Command Palette
Search for a command to run...
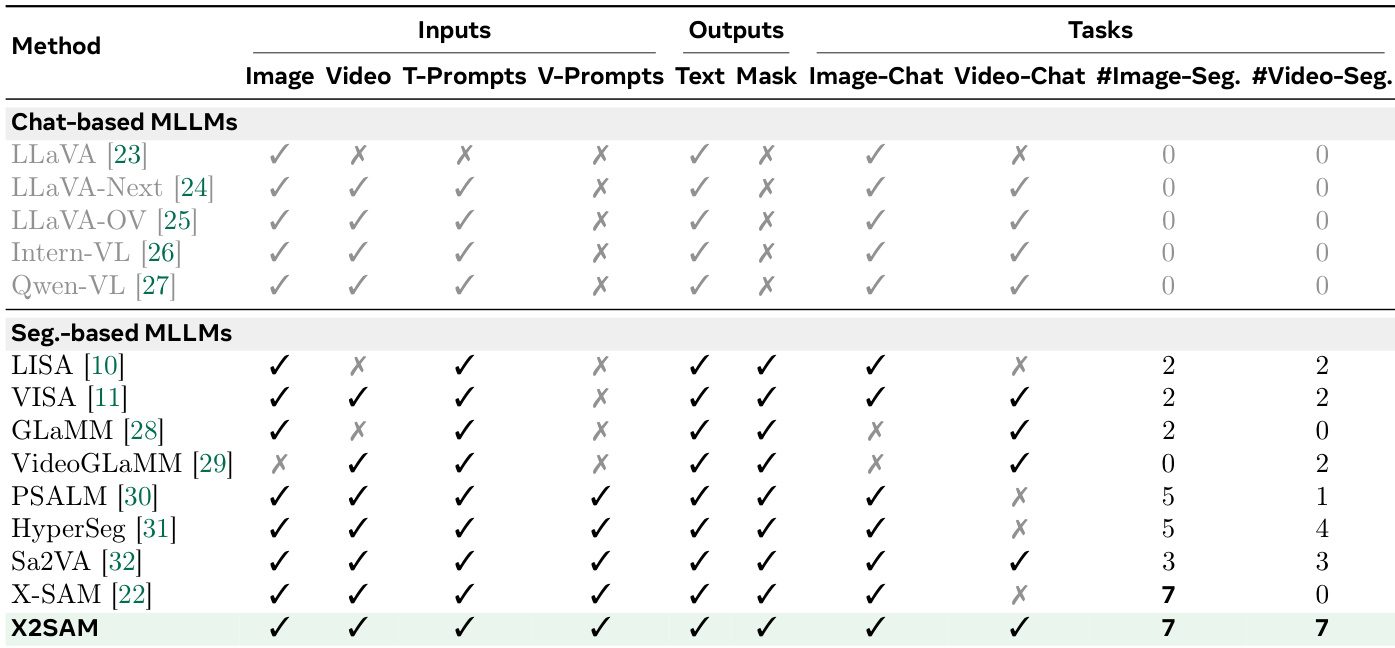
X2SAM:图像与视频中的任意分割
X2SAM:图像与视频中的任意分割
Hao Wang Limeng Qiao Chi Zhang Lin Ma Guanglu Wan Xiangyuan Lan Xiaodan Liang
摘要
多模态大语言模型(Multimodal Large Language Models, MLLMs)在图像级的视觉理解和推理方面表现强劲,但在图像和视频的像素级感知方面仍存在局限。以 SAM 系列为代表的基础分割模型能够生成高质量的掩码(masks),但它们依赖于底层视觉提示,无法原生解析复杂的对话式指令。现有的分割型 MLLMs 虽在一定程度上弥补了这一差距,但通常仅针对图像或视频中的一种模态进行专门优化,且极少能在同一界面中同时支持文本和视觉提示。我们提出了 X2SAM,这是一种统一的分割型 MLLM,将“任意目标分割”(any-segmentation)能力从图像扩展至视频。给定对话式指令和视觉提示,X2SAM 将大语言模型(LLM)与掩码记忆模块(Mask Memory module)相结合,该模块存储受引导的视觉特征,以实现时间上一致的视频掩码生成。同样的架构支持跨图像和视频输入的通用、开放词汇、指代表达、推理、接地对话生成、交互式以及视觉接地分割任务。此外,我们还引入了视频视觉接地(Video Visual Grounded, V-VGD)分割基准测试,用于评估模型是否能够通过交互式视觉提示对视频中的物体轨迹进行分割。通过在异构图像和视频数据集上采用统一的联合训练策略,X2SAM 在视频分割任务上展现了强大的性能,在图像分割基准测试中保持竞争力,并保留了通用的图像和视频对话能力。
一句话总结
