Command Palette
Search for a command to run...
Uni-OPD:统一基于策略的蒸馏与双重视角配方
Uni-OPD:统一基于策略的蒸馏与双重视角配方
摘要
在线蒸馏(On-policy Distillation, OPD)近期作为一种有效的后训练范式崭露头角,旨在将多个专用专家模型的能力整合至单一的学生模型中。尽管其在实践中取得了显著成功,但 OPD 能够带来可靠提升的具体条件仍未得到深入理解。在本研究中,我们识别出限制 OPD 有效性的两个根本瓶颈:一是对具有高信息量的状态(informative states)探索不足;二是针对学生轨迹(student rollouts)的教师监督信号不可靠。基于这一洞察,我们提出了 Uni-OPD,这是一个统一且通用的 OPD 框架,适用于大型语言模型(LLMs)和多模态大型语言模型(MLLMs),其核心在于一种双视角优化策略。具体而言,从学生的视角出发,我们采用两种数据平衡策略,以促进训练过程中对学生生成的高信息量状态的探索。从教师的视角出发,我们发现可靠的监督取决于聚合后的 token 级指导信号是否与结果奖励(outcome reward)保持顺序一致性。为此,我们开发了一种基于结果引导的边际校准机制(outcome-guided margin calibration mechanism),以恢复正确轨迹与错误轨迹之间的顺序一致性。我们在涵盖多种设置的五个人类主要领域和16个基准测试(benchmarks)上进行了广泛的实验,包括跨 LLMs 和 MLLMs 的单教师与多教师蒸馏、强到弱(strong-to-weak)蒸馏以及跨模态蒸馏。
一句话总结
Uni-OPD 通过双重策略统一了 LLMs 和 MLLMs 的 on-policy 蒸馏,该策略通过采用两种数据平衡策略来促进信息丰富的学生生成状态,并采用结果引导的边界校准机制来恢复正确和错误轨迹之间的顺序一致性,从而解决了探索和监督瓶颈,并在五个领域和十六个基准上进行了评估。
核心贡献
