Command Palette
Search for a command to run...
幻觉削弱信任;元认知是前进之路
幻觉削弱信任;元认知是前进之路
Gal Yona Mor Geva Yossi Matias
摘要
尽管在事实可靠性方面取得了显著进展,但错误——通常被称为“幻觉”(hallucinations)——仍然是生成式人工智能面临的主要担忧。随着大语言模型(LLMs)被期望在更复杂或更具细微差别的场景中发挥更大作用,这一问题尤为突出。然而,即使在最简单的设置下——即具有明确地面真值(ground truth)的事实性问题回答中——前沿模型在不借助外部工具的情况下仍会产生幻觉。我们认为,该领域内大部分事实准确性的提升主要来自于扩展模型的知识边界(编码更多的事实),而非提高模型对该边界的感知能力(即区分已知与未知)。我们推测,后者本质上极为困难:模型可能缺乏完美的判别能力,无法将真相与错误完全分离,从而在消除幻觉与保持实用性之间形成不可避免的权衡。通过不同的框架来看,这种权衡是可以解决的。如果我们将幻觉理解为“自信的谬误”——即没有适当限定条件而提供的错误信息——那么在“回答或拒绝回答”(answer-or-abstain)的两极分化之外,出现了一条新的路径:表达不确定性。我们提出了“忠实的不确定性”(faithful uncertainty)这一概念,即语言上的不确定性应与内在的不确定性相一致。这是元认知(metacognition)的一个方面——即意识到自身的不确定性并据此采取行动的能力。对于直接交互而言,基于不确定性采取行动意味着诚实地传达这种不确定性;对于 agentic systems(智能体系统)而言,它成为控制何时进行搜索以及信任何者的控制层。因此,元认知对于使大语言模型既值得信赖又具备能力至关重要;我们在结论中强调了实现这一目标所面临的未决问题。
一句话总结
作者提出了一种元认知框架,通过将语言不确定性对齐到内在不确定性,从而缓解大语言模型的幻觉问题。该框架将重点从知识扩展转向忠实的不确定性表达,旨在提升直接对话界面与自主 Agent 系统中的可信度与实用性。
核心贡献
- 本研究将忠实的不确定性定义为一项目标,旨在将语言中的怀疑表达与模型的内在置信状态对齐,确保在模型能力边界处准确传达其局限性。
- 该方法通过超越“回答或拒绝”的二元对立来重构幻觉缓解策略,将校准后的不确定性定位为 agent 系统中控制工具选择与验证的层级。
