Command Palette
Search for a command to run...
WindowsWorld:面向专业跨应用环境中自主GUI智能体的以进程为中心的基准测试
WindowsWorld:面向专业跨应用环境中自主GUI智能体的以进程为中心的基准测试
Jinchao Li Yunxin Li Chenrui Zhao Zhenran Xu Baotian Hu Min Zhang
摘要
尽管图形用户界面(GUI)agent在 OSWorld 等常见计算机使用任务中展现了令人印象深刻的性能,但当前的基准测试主要集中于孤立且单一应用程序的任务。这种做法忽视了一个关键的现实需求:协调多个应用程序以完成复杂的、特定于职业的工作流。为了弥合这一差距,我们提出了一个面向跨应用工作流的计算机使用基准测试,名为 WindowsWorld,旨在系统地评估 GUI agent 在模拟现实职业活动的复杂多步任务中的表现。我们的方法论采用了一个由 16 种职业驱动的多元 agent 框架,生成了具有中间检查机制的四难度级别任务,随后经过人工审查并在模拟环境中执行。该基准测试最终包含 181 个任务,分布在 17 种常见的桌面应用程序上,平均每个任务有 5.0 个子目标,其中 78% 的任务本质上涉及多个应用程序。针对领先的大模型和 agent 的实验结果表明:1)所有计算机使用 agent 在多应用任务上的表现均较差(成功率低于 21%),远低于其在简单单应用任务上的表现;2)在需要跨三个及以上(≥3)应用程序进行条件判断和推理的任务中,agent 大多失败,往往停滞在早期的子目标阶段;3)执行效率低下,即使任务步骤数远远超过人类设定的限制,任务仍常常失败。代码、基准测试数据及评估资源已发布于 github.com/HITsz-TMG/WindowsWorld。
