Command Palette
Search for a command to run...
MiniCPM-o 4.5:迈向实时全双模全模态交互
MiniCPM-o 4.5:迈向实时全双模全模态交互
摘要
多模态大语言模型(MLLMs)的最新进展已将人工智能能力从静态的离线数据处理推向实时的流式交互,但与人类级别的多模态交互相比,仍存在显著差距。当前的关键瓶颈已不再仅仅是模态覆盖范围或延迟,而是交互范式本身。首先,感知与响应仍被割裂为交替进行的阶段,这导致模型在生成过程中无法根据新输入进行及时调整。其次,大多数现有模型仍处于被动响应状态,仅对用户的显式请求做出反应,而缺乏在动态多模态环境中主动行动的能力。为此,我们推出了 MiniCPM-o 4.5,这是我们在实现类人多模态交互方面的最新成果。该模型通过实时的全双工全模态交互(full-duplex omni-modal interaction)弥合上述差距。MiniCPM-o 4.5 能够实时地同时看、听、说,并能基于对现场场景的持续理解,展现出发出提醒或评论等主动行为。MiniCPM-o 4.5 背后的核心技术是 Omni-Flow,这是一个统一的流式处理框架,它在共享的时间轴上对齐全模态的输入和输出。这种设计将传统的基于轮次(turn-based)的交互转化为全双工且时间对齐的过程,从而实现了感知与响应的同步,并使主动行为能够在同一框架内自然涌现。
一句话总结
MiniCPM-o 4.5 通过 Omni-Flow 实现实时全双工全模态交互,Omni-Flow 是一个统一的流式框架,它将全模态输入和输出沿共享时间轴对齐,将传统的轮流交互转换为时间对齐的过程,使模型能够同时看、听、说,并在不断演变的多模态环境中表现出主动行为。
核心贡献
- MiniCPM-o 4.5 被提出作为一个 90 亿参数模型,专为实时全双工全模态交互设计,允许同时感知和响应。该架构通过运行在少于 12GB RAM 上实现实用的边缘效率,同时支持在流式和传统轮流模式之间灵活切换。
- 一个名为 Omni-Flow 的统一流式框架将全模态输入和输出沿共享时间轴对齐,将传统的轮流交互转换为全双工过程。这种形式使模型能够在生成过程中纳入新输入以进行及时调整,并支持主动行为,例如基于持续场景理解发出提醒。
- 大量评估表明,该模型在视觉语言能力上接近 Gemini 2.5 Flash,并在其规模上提供最先进的开源性能。该模型在全模态理解和语音生成质量上也超越了 Qwen3-Omni-30B-A3B,同时保持了显著更高的计算效率。
引言