- 研究为 AI Agent 引入了基于过程的评估框架,将元认知可靠性置于端到端正确性之上,并纳入特定验证机制,以惩罚低效搜索与盲目信任来源的行为。
引言
大语言模型正越来越多地被部署于高风险应用中,其事实可靠性直接影响用户信任与安全,然而模型仍会持续生成被称为幻觉的自信错误。以往的缓解策略主要侧重于扩展内部知识或提升整体置信度校准,但这些方法之所以失效,是因为模型在实例层面缺乏可靠区分正确与错误答案的判别能力。这一局限迫使模型在事实准确性与实用价值之间面临严格权衡,因为消除错误通常需要激进的拒绝回答机制,而这会抑制有效信息的输出。作者将幻觉重新定义为自信错误,并提出将忠实的不确定性作为元认知解决方案。通过将语言上的谨慎表达与模型的内在置信状态对齐,该方法使系统能够在保留有用信息的同时诚实地传达不确定性,最终为直接交互与 Agent 工具调用建立可靠的控制层。
数据集

- 数据集构成与来源: 作者构建了一个包含 25,000 个样本的合成数据集,旨在复现 Nakkiran 等人(2025)记录的实证置信度分布特征。
- 子集详情与生成规则: 该数据集保持固定的 25% 基础幻觉率。置信度分数采用 Beta 分布生成,以模拟重叠的 LLM 行为,其中正确答案从 Beta(1.8, 1.0) 中采样,错误答案从 Beta(1.0, 1.3) 中采样。
- 处理与校准: 为确保观察到的权衡仅源于分布重叠而非概率校准偏差,团队对原始分数应用了等渗回归。该步骤实现了近乎完美的校准(smECE ≈ 0.014),并将判别能力隔离为唯一限制因素。
- 使用与评估策略: 作者未将数据用于模型训练,而是利用其分析效用误差曲线。通过在校准后的分数上扫描拒绝阈值,计算每个决策边界下正确回答与错误回答样本的比例。
方法
作者提出了一种以忠实的不确定性为核心的框架,该框架将大语言模型(LLM)的目标从纯粹的事实准确性,转向模型内在置信度与其在响应中表达的不确定性之间的对齐。该方法直接应对效用与事实性之间的权衡问题,即模型往往被迫在放弃不确定主张(从而牺牲有用信息)与生成自信但可能错误的答案之间做出选择。忠实的不确定性使模型能够通过生成响应并恰当地对不确定主张进行语言修饰,从而在保留有用信息的同时维持信任,且不牺牲信息量。核心理念在于,模型不仅需要具备知识储备,还应可靠地传达自身的不确定性。其目标并非彻底消除幻觉,而是确保输出中的任何不确定性都能准确反映模型的内在置信度。
