Command Palette
Search for a command to run...
ARIS:通过对抗性多智能体协作实现自主研究
ARIS:通过对抗性多智能体协作实现自主研究
Ruofeng Yang Yongcan Li Shuai Li
摘要
本报告介绍了 ARIS(Auto-Research-in-sleep,睡眠中自主研究),这是一个用于自主研究的开源研究框架(harness),涵盖其架构、保障机制以及早期部署经验。基于大型语言模型(LLM)构建的 agent 系统的性能不仅取决于模型权重,还取决于围绕模型的研究框架,该框架决定了向模型存储、检索和呈现哪些信息。在长周期研究工作流程中,主要的失效模式并非显而易见的崩溃,而是一种看似合理却缺乏充分支撑的“成功”:长时间运行的 agent 可能会产生证据支持不完整、报告有误,或从执行者的叙述框架中无声继承的论点。因此,我们提出 ARIS 作为一种研究框架,其默认配置通过跨模型的对抗性协作来协调机器学习研究工作流程:一个执行器 agent 模型推动工作进展,同时推荐来自不同模型家族的审查者 agent 对中间产物进行审查并提出修改要求。ARIS 包含三个架构层次。执行层提供了 65 多种可重用的 Markdown 定义技能、通过 MCP 进行的模型集成、用于迭代复用先前发现的持久化研究维基,以及确定性图表生成功能。编排层协调五种端到端的工作流程,支持可调整的努力设置以及可配置的审查者 agent 模型路由。保障层包括一个三阶段流程,用于检查实验论点是否有证据支持:完整性验证、结果到论点的映射,以及论点审计(将手稿声明与论点账本及原始证据进行交叉核对);此外还包括五遍科学编辑流程、数学证明检查以及渲染 PDF 的视觉检查。一个原型的自我改进循环会记录研究痕迹,并提出框架改进建议,这些建议仅在获得审查者批准后才被采纳。
一句话总结
针对长周期工作流中可能出现“看似合理但缺乏依据的成功”风险,ARIS 是一个开源研究框架,通过跨模型对抗性协作来协调自主机器学习研究。该框架将推动进展的执行模型与来自不同模型家族的审查模型配对,后者负责对中间产物进行批判性评估。同时,其执行层通过持久化研究维基、基于 MCP 的模型集成、确定性图表生成以及超过 65 项 Markdown 定义的技能,支持迭代式发现。
