Command Palette
Search for a command to run...
部署中学习:面向通用机器人策略的车队规模强化学习
部署中学习:面向通用机器人策略的车队规模强化学习
摘要
通用型机器人策略日益受益于大规模预训练,但仅依靠离线数据尚不足以支持稳健的现实世界部署。部署中的机器人会面临分布偏移(distribution shifts)、长尾故障(long-tail failures)、任务变化以及人类纠正机会,这些情况是固定的演示数据集无法完全涵盖的。本文提出“部署中学习”(Learning While Deploying, LWD),这是一种面向通用视觉-语言-动作(Vision-Language-Action, VLA)策略的持续微调框架,实现了从离线到在线、规模涵盖整个机器人集群的强化学习。LWD 从预训练的 VLA 策略出发,通过收集机器人集群中自主生成的轨迹(autonomous rollouts)和人类干预数据,在部署、共享物理经验、策略改进和重新部署之间形成闭环,从而实现策略的迭代优化。为了从异构且具有稀疏奖励(sparse-reward)的集群数据中稳定地学习,LWD 结合了分布隐式值学习(Distributional Implicit Value Learning, DIVL)以实现稳健的值估计,以及基于伴随匹配(Adjoint Matching)的 Q 学习(Q-learning via Adjoint Matching, QAM),用于在基于流(flow-based)的 VLA 动作生成器中提取策略。我们在由 16 台双臂机器人组成的集群上,对涵盖语义杂货补货及长达 3–5 分钟的长视界(long-horizon)任务在内的八种真实世界操作任务中验证了 LWD。随着集群经验的积累,单一通用策略的性能不断提升,最终平均成功率达到 95%,且在长视界任务上的提升最为显著。
一句话总结
Learning While Deploying (LWD) 是一个车队规模的离线到在线强化学习框架,用于通用视觉 - 语言 - 动作策略的持续后训练。该框架结合了 Distributional Implicit Value Learning 和通过 Adjoint Matching 的 Q-learning,以稳定异构、稀疏奖励的车队数据,利用 16 台双臂机器人共享的物理经验,在八个现实世界操作任务上实现了 95% 的平均成功率。
核心贡献
- 提出了 Learning While Deploying (LWD),作为一个车队规模的离线到在线强化学习框架,用于通用视觉 - 语言 - 动作策略的持续后训练。该系统通过利用跨机器人车队收集的自主 rollout 和人工干预,在部署和策略改进之间形成了闭环。
