Command Palette
Search for a command to run...
扭转局势:扩散大型语言模型的跨架构知识蒸馏
扭转局势:扩散大型语言模型的跨架构知识蒸馏
Gongbo Zhang Wen Wang Ye Tian Li Yuan
摘要
扩散大型语言模型(dLLMs)具备并行解码和双向上下文建模能力,但最先进的 dLLMs 为了实现具有竞争力的性能,通常需要数十亿参数。尽管现有的 dLLMs 蒸馏方法能够在单一架构内减少推理步数,但均未能解决跨架构知识转移的问题,而在跨架构场景中,教师模型与学生模型在架构、注意力机制以及 tokenizer 方面均存在差异。本文提出了 TIDE,这是首个针对跨架构 dLLM 蒸馏的框架,包含三个模块化组件:(1)TIDAL,它联合调节训练过程与扩散时间步(diffusion timestep)上的蒸馏强度,以应对教师模型噪声依赖性带来的可靠性变化;(2)CompDemo,通过互补掩码分割(complementary mask splitting)丰富教师模型的上下文,从而改善重度掩码情况下的预测效果;(3)Reverse CALM,一种跨 tokenizer 的目标函数,通过反转分块级别(chunk-level)的似然匹配,产生有界梯度并实现双端噪声过滤。通过将 80 亿参数的稠密模型和 160 亿参数的混合专家(MoE)模型作为教师,经由两条异构流水线蒸馏至 6 亿参数的学生模型,该方法在八个基准测试上的平均表现比基线方法高出 1.53 分。在代码生成任务中取得了显著的提升,HumanEval 得分达到 48.78,而自回归(AR)基线模型的得分为 32.3。
一句话总结
本文提出了 TIDE,这是首个面向扩散大语言模型的跨架构蒸馏框架。该框架融合了 TIDAL 时间步调制、COMPDEMO 互补掩码分割以及 Reverse CALM 跨分词器目标,将 8B 密集模型和 16B MoE 教师模型蒸馏为 0.6B 学生模型,在八个基准测试上平均提升 1.53 分,并在 HumanEval 上达到 48.78 分,相较于 32.3 分的自回归基线表现显著。