作者提出 X2SAM,这是一种统一的多模态大语言模型,通过将大语言模型与 Mask Memory 模块耦合,将任何分割(any-segmentation)能力从图像扩展至视频。该模块用于存储引导式视觉特征,以实现时间上一致的掩码生成,原生支持跨多样化分割任务的文本与视觉提示,在视频分割上表现强劲并在图像分割上具有竞争力,同时通过异构数据集的联合训练保留对话能力,并引入视频视觉定位(V-VGD)基准以评估基于交互式提示的跟踪能力。
核心贡献
- 提出 X2SAM,这是一种面向分割的多模态大语言模型,将像素级任何分割能力从静态图像扩展至动态视频序列。该架构将大语言模型与 Mask Memory 模块耦合,存储引导式视觉特征,从而能够根据对话指令和视觉提示生成时间上一致的掩码。
- 将开放词汇、指代、推理和交互式定位等多样化分割任务整合到单一指令遵循框架中,原生处理文本和视觉输入。该统一公式联合优化语义定位与基于记忆的时序传播,以克服以往仅图像或仅视频模型的结构碎片化问题。
- 引入视频视觉定位(V-VGD)基准以评估基于交互式视觉提示的视频对象定位,并配合针对异构图像和视频数据集的自适应联合训练策略。该训练协议实现了具有竞争力的图像分割性能、增强的视频分割精度,并保留了通用的多模态对话能力。
引言
多模态大语言模型已革新了高层视觉理解,但在静态图像和动态视频中生成精确的像素级掩码,对于需要细粒度时空分析的应用仍然至关重要。以往的分割系统存在结构碎片化问题:专注于图像的模型缺乏时序能力,而视频中心的方法难以保持掩码一致性或原生处理结合的文本与视觉提示。为弥合这一差距,作者利用统一架构,将大语言模型与新型 Mask Memory 模块耦合,以存储引导式视觉特征并强制执行时序连贯的掩码生成。该设计使单一对话界面能够使用交错的文本和视觉提示,在图像和视频输入上执行多样化分割任务;同时,在异构数据集上的联合训练策略在跨模态表现上达到具有竞争力的水平,且未牺牲通用推理能力。
数据集
- 数据集构成与来源: 作者采用两阶段训练流程,首先使用仅掩码的 SA-1B 数据集初始化掩码解码器。统一的联合训练阶段随后整合涵盖图像和视频模态的十四个分割任务数据,以及专用的图像和视频对话语料库。所有其他基准数据集严格保留用于验证和零样本评估。
