Command Palette
Search for a command to run...
基于GPU的高效加速图编辑距离计算
基于GPU的高效加速图编辑距离计算
Adel Dabah Andreas Herten
摘要
图表示法是现实世界中对象及其关系的强大抽象工具。在生物信息学、机器学习和模式识别等领域,计算图编辑距离(Graph Edit Distance, GED)至关重要。GED 定义为将一种图转换为另一种图所需的最少编辑操作数量。然而,最优解及近似最优解方法较高的计算复杂度限制了其在大规模图上的应用,因此实现高性能的并行 GED 计算显得尤为必要。为解决这一挑战,我们提出了 FAST-GED,这是一个快速且可扩展的开源 GED 计算框架,专为在 GPU 上运行而设计。FAST-GED 通过面向 GPU 的算法设计及其对 GPU 硬件的高效映射,最大限度地减少了主机与设备之间的通信,从而在保持高精度的同时实现了快速执行,克服了现有方法的局限性。该实现经过优化,并在多种 GPU 架构上进行了测试。我们在包含不同图规模和大小的真实及合成数据集上对 FAST-GED 进行了验证。结果显示,与 Python NetworkX 库相比,FAST-GED 在大多数情况下都能实现数量级级别的速度提升,并达到最优解。此外,其在准确性和可扩展性方面均优于最先进(state-of-the-art)的近似方法。研究表明,FAST-GED 有助于推动基于 GED 的解决方案在现实世界应用中的更广泛采用。
一句话总结
作者提出了 FAST-GED,这是一个基于 GPU 加速的框架。该框架通过 GPU 友好的算法设计与高效的硬件映射来计算图编辑距离,从而最小化主机与设备之间的通信开销。在包含不同图规模与密度的真实及合成数据集上,该框架相比 Python NetworkX 库实现了数量级级别的加速,在大多数情况下能够找到最优解,并在准确性与可扩展性方面均优于最先进的近似方法。
核心贡献
- FAST-GED 是一种新颖的 GPU 加速框架,通过利用并行处理高效计算图编辑距离,从而克服了现有 K-Best 方法在可扩展性与准确性方面的限制。
- 该框架实现了一种经过 GPU 优化的 K-Best 树搜索,通过执行专门的分支、排序与更新内核来最小化主机与设备间的通信,同时仅保留每个搜索层级的 Top K 节点。
- 在真实与合成数据集上的评估表明,FAST-GED 在大多数情况下能够达成最优解,相比 Python NetworkX 库实现了数量级加速,相比 48 核 AMD EPYC CPU 基线最高实现 300 倍加速,并在准确性与可扩展性方面超越了最先进的近似方法。
引言
基于图的建模是生物信息学、机器学习与网络安全领域的基础,其中图编辑距离(GED)是衡量复杂网络间结构相似性的关键指标。计算 GED 本质上属于 NP-hard 问题,这迫使实践者在保证最优性但大规模数据集上计算成本过高的精确算法,以及扩展性更好但始终牺牲准确性的近似方法之间做出权衡。为弥补这一差距,作者提出了 FAST-GED,这是一种 GPU 加速框架,将 K-Best 搜索策略与高度并行的执行流水线相结合,旨在消除高昂的主机与设备间数据转移开销。通过将分支、排序与更新操作直接映射至 GPU 硬件,该方案在保持高准确性的同时,相比传统 CPU 库与现有近似基线实现了数个数量级的加速。