核心贡献
- ARIS 是一个开源研究框架,通过包含超过 65 项可复用 Markdown 定义技能、基于 MCP 的模型集成、持久化研究维基和确定性图表生成的三层架构,协调自主机器学习工作流。
- 该框架实现了一种跨模型对抗性协作机制:执行模型负责推动进展,而来自不同模型家族的审查模型负责对中间产物进行批判性评估并要求修改。该机制有效打破了自我审查的盲区,且无需承担大型多 Agent 委员会的协调开销。
- 该系统集成了明确的质量保障栈,用于完整性审计与跨平台可移植性,支持可复现的端到端研究工作流,涵盖跨多个宿主环境的概念生成、实验验证与论文撰写。
引言
自动化端到端机器学习研究流程对加速科学发现具有重大潜力,但长周期自主任务仍极易受到幻觉、关联误差及结果误报的影响。以往的自主研究 Agent 通常依赖同模型自我优化与强耦合工作流,无法识别共有的归纳偏差,缺乏模块化断点续跑能力,且对实验完整性的系统级验证极为有限。为弥补这些不足,本文提出 ARIS 框架。该框架将单 Agent 执行视为本质上不可靠,并将研究过程分解为模块化、状态保持的各个阶段。研究团队采用跨模型家族的对抗性执行与审查配对机制,在关键里程碑设置明确的质量保障检查,确保每一项研究产物在推进至下一阶段前,均由不同的模型家族进行独立验证。
数据集
- 数据集构成与来源: 研究团队整理了一份技能清单,收录了当前版本中框架的核心技能,详见表 5。
- 子集详情: 提供的摘录未定义独立的子集,因此未记录具体规模、来源或筛选标准。
- 使用与训练配置: 研究团队引用该清单以建立基线技能框架。文本未提及训练集划分、混合比例或数据融合策略。
- 处理与元数据: 现有内容未描述任何裁剪方法、元数据生成步骤或额外的预处理流水线。
方法
ARIS 框架围绕执行、编排与保障三个核心架构层构建,共同应对长周期自主机器学习研究面临的挑战。执行层通过超过 65 项可复用技能提供模块化基础,每项技能均以纯文本 Markdown 文件(SKILL.md)定义,明确指定输入、输出、操作步骤与质量门禁。这些技能通过可版本化的产物契约进行协调,支持基于检查点的恢复与审计。