Command Palette
Search for a command to run...
理解文本到视频检索中的性能瓶颈:一项综合的经验与语言学分析
理解文本到视频检索中的性能瓶颈:一项综合的经验与语言学分析
Maria-Eirini Pegia Dimitrios Stefanopoulos Björn Þór Jónsson Anastasia Moumtzidou Ilias Gialampoukidis Stefanos Vrochidis Ioannis Kompatsiaris
摘要
文本到视频检索(Text-to-Video Retrieval)使用户能够通过自然语言查询找到相关的视频内容,这一任务随着在线视频的迅速扩展而变得越来越重要。在过去的六年里,研究产生了众多方法,例如双编码器、注意力驱动模型和多模态融合方法;然而,关于模型行为、数据集影响和查询难度等基本问题仍然存在。在这项工作中,我们在统一的预处理和评估框架下,对14种最先进的检索方法在3个广泛使用的数据集上进行了评估。我们分析了标题特征,包括长度、清晰度、语义类别以及动作与场景的平衡性,并将这些特征与模型性能联系起来。我们的结果显示,简短、清晰且简单的标题(如描述单一动作或颜色属性的标题)能够实现更高的召回率,而复杂事件、多步骤活动或细粒度场景描述对所有现有模型来说仍然具有挑战性。注意力驱动的架构更能处理时间依赖或多步骤的查询,而双编码器和多模态融合模型则主要在更简单或单一类别的标题上表现良好。跨数据集的泛化能力随着更大、更多样化的标题集得到提升,但生成式标题并未一致地提高检索准确性。总的来说,我们的发现突出了关键的数据集因素、基准测试挑战以及查询内容与模型架构之间的相互作用,为开发更有效的文本到视频检索系统提供了指导。
一句话总结
通过统一框架下的综合实证与语言学分析,对三个数据集中的十四种最先进的检索模型进行评估,本研究证明:在复杂且具有时间依赖性的查询任务中,基于注意力的架构优于双编码器与多模态融合方法;而在所有评估系统中,简短且语义简单的文本描述始终能带来更高的召回率。
核心贡献
- 提出统一的预处理与评估框架,在三个广泛使用的数据集上系统性地对十四种最先进的文本到视频检索模型进行基准测试。
- 分析查询特征(包括文本描述长度、清晰度、语义类别以及动作与场景的平衡度)与整体检索性能之间的相关性。
- 揭示不同的架构权衡,表明基于注意力的模型在时间依赖性查询方面表现优异,而双编码器与多模态融合方法在更简单、单类别文本描述上实现更高的召回率。
引言