参见框架示意图 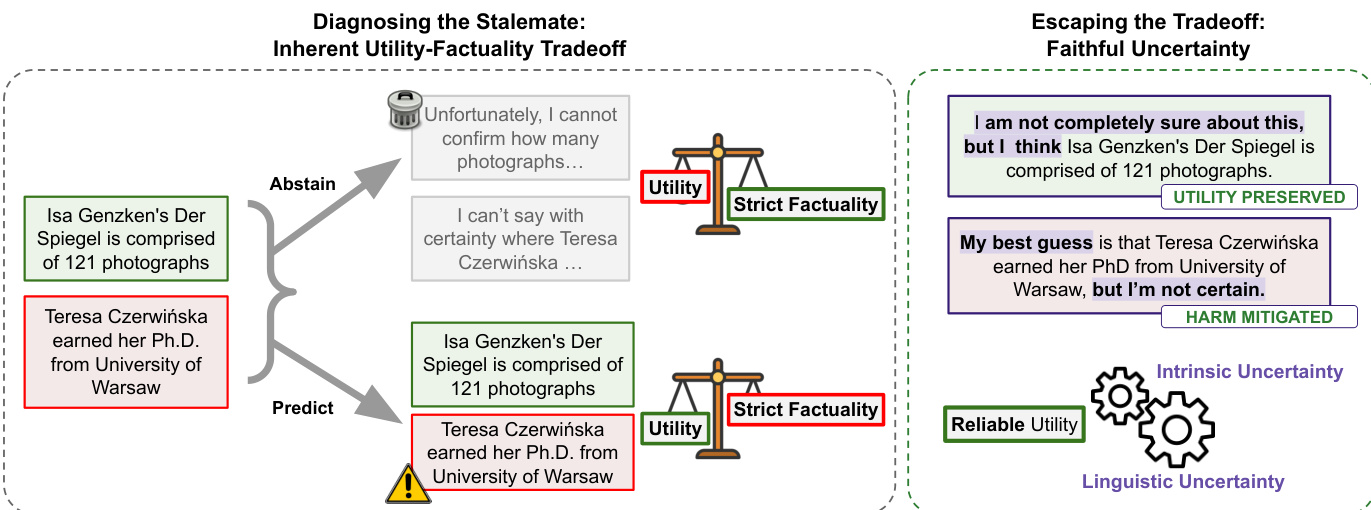 。该图展示了在严格事实性约束下效用与事实性之间的固有权衡,模型必须在放弃不确定主张或直接预测之间选择,这会导致降低信任的潜在错误。相比之下,忠实的不确定性范式使模型能够通过语言形式表达不确定性,同时仍提供答案,从而借助恰当的语言修饰减轻潜在危害。该框架借鉴了人类专家的沟通方式,即陈述的置信度会通过语言明确体现,从而在不牺牲有用信息提供的前提下增强信任。
。该图展示了在严格事实性约束下效用与事实性之间的固有权衡,模型必须在放弃不确定主张或直接预测之间选择,这会导致降低信任的潜在错误。相比之下,忠实的不确定性范式使模型能够通过语言形式表达不确定性,同时仍提供答案,从而借助恰当的语言修饰减轻潜在危害。该框架借鉴了人类专家的沟通方式,即陈述的置信度会通过语言明确体现,从而在不牺牲有用信息提供的前提下增强信任。
忠实的不确定性在实际应用中的操作化依赖于两项关键指标:内在不确定性与语言不确定性。内在不确定性定义为模型对特定主张的内部置信度,通过重复采样下生成冲突答案的概率来量化。对于查询 Q 与主张 A,内在置信度 confM(A) 的计算公式为 1−k1∑i=1k1[A contradicts Ai],其中 A1,…,Ak 为模型生成的主张。语言不确定性则通过果断性来衡量,即主张在输出中以自信方式传达还是进行了语言修饰的程度。该指标表示为 dec(A;R,Q)=Pr[A is True∣R,Q],并使用 LLM-as-a-judge 进行估算。忠实的不确定性随后被定义为这两项指标之间的对齐程度,其忠实度分数计算为 1−∣A(R)∣1∑A∈A(R)∣dec(A;R,Q)−confM(A)∣。分数为 1 表示完全对齐,较低的值则表明存在系统性的过度修饰或修饰不足。
如图下所示: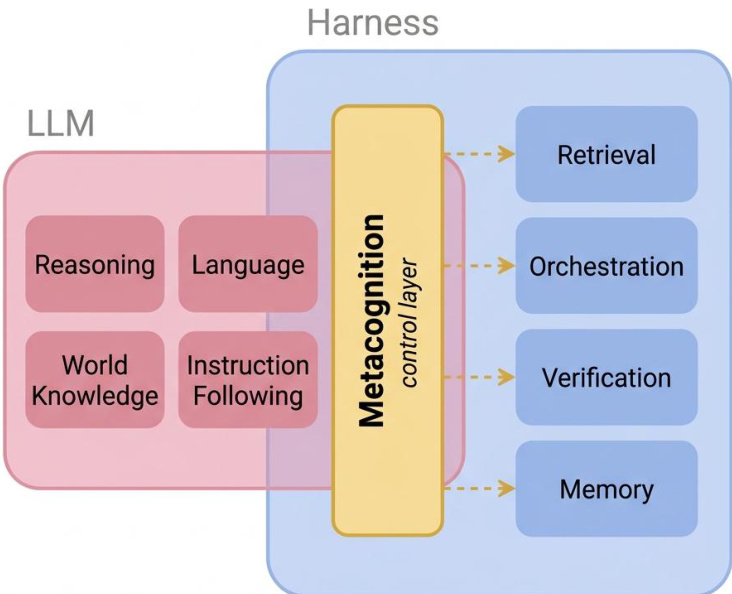 ,所提出的架构集成了一个作为 LLM 控制枢纽的元认知控制层。该层通过访问推理、语言、世界知识与指令遵循等内部状态,对模型行为进行监督与调节。它将输出路由至检索、编排、验证与记忆等外部组件,使模型能够动态评估并表达不确定性。这种模块化设计使系统能够将事实推理与元认知评估分离,从而便于置信度信号的提取与利用。
,所提出的架构集成了一个作为 LLM 控制枢纽的元认知控制层。该层通过访问推理、语言、世界知识与指令遵循等内部状态,对模型行为进行监督与调节。它将输出路由至检索、编排、验证与记忆等外部组件,使模型能够动态评估并表达不确定性。这种模块化设计使系统能够将事实推理与元认知评估分离,从而便于置信度信号的提取与利用。