核心贡献
- 本文引入了 TIDE,这是首个用于扩散大语言模型跨架构蒸馏的框架,实现了在架构、注意力机制和分词器不同的教师与学生模型之间的知识迁移。
- 该框架集成了三个模块化组件:TIDAL 根据时间步依赖的教师可靠性动态调节蒸馏强度;COMPDEMO 通过互补上下文分割在重度掩码下增强预测;Reverse CALM 提供了一种跨分词器目标,通过反转块级似然匹配来生成有界梯度并实现两端噪声过滤。
- 将 8B 和 16B 参数的教师模型蒸馏至 0.6B 学生模型,在八个基准测试上平均提升 1.53 分,其中 HumanEval 得分为 48.78,而自回归基线为 32.3。
引言
扩散语言模型已成为自回归架构的一种灵活替代方案,但其迅速演变为编码器、解码器和因果变体,给高效模型部署带来了碎片化挑战。现有的扩散模型蒸馏方法主要局限于仅压缩推理步骤的同架构设置,而成熟的自回归技术未能考虑扩散模型特有的动态特性,例如时间步依赖的教师可靠性以及同时生成的掩码 token。为弥补这一差距,本文提出 TIDE,这是一个跨架构蒸馏框架,可在根本不同的扩散模型之间迁移知识。研究团队借鉴插值原理与块级似然匹配机制来处理架构与分词器不匹配的问题,从而在异构扩散语言模型设计中实现稳健且高效的知识迁移。
数据集
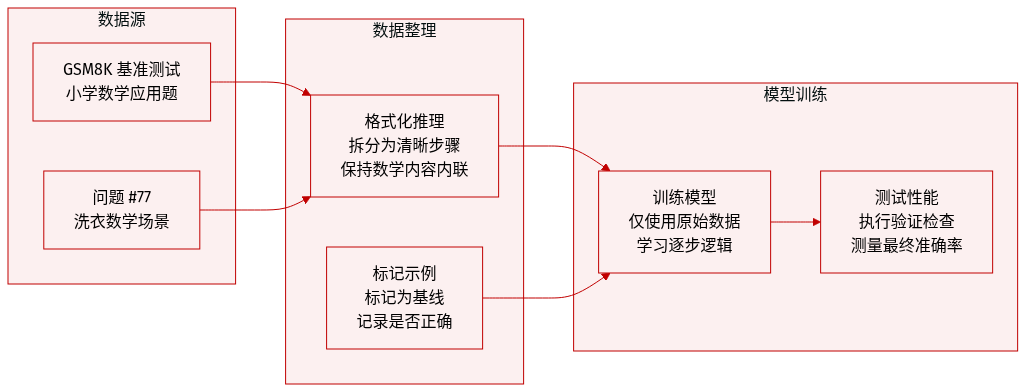
- 数据集构成与来源:研究团队采用 GSM8K 基准测试,该数据集包含一系列小学级别的数学应用题,旨在评估序列推理能力。
- 子集详情:提供的示例突出显示了一个具体实例(问题 #77),涉及包含洗衣数量的多步算术场景。该样本被明确归类为无蒸馏的基线样本,并被标记为错误。
- 数据使用与处理:研究团队将这些示例纳入无蒸馏基线设置中,以建立性能基准。数据经过处理以包含序列推理轨迹,使模型能够基于逐步数学逻辑进行评估或训练。