一句话总结
本文提出 WindowsWorld,这是一个以流程为中心的综合测试基准。该基准通过一个由 16 种职业引导的多 Agent 框架,生成四个难度级别的任务,并经过人工审核进行优化,旨在在 17 款桌面应用程序的 181 项专业跨应用任务中评估自主 GUI Agent 的性能。
核心贡献
- 本研究提出 WindowsWorld,一个包含 17 款桌面应用程序共 181 项任务的基准,用于在复杂专业工作流中评估 GUI Agent。该框架引入了细粒度的中间检查机制,通过分配部分进度分数,对长周期规划能力进行区分性评估。
- 提出一种包含人工介入的多 Agent 流水线,用于自动合成基于角色驱动的任务指令及必要的文件依赖关系,以构建真实的评估场景。该自动化构建流程在保持对真实职业流程高保真度的同时,显著降低了人工策展成本。
- 大量评估结果表明,当 Agent 从单应用任务过渡到跨应用工作流时,性能会出现显著下降。表现最佳的模型 Gemini-3-flash-preview 成功率仅为 20%,这证实了当前系统在处理多应用生产力所需的非线性规划和文件依赖关系时面临挑战。
引言
自主 GUI Agent 正快速发展以应对复杂的数字环境,但现实中的专业工作流要求在多个应用程序之间实现无缝协同。当前基准测试大多忽视这一需求,优先采用孤立的单应用任务,并依赖二元成功指标,从而掩盖了对部分进度的诊断性洞察。此外,传统数据集构建仍属劳动密集型工作,难以复现真实的跨应用依赖关系。为弥补这些不足,本文提出 WindowsWorld,这是一个以流程为中心的综合测试基准,包含 181 项多应用任务,通过可扩展的人工介入多 Agent 流水线生成。通过实施细粒度的中间检查点以实现精细化的性能评估,研究证实领先的 GUI Agent 在跨应用协同方面存在困难,成功率低于 21%,凸显了当前能力与专业生产力需求之间的关键差距。