方法
作者采用了一种名为 FAST-GED 的 GPU 加速方法来计算图编辑距离(GED),该方法旨在高效逼近两个属性图之间的 GED。整体框架在搜索树上执行一种改进的广度优先搜索(BFS),其中每个节点代表一条部分编辑路径。算法通过层级迭代推进,每一层对应转换过程的一个阶段。在每一层中,所有节点均被展开以生成后继节点,并评估其部分编辑距离(PED)。随后根据 PED 值选取最优的 K 个节点,构成搜索树的下一层。这种选择性探索过程旨在平衡计算效率与近似精度,因为更大的 K 值能够提高找到最优编辑路径的概率。
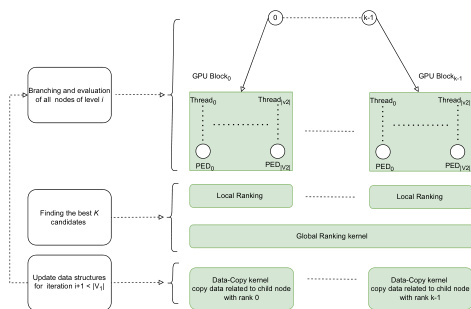
框架流程图提供了该过程的高层概览。算法从初始问题状态开始,迭代处理搜索树的每一层。该方法的核心是在 GPU 上实现的两阶段并行化策略。第一阶段为分支与评估,负责生成当前层的所有后继节点并计算其 PED。每个 GPU 块被分配一个当前层节点,该块内的线程各自负责生成并评估一个后继节点。此过程涉及使用替换操作将第一个图 g1 的顶点映射到第二个图 g2 的顶点,或执行删除操作。评估后继节点需要计算新顶点编辑操作的代价以及隐含的边操作代价。隐含边代价通过分析新映射顶点与当前编辑路径中顶点的交互关系来计算,并考虑所有可能的边替换、插入与删除。
第二阶段为选择,负责从新生成的候选节点中识别最优的 K 个节点以进入下一次迭代。为了在不产生完整排序开销的情况下高效找出 Top K 候选者,该方法采用两步排序流程。首先,在每个 GPU 块内,线程执行局部排序以确定最优的 L 个候选者(例如 L=5)。这些顶级候选者随后通过原子操作更新全局最佳 PED 值列表。其次,一个独立的内核为线程分配全局排名,从而识别出 Top K 候选者。该方法确保了选择过程具备良好的可扩展性并适用于 GPU 执行。整个过程不断重复直至到达最后一层,此时返回找到的最优路径作为近似 GED 解。
该架构旨在最大化 GPU 并行度的利用率。分支与评估阶段被映射至 GPU 块与线程,每个线程处理一个后继节点,从而实现大规模并行。选择阶段利用 GPU 共享内存与原子操作高效执行局部与全局排序。框架的复杂度分析表明,并行版本的时间复杂度为 O(n2),其中 n 为两个图中的最大顶点数,相比串行版本的 O(Kn3) 复杂度有了显著提升。空间复杂度为 O(K⋅n),得益于对 GPU 内存层次结构的高效利用,该复杂度在可管理范围内。
实验
评估设置在小规模随机数据集与中等规模真实数据集上,将 FAST-GED 与最先进的基于 CPU 的方法进行对比,同时调整图密度、GPU 架构与搜索树参数。这些实验验证了框架接近最优的准确性与一致的可扩展性,表明 GPU 并行化与内存优化有效克服了传统串行方法的计算瓶颈。定性而言,结果证实该方法在图复杂度变化的情况下仍能保持可靠性能,并提供精度与效率之间的可调平衡。最终,FAST-GED 被证明高度适用于大规模应用场景,使图分类与神经架构搜索等以往难以处理的任务得以快速且准确地执行。
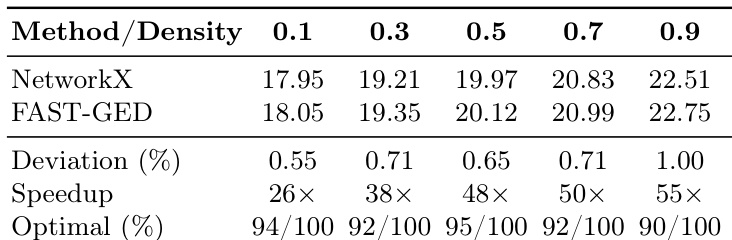
