Command Palette
Search for a command to run...
联合演化的策略蒸馏
联合演化的策略蒸馏
Naibin Gu Chenxu Yang Qingyi Si Chuanyu Qin Dingyu Yao Peng Fu Zheng Lin Weiping Wang Nan Duan Jiaqi Wang
摘要
RLVR 与 OPD 已成为后训练阶段的标准范式。本文对这两种范式在将多专家能力整合至单一模型过程中的机制进行了统一分析,并指出它们在能力损失方面的不同表现:混合 RLVR suffers from inter-capability divergence cost(跨能力发散代价),而在“先训练专家、后执行 OPD”的流水线中,尽管避免了发散问题,但由于教师与学生之间存在巨大的行为模式鸿沟,导致未能充分吸收教师的能力。为此,我们提出了协同演化策略蒸馏(Co-Evolving Policy Distillation, CoPD)。该方法鼓励专家并行训练,并在每个专家持续进行的 RLVR 训练过程中引入 OPD,而非等待专家训练完全结束后再执行;同时,各专家互为教师(使 OPD 具备双向性),从而实现协同演化。这一机制使得专家之间的行为模式更加一致,同时在整个过程中保留了充足的互补性知识。实验验证表明,CoPD 成功实现了文本、图像和视频推理能力的“全合一”集成,其性能显著优于混合 RLVR 和 MOPD 等强基线模型,甚至超越了特定领域的专家模型。CoPD 所提供的模型并行训练模式,有望启发一种全新的训练扩展范式。
一句话总结
作者提出了协同演化策略蒸馏(CoPD),这是一种后训练框架,通过并行化专家训练,并将双向策略蒸馏整合到持续的强化学习中,以解决能力间发散和行为模式差距问题。该框架最终实现了全面的文本、图像和视频推理能力,超越了既定基线模型和领域特定专家模型,从而提出了一种新颖的训练扩展范式。