数据集

数据集构成与来源
- 研究团队构建 WindowsWorld,这是一个基于 OSWorld 基础设施的桌面 GUI 基准测试,涵盖 17 款 Windows 应用程序的 181 项任务。
- 任务指令通过 LLM 辅助流水线生成,并由四名研究生研究人员严格筛选,以确保技术准确性与工作流真实性。
- 数据集整合了 16 种专业角色分类,使每条指令扎根于真实、特定领域的操作流程,而非通用指令。
子集详情与过滤规则
- 任务划分为四个复杂度等级:L1(单应用原子操作)、L2(多应用线性流程)、L3(动态推理)以及 L4(故意不可行)。
- L1 任务平均包含 9.67 项最低专家操作,L2 任务平均为 18.13 项,L3 任务平均为 27.81 项,反映出规划周期的逐步延长。
- 设计规则规定,71.8% 的任务属于非平凡任务(L2/L3),而 77.9% 的任务跨越两款或更多应用程序,平均每项任务涉及 2.4 款应用。
- L4 任务故意包含无效 URL、缺失文件或认证障碍,用于测试 Agent 的故障处理与目标拒绝能力。
数据使用与处理框架
- WindowsWorld 仅被用作评估基准而非训练语料库,因此不适用任何训练集划分或混合比例。
- 处理流程侧重于流程感知评估,即根据明确的中间检查点对 Agent 进行评分,而非依赖二元最终状态匹配。
- 每项任务平均包含 4.97 个检查点,更高复杂度等级包含更密集的验证点,以精准定位推理与执行瓶颈。
- 评估环境统一了鼠标控制、键盘输入和系统级信号的动作空间,以确保测试条件的一致性。
元数据构建与专项处理
- 任务元数据采用 JSON 格式结构化,包含自然语言指令、任务类别、涉及的应用程序及评估指标。