文本到视频检索使用户能够使用自然语言浏览海量视频库,该功能已成为语义搜索、数字助手和个性化推荐系统的关键能力。尽管历经六年的架构创新,该领域仍在性能瓶颈期停滞不前,同时计算复杂度持续攀升。既往研究存在评估协议不一致、过度依赖聚合指标等问题,且缺乏对查询难度、语言结构及数据集构成如何实际影响检索结果的深入洞察。为弥补这些不足,研究团队在三个主要基准上对十四种领先的检索架构进行了标准化评估,系统性地剥离文本描述多样性、语义类别及时间推理要求的影响。分析表明,模型的成功取决于查询的简单程度与数据集标注质量,为设计更严格的基准测试与下一代检索系统提供了清晰框架。
数据集

• 数据集构成与来源: 研究团队使用三个源自公开仓库的成熟视频文本检索基准进行评估:MSVD、MSRVTT 与 LSMDC。
• 子集详情: MSVD (2012) 与 MSRVTT (2016) 由带有众包人工文本描述的简短 YouTube 视频片段组成。LSMDC (2015) 包含 20 世纪 90 年代至 2010 年代的电影片段,并配有专业语音描述。LSMDC 训练集在剔除原始 7,408 个文件中的损坏文件后,过滤为 6,209 个视频。每个基准测试均提供固定测试集,其中 MSRVTT 与 LSMDC 各含 1,000 个查询,MSVD 含 670 个查询。
• 数据使用与处理: 研究团队直接采用原始创建者提供的默认训练集与测试集划分,未修改混合比例或训练流程。为研究文本描述多样性,团队利用 CLIP 与 Meta-Llama-3-8B-Instruct 为每个视频生成五条额外文本描述,从而构建扩展版 LSMDC。评估重点在于模型在不同查询分布与数据集特征下的表现。
• 元数据构建与预处理: 文本查询通过 spaCy、NLTK 与 sentence-transformers 划分为 10 种语义类型,并通过 Transformer 相似度得分与 WordNet 同义词进行类别扩展优化。无法明确归类的查询保留为“未识别”状态,以防止分析噪声。研究团队未实施自定义裁剪或帧提取策略,完全依赖原始数据集的预处理工作流与帧分割配置。
方法
研究团队利用比较框架,分析多个数据集与方法中文本查询特征与视频检索性能之间的关系。方法核心在于评估三种不同的视频检索架构,即 LSMDC、MSVD 与 MSRVTT,每种架构代表不同的模型或数据集配置。评估围绕一组既定指标与查询难度分类展开,旨在评估不同条件下的性能表现。
参见框架示意图 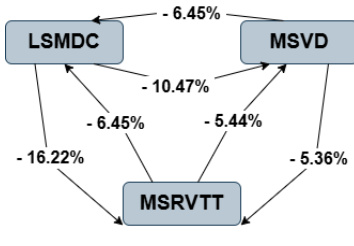 。该图展示了各模型之间的性能差异,百分比数值表示检索性能的相对变化。例如,MSVD 模型较 LSMDC 提升 6.45%,而 MSRVTT 较 LSMDC 提升 16.22%。这些指标源自检索视频的平均真实值索引,该索引用于定义查询难度。查询根据平均排名分为三个等级:简单(排名 < 200)、中等(排名 401–600)与困难(排名 > 800)。该分类使各模型处理不同难度查询的能力得以进行精细化分析。
