Command Palette
Search for a command to run...
使用RoundPipe在多个消费级GPU上实现高效训练
使用RoundPipe在多个消费级GPU上实现高效训练
Yibin Luo Shiwei Gao Huichuan Zheng Youyou Lu Jiwu Shu
摘要
在消费级 GPU 上对大语言模型(LLMs)进行微调具有极高的成本效益,但受限于有限的 GPU 内存和缓慢的 PCIe 互连带宽。流水线并行(Pipeline Parallelism)结合 CPU 卸载技术通过减少通信开销来缓解这些硬件瓶颈。然而,现有的流水线并行调度策略存在一种被称为“权重绑定”(weight binding)的根本性局限。将不均匀分布的模型阶段(例如,庞大的语言模型头层)绑定到特定的 GPU 上,会导致流水线的吞吐量受限于负载最重的那块 GPU,从而引发严重的流水线气泡(pipeline bubbles)。在本文中,我们提出了 RoundPipe,一种新型的流水线调度策略,旨在打破消费级 GPU 服务器上的权重绑定约束。RoundPipe 将 GPU 视为无状态的执行工作者池,并以轮询方式(round-robin)在设备间动态分发计算阶段,从而实现近乎零气泡的流水线执行。为确保训练的正确性和系统效率,RoundPipe 集成了优先级感知的传输调度引擎、细粒度的分布式基于事件的同步协议以及自动化的层划分算法。在 8 块 RTX 4090 GPU 服务器上的评估结果表明,在微调 17 亿至 320 亿参数的模型时,RoundPipe 相较于当前最先进的基线方法,实现了 1.48 至 2.16 倍的速度提升。值得注意的是,RoundPipe 使得在单台服务器上以 31K 的序列长度对 Qwen3-235B 模型进行 LoRA 微调成为可能。RoundPipe 作为开源 Python 库公开可用,并提供了全面的文档支持。
一句话总结
ROUNDPIPE 是一种流水线调度方法,通过在统一 GPU 池中采用轮询方式动态调度计算阶段,消除了消费级 GPU 训练中的权重绑定瓶颈。该方法辅以优先级感知传输调度、细粒度基于事件的同步以及自动层划分技术,实现了近零气泡的流水线,在 8× RTX 4090 服务器上微调 1.7B 至 32B 参数规模的模型时,相比最先进基线方法实现了 1.48-2.16 倍的加速。
核心贡献
- ROUNDPIPE 提出了一种新颖的流水线调度方案,通过将设备视为无状态工作节点并以轮询方式动态调度计算阶段,克服了消费级 GPU 上的权重绑定限制,从而消除流水线气泡。
- 该框架集成了优先级感知传输调度引擎,以实现参数移动与计算的重叠;采用细粒度基于事件的同步协议,在异步优化器更新期间保障数据一致性;并引入自动层划分算法,以平衡非对称划分阶段间的执行负载。