编排层管理五项端到端工作流(概念发现、实验桥接、自动审查循环、论文撰写与反驳),通过上述契约串联,并划分为四个研究阶段:发现、实验、手稿与投稿后。该层支持可调节的投入设置与可配置的审查模型路由,使用户能够在保持核心审查不变量的同时扩展研究的深度与广度。保障层实施多阶段流程以检测并缓解看似合理但缺乏依据的成功,包括证据完整性验证、结果到声明的映射,以及基于原始证据与声明账本的声明审计。该层还包含五轮科学编辑流水线、数学证明检查以及渲染 PDF 的视觉审查。原型元优化循环会记录研究轨迹,并提出框架改进建议,这些建议仅在审查模型批准后方可采纳,从而实现系统自身的迭代优化。整体架构旨在默认强制执行独立保障,利用执行模型与来自不同模型家族的审查模型之间的跨模型对抗性协作,从而降低共有的归纳偏差并增强批判性评估。



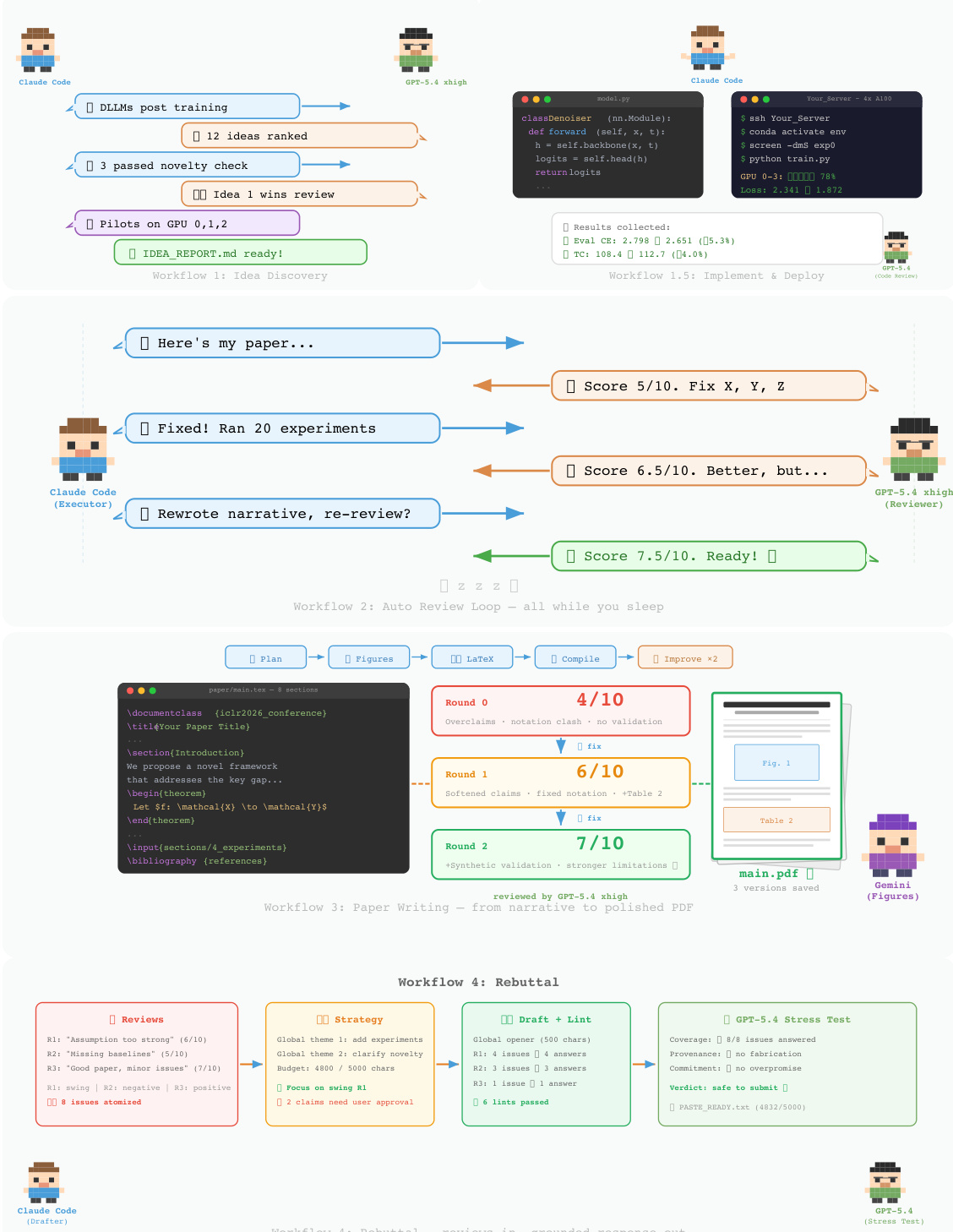
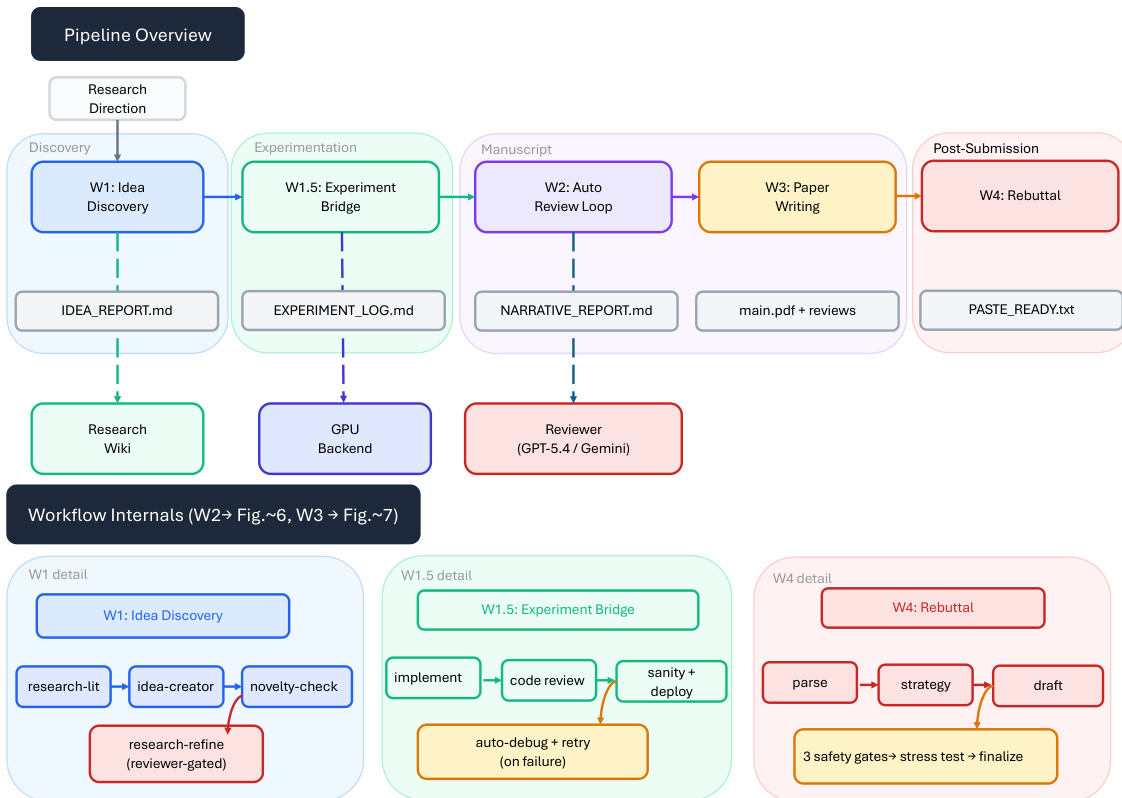
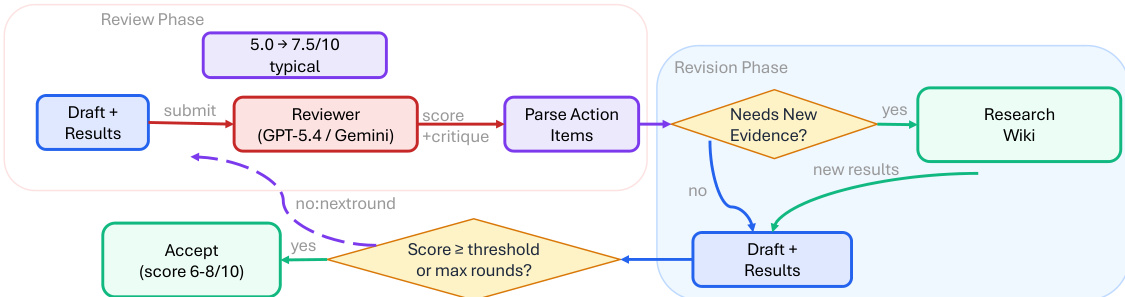