- 各子集关键细节: 图像任务遵循 X-SAM 混合微调设置,使用 COCO 进行通用分割,RefCOCO 变体用于指代任务,ReasonSeg 用于推理,基于 GLaMM 的集合用于定位对话,COCO-VGD 用于视觉定位,LLaVA-1.5 用于图像对话。视频分割任务从 VIPSeg、VSPW 和 YT-VIS19 中获取通用分割数据;YT-RefVOS21 和 DAVIS17-RefVOS 用于指代;ReVOS 用于推理;基于 VideoGLaMM 的数据集用于定位对话;YT-VOS19 用于对象分割。作者还引入了两个新构建的视频视觉定位分割数据集。YT19-VGD 直接基于 YT-VIS19 的实例标注构建,强调以实例为中心的对象。VIPSeg-VGD 过滤全景标注以仅保留跨帧具有稳定实例身份的事物类别,提供更密集的多对象上下文。视频对话训练依赖 VideoInstruct100K 语料库。
- 训练使用与数据混合: 作者分两个独立阶段训练模型。第一阶段冻结掩码编码器,仅将掩码解码器作为二分类任务优化一个 epoch。第二阶段解冻掩码编码器,并通过多任务学习联合训练投影器、大语言模型、掩码解码器和 Mask Memory。为平衡多样化数据源,作者应用数据集平衡重采样,温度参数设为 0.1。同时实施感知模态的批处理策略,为视频数据保持 32 的全局批大小,对图像数据应用四倍乘数,实现 128 的有效全局批大小。
- 处理与元数据构建: 帧采样针对每种任务类型定制。大多数视频分割任务使用连续帧采样,步长为 1,序列长度为 8 帧。视频定位对话任务采用全局采样策略,每个片段提取 16 帧,而视频对话输入扩展至 64 帧以支持长程时序理解。对于新构建的 V-VGD 数据集,每个目标对象与四个自动生成的视觉提示(点、笔划、框和掩码)配对,这些提示源自第一个可见的标注帧。监督目标由整个片段的完整时空掩码序列组成。训练期间,系统随机采样每个实例的一个提示类型以增强鲁棒性,而评估主要关注点和框条件。大语言模型使用秩为 128、缩放因子为 256 的 LoRA 进行微调,Mask Memory 配置为存储 8 个槽位。