核心贡献
- 提出协同演化策略蒸馏(CoPD)作为统一的后训练框架,通过交替执行 RLVR 与相互策略蒸馏,将多种专家能力整合至单一模型中。
- 训练过程在并行专家优化期间执行双向蒸馏,使模型能够互为教师,在对齐行为模式的同时保留互补知识。
- 在文本、图像和视频推理任务上的实证评估表明,CoPD 成功整合了多模态能力,显著优于混合 RLVR 和 MOPD 基线模型,并超越了领域特定专家模型。
引言
带有可验证奖励的强化学习与 OPD 已成为将专业模型能力整合到统一架构中的标准后训练范式。该方法的重要性在于,它能够实现文本、视觉和视频领域复杂推理任务的高效扩展。然而,现有方法存在固有局限:混合强化学习会带来能力间发散的成本,而顺序 OPD 流水线则因行为模式差距过大,导致学生模型无法充分吸收教师模型的专业知识。作者提出协同演化策略蒸馏以突破这些瓶颈,通过并行执行专家训练,并将蒸馏直接注入各分支持续的强化学习循环中。在主动优化期间将专家模型视为互为教师,该框架在整个训练过程中对齐行为模式并保留互补知识。这种协同演化策略成功将多模态推理能力融合至单一模型中,其性能超越了传统基线模型与独立的领域专家模型。
数据集

- 数据集构成与来源: 提供的节选未列出具体数据集或外部存储库。作者使用两个抽象能力数据集 D1 和 D2 来代表统一策略的不同优化目标。
- 各子集的关键细节: 未提供具体规模、过滤规则或来源元数据。文本将 D1 和 D2 视为理论构造,用于分析独立能力在联合训练期间的交互方式。
- 论文的数据使用方式: 作者利用 D1 和 D2 对比三种训练范式。他们通过在两个数据集的并集上联合优化来评估混合数据 RLVR,以测量梯度冲突;通过孤立训练专家并利用策略内轨迹对其进行蒸馏来评估静态 OPD 流水线;并引入 CoPD 以交替执行特定能力的 RLVR 与跨分支相互 OPD。这些数据集作为总优化信号 X(D1,D2) 发挥作用,各范式均尝试将其转化为实际的能力提升。