- 为了稳定从异构车队数据中学习,该方法结合了 Distributional Implicit Value Learning (DIVL) 以进行稳健的价值估计,以及通过 Adjoint Matching 的 Q-learning (QAM) 用于基于流的 VLA 动作生成器中的策略提取。这种方法使得使用离线数据和在线回放在多个现实世界任务上稳定训练通用 VLA 策略成为可能。
- 实验在 16 台双臂机器人车队的八个现实世界操作任务上验证了该系统,包括语义杂货补货和长视野任务。随着车队经验的积累,单一通用策略的平均成功率达到了 95%,在长视野任务上增益最大。
引言
通用机器人策略依赖于大规模预训练,但难以应对静态数据集无法捕捉的现实世界分布偏移和长尾失败。先前的强化学习方法通常因专注于特定任务设置而限制可扩展性,或无法稳定地从具有稀疏奖励的异构车队数据中学习。作者提出了 Learning While Deploying,这是一个车队规模的离线到在线框架,利用部署机器人车队共享的物理经验持续改进预训练的视觉 - 语言 - 动作策略。其方法结合了 Distributional Implicit Value Learning 以进行稳健的价值估计,以及通过 Adjoint Matching 的 Q-learning,以稳定基于流的生成器上的策略提取。该系统使得单一通用策略能够快速适应不同任务,并在长视野操作上实现高成功率。
方法
Learning While Deploying (LWD) 框架将机器人控制公式化为马尔可夫决策过程,其中策略在动作块上运行。该系统旨在弥合离线预训练与跨机器人车队的持续在线改进之间的差距。
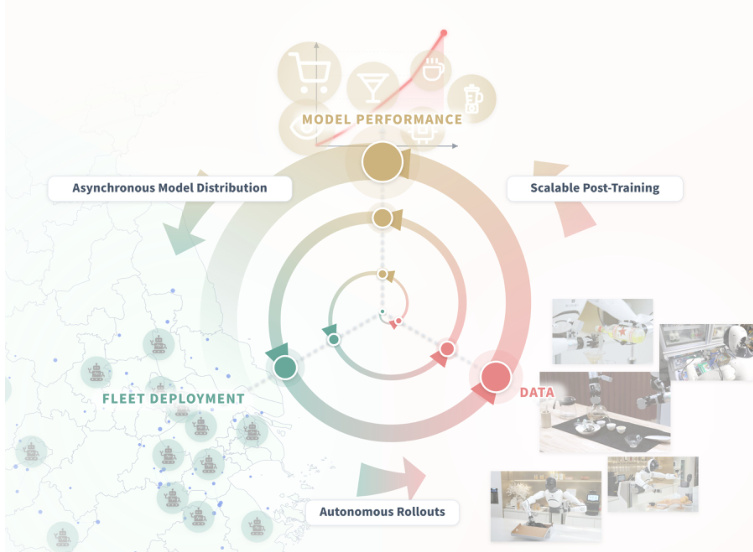
总体框架与数据飞轮
LWD 的核心理念是将部署不仅视为评估,而且视为持续学习的机制。如高层概述所示,系统作为一个连接模型性能、异步分布、车队部署和可扩展后训练的闭环运行。机器人在现实世界中执行任务,生成反馈到学习过程的数据。这创建了一个数据飞轮,其中机器人 rollout 扩展了回放缓冲区,混合回放更新了策略,刷新后的检查点被重新部署到车队。
离线到在线训练流程
训练过程分为两个不同的阶段,它们共享相同的优化目标,但数据来源不同。在第一阶段,策略、critic 和分布值模型在包含演示、专家轨迹和玩耍数据的静态离线缓冲区上进行预训练。这为部署提供了稳健的初始化。第二阶段涉及持续的在线后训练。在此,初始化的策略被部署到机器人车队进行自主 rollout。这些 rollout 用策略转换和可选的人工干预填充在线缓冲区。然后,学习者使用来自静态离线缓冲区和持续更新的在线缓冲区的混合回放来更新模型参数。
