨在探测拟合模型的字符串表示是否具备“可模拟性”(simulatable),即仅通过阅读模型的字符串输出,LLM 能否回答关于该模型行为的问题。我们发现,经过演化获得的模型在提升预测性能的同时,也增强了面向智能体的可解释性,并且这一优势能够泛化到新数据集和新解读测试中。此外,这些演化模型还改善了下游端到端的 ADS 系统性能,使 Copilot CLI、Claude Code 和 Codex 在 BLADE 基准测试中的表现最高提升了 73%。
一句话总结
作者介绍了 AGENTIC-IMODELS,这是一个代理式自动研究循环,用于进化兼容 scikit-learn 的表格数据回归器,旨在优化预测性能和一种新颖的基于 LLM 的可解释性指标,该指标衡量 agent 可模拟性,将 Copilot CLI、Claude Code 和 Codex 在 BLADE 基准测试上的下游性能提升了高达 73%。
核心贡献
- 本工作介绍了 AGENTIC-IMODELS,这是一种代理式自动研究循环,旨在进化可由 AI agent 而非人类解释的数据科学工具。该系统开发了一个兼容 scikit-learn 的表格数据回归器库,同时优化预测性能和面向 agent 的可解释性。
- 该方法使用一种新颖的基于 LLM 的可解释性指标来优化模型,该指标探测拟合模型的字符串表示是否可被 LLM 模拟。该指标评估 agent 是否仅通过阅读模型的字符串输出就能回答关于模型行为的问题。
- 实验表明,进化的模型同时提高了预测性能和面向 agent 的可解释性,同时泛化到新数据集和可解释性测试。这些模型还提高了下游端到端 ADS,将 Copilot CLI、Claude Code 和 Codex 在 BLADE 基准测试上的性能提升了高达 73%。
引言
随着代理式数据科学系统越来越多地自动化分析工作流,它们目前依赖于为人类消费设计而非为 agent 解释设计的可解释性工具。这种不匹配限制了系统可靠性,因为现有的输出(如可视化)难以被 agent 准确解析。为了解决这个问题,作者介绍了 AGENTIC-IMODELS,这是一个自动研究循环,用于进化兼容 scikit-learn 的回归器,同时优化预测准确率和面向 agent 的可解释性。该框架使用一种新颖的基于 LLM 的指标来衡量可模拟性,并在下游代理式数据科学基准测试上实现了高达 73% 的性能增益。
数据集