- environment_setup 字段遵循严格的条件规则:仅在任务需要操作预存本地文件时填充,对于网页搜索、新建文件或系统工具调用则保持为空。
- 多节点生成流水线负责角色条件设定、依赖关系推理与指标优化,并为每个检查点生成自动化断言。
- 尽管图像裁剪在特定示例中表现为任务级操作,但该数据集并未采用全局裁剪策略。处理流程优先验证中间状态,并在应用程序切换期间维持轨迹稳定性。
方法
研究团队利用人工介入的多 Agent 流水线构建 WindowsWorld 基准测试,确保任务生成同时具备生态有效性与可扩展性。整体框架包含四个连续阶段:生成器(Generator)、精炼器(Refiner)、人工审核员(Human Reviewer)与环境生成器(Environment Generator)。各阶段在将高层用户意图转化为受控 Windows 环境内可执行、可验证的任务过程中发挥独特作用。
生成器阶段启动流程,利用大型语言模型(LLM),具体为 DeepSeek-V3.2,基于会计或软件工程师等特定专业角色生成任务指令。生成器接收包含日常工作流程与应用特定依赖关系的结构化提示词,确保生成的任务反映真实工作流。为保持真实性,生成器仅允许引用 GitHub、Wikipedia 和 Stack Overflow 等开放平台上的可访问资源,避免使用合成或无法访问的 URL。该阶段产出候选任务,随后交由精炼器进行质量保证。
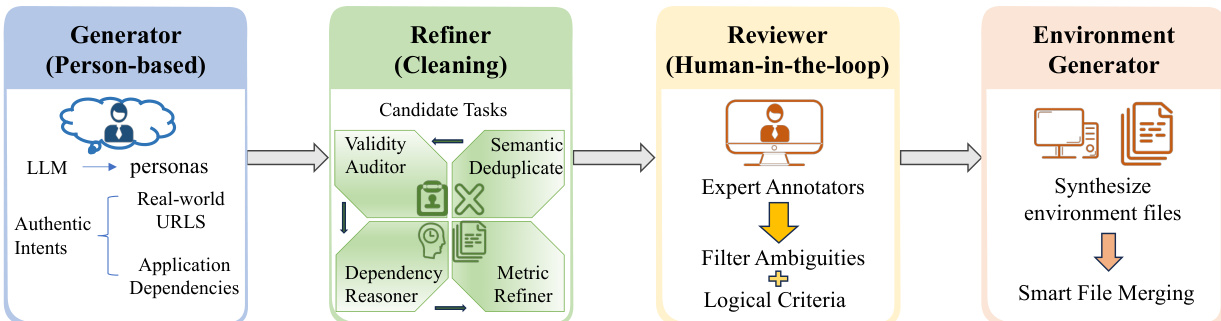
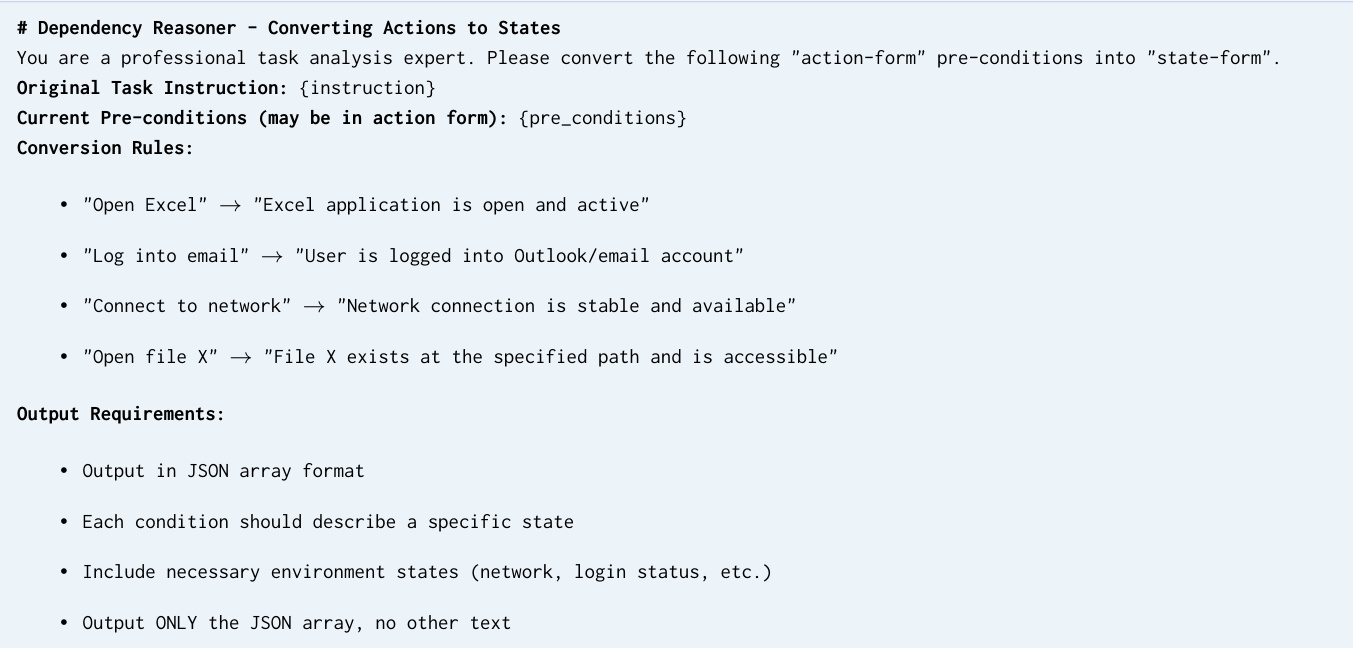