多模态大语言模型的最新进展已将能力从静态数据处理转向实时流式处理,但当前系统由于僵化的范式仍无法达到人类水平的交互。现有模型通常将感知和响应分离为交替阶段,这阻止了生成过程中的及时调整,并将行为限制为响应请求而非主动参与。作者通过 MiniCPM-o 4.5 解决了这些限制,这是一个专为实时全双工全模态交互设计的 90 亿参数模型。其关键创新是 Omni-Flow 框架,它将多模态输入和输出沿共享时间轴对齐,以实现同时看、听、说。该架构允许模型表现出主动行为,并在边缘设备上保持高计算效率,同时实现最先进的性能。
数据集
- 语音数据: 研究团队处理了来自不同来源的数百万小时无标签语音,以生成用于零样本 TTS、ASR 和多轮多说话人对话的训练集。高质量对话数据涉及由基于文本的 LLM 生成的口语化指令跟随对话,并在录音室条件下由专业配音演员重新录制。演员以对话风格演绎,带有不同的情感和语速,而不是逐字阅读脚本。
- 视觉语言数据: 基于 MiniCPM-V 4.5 系统,团队扩大了规模和范围,以覆盖更广泛的任务类型和现实世界场景。知识和对齐数据利用更新的 CapsFusion 生成器来合成信息丰富的图像描述并细化图像文本相关性估计。复杂文档和 OCR 数据采用相关性感知掩码策略,优先处理与图表相关的区域,以鼓励视觉定位。
- 现实世界和视频数据: 现实世界场景样本具有自然查询模式,其中简短答案被重写为详细的思维链风格理由,并由基于奖励模型的流程过滤。密集视频感知数据提供时间事件、人类动作和复杂场景转换的连续细粒度描述。纯文本指令数据从 MiniCPM 4.1 后训练数据集中纳入,以维持强大的语言能力。
- 全模态全双工数据: 该子集包括大规模网络数据和高质量指令样本,其中每个训练样本包含完整的视觉和音频输入,以及带有时间索引标记的输出文本和语音。大规模网络音视频数据经过过滤,以移除由单说话人语音或弱音视频相关性主导的片段。质量改进应用基于 OCR 的字幕移除、说话人头像检测以及对 ASR 衍生转录的过滤。手动构建的全双工任务数据支持高级能力,如连续场景描述和主动提醒。
方法
作者介绍了 MiniCPM-o 4.5,这是一个端到端全模态架构,旨在统一文本、视觉和音频处理。该系统支持在 Omni-Flow 框架下的全双工交互以及传统的轮流推理。导致该模型出现的交互能力演变在下面的时间线中说明,显示了从纯文本模型到当前全双工系统的进展。

现有范式通常遭受阻塞 I/O 和被动响应的问题,其中感知和响应发生在交替阶段。为了克服这些限制,作者引入了 Omni-Flow 框架,该框架沿共享时间轴协调全模态输入和输出流。这种方法将连续交互划分为细粒度的时间窗口,允许模型同时感知和说话。下面的比较突出了传统流式的局限性与所提出系统的主动全双工能力。
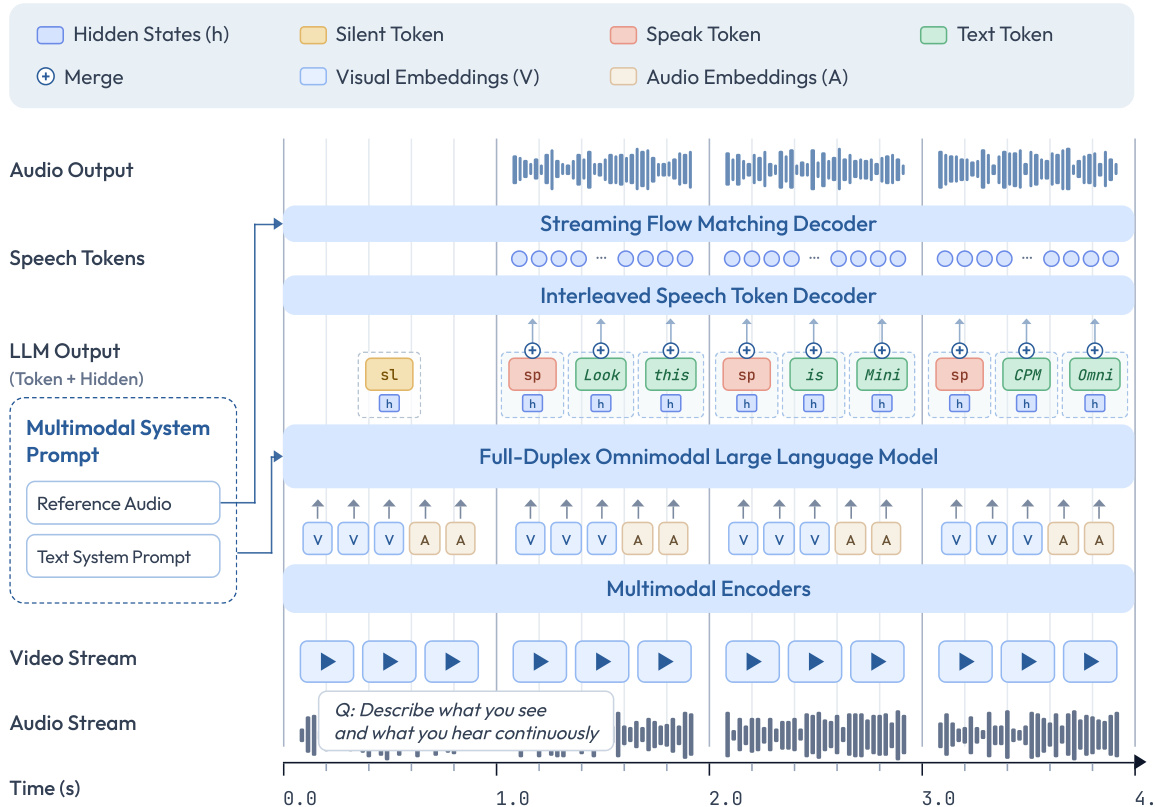