- 元数据与格式:每个条目均标注有问题标识符、指示实验条件的描述性标题以及正确性标签。推理步骤被格式化为带有内联数学表达式的顺序句子,以支持透明评估。
方法
TIDE 框架旨在解决扩散大语言模型(dLLMs)跨架构知识蒸馏的挑战,其中教师与学生模型在架构、注意力机制和分词器上存在差异。该方法整体由三个模块化组件构成,专门用于应对跨异构架构蒸馏的独特挑战。框架围绕一个核心训练循环构建,用于处理带噪声的输入序列,在此过程中学生模型学习利用真实标签和教师预测来推断掩码位置上的 clean tokens。学生模型是一个参数量为 0.6B 的块扩散语言模型(BD3LM),旨在从两个不同的教师模型中蒸馏知识:一个 16B MoE dLLM(LLaDA2.0-mini)和一个 8B 密集因果 dLLM(WeDLM-8B-Instruct),两者在基础结构和 tokenization 方案上均有显著差异。
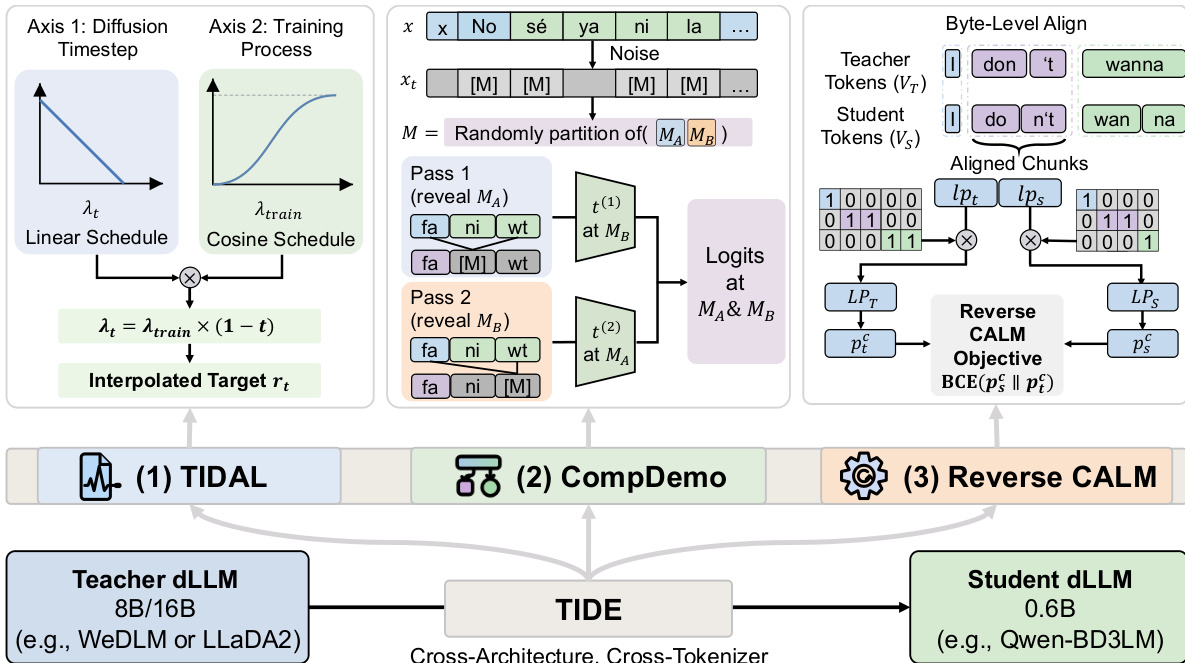
第一个组件 TIDAL(时间迭代双轴 Lambda 调制)旨在解决扩散时间步上教师信号可靠性变化的问题。在扩散模型中,教师的预测置信度高度依赖于噪声水平:在低噪声水平(t ≈ 0)下,教师观察到近乎完整的序列并产生可靠预测;而在高噪声水平(t ≈ 1)下,由于大量掩码,预测变得不可靠。TIDAL 引入了一种双轴调度机制,沿扩散时间步和训练进度联合调节蒸馏强度。蒸馏强度由插值系数 λt 参数化,定义为 λt=λtrain×(1−t),其中 t 为当前扩散时间步。这确保了在高噪声水平下蒸馏信号被降权,防止学生模型学习不可靠的教师输出。基础系数 λtrain 本身在归一化训练进度 p 上遵循余弦调度,从较低值(λinit)开始以避免训练初期表示崩溃,并逐渐增加至较高值(λmax)以在后期阶段鼓励全面的教师监督。插值目标 rt 由学生与教师 logits 组合而成,TIDAL 损失计算为该目标与学生 softmax 输出之间的 KL 散度。