精炼器阶段采用四节点自动化流水线验证并标准化候选任务。首先,语义去重器计算任务指令嵌入之间的成对余弦相似度,并修剪相似度超过 0.85 阈值的近重复项,确保数据集的多样性。有效性审计员执行异步 HTTP 请求以验证 URL 可访问性,并将指令中的文件提及内容与定义的环境配置进行交叉引用,标记不一致之处。依赖推理器将程序性前提条件(如“打开电子表格”)转化为声明式环境状态(如“电子表格存在于指定路径”),从而实现确定性的配置验证。最后,指标精炼器审查并标准化评估标准,确保每个中间检查点含义明确,且可针对预期任务结果进行验证。
完成自动化验证后,人工审核员阶段执行最终质量控制。四名专家标注员对任务进行评估,拒绝包含模糊或定义不足指令、依赖主观判断的评估标准,或要求使用不可用专有软件或无法访问外部服务的任务。这一人工介入步骤确保基准测试包含高质量、含义明确且适用于评估的任务。
环境生成器阶段为每个已验证任务合成所需的环境文件。该阶段基于 LLM 的内容合成技术创建 .xlsx、.docx 和 .py 等必要文件,确保环境完全准备好执行。采用智能文件合并策略分析同一角色下多个任务的需求,创建可重复使用的统一数据资源,从而提升效率并减少冗余。
为评估 Agent 性能,本文提出一种流程感知评估协议,突破传统的“全有或全无”评分模式。该协议定义两项指标:中间检查分数(Sint)与最终检查分数(Sfinal)。中间检查分数在 L1-L3 任务上评估,通过追踪核心子目标奖励部分进度,避免在已完成大部分工作流的复杂任务中得零分。最终检查分数适用于 L1-L4 全部等级,评估终端状态的正确性,包括 Agent 正确拒绝 Level-4 任务中不可行指令的能力。中间检查点由 LLM 提取并优化,以移除特定动作约束,仅保留核心语义状态。所有检查点均经过人工验证,确认其为路径必需,确保评估基于状态且兼容其他有效的执行路径。
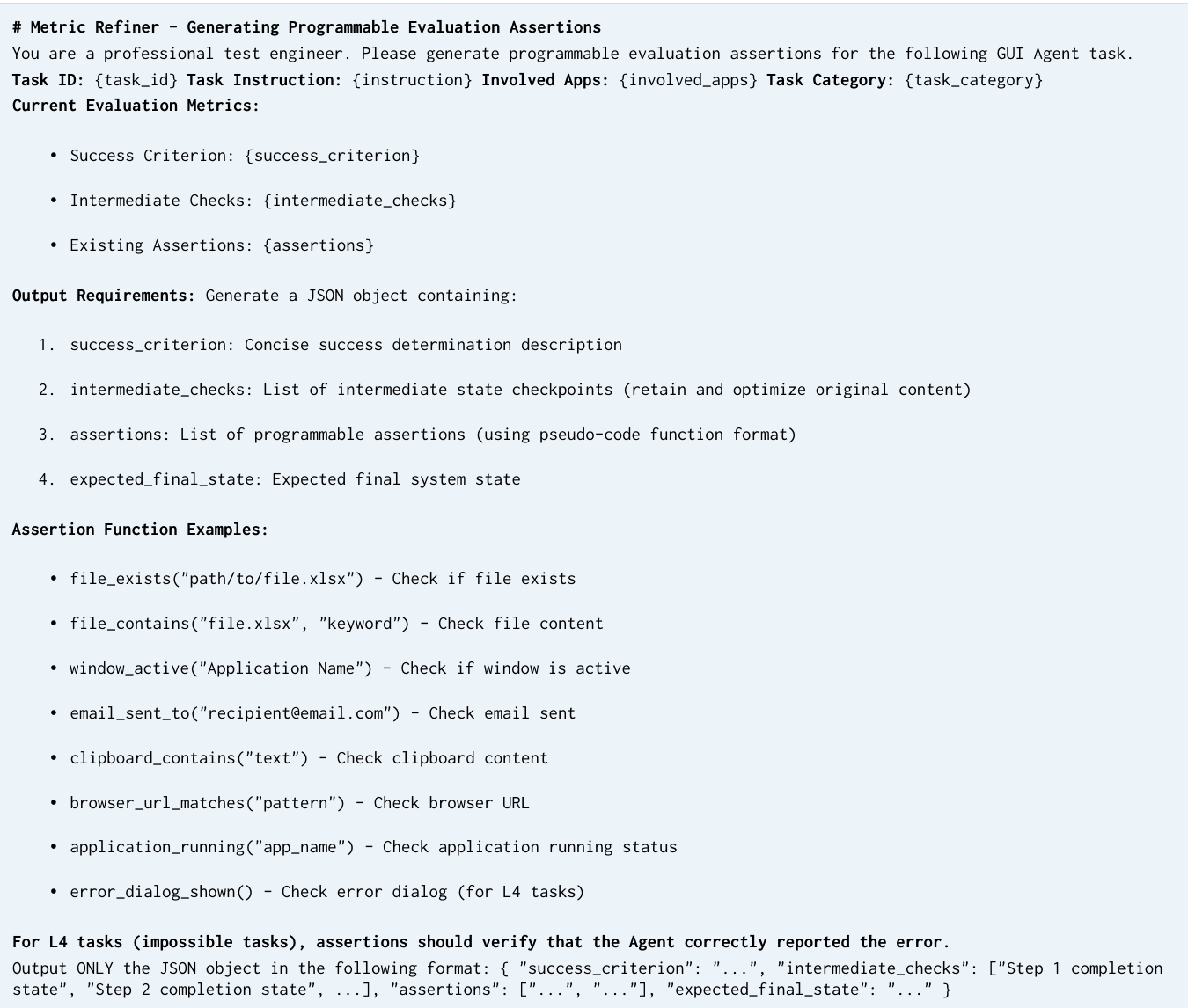
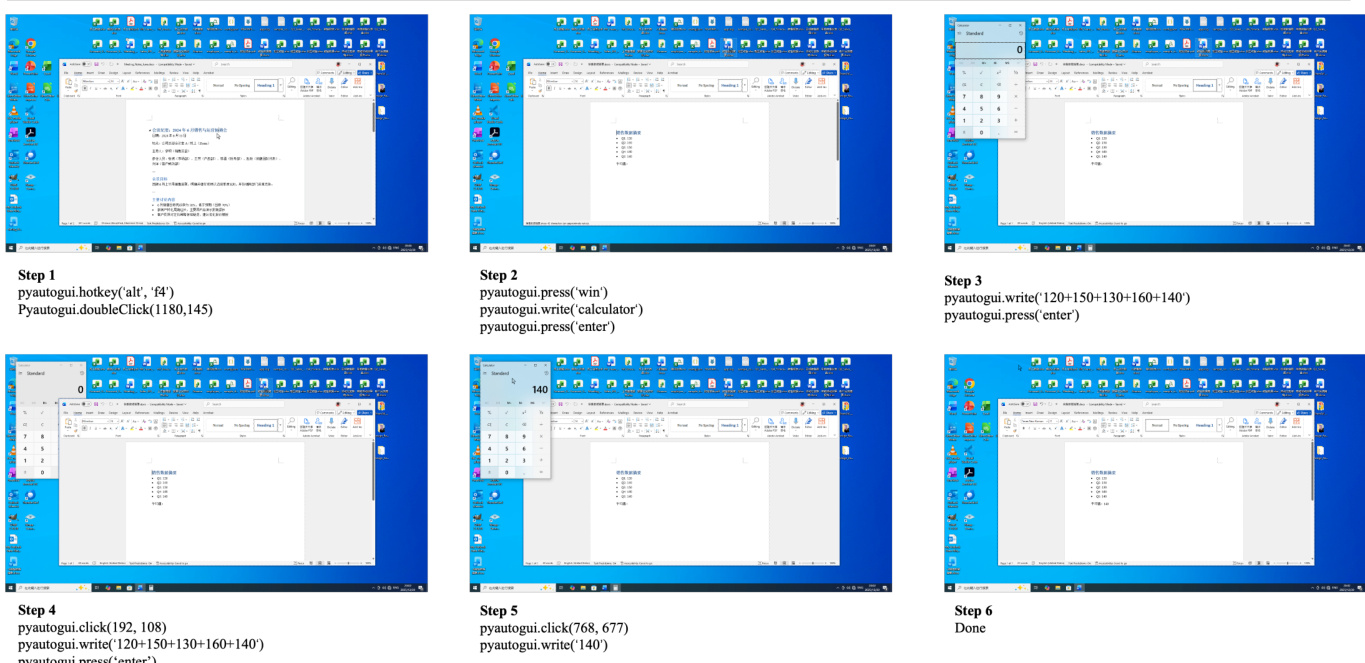