方法
作者提出 X2SAM,一种面向分割的多模态大语言模型(MLLM),旨在将分割能力从静态图像扩展至动态视频序列。整体框架作为双分支视觉提取系统运行,处理全局和细粒度视觉特征,并将其与语言指令整合以生成分割掩码和上下文语言响应。系统架构概述请参考框架图。
输入处理流程始于视觉输入 Xv∈RT×H×W×C,其中图像对应 T=1,视频对应 T>1,以及文本指令 Xq。视觉输入通过两条互补路径处理。视觉编码器 fv(采用自 Qwen3-VL-4B)通过添加时间戳、将输入划分为空间块并投影至潜在嵌入,提取全局视觉表示 Zv。同时,掩码编码器 gm(源自 SAM2)逐帧处理输入以捕获适合密集预测的细粒度视觉特征 Zm。当需要特定区域信息时,区域采样器 gr 使用点采样和自适应池化从 Zm 中提取局部视觉提示嵌入,生成区域级特征 Hr。文本指令按任务特定模板格式化、分词并嵌入为文本潜在表示 Hq。随后,投影的全局特征 Hv、区域特征 Hr 和文本嵌入 Hq 被输入大语言模型(LLM)fϕ。
LLM 自回归生成语言响应 Yq,并为 <SEG> token 生成专用潜在嵌入,该嵌入充当语言理解与掩码预测之间的语义桥梁。此嵌入由 MLLM 投影器转换为提示 token 嵌入 Zp。为保持视频帧间的时序连贯性,模型采用 Mask Memory 模块。该模块作为时序缓存,存储来自先前帧的引导式视觉特征。Mask Memory 模块的数据流详见下图。
如图所示,Mask Memory 模块包含四个组件:Memory Attention、Mask Decoder、Memory Encoder 和 Memory Bank。Memory Attention 关注来自先前帧的引导式视觉特征,为当前帧生成时序精炼的视觉特征 Zw。Mask Decoder 随后通过整合 Zp、可学习掩码查询 Qm 和 Zw 生成分割掩码 Ym。掩码预测后,Memory Encoder 将下采样视觉特征与当前帧掩码逻辑值编码为引导式视觉特征 Zmt。该特征存储于 Memory Bank 中,采用先进先出(FIFO)策略更新缓存。此固定大小内存设计在确保视频分割时序一致性的同时限制了计算成本。