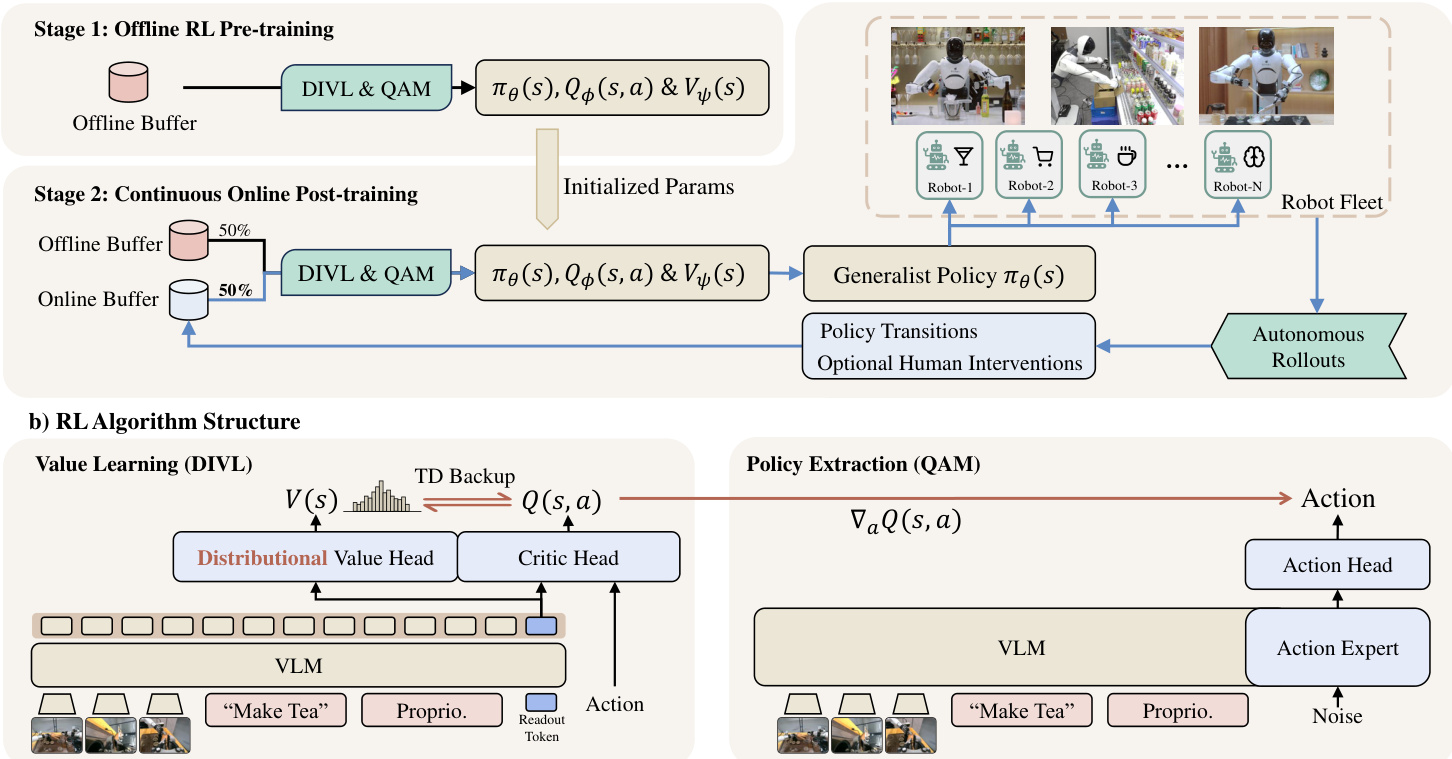
核心算法组件
LWD 的算法核心由两个主要模块组成:用于价值估计的 Distributional Implicit Value Learning (DIVL) 和用于策略提取的带有 Adjoint Matching 的 Q-learning (QAM)。
DIVL 用分布值模型替换了标准 Implicit Q-Learning 中使用的标量 expectile 值回归。分布值模型 Vψ(s) 表示数据集动作值的条件分布,而不是预测单个标量值。critic Qϕ 的 Bootstrap 目标源自该分布的分位数。这种方法保持了非对称 Bootstrap 原则,以偏向高价值动作,而不超出数据范围进行激进外推。为了处理混合任务回放中不同程度的不确定性,分位数水平 τ 根据学习到的价值分布的熵进行调整。
对于策略提取,LWD 利用基于流的视觉 - 语言 - 动作 (VLA) 模型。直接通过 flow 策略的多步生成过程进行反向传播计算成本高且不稳定。QAM 通过将轨迹级策略优化重新表述为沿参考流的局部回归目标来解决这个问题。来自 DIVL 的 critic 梯度初始化终端伴随状态,从而指导策略向量场的细化。
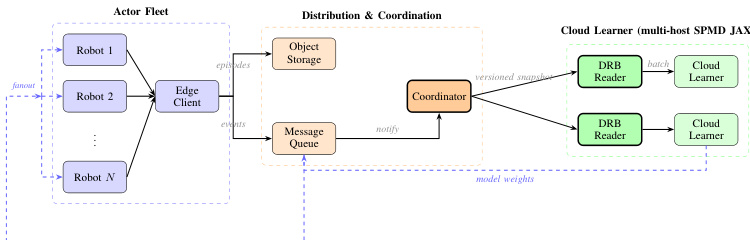
分布式系统架构
为了支持大规模部署,系统架构在 actor 车队和集中式 learner 之间进行了清晰分离。actor 车队由在本地运行策略的多个机器人组成。这些机器人与处理 episode 存储和事件通知的边缘客户端通信。协调器管理模型权重的分发和同步。在云端,多主机 SPMD JAX learner 从分布式回放缓冲区 (DRB) 读取数据,并执行 DIVL 和 QAM 更新所需的大量计算。更新后的模型权重随后异步推送到车队。
实验
该研究使用分布式机器人车队在八个现实世界操作任务上评估 LWD,以比较在线部署更新与静态或离线策略。结果表明,部署时的在线更新显著提高了性能,特别是在长视野任务上,尽管终端奖励稀疏,但学习到的价值函数成功跟踪了进度。此外,消融研究验证了分布值学习和自适应策略推动了这些增益,而分布式基础设施确保了可靠的数据摄入和策略同步。
作者在八个现实世界操作任务上评估了提出的 LWD 方法与多个基线,包括杂货补货和长视野组装。结果表明,LWD 的在线版本实现了最高的整体性能,在复杂长视野场景中观察到显著增益,其他方法在这些场景中显示改进有限。带有在线更新的 LWD 获得了最佳平均分数,优于静态和离线策略。该方法在长视野任务(如泡茶和调制鸡尾酒)上显示出相对于基线的巨大优势。在杂货补货任务上性能保持稳健,即使在基线方法已经实现高成功率的模式下仍保持顶级结果。