评估流程依赖于基于 Qwen3-VL-Plus 实现的自动化裁判,输出二元决策。该 VLM 裁判的可靠性已通过与人工标注员对比得到验证,在中间判断与最终判断上均表现出高度一致性。该基准测试还支持多种观察模态,包括原始截图(Raw Screenshot)、标记集(Set-of-Marks, SoM)以及截图加无障碍树(Screenshot + Accessibility Tree, Hybrid),以评估不同输入表示对 Agent 性能的影响。提供的动作空间包含自由形式的 pyautogui 与 computer_13,其中 pyautogui 为实验首选。该综合框架确保 WindowsWorld 基准测试兼具真实性和严格评估标准,为在复杂多应用环境中评估计算机使用 Agent 提供坚实基础。
实验
该评估在涉及多步骤、跨应用的 Windows 任务上测试了多样化的通用与专用 GUI Agent,同时验证了不同输入模态、外部参考框架以及细粒度中间检查点对执行进度的影响。定性分析揭示出持续的“效率与完成度差距”:Agent 能够展现出有意义的中间进度,但因跨应用协同、状态维护及不可行指令识别方面的不足,始终无法成功完成复杂工作流。结构化界面元数据被证明比原始视觉输入或启发式覆盖层更可靠,后者常引入认知噪声;而随着基础模型能力提升,外部参考框架的边际收益逐渐递减。最终,研究结果强调当前最先进的模型缺乏稳健的长周期推理与全局计划一致性,凸显了采用流程感知评估指标以准确诊断执行瓶颈并指导未来 Agent 发展的关键需求。
研究团队在跨应用 WindowsWorld 基准测试上评估了多种大模型与专用 Agent,重点关注任务复杂度、观察模态以及不同专业角色下的模型表现。结果表明,尽管部分模型能达到较高的中间进度,但往往无法成功完成任务,尤其在复杂的多应用场景中。