Command Palette
Search for a command to run...
持久视觉记忆:在LVLMs的深度生成中维持感知
持久视觉记忆:在LVLMs的深度生成中维持感知
Siyuan Huang Xiaoye Qu Yafu Li Tong Zhu Zefeng He Muxin Fu Daizong Liu Wei-Long Zheng Yu Cheng
摘要
尽管自回归大型视觉-语言模型(LVLMs)在多模态任务中展现出卓越的能力,但它们却面临着“视觉信号稀释”现象。在该现象中,文本历史的积累扩大了注意力划分函数,导致视觉注意力随着生成序列长度的增加而呈反比例衰减。为了应对这一问题,我们提出了持久视觉记忆(PVM),这是一种轻量级可学习模块,旨在确保持续且按需的视觉感知能力。PVM 作为 LVLMs 中前馈网络(FFN)的并行分支集成其中,建立了一条与距离无关的检索路径,直接提供视觉嵌入以实现精准的视觉感知,从而在结构上缓解了深度生成过程中固有的信号抑制问题。在 Qwen3-VL 模型上的大量实验表明,PVM 以极小的参数开销带来了显著提升,在 4B 和 8B 规模下均实现了平均准确率的稳定增长,特别是在需要持久视觉感知的复杂推理任务中表现尤为突出。此外,深入分析显示,PVM 能够有效抵抗由长度引起的信号衰减,并加速内部预测的收敛过程。
一句话总结
为应对自回归大型视觉语言模型中的视觉信号稀释问题,本文提出持久化视觉记忆(PVM)。该轻量级并行模块集成于前馈网络旁侧,构建了一条与距离无关的检索路径以维持视觉感知,在抵抗长度诱导信号衰减的同时,以极小的参数开销在复杂推理任务上为 4B 和 8B 的 Qwen3-VL 模型带来一致的精度提升。
核心贡献
- 本文提出持久化视觉记忆(PVM),一种集成于前馈网络旁的轻量级并行模块,旨在解决自回归大型视觉语言模型中的视觉信号稀释问题。
- PVM 建立了一条与距离无关的检索路径,可按需直接提供视觉嵌入,在结构上将视觉感知与不断扩展的文本历史解耦,从而抑制由长度增长引发的幻觉。
- 在 Qwen3-VL 4B 和 8B 模型上的评估表明,该方法以极小的参数开销在多种基准测试中实现一致的精度提升,同时有效抵抗信号衰减并加速预测收敛。
引言