核心架构由通过 token 级隐藏状态连接的三个主要组件组成。首先,多模态编码器以流式方式处理视觉和音频输入。视觉编码利用带有 SigLIP ViT 和重采样模块的 LLaVA-UHD 策略以实现高压缩比。音频编码采用基于块的流式 Whisper Medium 编码器。其次,LLM 骨干网络(Qwen3-8B)执行全模态理解和文本生成。第三,语音解码器处理输出生成。这包括一个交错语音 tokens 解码器,自回归生成离散语音 tokens,以及一个流式流匹配解码器,将这些 tokens 转换为音频波形。
数据通过这些模块的详细流程如下图所示。
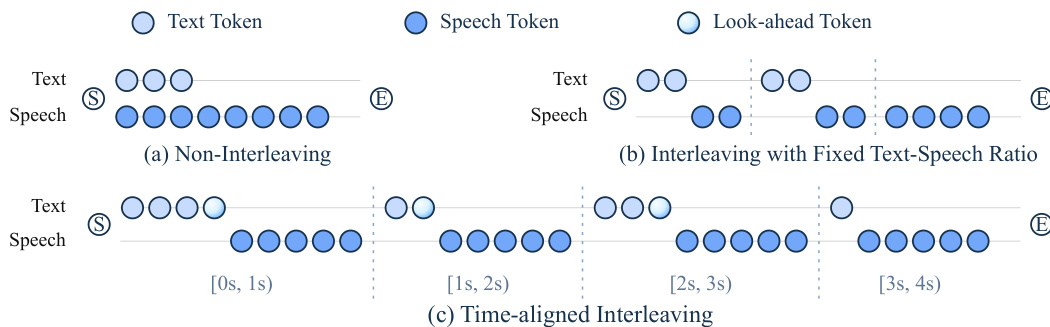
流式语音生成的一个关键挑战是保持语音输出与最新观察上下文之间的时间对齐。标准方法通常导致语音滞后于模型的演变状态。为了解决这个问题,作者提出了时间对齐交错(TAIL)。与非交错或固定比率策略不同,TAIL 自适应控制每一步生成的文本量,以确保语音流保持接近当前时间边界。这种时间对齐策略与其他方法相比的有效性可视化如下。
MiniCPM-o 4.5 的训练流程遵循精心设计的阶段过程以平滑集成语音能力。它从语音预训练开始,在冻结预训练视觉和语言组件的同时建立基础音频理解。随后是在平衡混合的视觉语言、语音和全模态数据上进行联合预训练,以构建统一的跨模态表示。随后的联合监督微调加强了所有模态的指令跟随。最后,应用强化学习以增强推理能力并利用准确性和 token 效率的奖励来减轻幻觉。
实验
评估全面评估了 MiniCPM-o 4.5 在视觉语言、语音、文本和全模态流式能力方面的表现,使用多样化的基准来验证其整体性能。结果表明,该模型在视觉语言理解和语音生成方面实现了最先进的开源性能,同时尽管进行了全模态训练,仍成功保留了核心文本能力。消融研究进一步证实,时间粒度和控制公式选择增强了全双工交互稳定性,而优化的推理框架确保了在消费级硬件上高效实时部署。
作者评估了语音生成能力,涵盖可懂度、说话人相似性和情感控制指标。结果表明,与基线模型相比,MiniCPM-o 4.5 实现了卓越的语音清晰度和表达控制。该模型在双语生成中表现出高可靠性,并且在长篇幅英语内容方面具有显著更好的稳定性。MiniCPM-o 4.5 在中文和英文方面均实现了优于基线模型的可懂度。该模型在长篇幅英语生成方面表现出比竞争对手显著更好的稳定性。MiniCPM-o 4.5 在情感和风格控制能力方面优于基线。

作者使用 LiveSports-3K-CC 基准评估全双工流式交互能力,以评估连续视觉交互。与基线模型相比,MiniCPM-o 4.5 表现出卓越的性能,在比较的系统中实现了最高的胜率。这些结果表明,所提出的 Omni-Flow 设计有效地沿共享时间线组织感知和响应,以实现更好的场景定位。MiniCPM-o 4.5 在 LiveSports-3K-CC 基准上实现了最高性能。该模型显著优于 LiveCC 和 StreamingVLM 基线。结果表明 Omni-Flow 设计对连续视觉交互有效。