- 在 8× RTX 4090 和 A800 服务器上的评估表明,该系统相比最先进基线方法实现了 1.48-2.16 倍的吞吐量加速,将最大序列长度延长了最高 5.6 倍,并支持在 24 GB 显存的消费级 GPU 上对 235B MoE 模型进行 LoRA 微调。
引言
在消费级 GPU 上微调大语言模型为 AI 普及提供了一条经济高效的途径,但受限于显存容量有限与 PCIe 互连速度较慢,该方法面临严重瓶颈。为突破硬件限制,研究人员通常将 CPU 卸载与流水线并行相结合。然而,传统流水线调度存在权重绑定问题,模型阶段被静态分配至特定设备。当阶段负载不均(例如大语言模型头部)时,静态分配会导致计算速度较快的 GPU 被迫等待,产生严重的流水线气泡并造成大量空闲时间。研究团队基于此卸载架构提出 ROUNDPIPE,这是一种将 GPU 视为无状态执行池的动态调度框架。通过以轮询方式调度计算阶段,并集成优先级感知传输引擎与细粒度基于事件的同步机制,ROUNDPIPE 消除了结构性流水线气泡,相比现有基线方法实现了最高 2.16 倍的训练吞吐量提升。
方法
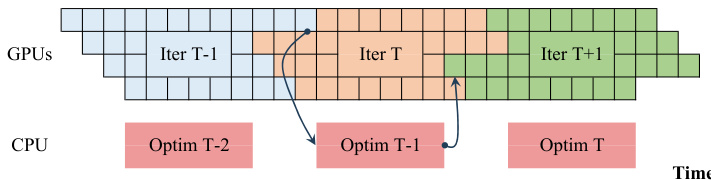
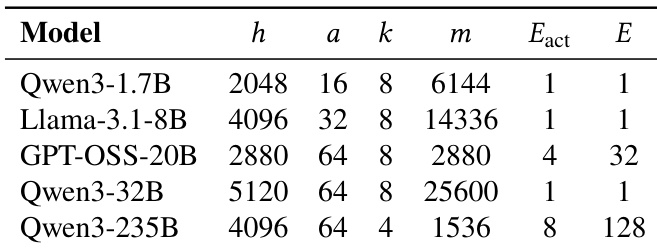
研究团队利用一种新颖的流水线并行框架 ROUNDPIPE,旨在通过解决现有方法固有的内存限制与通信瓶颈,在消费级 GPU 服务器上高效训练大模型。该系统核心建立在计算调度范式之上,将流水线阶段与固定物理 GPU 解耦,从而实现动态且灵活的调度。该范式通过将模型状态(参数、梯度与优化器状态)卸载至主机内存来实现,这使得任何 GPU 均可在所需数据就绪后立即执行相应阶段。如系统概览所示,该框架架构包含负责统筹整个训练过程的主控制器、负责执行计算与处理数据传输的 GPU 工作节点,以及在主机内存中对模型主副本执行异步更新的优化器工作节点。控制器负责管理微批次与阶段的调度,确保流水线在可用硬件上高效推进。
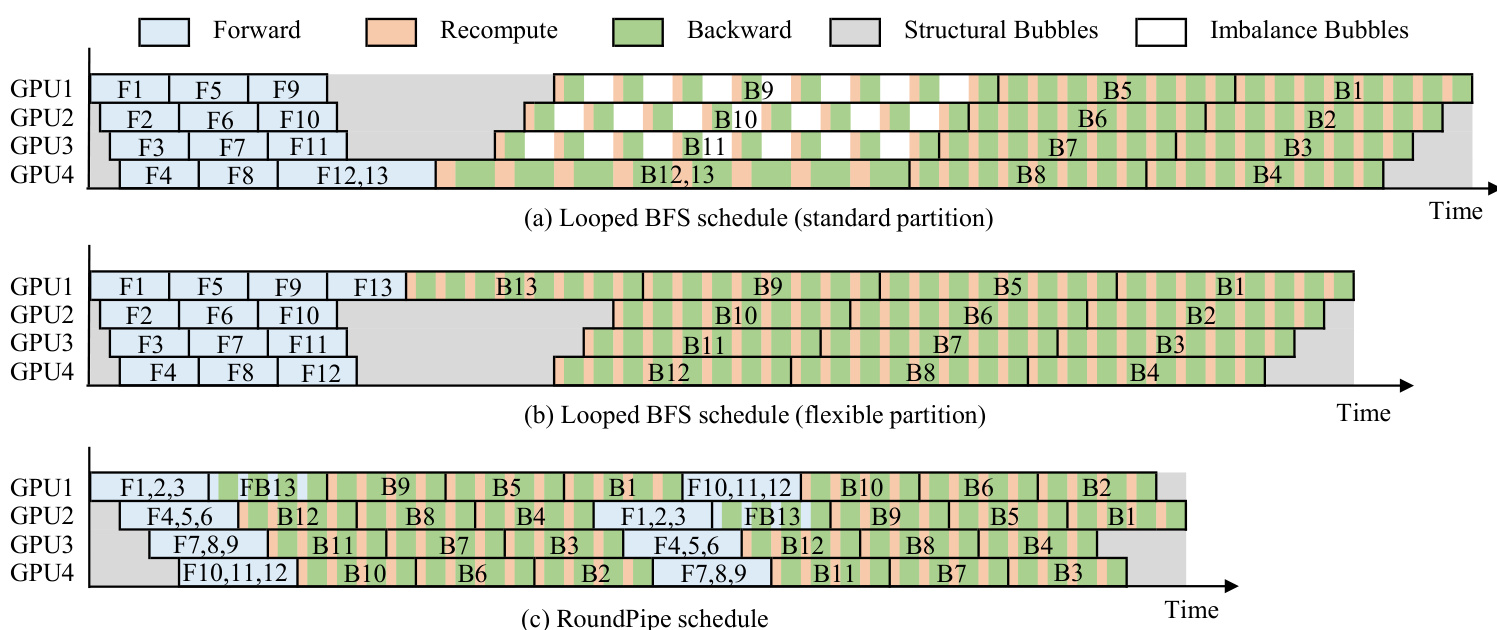
ROUNDPIPE 的调度通过两项关键机制实现。首先,轮询调度模式将微批次的前向与后向阶段按连续序列分配至所有可用 GPU,确保计算流程平滑且无气泡。该机制通过每轮处理多个微批次,并从上次分配的 GPU 无缝恢复调度来实现。其次,非对称阶段划分允许对前向与后向传播进行独立分区。由于反向传播通常因重计算而较慢,ROUNDPIPE 对层进行划分,使前向与后向阶段具有大致相等的执行时间,从而消除两阶段过渡期间的空闲时间。该方法打破了传统流水线并行的对称性,实现了更均衡高效的流水线。