第二个组件 COMPDEMO(互补演示条件去噪)解决了重度掩码下教师信号退化的问题。标准蒸馏为学生和教师提供相同的掩码输入,这可能导致预测效果不佳。COMPDEMO 通过将掩码位置划分为两个互补子集 MA 和 MB 来丰富教师的上下文。随后教师进行两次前向传播:第一次传播中,MA 位置的 tokens 作为上下文被揭示,而 MB 保持掩码状态;第二次传播中角色互换。这使得教师能够利用额外上下文在每个掩码位置生成更准确的预测,从而提升蒸馏信号的质量。两次传播的 logits 被合并,形成掩码位置的最终教师输出。
第三个组件 Reverse CALM 专为稳健的跨分词器对齐而设计。传统的 CALM 目标通过匹配块级似然,当学生为教师认为高概率的块分配较低的初始概率时,会遭遇梯度不稳定性。Reverse CALM 通过反转该目标来解决问题,即将教师的概率作为损失梯度中的固定系数,该系数有界且可防止梯度爆炸。这创造了一种稳定且自选择的训练信号,使学生自然聚焦于教师的高概率模式。梯度在两端进一步过滤:对齐较差的块(教师概率接近 0.5)系数为零,学生概率较低的块对梯度贡献微小,从而抑制噪声。这种两端过滤机制提供了一种更可靠且高效的方式,在不同 tokenization 方案下将学生输出与教师对齐。
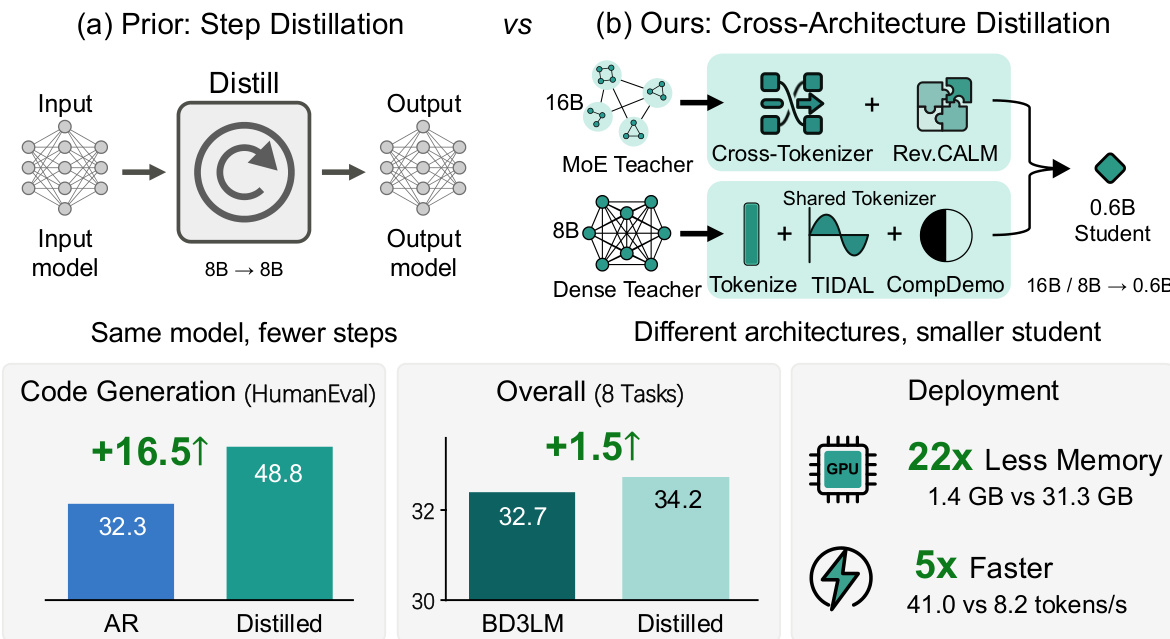
框架架构设计为模块化且高效。学生模型 Qwen3-0.6B-BD3LM 使用交叉熵损失与三个 TIDE 组件的组合进行训练。训练过程利用多样化的 SFT 数据集,共进行 10 个 epoch。整体流程实现了从大型异构教师到更小、更高效学生的有效知识迁移,在多个基准测试上取得显著性能提升,同时降低了内存占用与推理延迟。
实验
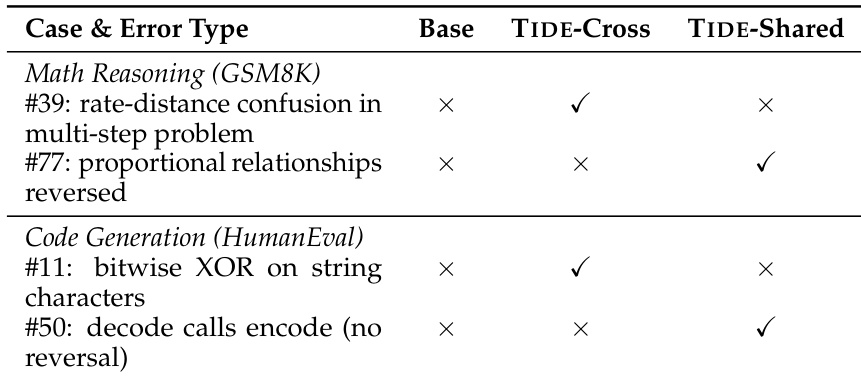