Mask Decoder 经过重新设计以克服并行掩码生成的局限性。受 X-SAM 启发,它整合了结构化注意力模块:Query-to-Image Attention 和 Token-to-Image Attention。这些模块使 LLM 的语义 token 嵌入 Zp 能够直接与空间特征交互,使解码器能够生成空间精确且与语言指令语义对齐的掩码。Token-to-Image Attention 参数初始化为零,以确保在训练初期 token 级条件信息的平滑稳定整合。
训练 X2SAM 涉及两阶段流程。首先执行类别无关分割器训练阶段,为掩码解码器提供稳定初始化。在此阶段,掩码编码器保持冻结,仅使用组合掩码损失 Lmask(结合二元交叉熵与 dice 损失)优化掩码解码器。这促使解码器学习类别无关的形状与边界先验。
随后在异构图像和视频数据集上执行统一联合训练阶段。为处理不同的时序长度和内存占用,采用维度转换流水线。视觉输入张量被转置并拆分为帧级张量,由掩码编码器处理。时序依赖通过掩码记忆模块在顺序掩码解码期间引入。为优化效率,采用感知模态的批处理:为管理内存,视频的基础设备批大小设为 B=1,而纯图像批被扩展。梯度累积也针对模态特定进行,时间感知采样器将相同长度的视频片段分组为批次。联合训练目标 Ljoint 整合了语言生成的自回归损失、分割的掩码损失以及掩码分类的 focal 损失。
实验
评估涵盖全面的图像和视频分割基准以及视觉对话任务,以评估模型的跨模态泛化与时序推理能力。消融实验验证了关键架构组件,表明战略性参数初始化、统一联合训练和多尺度掩码记忆显著提升了训练效率与时空对齐。基准评估验证了模型的整体泛化能力,显示其在保持强大静态图像分割性能的同时,相较于专家型与通用型多模态基线,大幅推进了视频理解。最终,研究结果证实统一公式有效弥合了精确空间定位与复杂时序推理之间的鸿沟,且未损害对话能力,尽管与高度专业化的视频对象分割模型相比仍存在性能差距。