- 组成与来源: 主要实验使用了来自 OpenML 和 PMLB 的 65 个数据集,包括来自 OpenML 的 7 个和来自 PMLB 的 58 个。
- 泛化数据: 作者保留了 16 个 OpenML 数据集用于泛化实验。
- 处理与子采样: 在评估期间,每个数据集被子采样至最多 1,000 个样本和 50 个特征。
- 元数据与计数: 在子采样发生之前记录了原始样本和特征计数。
- 模型使用: 优化循环包含了按认知操作分组的 43 项可解释性测试。
- 评估策略: 泛化性使用 157 项新的可解释性测试进行评估,通过率汇总自 9 次 AGENTIC-IMODELS 运行。
方法
作者利用代理式自动研究循环自动发现既准确又可被 LLM 解释的模型类别。AGENTIC-IMODELS 的目标是同时优化预测性能和一种新颖的可解释性指标。这是通过使用一个 coding agent 实现的,该 agent 迭代提出并改进模型实现,具体为兼容 scikit-learn 的 Python 类,包含 fit、predict 和 __str__ 方法。该 agent 在一套表格回归数据集上评估候选模型的性能,并利用 LLM 评分测试进行可解释性评估。
参考框架图以了解该循环的高层架构,其中 agent 与 Agentic-imodels 库交互,并根据来自性能和可解释性测试的反馈进行迭代。
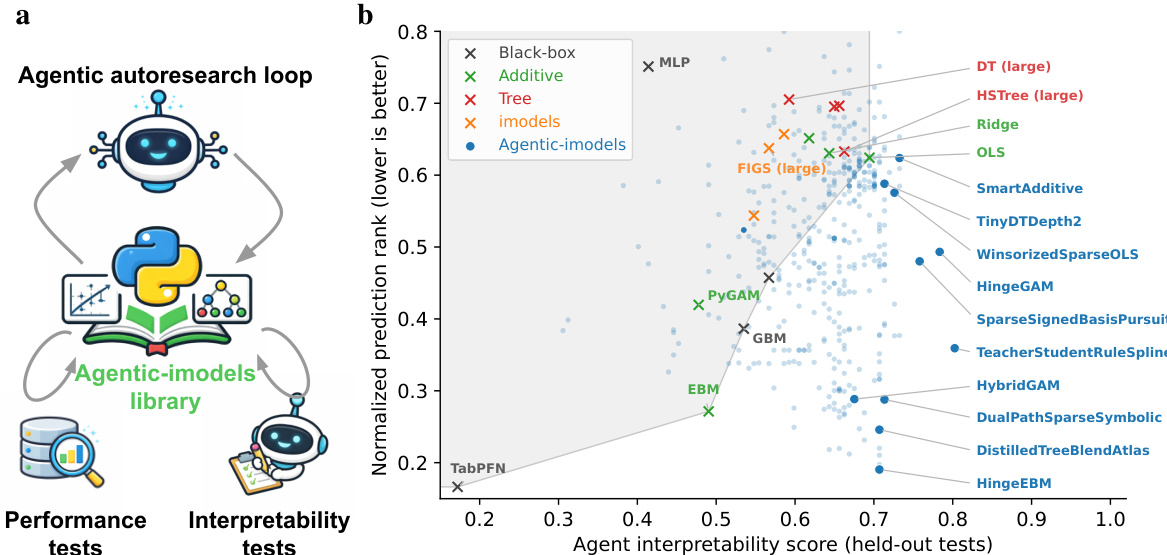
为了评估可解释性,系统将 Agent 可解释性得分定义为基于 LLM 测试的通过率。这些测试探测 LLM 是否仅通过阅读拟合模型的 __str__ 输出就能回答关于该模型的定量问题。该协议包括从已知真实函数生成合成数据,拟合模型,并向 LLM 提供字符串表示和查询。响应根据真实情况进行评分。测试套件涵盖六个类别:特征归因、点模拟、敏感性分析、反事实推理、结构理解和复杂函数模拟。
该框架促进了采用显示 - 预测解耦架构的发现,其中内部预测逻辑比显示表示更复杂。例如,HingeEBM_5bag 模型拟合一个两阶段模型,涉及分段线性基展开和残差上的 EBM,但其 __str__ 方法仅显示一个折叠的线性方程。在阶段 1,对于每个特征 j,它在 K=2 分位数节点处构建正 hinge 项 max(0,xj−t) 和负 hinge 项 max(0,t−xj)。Lasso 选择稀疏子集以产生阶段 1 预测:
在阶段 2,如果残差解释了超过 10% 的剩余方差,则拟合 EBM,但最终预测结合两个阶段,而显示逻辑将 hinge 贡献折叠为有效线性斜率。
类似地,SmoothAdditiveGAM 模型拟合一个贪婪加法提升 stump 模型。在 200 轮中的每一轮,它选择特征 j 和阈值 τ,通过深度 1 树最大程度地减少残差 SSE,更新每特征形状函数 fj,并减去拟合的步长。提升后,应用 3 次拉普拉斯平滑。预测为:
y^=μ+j∑fj(xj),其中每个 fi 是一个分段常数函数。对于显示,为每个特征计算线性近似,如果 R2>0.90,则将其渲染为系数。此平滑步骤至关重要,因为它平整了不规则形状函数,增加了表现为简单线性项的特征比例。另一个变体 RidgeRFResid 结合了用于显示的 Ridge 回归模型和用于预测的基于残差拟合的 Random Forest,在保持有竞争力性能的同时实现了高可解释性得分。
实验
本研究采用自主 coding agent 在 65 个数据集上进化可解释回归模型,并将它们与 16 个标准基线进行基准比较,以评估预测和可解释性性能。进化的模型在可解释性 - 性能前沿上实现了帕累托改进,结果在不同 LLM 评估器和保留数据集上保持稳健。此外,将这些模型集成到下游 AI 数据科学 agents 中,由于限制显示复杂度的架构策略,与标准工具相比,显著提高了它们在 BLADE 基准测试上的分析性能。
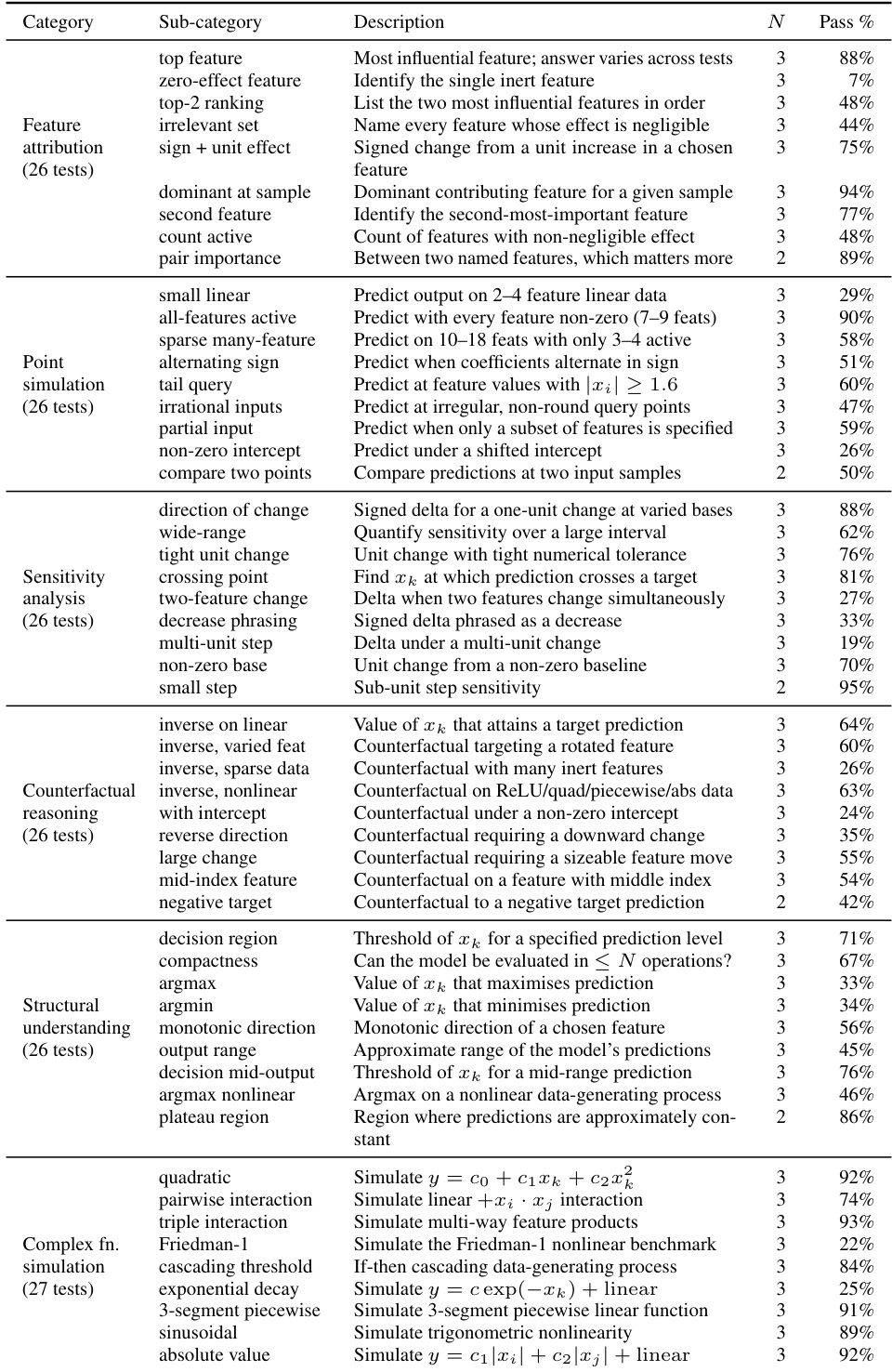
下表详细说明了进化的模型在包含 157 项可解释性测试的综合套件中的细粒度性能,按任务类型分类,如特征归因、敏感性分析和函数模拟。数据显示成功率差异很大,表明模型在特定结构和敏感性任务上非常有效,但在其他任务上存在显著困难,特别是涉及复杂交互或识别无效效应的任务。模型在简单敏感性任务和特定非线性函数模拟(如二次和绝对值模拟)上实现了非常高的成功率。对于需要识别无关特征或复杂多特征变化的任务,性能明显较弱,通过率显著下降。评估套件涵盖了广泛的复杂度,从线性预测到反事实推理,揭示了结构理解方面的特定优势,以及在处理稀疏或高维特征交互方面的局限性。
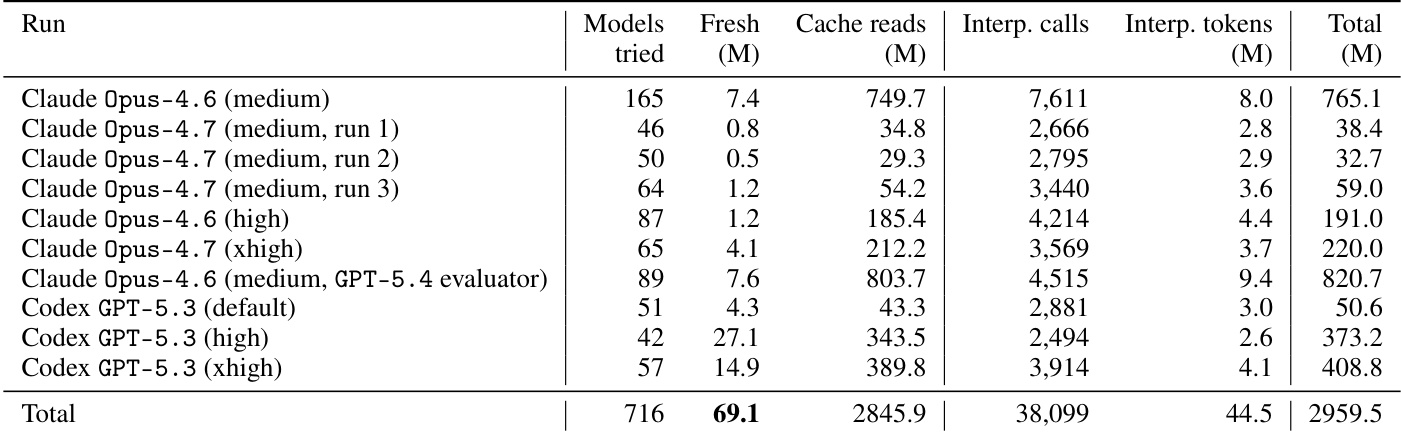