- 处理细节: 节选未描述数据裁剪、元数据构建或预处理步骤。重点仍在于梯度动态、师生行为重叠度以及效用函数的数学建模,而非实证数据准备。
方法
作者提出了协同演化策略蒸馏(CoPD),该框架旨在使多个专家分支协同演化,从而允许每个分支探索自身能力,同时持续跨领域转移知识。核心理念是在整个训练过程中交替执行分支特定强化学习与策略内蒸馏(OPD),通过维持分支间的行为接近度来确保知识转移的有效性。该框架以单一基础模型 πθ 为起点,初始化多个具有相同参数的并行学习分支 πθj 和 πθk,每个分支关联一个独立的能力数据集 Dj 和 Dk。训练按交替周期进行,每个周期包含两个阶段:分支特定 RLVR 阶段与相互 OPD 阶段。
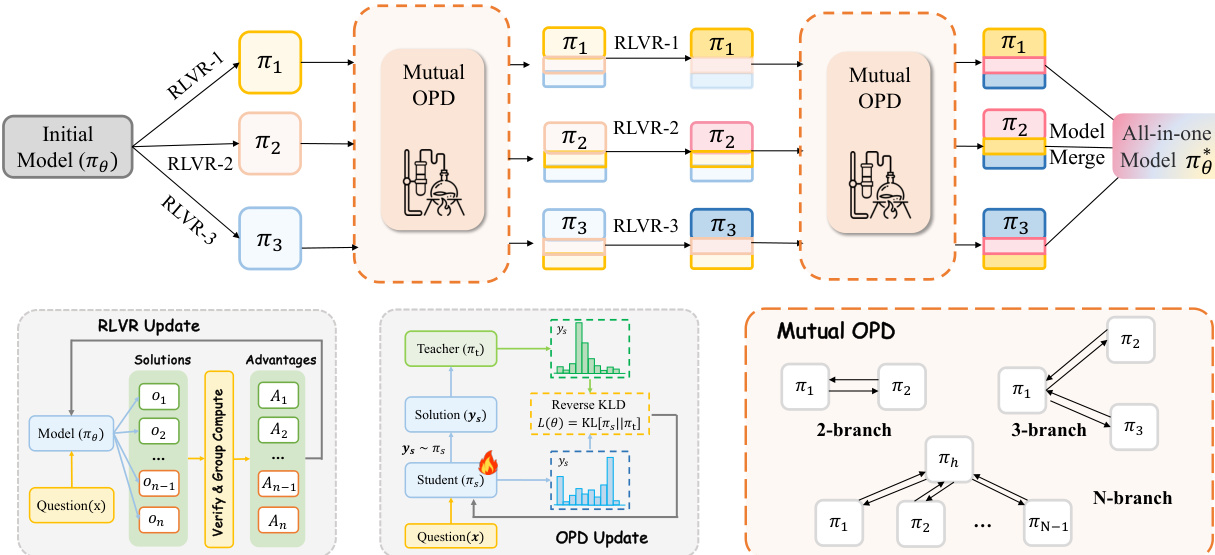
如图所示,该框架图展示了整体流程。初始模型 πθ 被拆分为多个分支,每个分支在其专属数据集上进行 RLVR。经过一系列 RLVR 更新后,分支进入相互 OPD 阶段进行知识交换。此交替过程持续 N 个周期。最后一步将协同演化的分支合并为统一模型 πθ∗,该模型受益于所有分支的综合知识。通过采用中心辐射型拓扑结构,该框架可扩展至两个以上分支,即中心辐射分支与多个辐条分支进行知识交换,如图示。
在分支特定 RLVR 阶段,每个分支独立在其能力数据上执行组相对策略优化(GRPO)以深化专业知识。分支 k 的 RLVR 目标定义为:
LRLVR(k)(θk)=Ex∼Dk[G1i=1∑G∣yi∣1t=1∑∣yi∣min(ρi,t(k)A^iRL,clip(ρi,t(k),1−ϵ,1+ϵ)A^iRL)]其中 A^iRL 和 ρi,t(k) 遵循标准 GRPO 公式。该阶段逐步推动分支走向差异化的能力前沿,形成可用于跨能力转移的知识差距。
