Command Palette
Search for a command to run...
RADIO-ViPE:动态环境中开放词汇语义SLAM的在线紧耦合多模态融合
RADIO-ViPE:动态环境中开放词汇语义SLAM的在线紧耦合多模态融合
Zaid Nasser Mikhail Iumanov Tianhao Li Maxim Popov Jaafar Mahmoud Sergey Kolyubin
摘要
我们推出了 RADIO-ViPE(Reduce All Domains Into One -- Video Pose Engine,将全领域归一化——视频姿态引擎),这是一种在线语义 SLAM(同步定位与地图构建)系统,能够在动态环境中实现感知几何结构的开放词汇 grounding(空间定位/指代),将任意自然语言查询与局部化的 3D 区域及物体进行关联。与现有需要校准后、带有位姿信息的 RGB-D 输入的方法不同,RADIO-ViPE 可直接处理原始单目 RGB 视频流,无需预先知道相机内参、深度传感器信息或位姿初始化状态。该系统将来自聚合型基础模型(如 RADIO)的多模态嵌入(涵盖视觉和语言领域)与几何场景信息紧密结合。这种耦合贯穿于初始化、优化及因子图连接阶段,从而提升多模态地图的一致性。优化过程采用了自适应鲁棒核函数,旨在同时处理主动移动的物体以及由 agent(智能体)导致的场景元素位移(例如在自中心会话期间重新摆放的家具)。实验结果表明,在动态 TUM-RGBD 基准测试中,RADIO-ViPE 取得了最先进(state-of-the-art)的结果,同时在与依赖校准数据和静态场景假设的离线开放词汇方法相比时,也保持了具有竞争力的性能。RADIO-ViPE 填补了实际部署中的关键空白,为自主机器人和不受限制的野外视频流提供了健壮的开放词汇语义 grounding。项目页面:https://be2rlab.github.io/radio_vipe
一句话总结
RADIO-ViPE 是一种在线语义 SLAM 系统,它利用自适应鲁棒核将基础模型的视觉-语言嵌入与几何场景信息紧密耦合,从而能够从未经标定内参的原始单目视频中,在动态环境中实现开放词汇定位,并在动态 TUM-RGBD 基准测试中取得最先进的结果。
核心贡献
- 本文提出 RADIO-ViPE,一种在线语义 SLAM 系统,通过将自然语言查询与动态环境中的局部 3D 区域相关联,实现几何感知的开放词汇定位。
- 该框架处理未经标定内参、深度传感器或位姿初始化的原始单目 RGB 视频,并利用自适应鲁棒核将视觉-语言嵌入与几何数据紧密耦合,以应对移动物体和场景重排。
- 在动态 TUM-RGBD 基准测试上的实验表明,该系统取得了最先进的性能,同时在面对依赖标定数据和静态场景假设的离线开放词汇方法时,仍保持具有竞争力的结果。
引言
通用机器人需要将自由形式的语言查询映射到 3D 几何地图上,以便在非结构化环境中执行灵活的语言驱动任务。现有方案存在关键权衡:几何 SLAM 管道缺乏语义感知能力或依赖封闭的对象分类体系,而离线开放词汇方法则忽略实时里程计并假设场景静态。实时开放词汇 SLAM 系统往往无法处理动态干扰,且许多方法需要标定输入或深度传感器,限制了其在受控环境外的部署。本文引入 RADIO-ViPE,一种在线语义 SLAM 系统,该系统接收原始、未标定的单目 RGB 视频,在不依赖深度先验或位姿初始化的情况下生成几何感知的开放词汇地图。该方法利用聚合型基础模型,在密集光束法平差框架内将视觉-语言嵌入与几何约束紧密耦合。系统采用时间一致的自适应鲁棒核,联合优化重投影误差与语义差异,以过滤移动 agents 和准静态场景变化。这种统一方法使得在动态环境中实现稳健的实时语言定位成为可能,推动了自主机器人在非受限场景中的部署。