大型视觉语言模型通过将视觉编码器与语言模型相连接,推动了多模态智能的发展,使复杂推理与长程对话成为可能。随着此类系统处理更长的生成任务,保持视觉保真度对于防止幻觉并确保可靠、基于事实的输出至关重要。标准自回归架构存在视觉信号稀释问题,静态图像 token 会被不断累积的文本历史逐渐淹没。以往的缓解策略依赖直接注入视觉信息或复杂上下文管理,这往往会破坏语言连贯性、修改模型主干或牺牲细粒度视觉细节。本文利用名为持久化视觉记忆(PVM)的轻量级并行模块,将视觉检索与自回归流程解耦。通过在标准前馈网络旁侧集成门控交叉注意力机制,该设计建立了一条专用路径以持续访问原始视觉嵌入。此方法在扩展上下文中维持高保真感知,且不干扰逻辑推理,在多项基准测试中带来一致的性能提升。
数据集
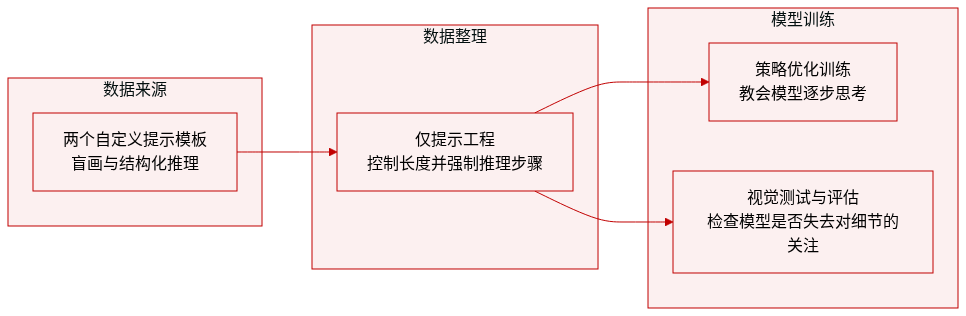
-
数据集构成与来源: 本文构建了一个以两种自定义提示模板为核心的专用指令语料库,而非依赖现成的外部数据集。这些模板作为训练与评估阶段的主要数据生成与结构化机制。
-
子集详情:
- 视觉压力测试(盲画师): 该模板明确要求详尽的视觉描述(“每一笔触”),并强制生成长篇连续文本,以隔离持续性的视觉注意力并防止通用幻觉。
- 结构化推理: 改编自 OpenMMReasoner-SFT-874K,该模板通过要求模型在生成最终答案前于
<anth Thinking>标签内输出内部推理独白,来强制执行结构化的思维链工作流。
-
训练与评估用途: 本文应用视觉压力测试以实证验证视觉信号稀释现象,而结构化推理模板则指导策略优化训练阶段及后续模型评估。两种模板均直接集成至指令微调流水线中。
-
处理与格式化细节: 本文摒弃传统的过滤、裁剪或元数据构建流程。取而代之的是依赖严格的提示词工程来控制输出长度、强制持续的视觉依赖关系并标准化推理步骤。这些指令性约束有效塑造了数据集结构及模型在各阶段的行为。
方法
本文采用并行架构以解决自回归大型视觉语言模型(LVLM)中固有的视觉信号稀释问题。所提出的持久化视觉记忆(PVM)模块作为并行分支集成于 Transformer 解码器块内的前馈网络(FFN)旁侧。该设计建立了一条专用的、与距离无关的检索路径,直接访问视觉嵌入,从而在结构上缓解由文本历史累积导致的信号抑制。
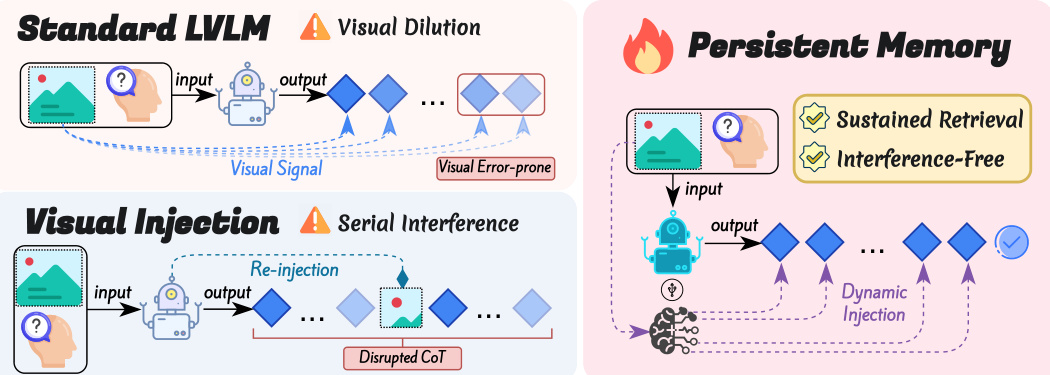
参考框架示意图,该图展示了标准 LVLM 与 PVM 增强架构之间的核心差异。在标准 LVLM 中,随着自回归生成过程的推进,视觉信号会遭受稀释与干扰,导致视觉注意力权重衰减。相比之下,PVM 框架通过将视觉感知过程与主推理流隔离,确保持续且无干扰的视觉检索。该模块将多头自注意力(MHSA)层的隐藏状态视为查询向量以检索特定视觉上下文,从而在生成过程中实现主动视觉检索。