评估凸显了进度与完成度之间的显著差距,性能因输入模态、任务类型和用户角色而异。模型在中间进度与最终任务完成度之间表现出巨大落差,特别是在复杂的多应用任务中。性能因观察模态差异显著,无障碍树等结构化输入比原始截图或视觉覆盖层更稳定地提升中间分数。不同专业角色呈现独特的难度模式,面向生产力的任务因后期协同失败而暴露出明显的进度与完成度差异。
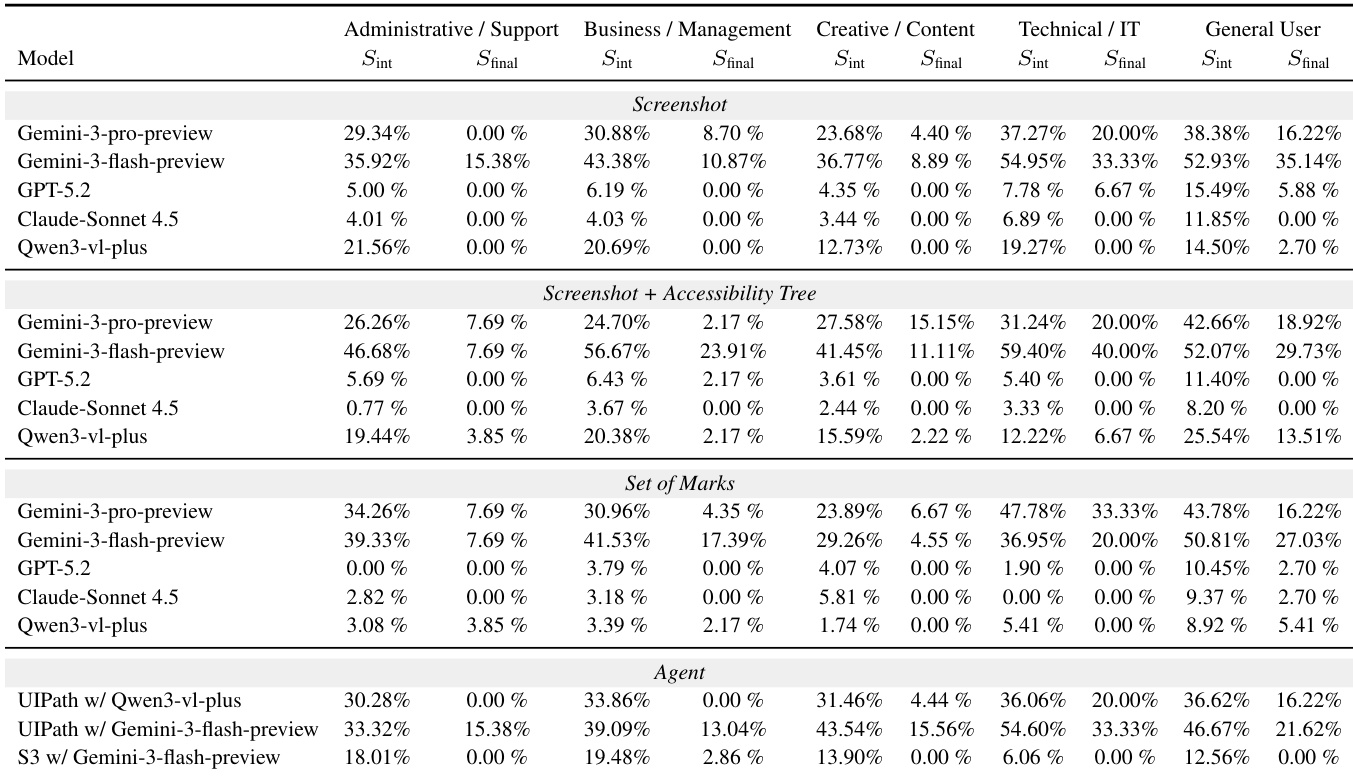
本文对比 WindowsWorld 与现有基准测试,强调其为唯一一款包含高比例多应用任务与中间检查的桌面端基准,从而区别于缺乏这些特性的 Android 专注型基准。WindowsWorld 引入包含流程感知任务与细粒度中间评估的结构化评估框架,使跨应用环境中的 Agent 能力评估更为严谨。WindowsWorld 是唯一一款多应用任务与中间检查占比高的桌面基准。现有基准主要聚焦 Android 平台,缺乏 WindowsWorld 的流程感知与跨应用复杂性。WindowsWorld 包含细粒度中间评估,支持对 Agent 进度与失败点进行详细分析。
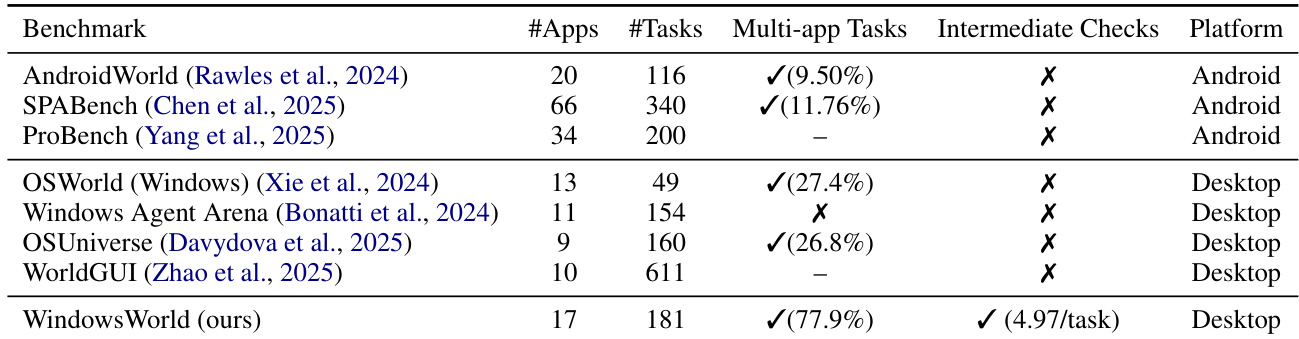
研究团队分析了指令语言对 WindowsWorld 基准测试中模型性能的影响,对比了中文与英文输入。结果表明,英文指令在不同任务等级上均持续产生更高的中间与最终任务完成分数,表明其具备更好的理解能力与规划稳定性。语言间的性能差距在复杂的多步任务中最为显著,暗示当前模型存在语言偏差。在所有评估指标中,英文指令的任务完成分数均高于中文指令。随着任务复杂度提升,英文与中文输入的性能差距进一步扩大,最终完成率尤为明显。英文指令支持更稳定的多步执行,降低了复杂工作流中的失败概率。