。该图展示了各模型之间的性能差异,百分比数值表示检索性能的相对变化。例如,MSVD 模型较 LSMDC 提升 6.45%,而 MSRVTT 较 LSMDC 提升 16.22%。这些指标源自检索视频的平均真实值索引,该索引用于定义查询难度。查询根据平均排名分为三个等级:简单(排名 < 200)、中等(排名 401–600)与困难(排名 > 800)。该分类使各模型处理不同难度查询的能力得以进行精细化分析。
如图下方所示: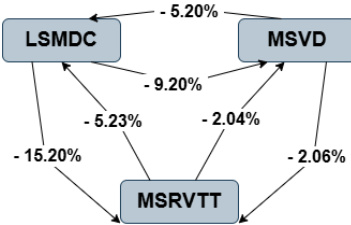 ,进一步凸显了各模型间的性能差异。MSVD 模型较 LSMDC 再次提升 5.20%,而 MSRVTT 提升 15.20%。这些差异通过相对性能差距进行量化,反映了各模型基于文本查询检索相关视频的有效性。该框架为理解查询构成与模型架构对检索结果的影响提供了系统化方法。
,进一步凸显了各模型间的性能差异。MSVD 模型较 LSMDC 再次提升 5.20%,而 MSRVTT 提升 15.20%。这些差异通过相对性能差距进行量化,反映了各模型基于文本查询检索相关视频的有效性。该框架为理解查询构成与模型架构对检索结果的影响提供了系统化方法。
实验
本研究在统一训练设置下,于三个基准数据集上评估十四种文本到视频检索模型,旨在考察架构性能、训练效率与数据敏感性。实验验证了查询语义、文本描述多样性及视频预处理如何直接影响检索结果,表明成功更依赖于数据集特征而非模型架构。语义具体且长度适中的清晰查询始终表现更佳,抽象描述仍具挑战性,而在多描述数据集上训练的模型展现出显著增强的跨数据集泛化能力。此外,敏感性分析证实,激进压缩或低帧率虽能降低计算成本,却以牺牲检索精度为代价。最终结果表明该领域进展已趋于平缓,凸显了对更丰富数据集及能够处理复杂多模态查询架构的需求。
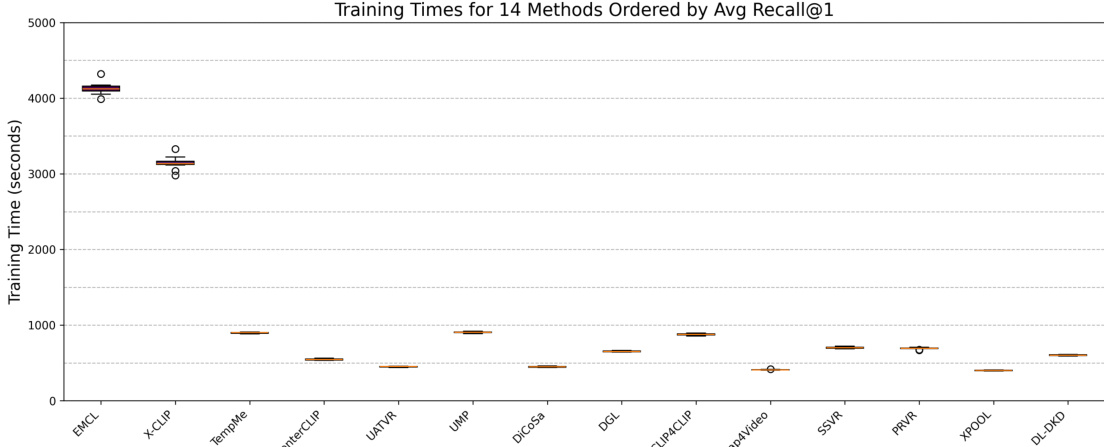
{"summary": "研究团队在三个基准数据集上使用统一的实验设置评估了 14 种视频文本检索方法。分析揭示了模型性能与训练效率之间的权衡,部分方法以显著更长的训练时间为代价换取高召回率。结果还表明,检索性能受查询难度、描述质量及数据集特征等因素影响。", "highlights": ["平均 Recall@1 较高的方法通常需要更长的训练时间,表明性能与计算成本之间存在权衡。", "大多数方法表现出相似的训练时间,但少数表现优异的模型显示出显著更长的训练周期。", "评估强调,模型性能与效率受数据集属性与查询特征影响,而非仅取决于模型架构。"]
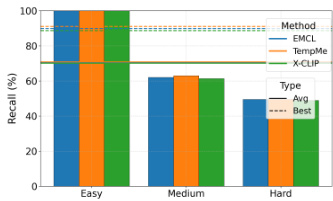
研究团队分析了不同查询难度级别下的视频文本检索性能,表明模型在简单查询上的召回率高于中等与困难查询。结果表明,检索性能随查询难度变化显著,表现最佳的模型在更简单的查询上展现出更强的性能。相较于中等与困难查询,模型在简单查询上实现更高的召回率。不同难度级别间的性能差异在多种检索方法中保持一致。表现最佳的模型在简单查询上表现更强,表明其对查询简单程度存在依赖。
