Command Palette
Search for a command to run...
分离智力与执行:面向模型上下文协议的工作流引擎
分离智力与执行:面向模型上下文协议的工作流引擎
Abhinav Singh Parmar
摘要
大语言模型(LLM)agents 越来越多地通过模型上下文协议(Model Context Protocol, MCP)等工具调用协议与外部系统进行交互。在当前的架构中,agent 必须在每个会话中对每一次工具调用进行推理,从而消耗与执行动作数量成正比的 tokens——即使该任务此前已被解决。我们提出了 MCP 工作流引擎(MCP Workflow Engine),这是一种新型的、原生支持 MCP 的编排层,将智能(决定做什么)与执行(实施操作)解耦。Agent 仅需推理一次,即可生成声明式的工作流蓝图——这是一个 JSON 文档,指定了带有参数化模板、循环、并行分支和数据管道的有向 MCP 工具调用序列。后续执行由单一的 run_workflow 工具调用触发,无论蓝图的内部复杂性如何,每次执行仅消耗一次调用的 tokens 量。我们形式化了 MCP 中介架构模式(MCP Mediator architectural pattern)——一种同时作为下游 MCP 服务器客户端的 MCP 服务器,并基于 MCP SDK 使用 TypeScript 实现了该模式。我们在一个生产级的 Kubernetes CMDB(配置管理数据库)同步任务上评估了该引擎,该任务跨越 2 个 MCP 服务器、38 个命名空间、13 个工作节点和 22 种不同的资源类型,共包含 67 个编排步骤。结果显示,该引擎将每次执行的 tokens 成本降低了 99% 以上,在不到 45 秒的时间内完成了包含 1,200 多个节点和 2,800 多个关系(涵盖 20 种关系类型)的完整集群图构建,并实现了确定性的、幂等的执行,且运行时无需任何 agent 介入。
一句话总结
MCP 工作流引擎通过将 agent 任务编译为包含参数化模板、循环、并行分支和数据管道的声明式 JSON 蓝图,将 LLM 的智能与执行解耦。该设计使得单次 run_workflow 调用即可触发复杂序列,且仅消耗一次调用的 token 用量。其有效性已在生产级 Kubernetes CMDB 同步任务中得到验证,该任务跨越 2 个 MCP 服务器、38 个命名空间、13 个工作节点和 22 种资源类型,共包含 67 个步骤。
核心贡献
- 该工作引入了 MCP 工作流引擎,并形式化了 MCP Mediator 架构模式,建立了一个明确将 AI 驱动规划与自动化任务执行解耦的编排层。
- agent 生成一份包含参数化模板、循环、并行分支和数据管道的单一声明式 JSON 蓝图,随后引擎在内部复杂性不变的情况下,仅消耗一次调用的 token 即可执行整个流水线。
- 基于 MCP SDK 的 TypeScript 实现在生产级 Kubernetes CMDB 同步任务中进行了评估,成功编排了跨越 2 个 MCP 服务器、38 个命名空间、13 个工作节点和 22 种不同资源类型的 67 个步骤,且无需进一步的模型推理。