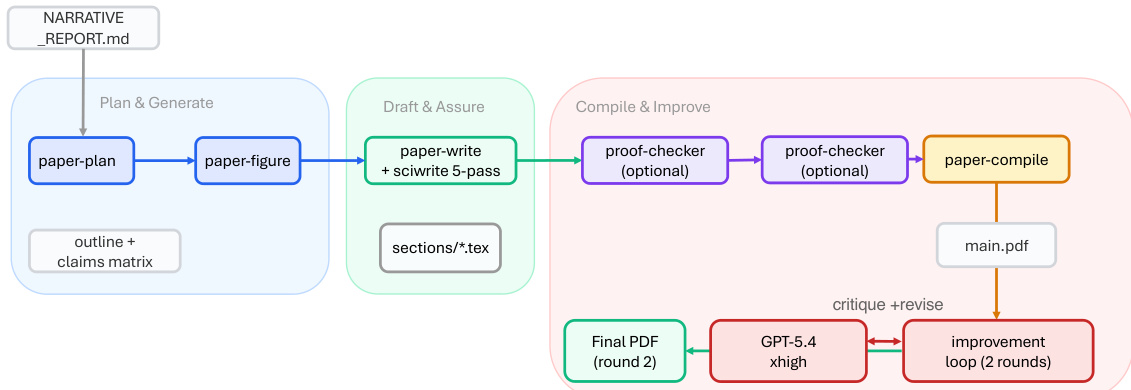
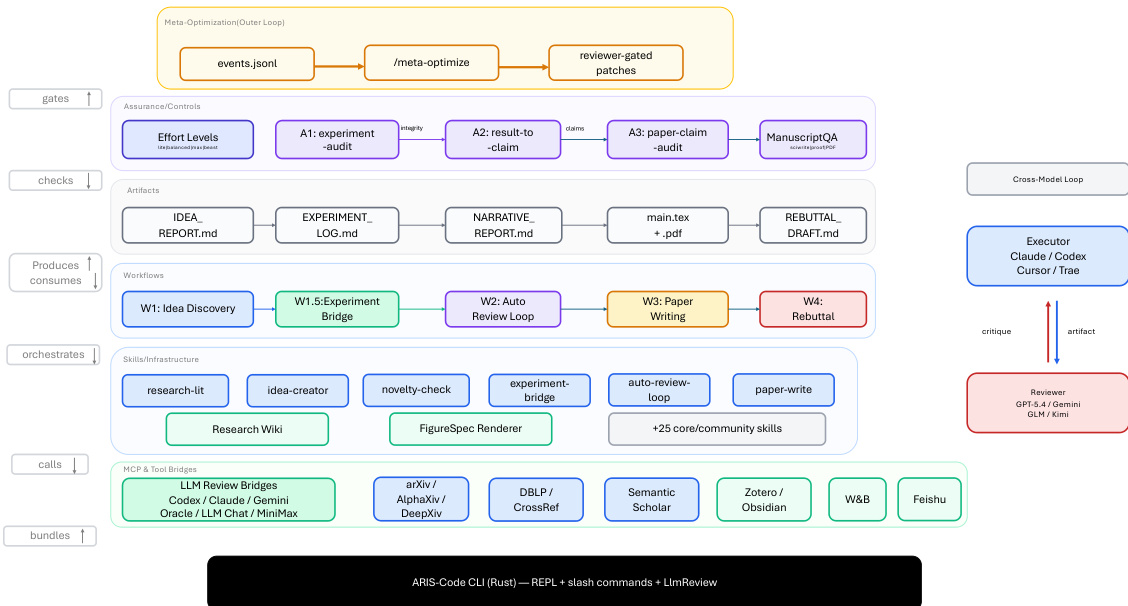
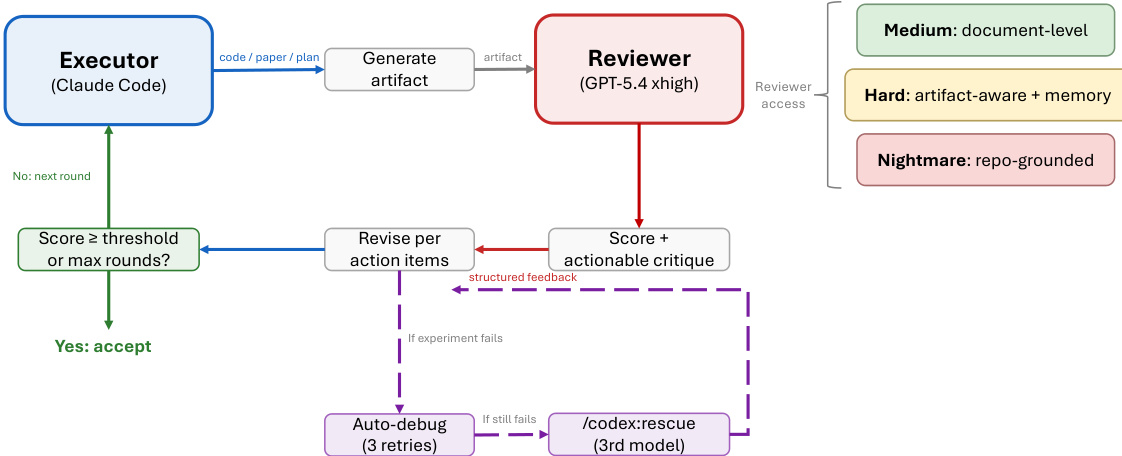
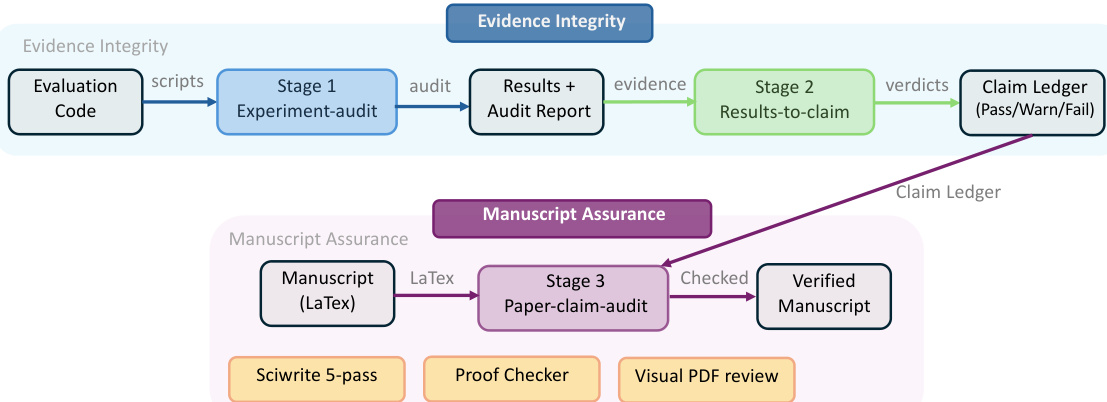
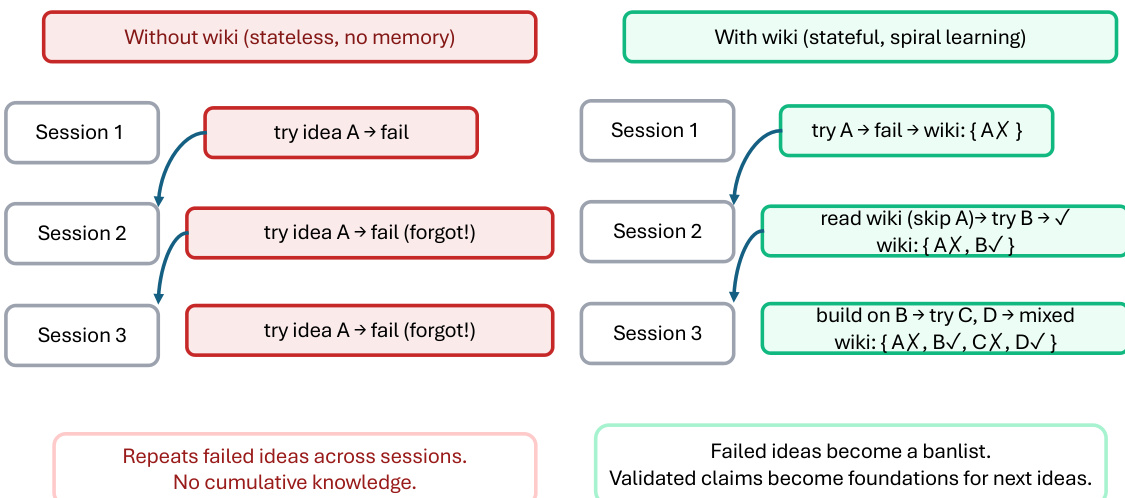

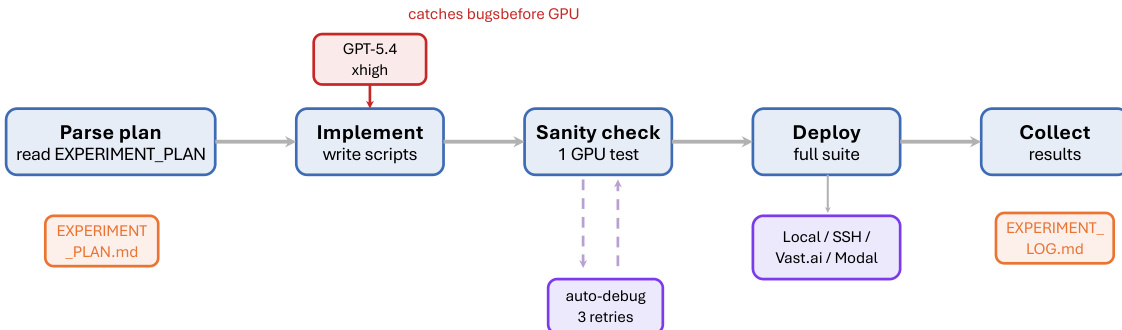
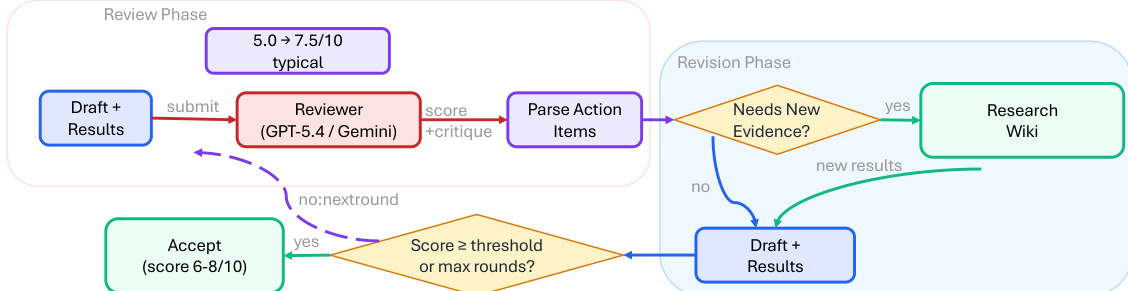
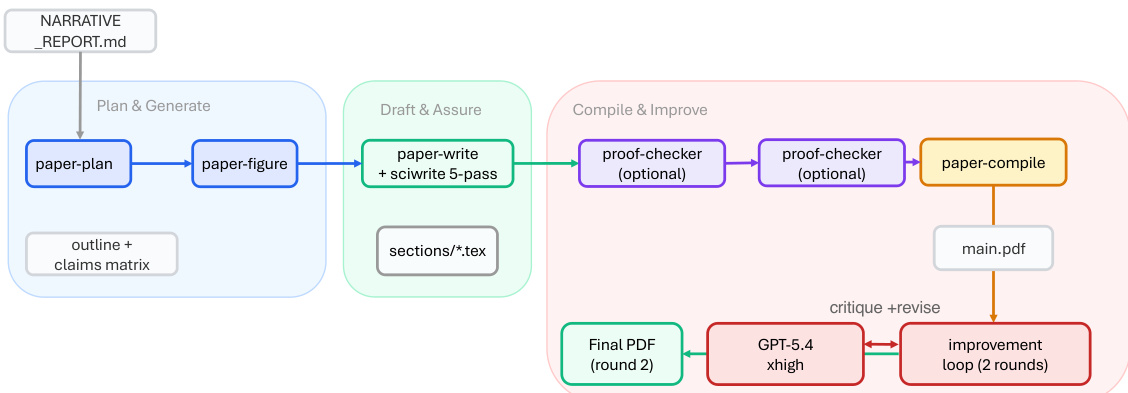

实验
评估工作依赖于观测部署跟踪与单次夜间运行测试,旨在真实场景下检验 ARIS 的性能。这些实验验证了系统在实际中自主剔除缺乏依据的声明、并通过自动化审查循环迭代优化手稿的能力,同时展示了在多个技术领域中的显著生态扩展潜力。