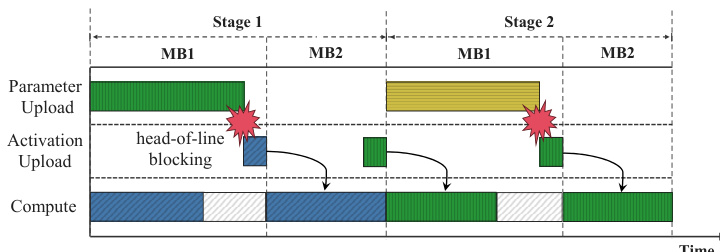
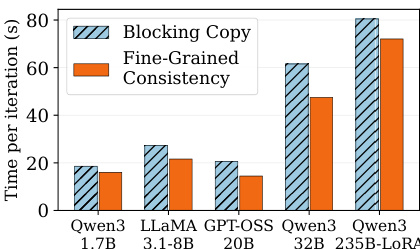
为管理调度范式所需的数据移动,ROUNDPIPE 采用多流架构以实现数据传输重叠。该系统为每个 GPU 维护四个专用通信流,分别处理参数上传、梯度下载、激活值上传与激活值下载。通过将关键路径上的激活值传输置于最高优先级,并将优先级较低的参数与梯度传输调度至激活值传输之间的空闲窗口,框架确保了数据传输与计算的高效重叠。此外,优先级感知传输调度引擎的引入进一步提升了效率,有效避免了队头阻塞问题。
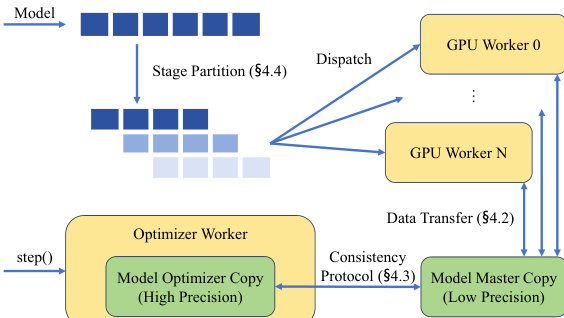
在此并发执行模型中,维持参数一致性以支持异步优化器更新是一项关键挑战。ROUNDPIPE 通过一种细粒度的基于事件的协议解决该问题。系统未在同步期间阻塞流水线,而是将权重与梯度副本卸载至优化器工作节点,并利用逐层 CUDA 事件强制执行必要的排序约束。这使得同步操作可在单个层级执行,允许流水线在早期层级继续推进,而无需等待深层级同步完成,从而消除不必要的流水线气泡。
最后,ROUNDPIPE 内置自动阶段划分算法以优化性能。系统在初始迭代期间收集逐层执行时间与内存数据,并采用贪心策略寻找最优划分方案,在满足 GPU 内存约束的前提下最小化最大阶段运行时间。该自动化流程确保了流水线各阶段负载均衡,无需手动调参。整体系统设计旨在保持全计算密集型吞吐量,屋顶线分析证实,对于典型训练批次大小,数据传输可与计算完全重叠。
实验
在消费级与数据中心 GPU 服务器上的评估实验,从端到端吞吐量、最大序列长度、扩展行为及内部流水线效率等维度,验证了 ROUNDPIPE 的内存卸载与异步优化策略。吞吐量与序列长度测试表明,该框架通过缓解流水线气泡与规避内存瓶颈,持续优于现有系统。扩展性与消融实验进一步证实,自定义调度与基于事件的一致性协议消除了通信开销,并在不同上下文长度下保持稳健性能。最终结果表明,ROUNDPIPE 是一种高效训练方案,使高性价比的消费级硬件能够媲美数据中心级性能。
研究团队在消费级 GPU 服务器上评估了 ROUNDPIPE 的性能,证明其在不同模型规模下相比现有系统实现了更高的训练吞吐量并支持更长的序列长度。结果表明,ROUNDPIPE 在序列长度增加时仍能保持稳健性能,并通过新颖的调度与通信策略显著减少流水线气泡。系统随 GPU 数量增加有效扩展,即使在内存与带宽受限的硬件上也能超越基线方法。ROUNDPIPE 在多种模型规模与 GPU 数量下均实现了高于现有系统的训练吞吐量。与其他框架相比,ROUNDPIPE 支持更长的序列长度,尤其在参数量较大的模型上表现突出。随着序列长度增加,系统保持性能稳定,在不同上下文长度下展现出良好的鲁棒性。