评估在两条蒸馏流水线中测试了 TIDE 框架,将大型扩散语言模型压缩至紧凑的学生架构,利用基准测试、组件消融实验和效率测量来验证该方法。基准结果证实跨架构知识迁移是有效的,每条流水线均受益于针对词汇不匹配或精确 token 对齐量身定制的策略。消融与案例研究实验验证了时间调度与上下文丰富化对稳定学习至关重要,使蒸馏模型能够继承教师特定的推理模式,并纠正基线在算术与代码生成中的失败。最终,实验表明 TIDE 通过显著降低计算开销并带来相对于自回归模型的实质性质量提升,成功实现了高效部署。
研究团队在两条不同的流水线中评估了扩散语言模型的蒸馏框架,一条使用共享分词器,另一条采用跨分词器设置,两者均面向较小的学生模型。结果显示,该框架提升了非蒸馏基线的性能,每条流水线均受益于针对其架构量身定制的特定策略。与同规模的自回归基线相比,蒸馏模型在代码生成任务上取得了更高的分数。该蒸馏框架在两条不同的流水线中提升了性能,每条流水线均受益于针对其架构的策略。蒸馏模型在代码生成任务上得分高于同规模自回归基线。该框架证明跨架构蒸馏是有效的,并凭借显著的内存与速度提升实现了实际部署。
研究团队评估了扩散语言模型的蒸馏框架,比较了不同基准和教师模型下的性能。蒸馏学生模型始终优于非蒸馏基线,在代码生成任务上改善显著。每条蒸馏流水线均受益于针对其特定架构和分词器设置量身定制的独立策略。蒸馏模型在所有基准测试中得分均高于非蒸馏基线,其中代码生成任务的提升最为显著。跨分词器流水线受益于采用反向 KL 散度的策略,而共享分词器流水线在渐进式课程与丰富教师信号下表现更佳。蒸馏带来了性能的大幅提升,尤其在代码生成等结构化任务上,同时保持了推理效率。
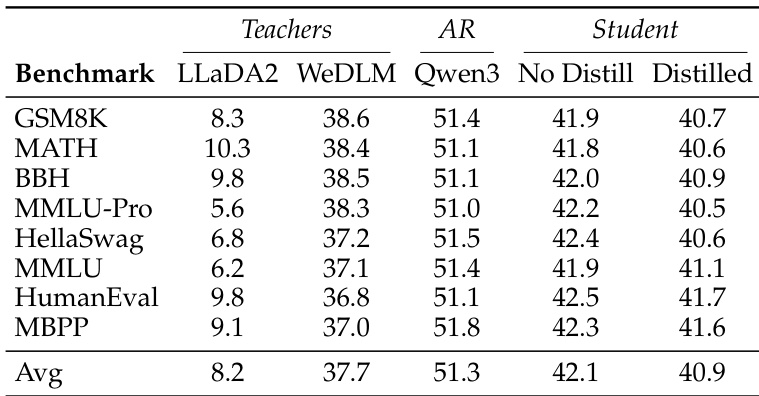
研究团队评估了扩散语言模型的跨架构蒸馏框架,比较了两条不同的流水线:一条使用共享分词器,另一条采用跨分词器方法。结果表明,该框架提升了各基准测试的性能,每条流水线均受益于针对其特定架构的独立策略。蒸馏模型显著优于基线模型,尤其在代码生成任务中,同时通过降低内存占用与延迟维持了高效推理。该框架提升了各基准测试的平均性能,其中跨分词器流水线取得了最高的总分。每条流水线均受益于独立策略,共享分词器流水线偏好渐进式课程,而跨分词器流水线则受益于有界梯度与噪声过滤。蒸馏模型在代码生成方面表现卓越,在 HumanEval 和 MBPP 基准测试中超越了同规模的自回归模型。