- 本文介绍了 Uni-OPD,这是一个统一的 on-policy 蒸馏框架,可泛化至大型语言模型和多模态大型语言模型。该框架以双视角优化策略为核心,以提高数据适用性和训练稳定性。
- 技术贡献包括两种数据平衡策略以促进学生的探索,以及一种结果引导的边界校准机制以恢复教师监督中的顺序一致性。这些组件确保可靠的指导在学生 rollout 期间与结果奖励保持一致。
- 广泛的实验验证了该方法在 5 个领域和 16 个基准上的表现,涵盖单教师和多教师蒸馏等设置。评估包括涉及 LLMs 和 MLLMs 的强到弱和跨模态蒸馏场景。
引言
后训练大型语言模型需要平衡监督微调和强化学习,以注入推理能力,同时避免遭受暴露偏差或不稳定的信用分配。虽然 on-policy 蒸馏 (OPD) 通过结合 on-policy 采样和 token 级监督提供了一个有前途的解决方案,但其可靠性仍知之甚少,且先前的工作主要局限于纯文本模型。作者识别出现有 OPD 方法中的两个关键瓶颈:对信息丰富状态的探索不足,以及缺乏与结果奖励顺序一致性的不可靠教师监督。为了解决这些挑战,他们提出了 Uni-OPD,这是一个采用双视角优化策略的统一框架。作者利用数据平衡技术来鼓励多样的学生探索,并引入结果引导的边界校准机制以确保可靠的教师指导。这种统一的方法有效地泛化至 LLMs 和 MLLMs 在各种蒸馏设置中。
数据集
作者整理了一个专门的训练语料库,并使用一套既定的基准验证性能。
训练数据组成与处理
- 文本数学推理:来自 DeepMath 数据集的 57.0K 样本,过滤难度等级为 6 或更高,以训练数学推理能力。
- 文本代码生成:来自 Eurus-2-RL-Data 数据集代码子集的 25.3K 样本,用于代码生成能力。
- 多模态数学推理:来自 OpenMMReasoner-RL 数据集的 14.8K 样本,涵盖 MMK12、WeMath-Standard 和 WeMath-Pro 子集。