在相互 OPD 阶段,每个分支在其他分支的数据上生成策略内轨迹,并接收 token 级监督。这实现了新获取知识在能力间的转移。该过程是对称的,因此两个分支在每一步交替扮演教师和学生角色,持续交换知识。接收分支 j 监督的分支 k 的教师信号定义为:
δi,t(k←j)=logπθj(yi,t(k)∣x′,yi,<t(k))−logπθk(yi,t(k)∣x′,yi,<t(k))跨分支更新的 token 级优势为 A^i,t(k)=βkδi,t(k←j),其中 βk 平衡跨分支蒸馏的相对贡献。关键在于,相互 OPD 期间分支特定 RLVR 不会暂停;相反,两个目标交替执行以更新模型。

交替训练流程总结于算法 1。每个周期 n 包含两个阶段:阶段 I 中,每个分支在其能力数据上执行 SRL 步 GRPO;阶段 II 中,每个分支执行 SOPD 步相互蒸馏。超参数 SRL 和 SOPD 决定了两个阶段之间的节奏。较大的 SRL 允许分支在阶段 I 积累更多差异化的特定能力发现,为后续蒸馏提供更丰富的信号。较大的 SOPD 则会在阶段 II 实现更彻底的知识转移。由于所有分支均从同一基础模型启动,并通过持续的相互蒸馏保持紧密耦合,其参数不会大幅发散。作者利用这一特性,通过跨分支的简单参数合并来获取最终统一模型。
实验
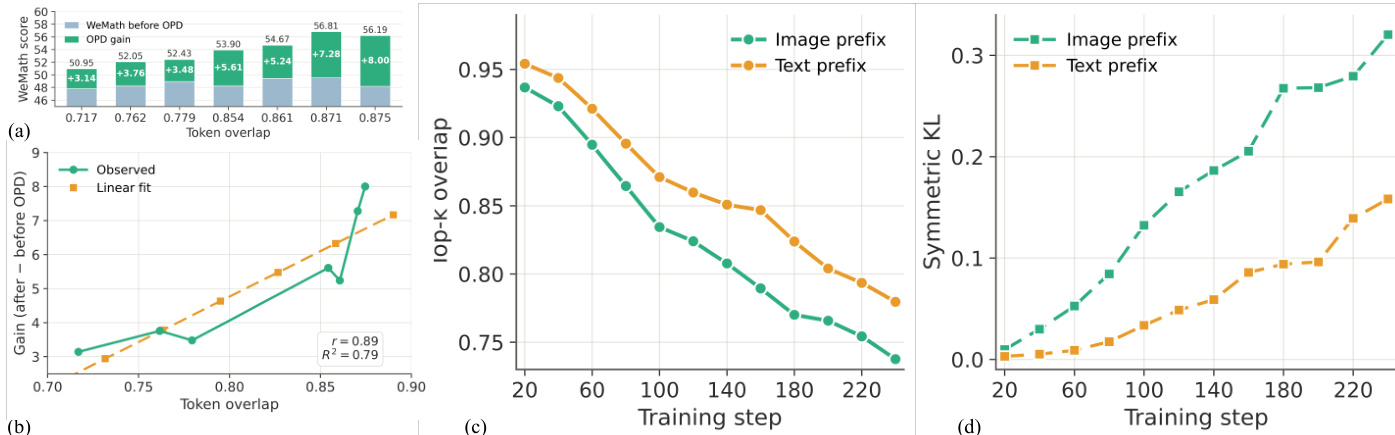
初步研究验证了蒸馏效果随师生行为重叠度的增加而提升,而标准的独立训练会系统性地使专家陷入低重叠状态,严重阻碍知识转移。为克服此局限,CoPD 在文本、图像和视频推理基准上与静态及混合基线进行了对比评估。实验表明,并行的相互蒸馏成功在整个训练过程中维持了最优的行为对齐,使所有领域的能力能够同步增强,避免了静态流水线特有的干扰或传输不完整问题。进一步分析证实,交替执行专业化探索与持续整合对于维持高重叠度并最大化整体模型性能至关重要。