下表详细说明了 AGENTIC-IMODELS 自动研究循环在不同 coding agents 和推理努力级别下的 token 消耗。它区分了 fresh tokens,代表新处理,和 cache reads,占总体积主导地位但计费费率较低。结果显示 token 分布存在显著差异,具体取决于使用的特定 agent 和配置。cache reads 占所有实验运行总 token 量的绝大多数。与列出的大多数 Claude 配置相比,Codex 高努力运行的 fresh token 消耗明显更高。总 token 使用量受 cache read 量严重影响,该量在不同模型配置和推理努力之间波动很大。
下表概述了用于评估进化回归模型的可解释性测试综合套件,将任务分类为特征归因、模拟和敏感性分析等领域。这些测试构成了 agent 可解释性得分的基础,该得分与预测性能进行基准比较以评估 AGENTIC-IMODELS 框架的权衡。结果表明,模型在基础归因和结构任务上表现出色,但在复杂模拟和反事实推理方面面临不同程度的困难。特征归因和结构理解测试在评估的模型中始终表现出高成功率。点模拟任务表现出显著的难度差异,简单预测成功,而复杂多特征交互经常困难。敏感性分析产生稳健性能,而反事实推理任务给系统带来了最大的挑战。

实验评估了四个 AI coding agents 在 BLADE 基准测试上的表现,比较了它们使用标准工具与利用进化 AGENTIC-IMODELS 时的性能。数据显示,当包含专用模型时,所有 agent 的分数均呈现一致上升趋势。值得注意的是,起始基准性能较低的 agent 经历了最显著的改进。与标准工具相比,所有四个 coding agents 在配备 AGENTIC-IMODELS 包时都获得了更高的平均分数。基座模型较弱的 agents 在性能指标上表现出最大的相对增益。性能提升在各个数据集上保持一致,AGENTIC-IMODELS 在几乎每种情况下都优于标准工具。
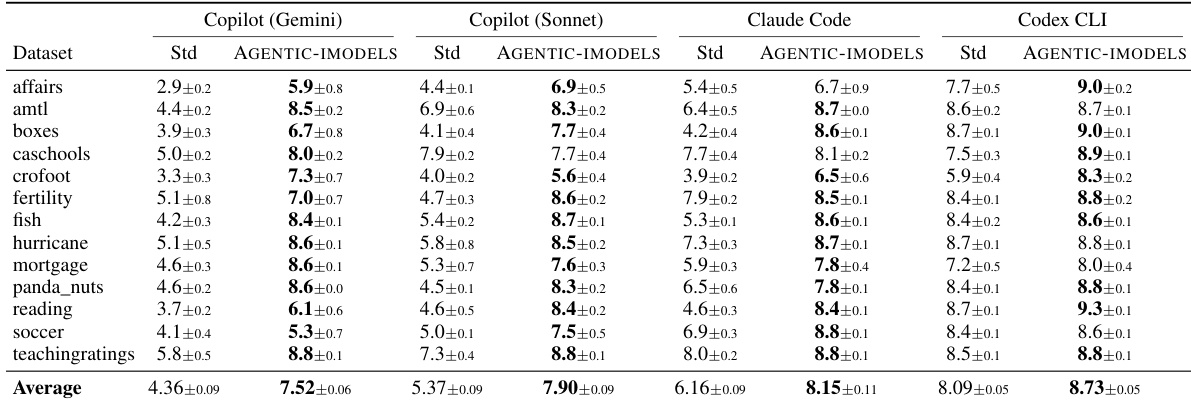
实验评估了 AGENTIC-IMODELS 框架在可解释性测试、token 消耗分析和 coding agents 在 BLADE 基准测试上的性能。可解释性结果表明,进化的模型在结构理解和敏感性分析方面表现出色,但在复杂特征交互和反事实推理方面存在困难。虽然 token 使用主要由 cache reads 驱动,但集成专用模型始终提高了 coding agent 分数,为基准能力较弱的 agents 提供了最显著的性能增益。