- 多模态逻辑推理:来自 OpenMMReasoner-RL-74K 数据集的 14.8K 样本,涵盖 AlgoPuzzle、PuzzleVQA 和 ThinkLite-VL-Hard 子集。
- 多模态文档理解:来自 OpenMMReasoner 的 TQA 子集的 15% 采样获得的 14.6K 样本,结合 ChartQA 和 InfographicsVQA 训练集。
评估基准
- 文本数学:AIME (2024/2025) 和 HMMT25,用于竞赛级推理挑战。
- 文本代码:HumanEval+、MBPP+ 和 LiveCodeBench (v6),用于功能正确性和执行评估。
- 多模态数学:MathVision、DynaMath 和 WeMath,用于跨学科和知识概念的视觉问题解决。
- 多模态逻辑:LogicVista 和 VisuLogic,用于难以用文本表达的视觉推理任务。
- 文档理解:AI2D、ChartQA、DocVQA 和 InfoVQA,用于图表和布局推理能力。
方法
作者提出了 Uni-OPD,这是一个旨在推进 LLMs 和 MLLMs 同策略蒸馏 (OPD) 的统一框架。该架构解决了标准 OPD 中的两个根本瓶颈:对信息丰富的学生生成状态探索不足,以及对学生 rollout 的不可靠教师监督。该框架通过双视角方案运行,通过数据平衡增强学生探索,并校准教师监督以与结果奖励对齐。
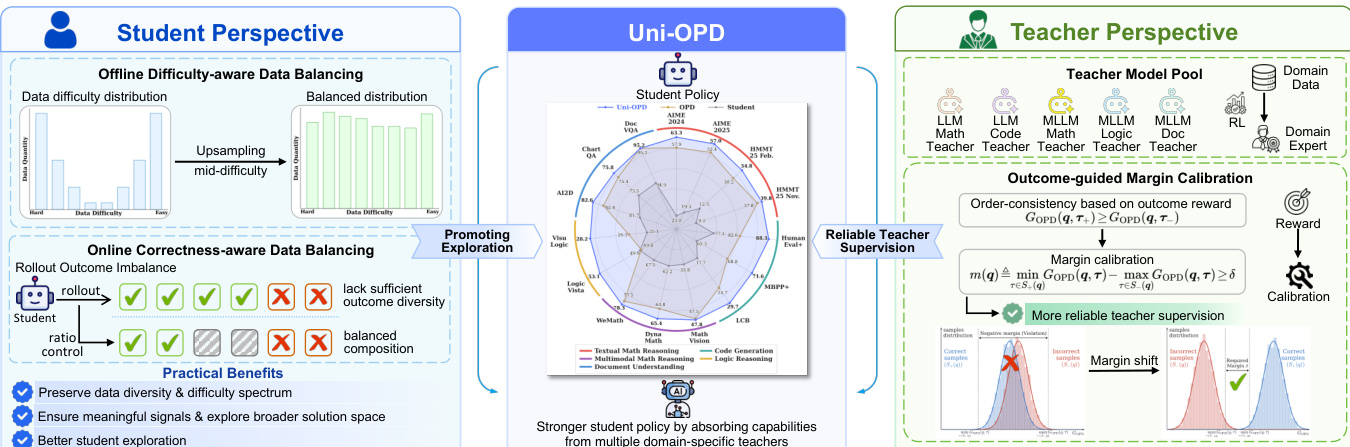
学生视角:用于探索的联合数据平衡
从学生的角度来看,该框架采用两阶段数据平衡策略,以确保生成的轨迹具有足够的多样性和适当的难度等级。
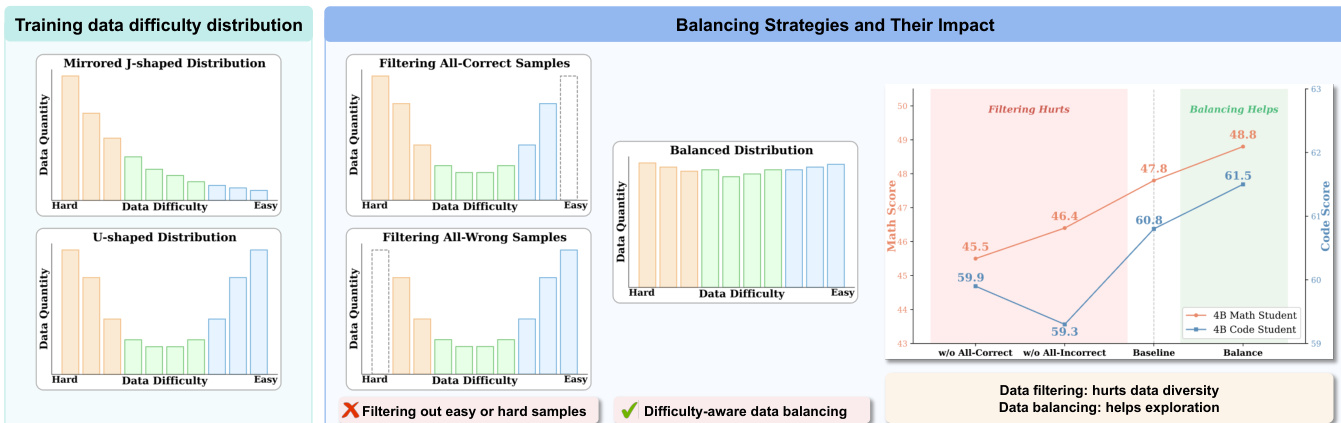
离线难度感知数据平衡 标准强化学习实践通常会过滤掉过易或过难的样本。然而,实证研究表明,小规模模型的训练数据经常表现出偏态分布,例如镜像 J 形或 U 形模式。激进地过滤这些样本会减少数据多样性并限制对信息丰富状态的探索。为了缓解这一问题,Uni-OPD 采用了一种难度感知平衡策略,选择性地过采样中等难度样本。这种方法将数据分布重塑为更均匀的形式,同时保留多样性和难度谱,使学生能够探索更广阔的解空间。