如图下方所示,PVM 模块分三个阶段运行以确保参数效率并最小化推理开销。首先,输入隐藏状态与视觉特征通过独立的可学习降维器投影至低维潜在空间。该投影步骤充当瓶颈适配器,提炼核心视觉语义并过滤冗余。其次,执行交叉注意力机制,其中投影后的隐藏状态作为查询,投影后的视觉特征同时作为键和值。该操作将注意力域严格限制于视觉集合,实现独立的注意力归一化。随后应用轻量级前馈网络以优化潜在特征。最后,优化后的潜在特征通过上投影矩阵映射回原始高维空间。
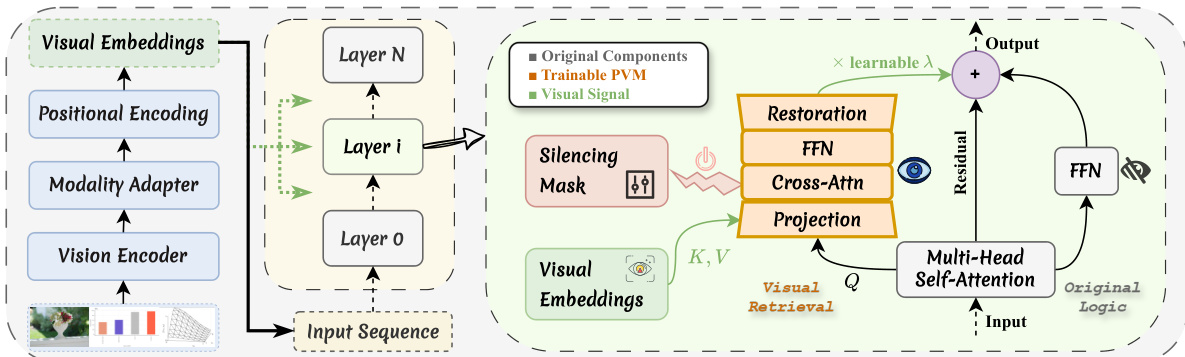
视觉记忆通过由可学习标量门控控制的残差连接注入主流程。为保持视觉表示的完整性,本文采用视觉静默掩码,该掩码仅对文本 token 激活该模块。此选择性激活机制防止视觉 token 进行冗余的自我引用,并确保视觉信号仅在必要时注入。最终输出由原始隐藏状态、FFN 输出与门控视觉注入相加得到,保持与输入相同的维度形状,从而无需结构变更即可无缝集成至模型主干。
实验
评估环节在 Qwen3-VL 架构上采用全面的多元模态基准测试与消融实验,以验证持久化视觉记忆框架的有效性。性能基准测试与长程生成测试确认,该方法能有效对抗固有的视觉信号稀释问题,大幅稳定长推理链上的模型输出。机制探测与消融实验进一步表明,这些性能提升源于对原始视觉信息的主动检索以及跨层注入策略,从而在不依赖被动参数扩展的前提下加速预测收敛。最终,该方法在多样化任务中带来一致的性能改善,同时引入的推理开销可忽略不计。
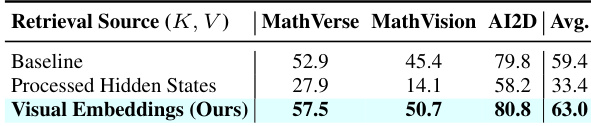
本文开展消融实验以评估不同检索源对模型性能的影响,对比原始视觉嵌入与处理后的隐藏状态。结果表明,使用原始视觉嵌入在所有基准测试中均取得更优性能,而将其替换为处理后的隐藏状态会导致精度显著下降,尤其在推理任务中更为明显。这表明模型的性能提升源于检索未处理视觉信号的能力,而非依赖以文本为主导的表示。在所有基准测试中,使用原始视觉嵌入相较于处理后的隐藏状态带来更高性能。用处理后的隐藏状态替换原始视觉嵌入会导致严重性能退化,特别是在推理任务中。原始视觉检索带来的改进归功于模型访问未处理视觉信号的能力,而非文本主导表示。
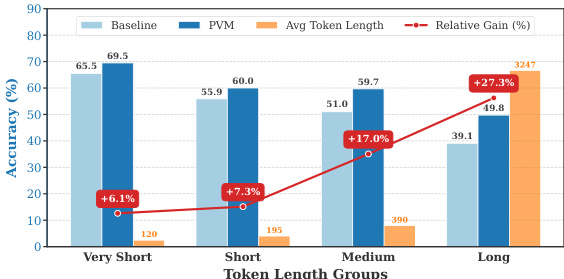
本文开展实证分析以评估持久化视觉记忆(PVM)框架在长文本多模态生成中缓解视觉信号稀释的有效性。结果表明,PVM 在不同序列长度下均持续改善性能,且在更长输出中提升幅度显著增强。该方法展现出生成长度与相对提升之间的强正相关关系,表明 PVM 在视觉注意力易衰减的推理链稳定方面尤为有效。PVM 在较长生成任务中表现出最大的相对提升,性能增益随序列长度增加而扩大。PVM 提供的改进在不同 token 长度分组中保持一致,证明其对长程生成的鲁棒性。PVM 在长序列中取得显著性能提升,而基线模型在此类场景下通常会遭受严重的视觉注意力稀释。