{"summary": "作者提出了一种名为 CoPD 的方法,通过交替探索与相互蒸馏使文本和图像分支协同演化,从而提升多模态推理性能。结果表明,CoPD 在所有基准测试中实现了最佳的整体性能,优于单一专家和静态蒸馏方法,并在整个训练过程中维持了分支间的高行为重叠度。该方法有效平衡了专业化与整合,避免了其他方法中出现的能力发散问题。", "highlights": ["与所有基线相比,CoPD 在图像和文本推理基准上实现了最高的整体性能。", "与表现出逐渐发散趋势的静态方法不同,CoPD 在训练期间维持了分支间的高行为重叠度。", "该方法的有效性归因于交替探索与相互蒸馏,这种机制平衡了专业化与整合。"]
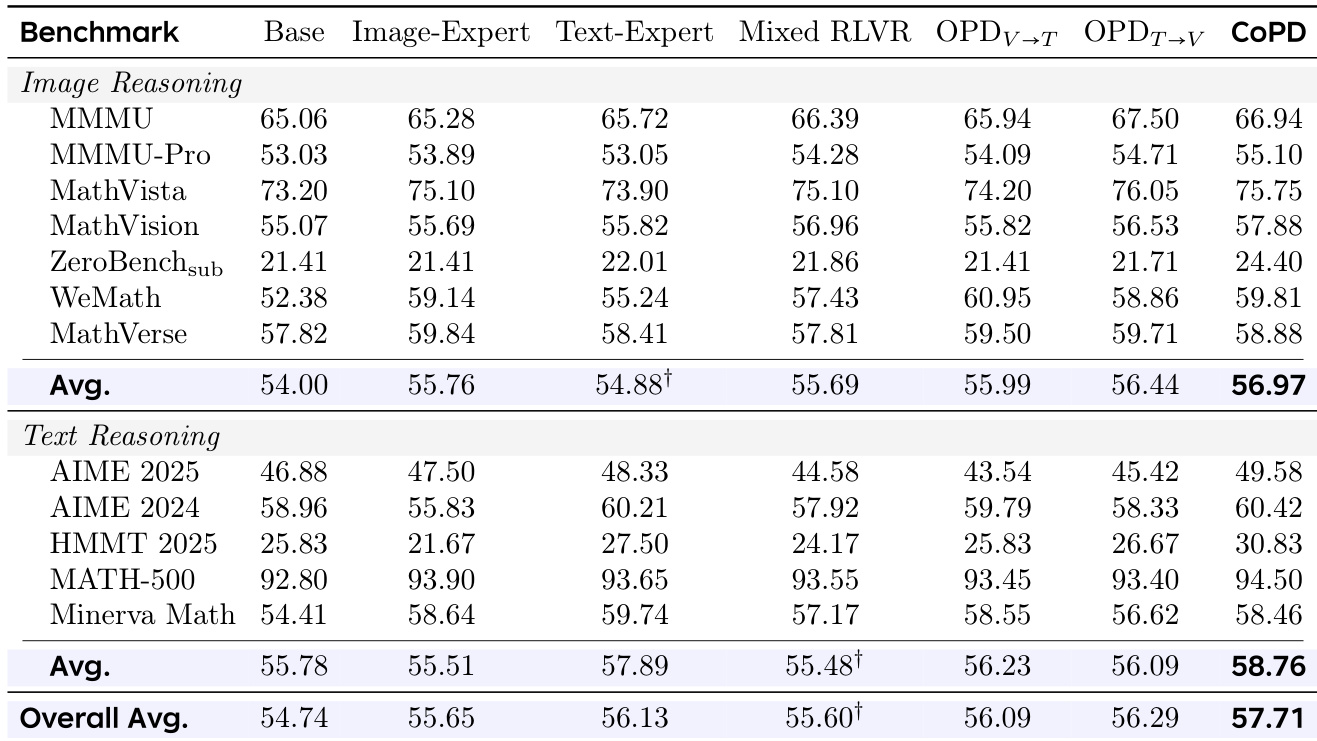
作者在多领域推理任务中将 CoPD 与基线模型进行对比,表明 CoPD 通过在训练期间维持分支间的行为一致性来实现优越性能。结果证明,CoPD 优于静态蒸馏和单分支方法,相互 OPD 与参数合并共同促成了平衡的能力整合。该方法在整个训练过程中保持分支间的高重叠度与低发散性,避免了孤立专家训练中出现的性能下降。与基线模型相比,CoPD 在图像和文本推理基准上取得了最佳的整体性能。相互 OPD 与合并是维持行为一致性和实现平衡能力整合的关键。与经历显著发散的静态方法不同,CoPD 在训练期间维持了高分支重叠度与低发散性。

作者通过实验分析了师生行为重叠度与蒸馏效果之间的关系,结果表明重叠度越高,蒸馏带来的收益越大。他们证明,标准训练方法会导致专家与共享基础模型之间的发散程度不断增加,从而导致蒸馏效率低下,而所提方法通过持续协同演化维持了最优重叠度,并实现了有效的知识转移。蒸馏收益随师生间行为重叠度的提高而增加。标准训练引起专家与基础模型间发散程度的加剧,降低了蒸馏效果。所提方法通过持续协同演化维持高行为重叠度,并实现了有效的相互蒸馏。