在线正确性感知数据平衡 即使经过离线平衡,训练期间探索不足也可能导致模型陷入局部最优,特别是当 rollout 组缺乏结果多样性时(例如,仅包含错误轨迹)。为了防止这种情况,Uni-OPD 明确强制每个 rollout 组内正确和错误轨迹的平衡组成。这确保学生持续接收有意义的对比信号以进行稳定的 on-policy 学习,避免所有样本共享相同结果的退化情况。
教师视角:结果引导的边界校准
从教师的角度来看,该框架引入了一种机制,通过强制与结果奖励的一致性来纠正不可靠的 token 级监督。
不可靠的教师监督 在标准 OPD 中,教师基于教师和学生策略之间的对数概率差距提供细粒度监督。理想情况下,该蒸馏信号应与整体轨迹正确性对齐。然而,在实践中,由于分布外 (OOD) 退化、对错误轨迹的高估或对正确轨迹的低估,这种对齐经常失败。这些问题导致违反顺序一致性,即错误轨迹获得的蒸馏回报高于正确轨迹。
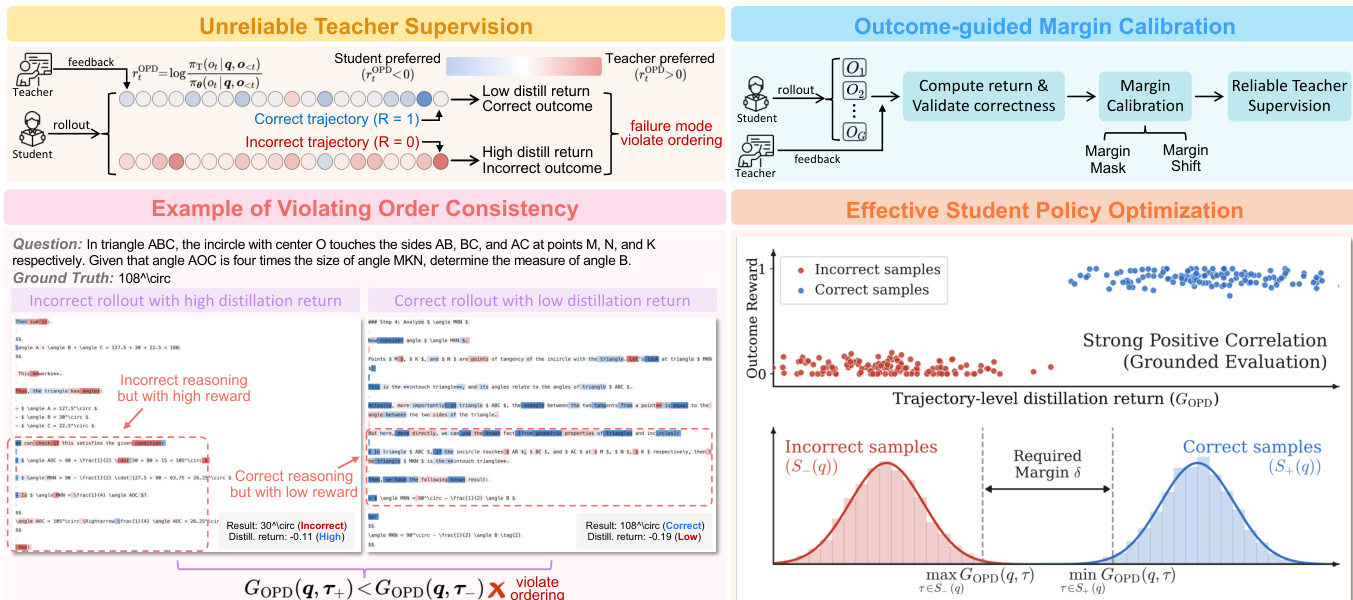
结果引导的边界校准 为了恢复可靠性,Uni-OPD 定义轨迹级蒸馏回报 GOPD(q,τ) 为轨迹 τ 上教师和学生之间的平均对数概率差距。该方法通过要求正确轨迹 (S+(q)) 的蒸馏回报高于错误轨迹 (S−(q)) 的蒸馏回报来强制顺序一致性。具体而言,它定义提示级边界 m(q) 为正确轨迹的最小回报与错误轨迹的最大回报之间的差值。
m(q)≜τ∈S+(q)minGOPD(q,τ)−τ∈S−(q)maxGOPD(q,τ)该框架要求该边界满足 m(q)≥δ,其中 δ>0 是安全边界。采用两种校准策略来强制执行此约束:
- 边界掩码: 该策略丢弃不满足边界条件的提示组,确保训练仅在可靠监督下进行。
- 边界偏移: 该策略通过应用最小加性修正来修复不可靠组。对于满足 m(q)<δ 的组,将偏移 λ(q)=δ−m(q) 应用于轨迹回报(例如,提升正确轨迹或抑制错误轨迹),以保证在不丢弃数据的情况下满足目标边界。