引言
作者探讨了业界对基于工具增强的 LLM agent 的日益依赖,这些 agent 正通过模型上下文协议(Model Context Protocol)等标准化接口,在异构系统中自动化执行复杂的多步操作。尽管此类 agent 能够实现强大的软件自动化,但现有架构迫使模型对每一个执行步骤进行推理,导致 token 呈二次方增长、延迟较高,并使重复性任务面临高昂成本。传统工作流引擎虽可避免此类开销,但依赖开发者手动编写的图结构;而多 agent 框架则会使 LLM 陷入执行循环中。为填补这一空白,作者提出了 MCP 工作流引擎,该引擎在形式上分离了一次性规划与重复性执行。模型在初始设计阶段生成声明式 JSON 工作流蓝图,随后引擎以确定性方式执行各步骤,无需任何进一步的 LLM 参与,从而在保持完全自动化的同时大幅降低推理成本。
数据集

- 数据集构成与来源: 作者通过结构化的工作流蓝图同步实时 Kubernetes 集群资源,生成集群管理数据库(CMDB)图。
- 各子集关键细节: 生成的数据集包含超过 1,200 个节点和 2,800 个关系,划分为 16 种节点标签和 20 种关系类型。该工作流在三个不同阶段处理这些资源,包括集群级创建、命名空间级迭代以及跨资源关系映射。
- 数据使用与处理: 作者执行同步流水线以验证图生成过程,通过循环迭代将 67 个顶层步骤扩展为约 2,000 次 MCP 工具调用。该流水线按顺序处理数据,最终零错误完成,且消耗零个 agent token。
- 元数据与结构细节: 图架构以 Cluster 节点为根,分支出 Namespace 和 Node 作为主要子节点。作者强制执行严格的基于阶段的执行顺序,并明确定义关系类型,以在同步集群中保持一致的元数据拓扑结构。
方法
MCP 工作流引擎采用了一种新颖的架构模式 MCP Mediator,该模式将 LLM agent 的推理阶段与工具调用的执行阶段解耦。此设计使引擎能够同时充当 MCP 服务器(向 agent 暴露工作流管理工具)和 MCP 客户端(连接下游 MCP 服务器以执行工具调用)。系统采用两阶段生命周期运行。在 1a 阶段,agent 通过工具列表发现下游 MCP 服务器,并进行试探性调用以学习可用工具的架构及其响应结构。在 1b 阶段,agent 对所需的资源类型、关系和步骤顺序进行推理,以构建声明式工作流蓝图(一种可重用的 JSON 文档)。随后该蓝图被存储并可重复执行。请参阅框架图以获取系统架构的可视化表示,图中展示了涉及的独立层级与组件。
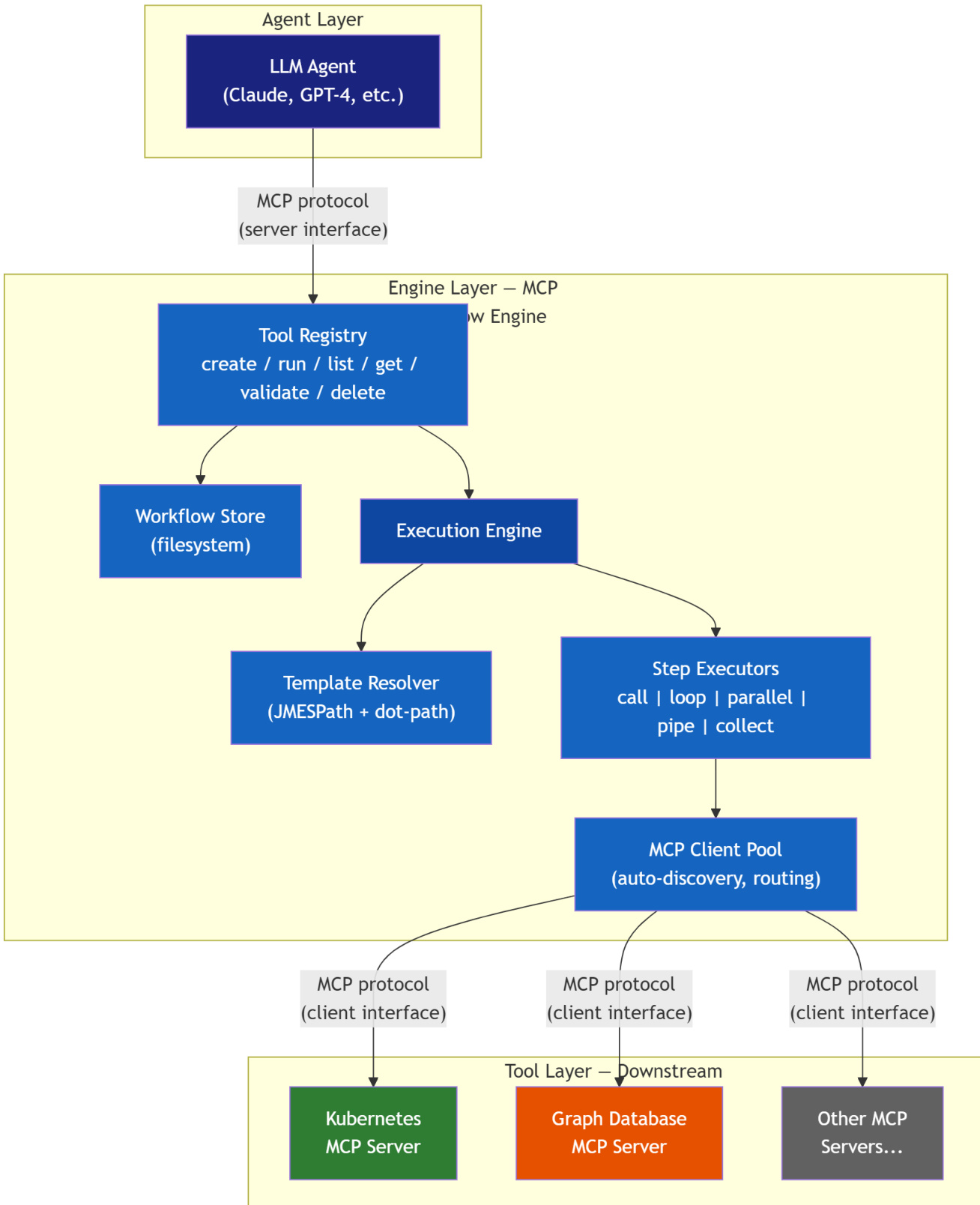
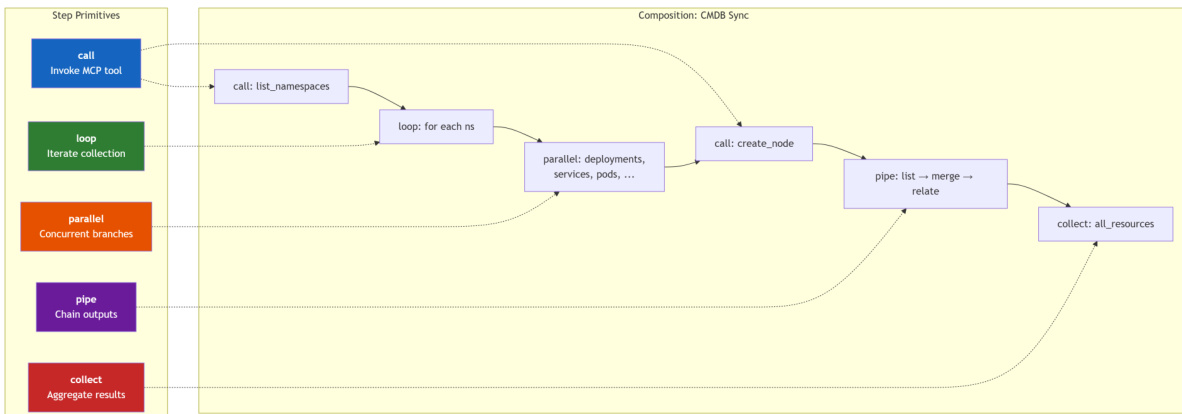