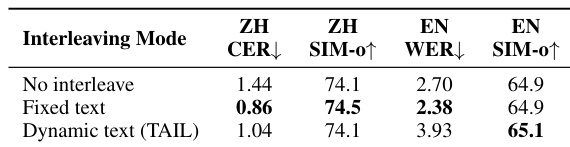
作者提出了 MiniCPM-o 4.5 与竞争模型在自动语音识别、翻译和音频理解任务方面的全面评估。结果表明,该 90 亿参数模型在语音翻译和特定问答基准方面实现了领先性能,通常超越更大的 300 亿模型。然而,评估也突出了性能差距持续存在的具体领域,特别是在复杂的事实语音问答方面。MiniCPM-o 4.5 在语音翻译和特定音频理解任务如 MELD 方面实现了领先结果,通常超越更大的 300 亿模型。该模型展示了强大的自动语音识别能力,在 GigaSpeech 和 VoxPopuli 基准上获得最高分。在基于常识的语音 QA 方面表现依然强劲,但在检索类事实和中文语音知识任务方面与基线相比存在差距。
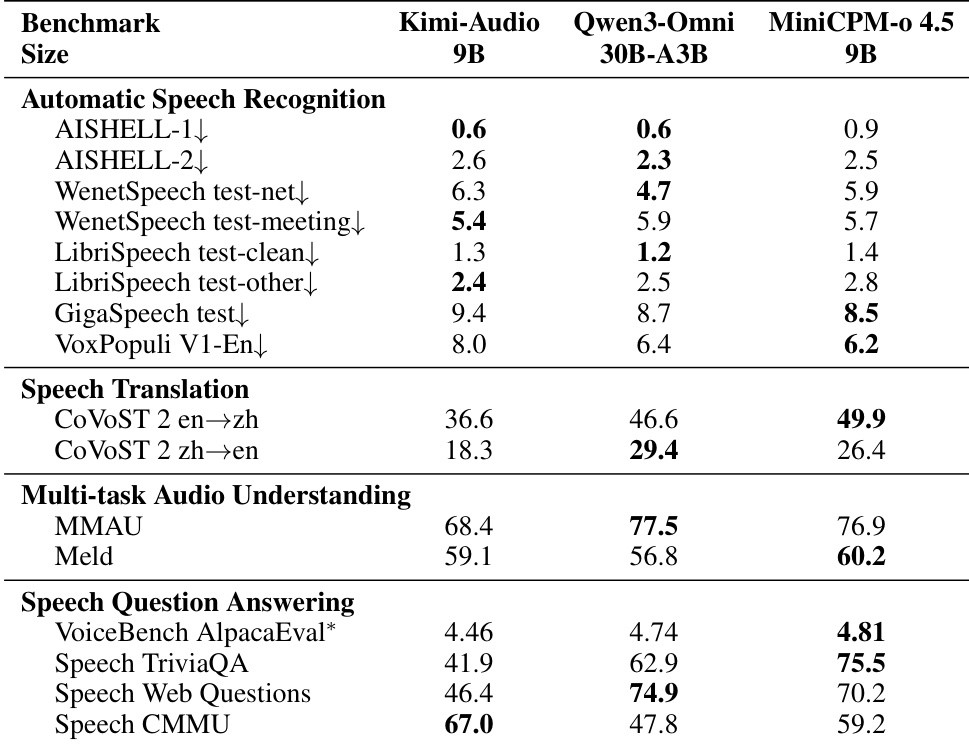
作者在单个 NVIDIA RTX 4090 上评估推理效率,将 MiniCPM-o 4.5 与更大的 Qwen3-Omni-30B-A3B 模型进行比较。结果表明,由于内存限制,较大的模型无法在 BF16 精度下运行,而 MiniCPM-o 4.5 在显著更低的内存要求下成功运行。在 INT4 量化下,MiniCPM-o 4.5 展示了更高的吞吐量和更低的延迟,同时消耗比基线少得多的内存。MiniCPM-o 4.5 在 BF16 下成功运行,而更大的 Qwen3-Omni-30B-A3B 模型遇到内存不足错误。在 INT4 量化下,与基线相比,MiniCPM-o 4.5 实现了更高的吞吐量和更低的延迟。所提出的模型保持了显著更低的内存占用,在 INT4 模式下使用的内存约为 Qwen3-Omni-30B-A3B 所需内存的一半。
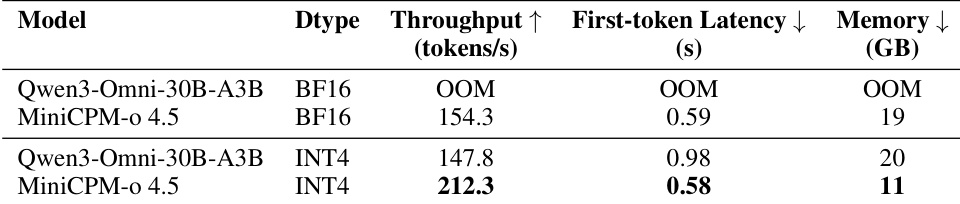
作者评估了三种语音生成模式,以评估交错对质量和交互能力的影响。固定文本交错在中文和英文方面均显示出优于其他模式的识别准确率,表明分块流式生成改善了发音。专为全双工交互设计的动态文本交错策略以少量识别准确率为代价换取了英文中更好的说话人相似性。固定文本交错导致最低的字词错误率。动态文本交错实现了英文最高的说话人相似性分数。两种交错策略在识别准确率方面均优于非交错基线。
作者评估了 MiniCPM-o 4.5 在语音生成、全双工流式、音频理解和推理效率方面的表现,以验证其能力与竞争模型相比的情况。结果表明,在语音清晰度、情感控制和连续视觉交互方面表现卓越,尽管在复杂事实问答方面存在一些差距,该模型在翻译和识别任务中通常超越更大的基线。此外,该系统展示了显著的效率优势,并通过特定的文本交错策略实现了识别和说话人相似性的最佳质量。