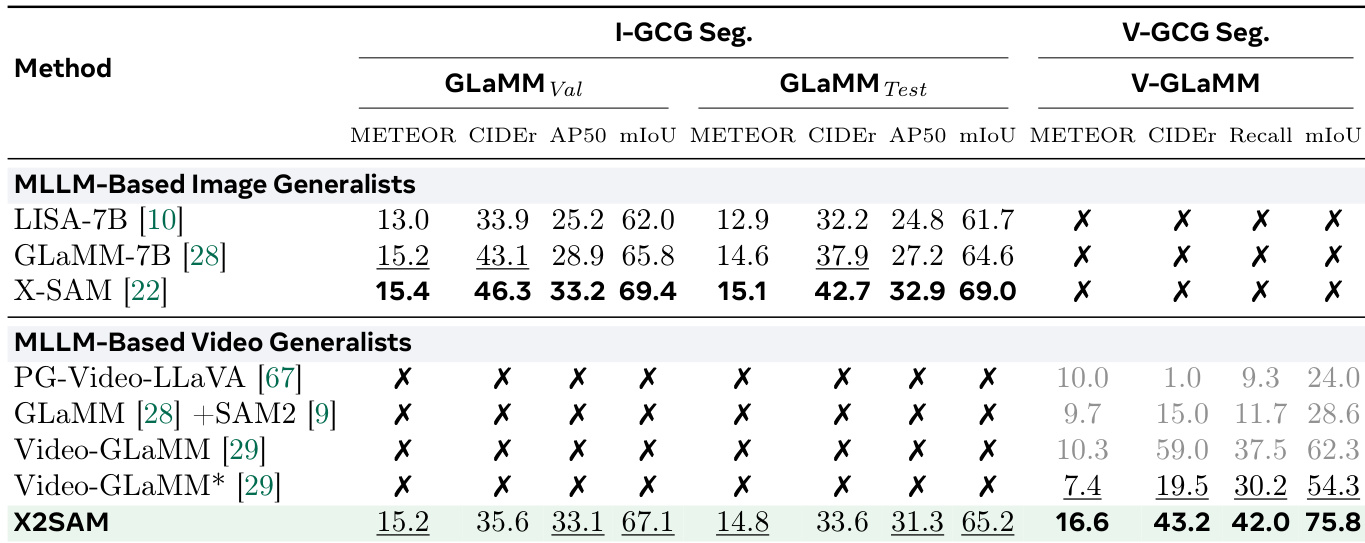
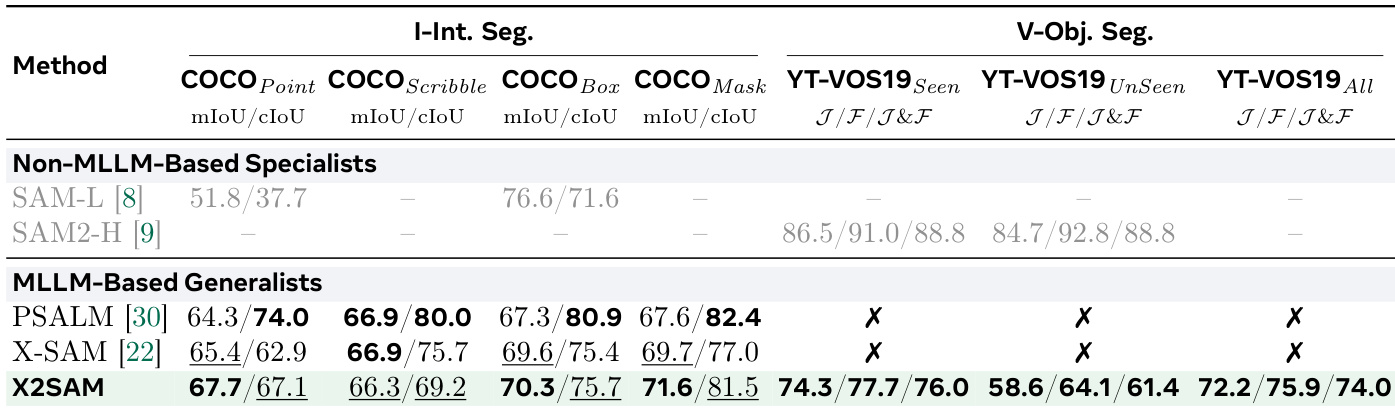
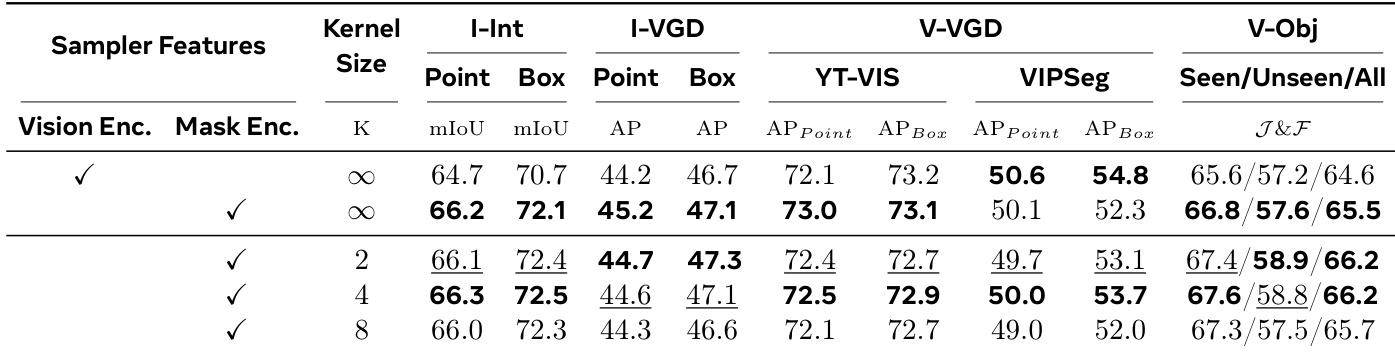
下表比较了各种方法在图像和视频对象分割任务上的性能,突显了 X2SAM 在多个基准上的强劲表现。X2SAM 在非 MLLM 专家和其他 MLLM 通用模型中实现了具有竞争力或更优的性能,特别是在视频对象分割和交互式分割任务中,部分方法标记为不支持或未报告。X2SAM 在图像和视频对象分割任务上均取得高性能,优于其他 MLLM 通用模型和非 MLLM 专家模型。X2SAM 在交互式分割中表现强劲,在 COCO Point、Scribble 和 Box 提示上取得最高分。部分方法标记为不支持或未报告,表明其在特定分割基准上的适用性受限。
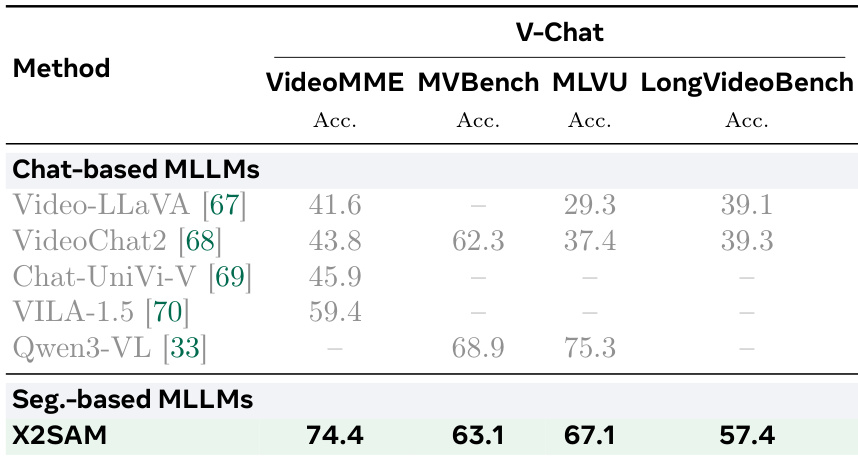
作者比较了 X2SAM 与其他基于分割和基于对话的多模态语言模型在视频对话基准上的性能。结果显示,X2SAM 在多个视频对话任务中实现了具有竞争力的准确率,优于多个以对话为中心模型,同时保持强大的分割能力。模型在视频理解方面展现出持续改进,特别是在长视频理解和多模态推理方面。X2SAM 在视频对话基准上优于多个基于对话的 MLLM,在多项任务中实现更高准确率。模型在长视频理解方面表现强劲,在 LongVideoBench 上相较于其他方法取得显著增益。X2SAM 在多模态推理任务中取得竞争性结果,证明其在整合分割与语言理解用于视频分析方面的有效性。