作者在小型随机图上将 FAST-GED 与 NetworkX 进行对比,结果显示 FAST-GED 以极小的偏差和显著的加速实现了接近最优的结果。该性能在不同图密度下保持一致,展现了鲁棒性与可扩展性。FAST-GED 与最优结果的偏差小于 1%,同时相比 NetworkX 提供了大幅加速。加速比随图密度增加而提升,且 FAST-GED 在不同图结构下保持稳定的性能。对于小型随机图,FAST-GED 在超过 90% 的实例中均能稳定达到最优编辑距离。
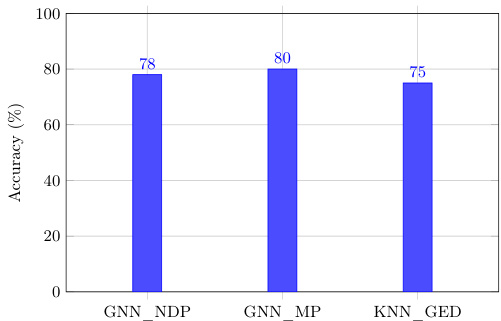
作者在不同数据集与应用场景下,将 FAST-GED(一种 GPU 加速的图编辑距离方法)与最先进的技术进行性能对比。结果表明,与传统方法相比,FAST-GED 实现了高准确性与显著加速,证明了其在图分类任务中的有效性。该方法在不同图规模与代价设置下表现稳健,并通过 GPU 并行性维持了可扩展性。FAST-GED 在保持可解释性与易实现性的同时,达到了可与先进图神经网络相媲美的精度。该方法相比传统技术展现出大幅加速,使其能够实际应用于大规模图分析。FAST-GED 在不同图规模与代价设置下保持性能一致,且随着保留节点数量的增加,精度不断提升。
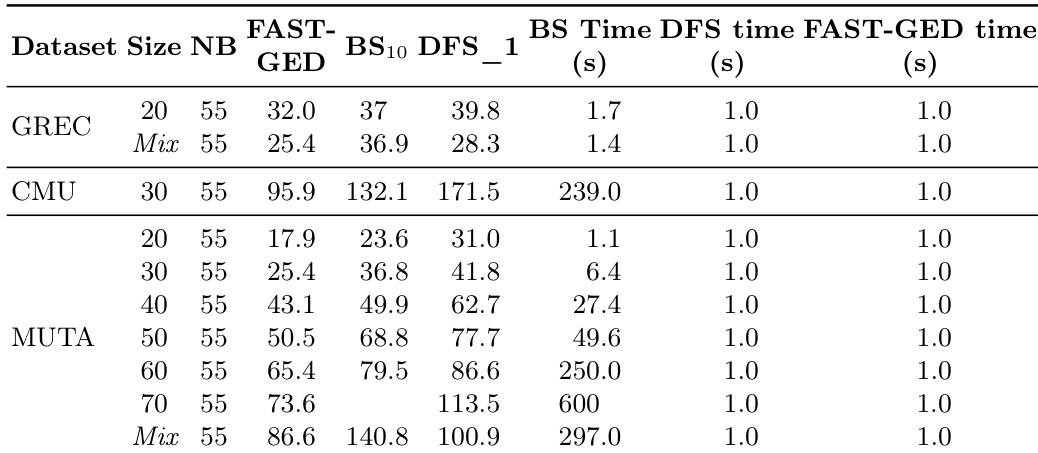
作者在中等规模真实数据集上,将 FAST-GED 与最先进的近似方法进行评估,展示了其卓越的准确性与速度。结果表明,FAST-GED 在所有数据集上均实现了低于基线方法的平均编辑距离,同时将执行时间控制在一秒以内。得益于 GPU 并行性,该方法在不同图规模下表现一致,并随图复杂度增加实现高效扩展。FAST-GED 在所有数据集上的平均编辑距离均低于 BS 与 DFS_1,且执行时间保持在一秒以内。FAST-GED 在不同图规模下表现稳定,并随图复杂度增加高效扩展。该方法的精度随节点保留数量的增加而提升,呈现出快速改进阶段随后缓慢收敛至最优编辑距离的趋势。
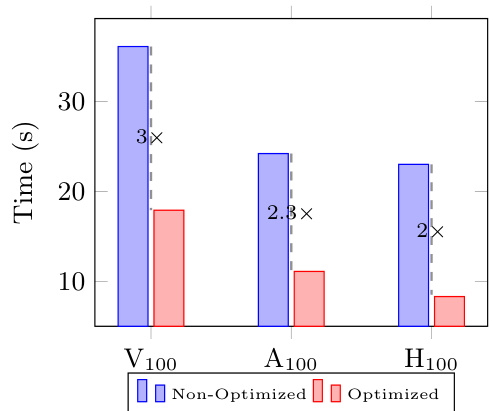
作者在不同 GPU 架构上评估了 FAST-GED 的性能,对比了优化版与非优化版。结果表明,优化版在所有 GPU 代际中均显著缩短了执行时间,且在较旧硬件上性能提升更为明显。优化版相比非优化版实现了稳定的加速,证明了所提优化措施的有效性。在所有 GPU 架构上,FAST-GED 的优化版均相比非优化版实现了显著加速。加速提升在 V100 GPU 上最为显著,优化版速度达到非优化版的三倍。优化版将最终数据准备步骤的运行时间从总运行时间的 40% 降低至 5%。
实验在小型随机图、真实数据集与多种 GPU 架构上,将 FAST-GED 与传统及近似基线进行对比,以验证其计算效率、准确性与硬件适应性。结果证明,该方法在实现大幅加速的同时,始终能够达到接近最优的编辑距离,并在不同图密度、规模与算法代价设置下保持稳健性能。硬件评估进一步证实,优化后的 GPU 实现显著降低了执行时间,尤其在较旧架构上效果明显,且未牺牲准确性。综合来看,这些发现确立了 FAST-GED 作为一种高度可扩展、可解释且实用的解决方案,能够高效支持大规模图分析。