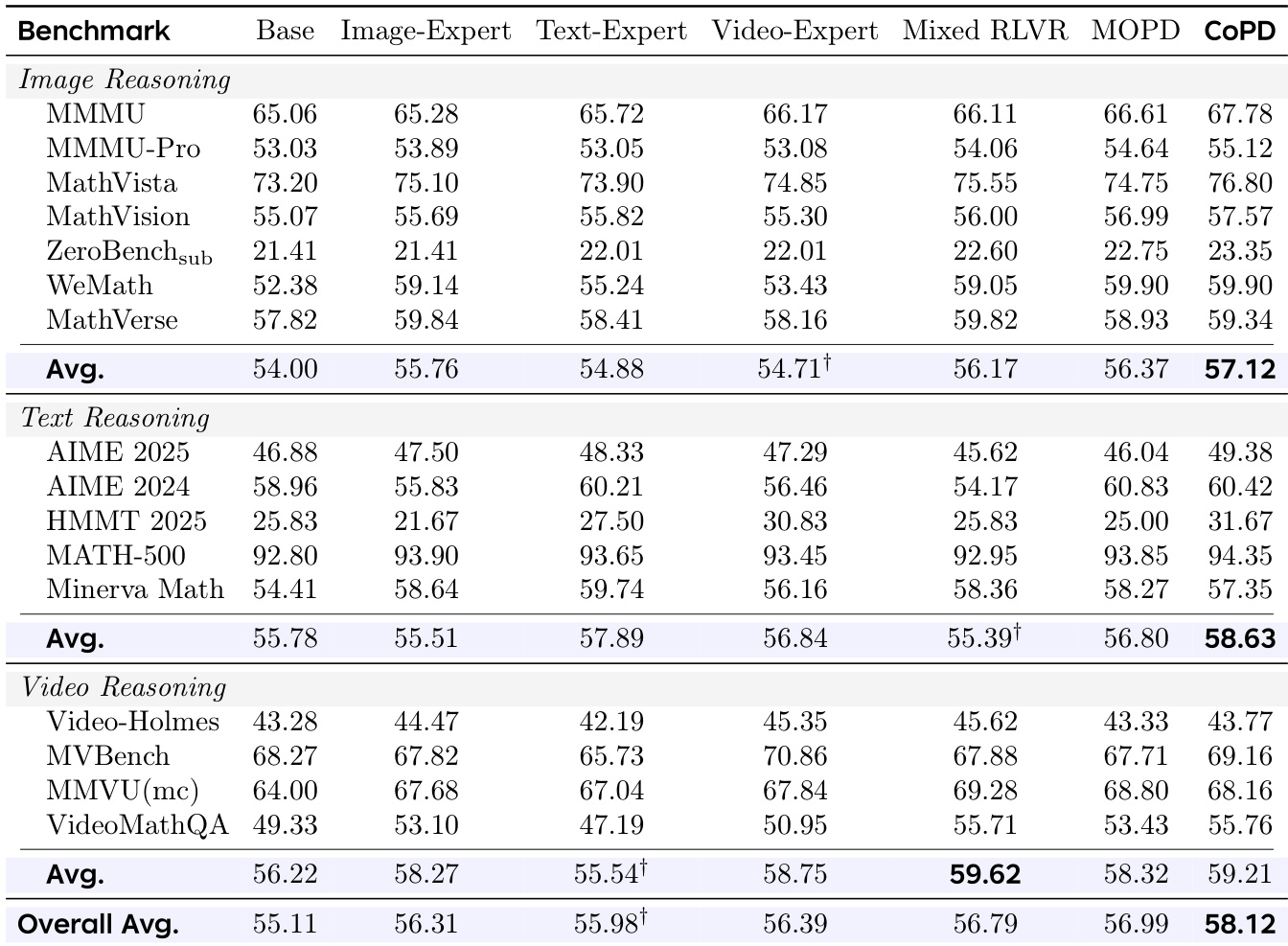
作者通过实验评估了 CoPD 方法在整合多领域推理能力方面的有效性。结果显示,CoPD 通过在训练期间平衡专业化与对齐性,优于包括静态蒸馏和混合训练在内的基线模型。该方法在图像、文本和视频推理中实现了优越性能,且未牺牲单一领域的能力。消融研究证实,相互蒸馏与合并对整体性能提升至关重要。与所有基线相比,CoPD 在图像、文本和视频推理基准上取得了最佳的整体性能。该方法在训练期间维持了分支间的高行为重叠度,防止了静态流水线中观察到的漂移现象。相互蒸馏与合并是实现 CoPD 平衡且整合能力的核心组件。
作者通过实验评估了一种协同演化蒸馏方法,表明在训练期间维持师生模型间的行为重叠度能够改善知识转移。结果证明,所提方法通过在训练全程维持更高的分支重叠度与更低的发散性,优于基线模型,从而在图像和文本推理任务上取得更好的整体性能。与重叠度随时间下降的基线模型不同,所提方法在训练期间维持了分支间的高行为重叠度。该方法通过交替训练阶段平衡专业化与整合,在图像和文本推理上均实现了优越性能。结果表明,双向相互蒸馏对达到最优性能必不可少,协同演化使能力超越了单分支模型所能达到的水平。
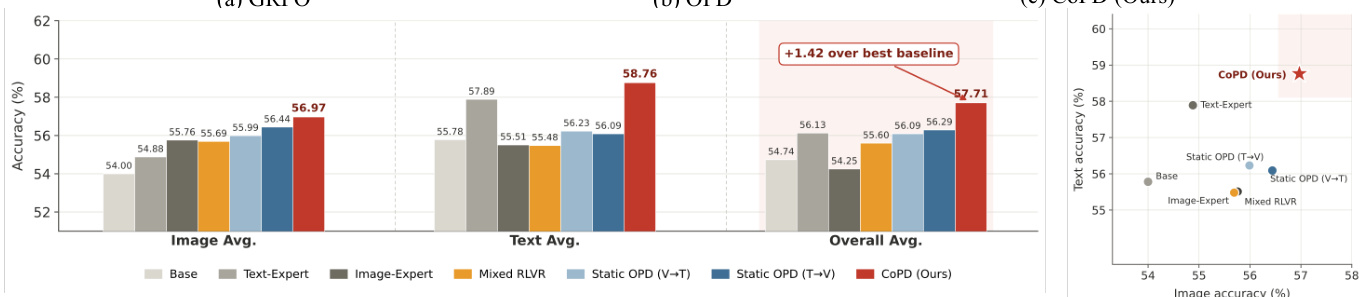
实验在多个推理基准上将 CoPD 与静态及单分支基线进行对比,以验证持续协同演化对知识转移的影响。初步评估证实,该方法维持了分支间的高行为重叠度,有效防止了孤立训练流水线典型的能力发散。后续分析表明,交替探索与相互蒸馏成功平衡了专业化与整合,并直接关联到蒸馏效率的提升。总体而言,结果确立了同步多模态开发始终优于传统方法,因其实现了稳健且稳定的知识共享。