工作流蓝图是系统的核心产物,设计为可移植、可版本控制且人类可读的 JSON 文档。它指定了标识符、描述、参数化输入、错误处理策略以及步骤序列。引擎的执行由一种极简的、包含五个原语领域特定语言(DSL)驱动,用于编排这些步骤。第一个原语是 call,用于在下游服务器上调用特定的 MCP 工具。loop 原语遍历集合,为每个项目执行子步骤并注入项目级上下文。parallel 原语并发执行多个独立分支,以最大化吞吐量。pipe 原语支持顺序数据转换流水线,使前一个步骤的输出成为下一个步骤的输入。最后,collect 原语聚合子工作流的结果,促进混合 agent-引擎模式,使 agent 能够审查一批结果。该设计有意省略了条件判断和变量等结构,以维持简单性与可预测性,防止 DSL 演变为意外的编程语言。如下图所示,这些原语被组合成完整的工作流,例如 Kubernetes CMDB 同步流程。

执行引擎依赖一个稳健的模板解析流水线来处理参数化输入。该流水线执行多遍替换,解析循环变量和步骤引用以生成完全解析的命令。它支持用于结构化数据提取的 JMES.Path 表达式以及用于简单属性访问的 dot-path 回退机制。一项关键的设计决策确保当值为单个模板表达式时,解析器返回原始值(保留数组和对象)而非字符串化版本,从而实现步骤间类型安全的数据流。引擎的客户端池管理到下游 MCP 服务器的连接,自动发现工具并构建路由表。它支持三种错误策略:中止(abort)、继续(continue)和重试(retry),并提供累积错误以支持部分成功工作流的选项。引擎执行两级验证:结构错误会阻止蓝图保存,而工具警告则不会阻塞流程。序列图展示的两阶段生命周期表明,agent 仅参与初始探索和蓝图构建阶段。后续执行完全由引擎处理,无论蓝图多复杂,均消耗固定且最少的 token。
实验
实验在用于 CMDB 同步的生产级 Kubernetes 集群上展开,从效率、可靠性和可扩展性三个维度验证了确定性工作流引擎与基于概率的 agent-in-the-loop 基线的对比效果。测试表明,无论集群规模如何,该引擎均能保持稳定的 token 消耗并大幅缩短执行时间,有效缓解了 agent 基线中迅速攀升的上下文成本与高延迟问题。可靠性测试证实,确定性执行消除了幻觉风险,而稳健的错误处理确保了状态收敛的一致性。最后,组件消融实验与跨领域评估验证了模板解析与并行处理对性能的关键作用,并表明该编排模式可无缝泛化至其他重复性多步工具工作流。
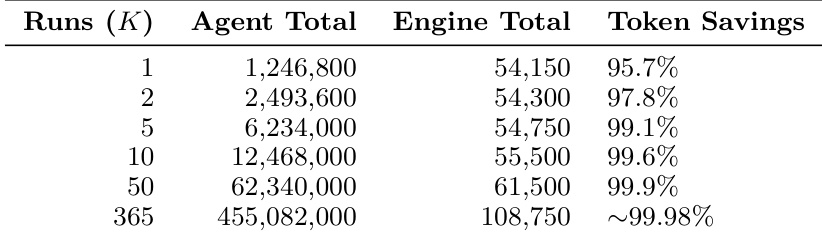
作者分析了 CMDB 同步系统的 token 消耗情况,对比了基线 agent-in-the-loop 方法与工作流引擎。工作流引擎在确保确定性与可靠行为的同时,显著降低了总 token 用量与执行时间。结果表明,随着集群规模扩大,工作流引擎的成本保持稳定,而基线方法因上下文累积呈现出超线性增长。工作流引擎通过将设计与执行解耦,降低了相较于 agent-in-the-loop 基线的总 token 消耗。在工作流引擎下,执行速度更快且具有确定性,避免了基于 agent 方法中常见的概率性失败。在工作流引擎下,token 成本随集群规模线性扩展,而基线方法则因上下文累积呈现超线性增长。