作者认为,忠实的不确定性是一项可行且实用的目标,因为它规避了将有限参数映射至无限外部世界的局限性。相反,该方法将问题视为闭环系统,其中忠实度的真实标签是内部的,具体而言即模型自身的置信度信号。这些信号在本质上具备可计算性,可通过架构改进、数据调整以及更优的训练策略加以利用。该框架进一步佐证了内在不确定性信号已经存在且可获取的观点,近期机制可解释性研究以及将这些信号应用于强化学习以提升多样性与推理能力的工作均提供了证据。
参见框架示意图 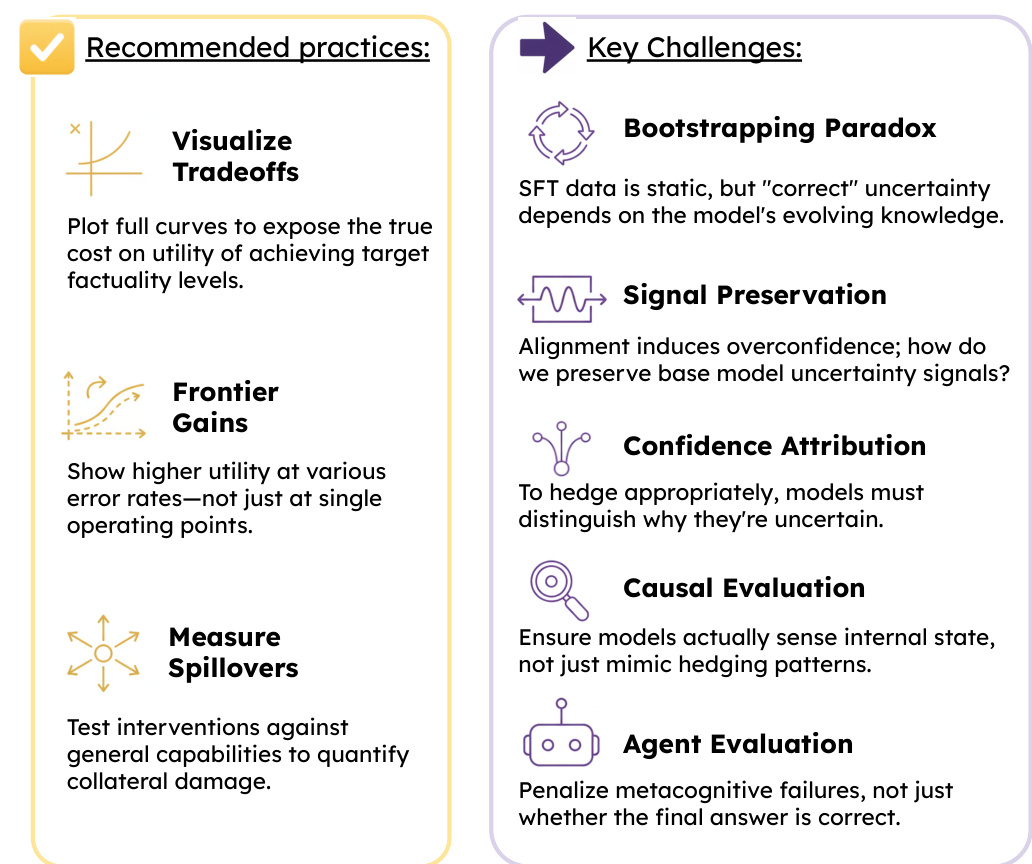 。该图概述了实施忠实的不确定性时的推荐实践与核心挑战。推荐实践包括通过完整曲线可视化权衡关系以揭示事实性的真实成本,展示不同错误率下的前沿收益,以及测量溢出效应以测试干预措施对通用能力的影响。核心挑战包括自举悖论(SFT 数据是静态的,但不确定性依赖于不断演进的知识)、信号保持(对齐过程可能诱发过度自信)、置信度归因(要求模型区分自身为何不确定)、因果评估(确保模型感知内部状态而非模仿语言修饰模式),以及 Agent 评估(对元认知失败进行惩罚,而非仅针对错误答案)。这些考量突显了将内在置信度与语言表达对齐的复杂性,以及开发稳健评估方法的必要性。
。该图概述了实施忠实的不确定性时的推荐实践与核心挑战。推荐实践包括通过完整曲线可视化权衡关系以揭示事实性的真实成本,展示不同错误率下的前沿收益,以及测量溢出效应以测试干预措施对通用能力的影响。核心挑战包括自举悖论(SFT 数据是静态的,但不确定性依赖于不断演进的知识)、信号保持(对齐过程可能诱发过度自信)、置信度归因(要求模型区分自身为何不确定)、因果评估(确保模型感知内部状态而非模仿语言修饰模式),以及 Agent 评估(对元认知失败进行惩罚,而非仅针对错误答案)。这些考量突显了将内在置信度与语言表达对齐的复杂性,以及开发稳健评估方法的必要性。
实验
在 SimpleQA Verified 数据集上的评估揭示了一种根本性的分化现象,模型必须在高幻觉率下的广泛覆盖与为确保事实性而降低效用之间做出选择。该分析验证了固有的能力差距,表明当前语言模型无法可靠地区分自身错误与准确知识,从而导致理想性能区域处于空白状态。因此,实验得出结论:标准指标掩盖了幻觉缓解过程中不可避免的效用损耗,亟需建立能够追踪完整效用误差权衡、验证真实能力改进,并评估对模型通用帮助性产生附带影响的评估框架。