由于报告的结果仍属观测性质,其主要确认了操作可行性,而非为特定的审查架构或模型配置确立因果优势。未来需建立受控基准测试协议,以将算法设计的影响与研究者经验、任务难度等外部变量隔离开来。
研究团队展示了不同系统(包括其自身系统)在多项能力上的对比,涵盖跨家族审查、对抗性审查、可组合性、端到端研究工作流、保障栈及跨平台可移植性。ARIS 展现出全面的功能集,尤其在可组合性与端到端研究工作流方面表现突出,并支持跨平台可移植性。其他系统均未支持跨平台可移植性与端到端研究工作流。ARIS 包含可组合技能与保障栈,而大多数对比系统缺乏这些特性。ARIS 实施了默认的跨家族策略,而其他系统要么缺乏此能力,要么采用部分覆盖或无策略。
评估从多个能力维度将 ARIS 与现有系统进行对比,验证了其在跨家族与对抗性审查、可组合性、端到端研究工作流、保障栈及跨平台可移植性方面的表现。ARIS 展现出更优的集成能力,其独特之处在于完整支持端到端工作流与跨平台部署,同时引入了竞品工具所缺乏的可组合技能与专用保障栈。此外,该框架确立了全面的默认跨家族策略,有效弥补了替代方案中存在的覆盖不全或缺失问题。