作者对比了多次运行中 agent-in-the-loop 基线与工作流引擎的 token 消耗,表明随着运行次数增加,引擎始终能实现更高的 token 节省。结果表明,引擎的成本随运行次数线性增长,而 agent 基线的成本因上下文累积呈超线性增长,导致效率收益递减。工作流引擎的 token 节省率随运行次数增加而提高,在大规模场景下节省率接近 100%。Agent-in-the-loop 的 token 成本因上下文累积呈超线性增长,而引擎成本呈线性增长。工作流引擎展现出显著的效率提升,尤其在大规模重复执行场景中。
作者在工作流引擎与 agent-in-the-loop 基线之间进行了对比评估,表明引擎实现了更快的执行速度与更高的可靠性。移除模板解析或错误处理等关键组件会导致失败,而并行执行则提升了性能。引擎的设计使其在不同配置下均能保持一致且可扩展的行为。相较于 agent-in-the-loop 基线,工作流引擎完成任务更快且零错误。移除模板解析会导致所有步骤失败,凸显了其核心作用。若无错误处理,系统将在首次失败时中止,证明了稳健恢复策略的重要性。

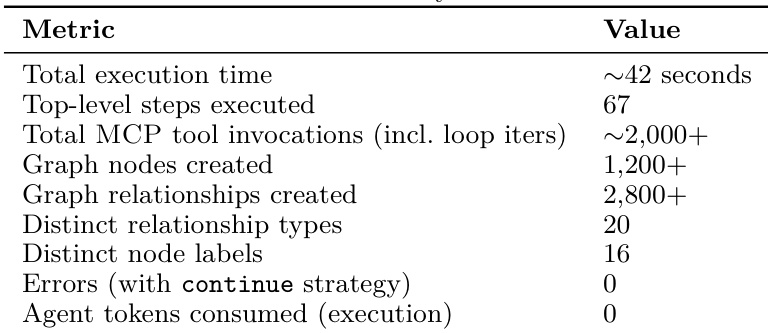
作者在 Kubernetes 集群同步任务上评估了工作流引擎,测量了执行时间、工具调用次数及图创建指标。引擎实现了快速执行、零错误以及极少的 agent token 消耗,相较于 agent-in-the-loop 基线展现了高效性与可靠性。工作流引擎在约 42 秒内完成该任务,包含超过 2,000 次工具调用,并创建了超过 1,200 个图节点。执行过程高度可靠,使用 continue 策略时零错误,且全程未消耗 agent token。引擎扩展高效,在不同集群规模下保持性能一致,且未增加 token 成本。
该实验涉及一项包含 67 个步骤的 CMDB 同步任务,跨越多个阶段,包括集群级、命名空间级和关系阶段,各阶段涉及不同的资源类型与操作。相较于 agent-in-the-loop 基线,工作流引擎在效率与可靠性方面展现出显著提升,尤其在降低 token 消耗与执行时间的同时保持了确定性行为。该任务被划分为三个阶段,包含多变的资源类型与操作,共计 67 个步骤。相较于 agent-in-the-loop 方法,工作流引擎在 execution time 与可靠性方面取得了实质性改进。在 agent 基线下,token 成本随集群规模呈超线性扩展,而在工作流引擎下则保持稳定。

实验针对 Kubernetes CMDB 同步任务,在工作流引擎与 agent-in-the-loop 基线之间进行评估,以检验其可扩展性、可靠性与资源效率。测试验证了将设计与执行解耦可生成确定性架构,该架构能够适应不同集群规模与重复运行,并保持性能稳定。定性结果表明,工作流引擎通过防止上下文累积、确保稳健的错误恢复,并避免阻碍 agent 方法的超线性 token 成本,实现了显著优于基线的表现。