通过整合这些学生探索和教师校准模块,Uni-OPD 稳定了优化并提高了蒸馏过程在多样领域中的可靠性。
实验
跨文本和多模态领域的综合实验使用 Qwen3 模型评估 Uni-OPD,基准涵盖数学推理、代码生成和文档理解。该方法在单教师和多教师蒸馏、强到弱蒸馏以及跨模态设置中持续优于标准基线,通过有效合并专门能力到统一的学生策略中。消融研究验证了核心策略(如边界校准和数据平衡)增强了训练稳定性以及 token 级反馈与结果奖励之间的对齐。定性案例研究进一步证实,与标准蒸馏方法相比,Uni-OPD 生成更简洁准确的推理轨迹。
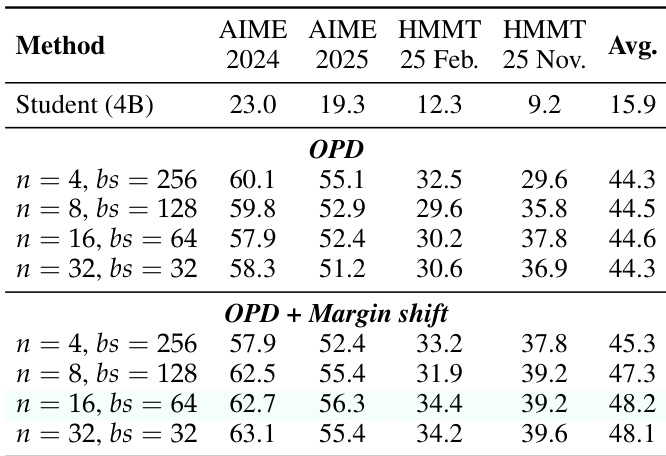
作者评估了 4B 学生模型在数学推理基准上使用 On-Policy Distillation 和包含边界偏移的变体。结果表明,添加边界偏移在各种批次和 rollout 设置中持续优于标准方法。此外,性能随超参数变化,特定配置产生最高平均分。基线学生模型的表现显著差于蒸馏方法。边界偏移技术持续提升性能优于标准 OPD。中间 rollout 设置结合特定批次大小实现了最佳结果。
作者使用 Qwen3 模型在数学推理和代码生成任务上评估 Uni-OPD。结果表明,Uni-OPD 在单教师和多教师蒸馏设置中持续优于标准 OPD 基线。该方法在两个领域均实现了最高平均分,证明了从专门教师到学生模型的有效能力迁移。Uni-OPD 在数学推理和代码生成基准上均优于 OPD 基线。在单教师蒸馏中,Uni-OPD 在所有评估的数学和代码任务中产生最高平均分。该方法在多教师蒸馏中保持其优势,有效合并来自多个专门教师的能力。
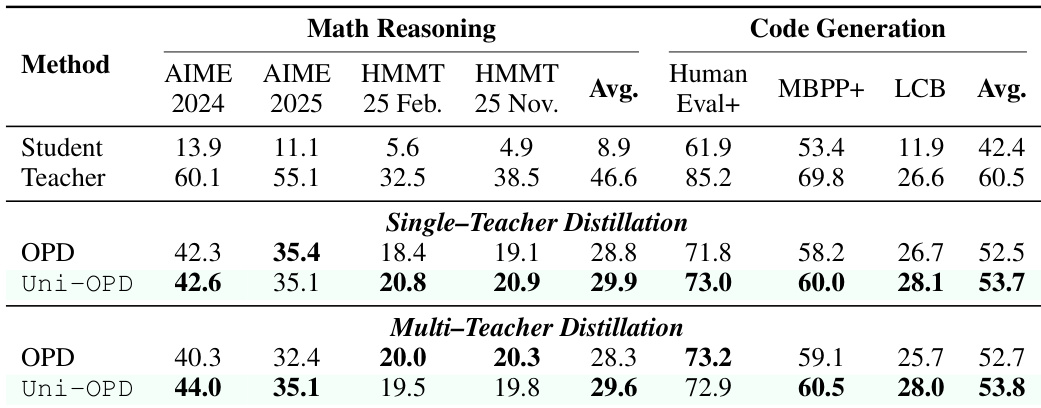
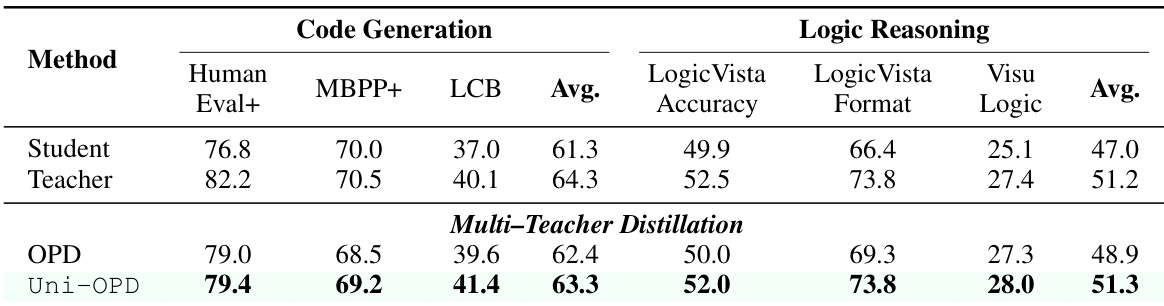