{"summary": "研究团队在三个基准数据集上评估了 14 种视频文本检索方法,在一致设置下分析性能差异、任务效应与训练效率。研究强调,模型性能受查询特征(如长度、清晰度、语义类型)及数据集属性(如描述数量与多样性)影响,包含多条描述的数据集有助于提升泛化能力。", "highlights": ["查询特征(如长度、清晰度、语义类型)显著影响检索性能,长度适中且语义具体的查询表现优于复杂或抽象查询。", "相较于单描述数据集,每条视频包含多条描述的数据集提供更丰富的监督信号,并改善跨数据集泛化能力。", "表现最佳的模型展现出不同优势,基于注意力的模型处理复杂查询能力更强,而双编码器模型在简单或单类别查询上表现良好。"]
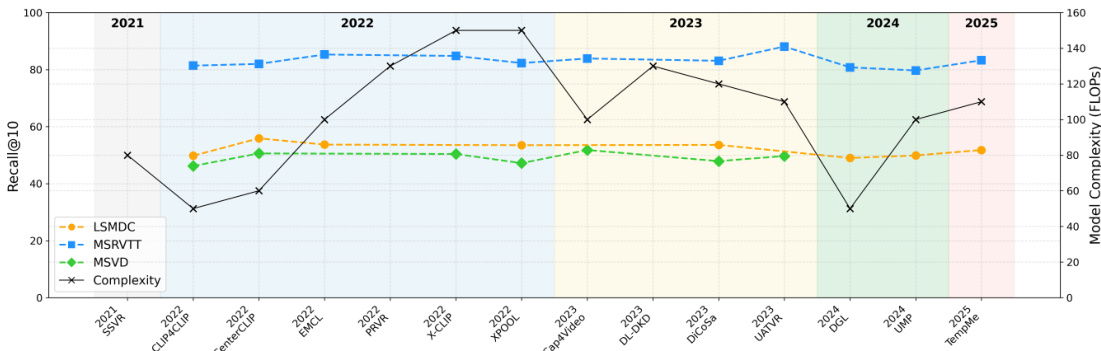
研究团队在多个数据集上分析视频文本检索模型,并基于召回率指标与模型复杂度评估其性能。结果显示,模型性能在不同数据集上差异显著,部分方法在特定数据集上实现更高召回率,而其他方法则保持稳定表现。分析同样揭示了计算效率与检索精度之间的权衡,更复杂的模型往往能实现更好的召回率,但需要更多训练时间。性能因数据集而异,部分方法在特定数据集上表现突出,而其他方法则维持稳定结果。模型复杂度与训练效率之间存在权衡,更复杂的模型实现更高召回率,但需要更多计算资源。模型性能受数据集特征影响,包括提供的描述数量与质量。
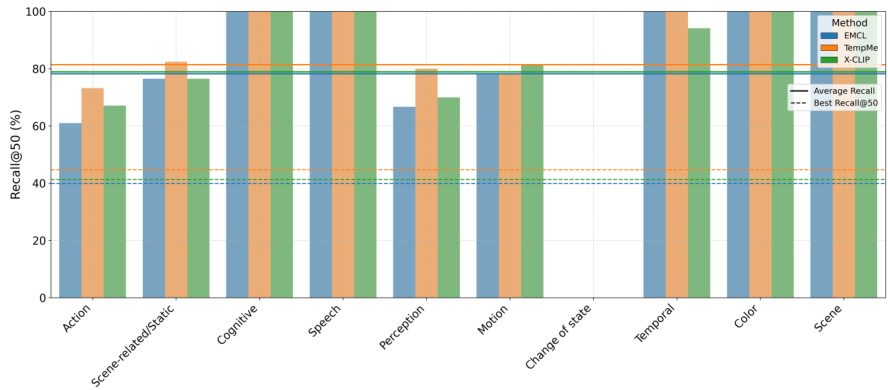
研究团队在不同语义类别下分析视频文本检索模型,重点关注查询类型如何影响性能。结果表明,模型在语音、运动、色彩等具体且简单的查询上实现更高召回率,而在动作及场景相关/静态等更抽象或复杂的类别上性能下降。表现优异的方法(EMCL、TempMe 与 X-CLIP)根据查询类型展现出不同优势,部分方法在各类别中表现一致,而其他方法对特定语义类型更为敏感。相较于抽象或复杂类别,模型在语音、运动、色彩等具体且简单的查询类型上实现更高召回率。性能在不同语义类别间差异显著,动作及场景相关/静态查询对检索更具挑战性。表现优异的方法在不同类别中展现不同优势,表明模型架构影响其对查询语义的敏感度。
研究团队在三个基准数据集上评估十四种视频文本检索方法,以考察整体性能、训练效率及对输入特征的敏感性。实验验证了检索成功高度依赖查询难度与语义清晰度,模型在具体查询上的表现始终优于抽象查询,而每条视频包含多条描述的数据集显著提升泛化能力。最终分析揭示了检索精度与计算成本之间的明确权衡,表明最优模型选择必须在架构复杂度、训练效率与特定查询需求之间取得平衡。