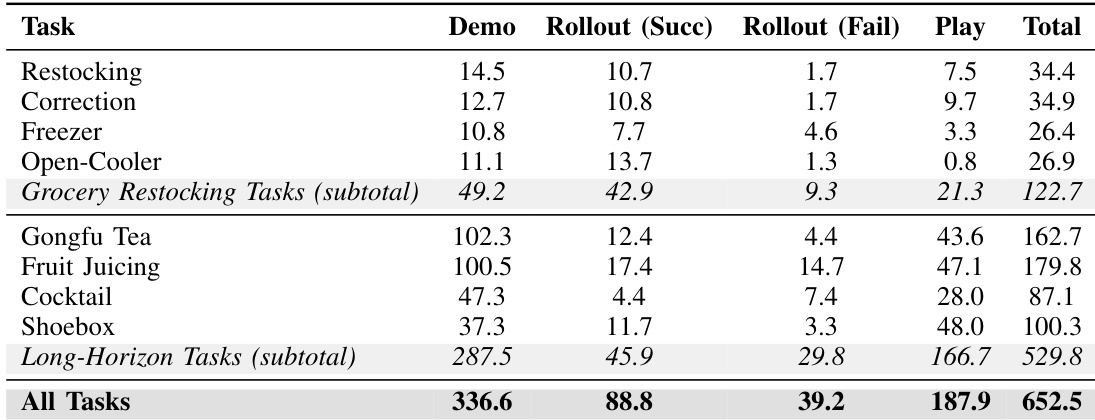
该表概述了用于训练的离线数据组成,按任务类型和来源对数据进行分类,包括演示、rollout 和玩耍数据。由于 episode 持续时间较长,长视野任务占据了数据集体积的绝大多数,而演示提供了最大份额的成功轨迹。玩耍数据和失败的 rollout 构成了缓冲区的重要部分,在长视野场景中浓度更高。与杂货补货任务相比,长视野任务占据了数据集体积的绝大多数。演示提供了最大份额的成功轨迹,超过其他数据源。玩耍数据和失败的 rollout 在长视野任务中比在杂货补货任务中更为普遍。
作者在八个现实世界操作任务上评估了提出的 DIVL 方法与 Expectile Regression,包括杂货补货和长视野组装。结果表明,对于这两种方法,在线训练设置始终产生比离线训练更高的性能。具体而言,在线 DIVL 方法实现了最高的平均分数,在复杂长视野任务上显示出相对于基线的显著改进。在线 DIVL 在所有评估任务中实现了最高的平均性能。提出的方法在长视野任务上显示出相对于基线的显著增益。DIVL 的离线和在线版本均优于 Expectile Regression 基线。

该表量化了分布式训练基础设施的操作延迟,测量了 episode 到达 learner 的时间和更新后的策略到达 actor 的时间。模型分布的中位延迟略低于 episode 摄入的中位延迟,而摄入的第 99 百分位数则 substantially 更高,表明数据上传过程中的方差更大。模型分布的中位延迟略快于 episode 摄入。episode 可用性的第 99 百分位数延迟显著高于模型接收。episode 摄入的第 99 百分位数延迟是模型分布的两倍多。

作者评估了一种分布值学习方法与标量 expectile 回归基线,以评估价值估计质量。提出的方法在离线和在线设置中,在短视野和长视野任务上始终优于基线。值得注意的是,性能优势在长视野任务上更为显著,尤其是利用在线训练数据时。提出的方法在所有任务视野和训练模式下始终获得比标量基线更高的分数。与短视野任务相比,长视野任务的性能改进要大得多。在复杂任务的在线训练期间,提出的方法与基线之间的差距显著扩大。

作者在八个现实世界操作任务上评估了提出的方法与基线,证明了在线训练设置始终产生优于离线方法的性能。结果表明,提出的方法在基线性能有限的复杂长视野场景中具有显著优势,而分布值学习进一步提高了相对于标量基线的价值估计质量。支持分析证实,长视野任务主导了数据集体积,且 episode 摄入表现出比模型分布显著更高的延迟方差。