作者在涉及文本代码生成和多模态逻辑推理的多教师蒸馏场景中评估 Uni-OPD。结果表明,Uni-OPD 在两个领域的所有评估指标中持续优于标准 OPD 基线。所提出的方法实现了最高平均分,证明了异构教师能力的有效整合。Uni-OPD 在代码生成和逻辑推理基准上均优于标准 OPD 基线。该方法在多教师蒸馏设置中实现了最高平均分。在 Human Eval+ 和 LogicVista 准确率等特定任务中观察到一致改进。
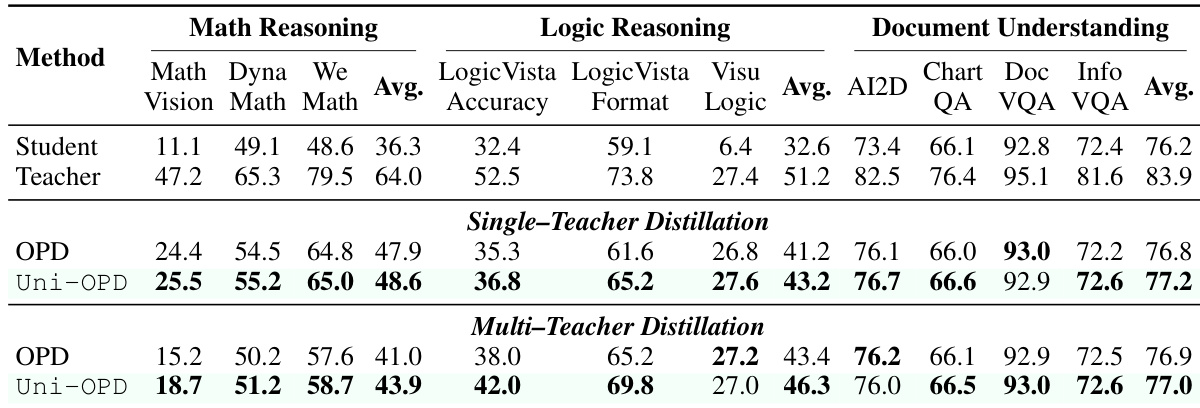
作者在单教师和多教师蒸馏设置下评估 Uni-OPD 与标准 OPD 基线针对多模态大型语言模型。结果表明,与基线方法相比,Uni-OPD 在数学推理、逻辑推理和文档理解任务中持续实现更优越的性能。在多教师场景中,所提出的方法成功将来自多个专门教师的能力整合到统一的学生模型中。Uni-OPD 在单教师蒸馏的所有评估领域中优于 OPD 基线。当同时从多个教师蒸馏时,该方法表现出对 OPD 的一致改进。Uni-OPD 有效地将来自不同领域特定教师的 distinct 能力合并到单一学生策略中。
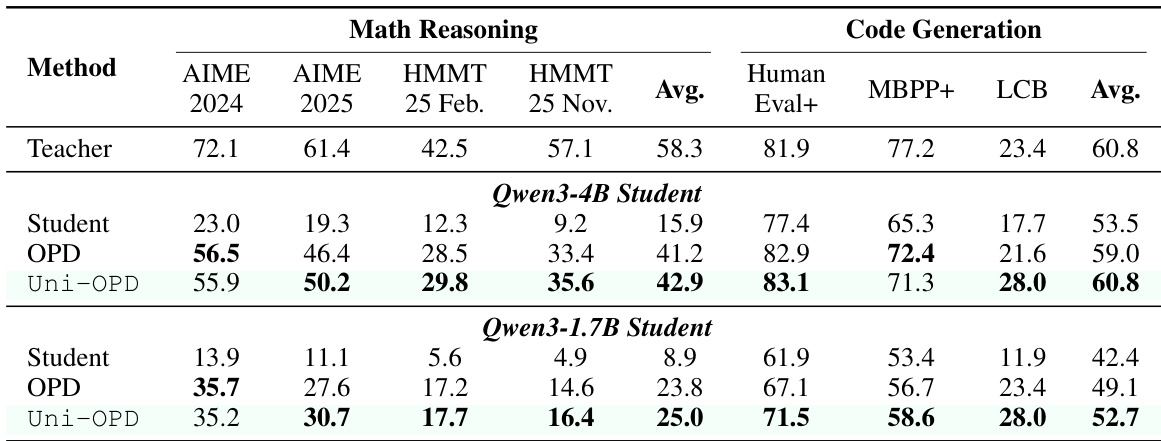
作者在强到弱蒸馏设置下评估 Uni-OPD,将能力从大教师转移到较小的学生模型。结果显示,对于不同的学生大小,Uni-OPD 在数学推理和代码生成任务中持续优于标准 OPD 基线。该方法有效地弥合了能力差距,使较小的学生能够吸收来自优秀教师的复杂推理行为。Uni-OPD 在 4B 和 1.7B 学生配置中持续优于标准 OPD 基线。该方法缩小了较小学生与较大教师模型之间的性能差距,特别是在代码生成方面。在包括 AIME、HMMT 和 HumanEval 在内的多样基准上观察到性能提升。
作者使用多样的学生和教师配置,在数学推理、代码生成和多模态任务上评估 Uni-OPD 和边界偏移变体与标准 On-Policy Distillation。结果表明,Uni-OPD 通过有效整合异构能力和弥合强到弱蒸馏中的能力差距,在单教师和多教师设置中持续优于基线。此外,边界偏移技术和优化的超参数配置在各种基准上产生了优于标准方法的显著性能提升。