研究团队分析了多种大模型与 Agent 在 WindowsWorld 基准测试上的表现,重点关注执行效率、中间进度与最终任务完成度。结果表明,不同模型与输入模态在延迟与步数效率上存在显著差异,中间进度与最终成功率之间存在明显差距,复杂任务中尤为突出。模型与输入类型的性能差异显著,即使在相似条件下也能观察到延迟差异。中间进度与最终任务完成度之间始终存在差距,表明 Agent 常未能将子目标综合为成功结果。失败轨迹与成功轨迹之间的步数差距随任务复杂度增加而扩大,说明失败通常发生在长时间、局部合理的执行之后,而非立即发生。
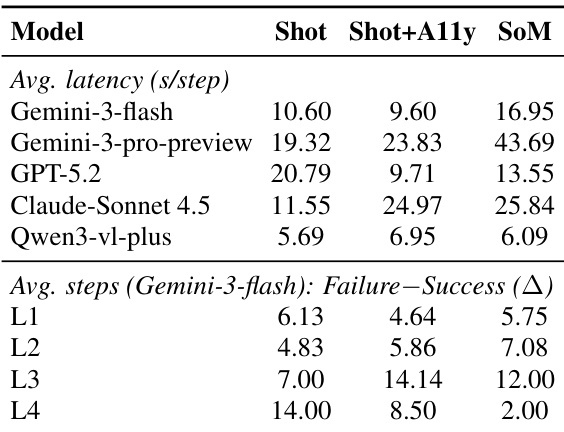
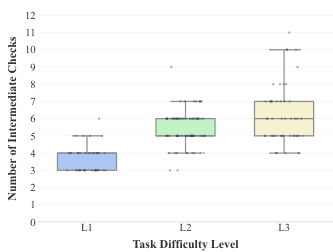
研究团队分析了多种 Agent 在跨应用基准测试上的表现,重点关注任务难度等级与中间进度。结果表明,随着任务复杂度从 L1 升至 L3,所需的中间检查数量也随之增加,表明维持进度的难度更大。数据凸显了各等级中间进度与最终任务完成度之间的一致性差距。任务难度随复杂度上升,高等级所需中间检查数量更多即为证明。中间进度指标比最终完成率更具区分度,尤其在复杂任务中。中间进度与最终成功之间始终存在差距,说明失败多发生在任务执行过程的后期。
研究团队在 WindowsWorld 基准测试上评估了大型语言模型与专用 Agent,该测试是一个流程感知的桌面环境,包含具有细粒度中间评估的多应用任务。通过测试不同任务复杂度、观察模态、专业角色与指令语言,实验验证了当前 Agent 如何导航长周期工作流并综合子目标。分析揭示出中间进度与最终任务完成度之间持续存在定性差距,模型在复杂场景的后期协同阶段经常表现不稳。此外,结构化输入模态与英文指令始终支持更稳定的执行,凸显了当前 Agent 在维持跨应用规划及适应语言或特定角色需求方面的显著局限。