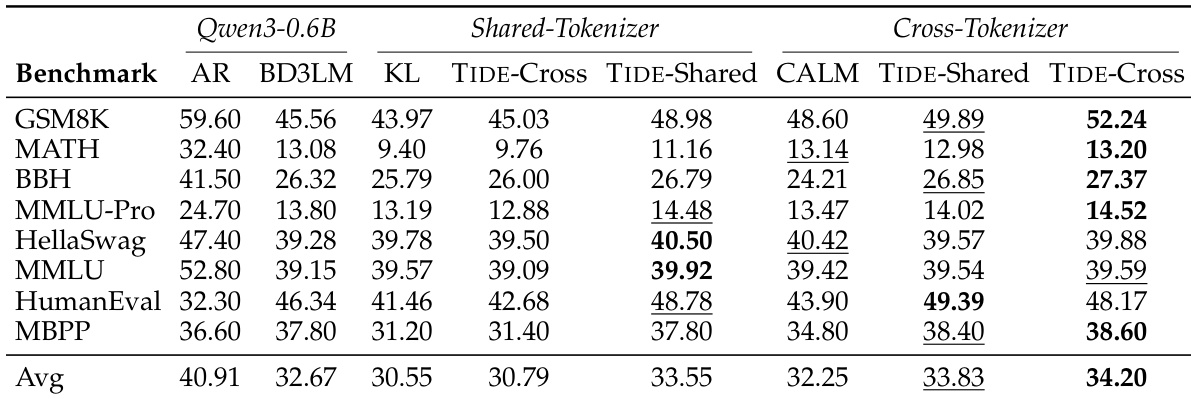
研究团队在两条不同的流水线中评估了扩散语言模型的蒸馏框架,证明跨架构蒸馏能够提升相对于非蒸馏基线的性能。该框架集成了模块化组件,以应对时间、空间与词汇挑战,每条流水线均受益于各自的最优独立策略。蒸馏模型在代码生成任务上展现出强劲性能,超越了同规模的自回归模型。结果凸显了不同蒸馏方法可解决不同类型的错误,且每位教师模型均传授了独特的知识。跨架构蒸馏在多个基准测试中提升了相对于非蒸馏基线的性能。每条流水线偏好不同的策略,跨分词器流水线受益于 Reverse CALM,而共享分词器流水线则受益于 TIDAL 与 COMPDEMO。蒸馏模型在代码生成方面表现出色,成功解决了基线模型未能处理的具体错误。
研究团队将蒸馏模型及其基线与更大的教师模型进行对比,证明蒸馏在保持具有竞争力的推理速度的同时降低了内存使用与延迟。与基线相比,蒸馏模型实现了更低的内存消耗,但推理速度较慢,不过代码生成任务的显著性能提升使这一权衡合理化。结果表明,蒸馏模型在效率与特定任务能力上均优于未蒸馏版本。与大型教师模型相比,蒸馏降低了峰值内存使用与推理延迟。蒸馏模型取得了具有竞争力的推理速度,相较于未蒸馏基线仅轻微降低吞吐量。与同规模自回归基线相比,蒸馏模型在代码生成任务上展现出更优越的性能。
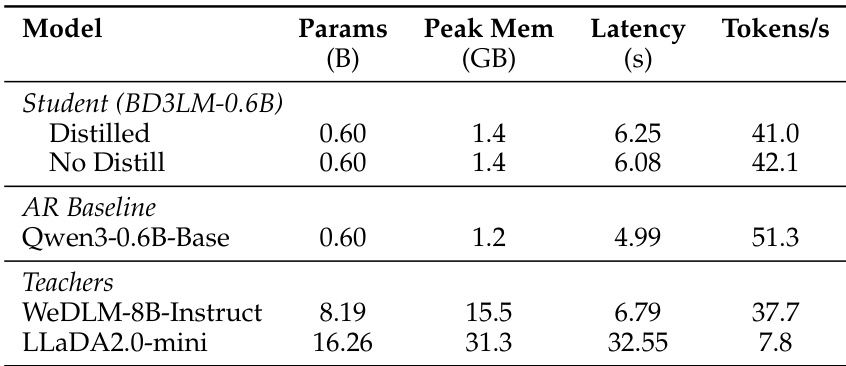
研究团队在共享与跨分词器流水线中评估了扩散语言模型的跨架构蒸馏框架,将蒸馏学生模型与未蒸馏基线及同规模自回归模型进行对比。实验验证了特定架构的训练策略能够有效迁移知识,使框架能够在多样化基准测试中持续提升性能。定性来看,蒸馏模型在代码生成等结构化任务中展现出更强的能力,成功解决了基线模型无法处理错误模式。此外,该方法在保持具有竞争力吞吐量的同时大幅降低了内存消耗与推理延迟,为高效模型部署展示了明确的实际优势。