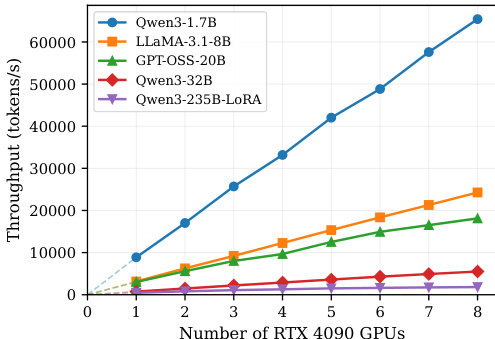
研究团队在消费级与数据中心级 GPU 服务器上评估了 ROUNDPIPE 的性能,证明其在不同模型规模下均能实现高训练吞吐量并支持长序列长度。结果表明,ROUNDPIPE 通过减少流水线气泡并利用卸载技术有效管理内存,即使在显存受限的硬件上也能持续优于现有系统。ROUNDPIPE 通过减少流水线气泡并提升通信与计算的重叠度,实现了高于现有系统的训练吞吐量。通过将激活值卸载至 CPU 内存并按需重计算,ROUNDPIPE 支持比基线方法更长的序列长度。ROUNDPIPE 在不同序列长度下均保持稳健性能,随着注意力计算成本增加,吞吐量呈现平滑下降趋势。
研究团队在多种 GPU 服务器(包括消费级与数据中心级硬件)上评估了 ROUNDPIPE,并从吞吐量与最大序列长度维度分析其性能。结果表明,ROUNDPIPE 通过有效管理流水线气泡与通信计算重叠度,实现了高于现有系统的吞吐量并支持更长序列,在内存受限的硬件上优势尤为明显。系统性能在不同模型规模与 GPU 配置下扩展良好,即使序列长度增加仍保持稳健。ROUNDPIPE 相比现有系统实现了更高的训练吞吐量并支持更长序列,尤其在内存受限硬件上表现突出。该系统在广泛序列长度范围内保持稳健性能,吞吐量随注意力成本增长而平滑下降。ROUNDPIPE 显著减少了流水线气泡,并将权重与梯度同步有效与 GPU 计算重叠,从而提升了整体效率。
研究团队在消费级与数据中心级 GPU 上评估了 ROUNDPIPE 的性能,重点考察吞吐量与最大序列长度。结果表明,ROUNDPIPE 相比现有系统实现了更高的吞吐量并支持更长序列,这主要归功于其高效的流水线设计与更少的通信计算气泡。系统在不同序列长度下保持稳健性能,并随模型规模与 GPU 数量增加有效扩展。ROUNDPIPE 在消费级与数据中心 GPU 上,针对多种模型规模均实现了高于现有系统的训练吞吐量。通过高效管理内存与降低通信开销,ROUNDPIPE 支持比其他基线更长的序列。该系统性能在不同序列长度下表现稳健,并随模型规模与 GPU 数量扩展良好。
研究团队在消费级与数据中心级 GPU 服务器上评估了 ROUNDPIPE,验证了其在不同模型规模与硬件配置下的效率与可扩展性。该系统持续优于现有框架,提供更高的训练吞吐量并支持显著更长的序列长度。这些改进源于优化的调度与内存卸载策略,有效最小化了流水线气泡并增强了通信与计算的重叠。因此,ROUNDPIPE 在序列长度增加时仍能保持稳健稳定的性能,即使在内存与带宽受限的硬件上也展现出可靠的扩展能力。