本文在多项多模态推理基准测试中将 PVM-8B 模型与基线 MLP 变体及标准 SFT+GRPO 方案进行对比。结果表明,PVM 持续优于两种基线方案,取得更高的平均准确率并在各项独立任务中展现改进。性能提升归功于模型在生成过程中主动检索与融合视觉信号的能力,而非参数容量的增加。PVM-8B 在所有评估基准上均取得更高平均准确率,超越 MLP 基线与 SFT+GRPO 方案。PVM 的性能改进在各独立任务中保持一致,在 MMBench-CN、MMT 与 AI2D 中提升尤为显著。性能提升源于模型的主动视觉检索机制而非参数量增加,等参数 MLP 基线的较差表现印证了这一点。

本文对比 PVM 增强模型与基线 Qwen3-VL 模型的推理性能,重点关注解码吞吐量与每个输出 token 的耗时。结果表明,PVM 增强模型的吞吐量略低于基线,解码延迟更高,表明生成过程中的计算成本存在微小但可测量的增加。与基线模型相比,PVM 增强模型的解码吞吐量略有下降。PVM 增强模型中每个输出 token 的耗时轻微增加,表明存在微小的延迟开销。尽管延迟略有上升,PVM 增强模型仍保持高速生成能力,对实时推理能力的影响可忽略不计。

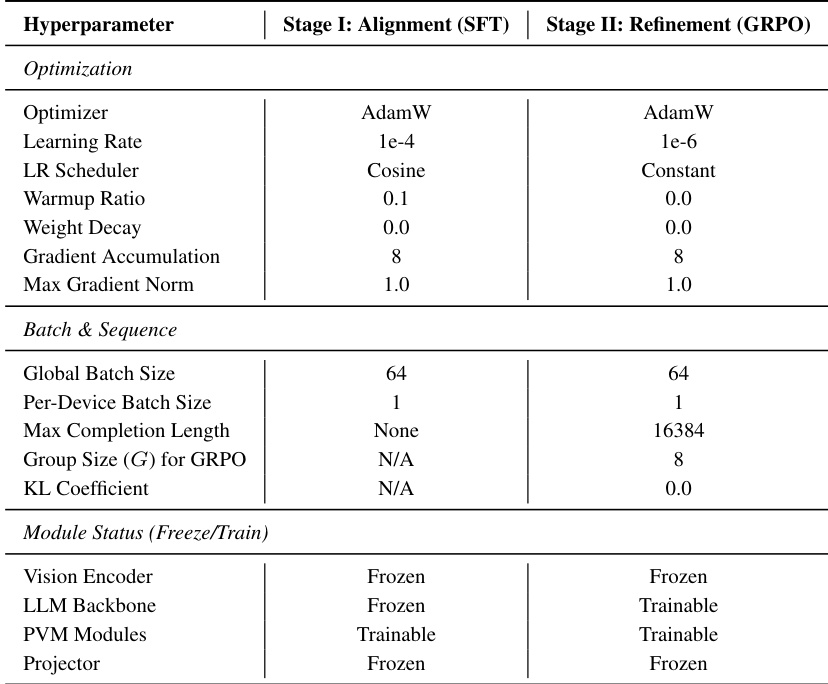
本文提出持久化视觉记忆(PVM)方法的流水线,对齐阶段与优化阶段采用不同的优化设置。第一阶段使用高学习率与余弦调度,并冻结视觉与 LLM 主干;第二阶段采用较低学习率与恒定调度,允许训练 LLM 与 PVM 模块,同时保持视觉编码器冻结。训练流水线包含两个阶段,具有不同的优化设置,涵盖独立的学习率与调度策略。第一阶段冻结视觉编码器与 LLM 主干,第二阶段则使 LLM 与 PVM 模块可训练。PVM 模块在两个阶段均可训练,但投影器在整个训练过程中保持冻结。
评估框架通过定向消融实验、对比基线测试与效率分析,在多元模态推理基准上对持久化视觉记忆(PVM)方法进行评估。实验验证确认,直接检索原始视觉嵌入对维持推理精度至关重要,而记忆机制有效对抗长文本生成中的注意力稀释,性能收益随序列长度增加而放大。对比基准进一步证明,PVM 持续优于参数量匹配与标准微调变体,证实其优势源于主动视觉信号融合而非模型容量增加。最后,效率测试表明记忆检索过程仅引入极小计算开销,完整保留实时推理能力。