作者比较了不同 MLLM 在图像和视频分割任务上的性能,评估其在各类基准上的有效性。结果表明,具有特定视觉编码器和 LLM 配置的模型在图像和视频分割上均取得强劲表现,特别是在视频任务中指标优于其他模型。模型在图像分割上保持竞争性性能,同时在视频分割上展现显著改进,尤其是在需要时序推理和定位的任务中。模型在图像和视频分割任务上均表现强劲,视频分割指标相较于其他模型有显著提升。模型在图像分割基准上保持竞争性性能,同时在视频分割上展现显著增益,特别是在需要时序推理的任务中。模型在视频分割任务上优于其他 MLLM,特别是在视频指代和视频定位对话生成方面,展现出稳健的时序理解能力。

作者将 X2SAM 与现有方法在图像和视频任务的通用分割基准上进行比较。结果显示,X2SAM 在图像分割任务上实现竞争性性能,并在视频通用分割上优于其他 MLLM 通用模型,特别是在 VSPW 和 YT-VIS19 上。模型在两个领域均保持强劲表现,未以牺牲一方性能为代价。X2SAM 在视频通用分割基准上实现最先进结果,超越以往的 MLLM 通用模型。X2SAM 在图像通用分割任务上相较于专家模型保持竞争性性能。模型在图像和视频领域展现平衡性能,表明实现有效泛化而无需领域特定专业化。
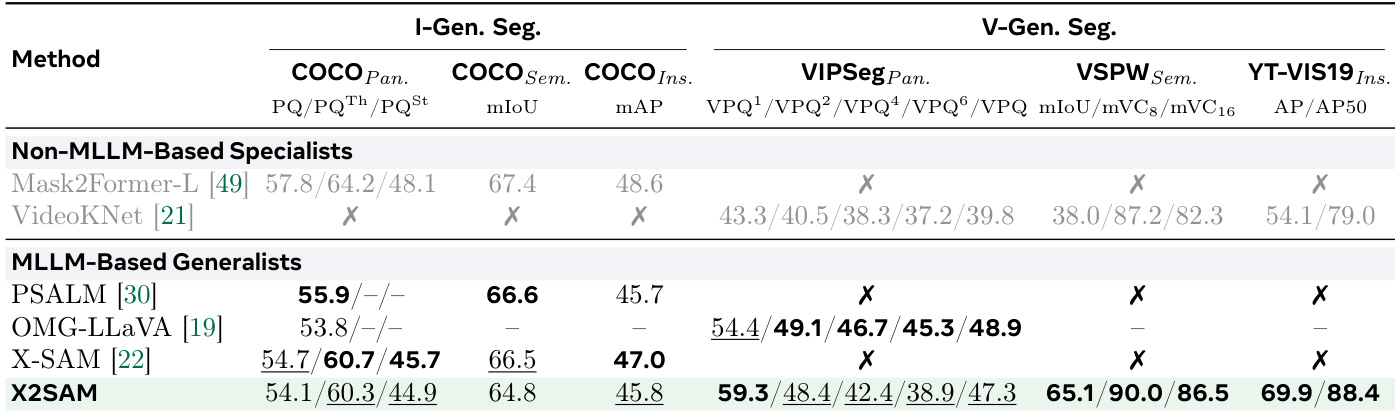
下表评估了不同区域采样器配置对各类基准分割性能的影响。它比较了使用视觉编码器与掩码编码器特征,以及用于空间聚合的不同核大小。结果表明,使用掩码编码器特征配合 4 的核大小在大多数任务中一致提升性能,特别是在图像交互和视频视觉定位分割中。这些配置的组合在多个基准上带来最佳整体结果。使用掩码编码器特征在大多数分割任务中持续优于视觉编码器特征。核大小为 4 相较于较大或全局聚合核实现最佳性能。掩码编码器特征与 4 的核大小组合在多个基准上获得最高分数,表明其分割的空间聚合达到最优。
实验将 X2SAM 与专家型及通用型多模模型在图像和视频分割、交互式提示及视频对话基准上进行比较,以验证其统一空间定位与时序推理能力。主要评估表明,模型在长视频理解和跨模态理解方面持续匹配或超越竞争方法,同时在不同视觉领域保持平衡表现。补充消融研究进一步证实,利用掩码编码器特征配合优化的空间聚合核有效提升了分割精度,突显了支撑稳健视频分析的架构选择。