方法
RADIO-ViPE 是一种统一的在线语义 SLAM 系统,旨在从未经标定的单目 RGB 视频流中运行,在滑动窗口因子图框架内集成相机位姿优化、深度估计和密集高级视觉嵌入。如系统概览图所示,整体流水线运行频率约为 8–10 FPS,并利用自适应核增强动态环境下的鲁棒性。系统从相机初始化开始,使用 GeoCalib 从均匀采样的帧中引导内参,无需标定靶或已知相机模型,随后在光束法平差过程中进行联合优化。关键帧的选择由通过加权密集光流估计的相对运动驱动,超过运动阈值的帧被指定为关键帧并添加到因子图 G=(V,E) 中,其中 V 代表关键帧,E 表示成对连接。
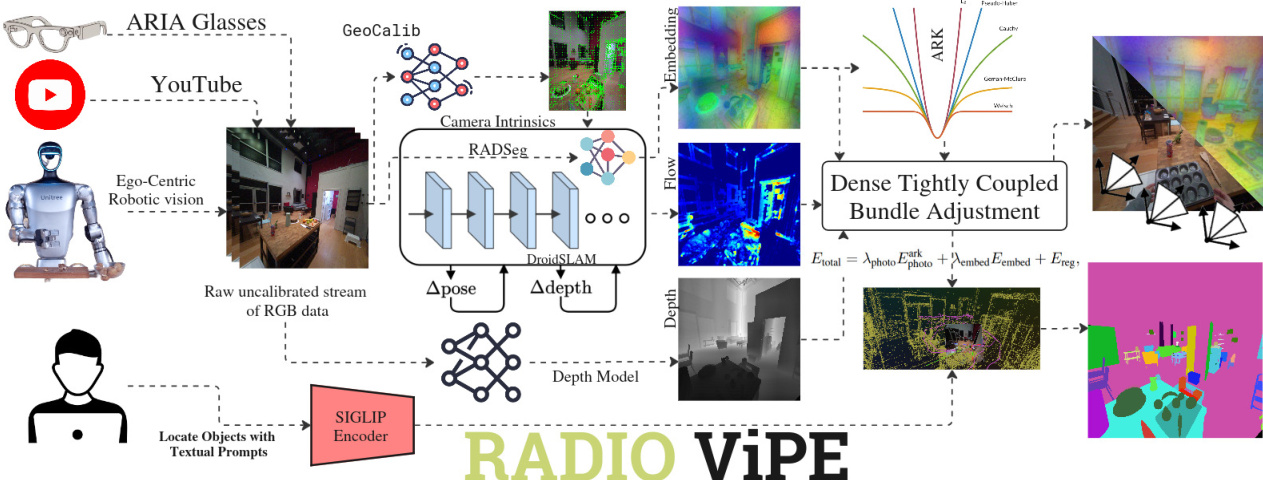
使用 RADSeg 模型为每个关键帧提取密集多模态嵌入,该模型在 SigLIP 嵌入空间内生成与语言对齐的特征。这些嵌入通过双线性插值上采样至 (H/8,W/8) 分辨率,并使用主成分分析 (PCA) 压缩至 D=256 维,确保可扩展性和高效的内存管理。该 PCA 压缩直接应用于编码器特征空间,保留了空间推理至关重要的结构完整性。PCA 分量在光束法平差的初始化阶段计算,在收集到足够数量的关键帧缓冲区后执行,以确保映射的稳健性和代表性。
使用单目基础深度模型为每个关键帧估计度量深度图,为保持数值稳定性转换为逆深度(视差),并下采样 8 倍以匹配光流分辨率。为了提高无纹理区域光流先验的鲁棒性,引入了源自密集 RADIO 特征的语义对应项。对于帧 i 中的每个像素 u,计算 PCA 压缩后的 Radio 嵌入 Zi(u)∈RK 与目标帧像素嵌入之间的余弦相似度,从而生成密集语义流场 Ωsem(u)。该语义先验通过基于像素级置信度的混合与光度流先验融合:
Ωprior(u):=βΩprior(u)+(1−β)Ωsem(u).混合权重 β 平衡光度流置信度与峰值语义相似度得分。在构建光度流项的相关体积时,混合初始化替换 Ωprior,同时保持流网络架构不变。
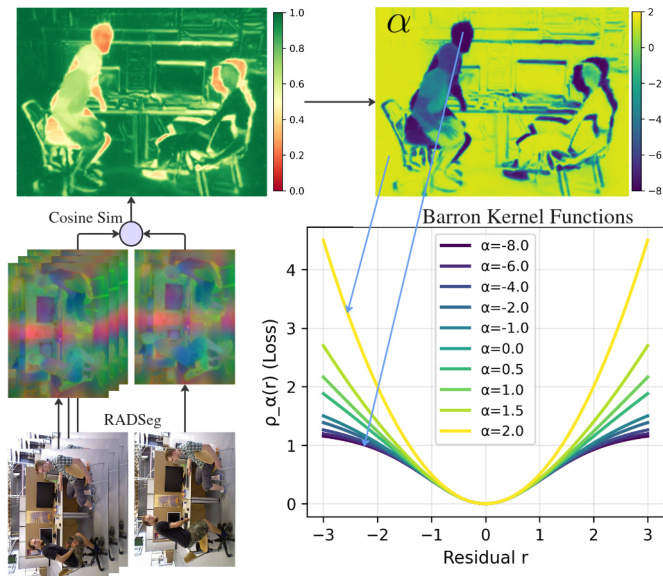
光束法平差通过最小化视觉-语言-几何能量函数来优化相机内参、位姿和 3D 场景结构。因子图连接通过基于嵌入的共视性在几何邻近性之外进行增强:通过对其 RADSeg 嵌入进行平均池化并对结果进行 ℓ2 归一化,获得每个关键帧的全局描述符。新进入的关键帧通过单次余弦相似度查询与非近期关键帧(排除最近的 τ 帧)进行匹配;超过阈值 η 的配对由双向边连接。优化过程包含一个密集光度流项,通过光流约束强制执行几何一致性。对于每条边 (i,j),帧 i 中的像素 u 投影到帧 j 的方式为:
μij=Πj(TjTi−1∘Πi−1(u, di(u))),其中 Πq 和 Πq−1 表示在内参 Kq 下的投影与逆投影函数。光流网络预测残差密集流场 Ωij∈RH×W×2 和像素级置信度权重 w(u),先验流估计 Ωijprior=μij−u 用于初始化相关体积。光度项为:
Ephoto=u∑w(u)⋅Ωijprior−Ωij(u)2.引入了一种新颖的嵌入相似度项,以在几何约束下强制执行跨视图特征对齐。对于每条边 (i,j),源像素 u∈Ii 被投影到目标帧以定位其对应像素 v=Pi,j(u)∈Ij,目标嵌入通过双线性插值恢复。对两个嵌入进行 ℓ2 归一化后,计算余弦相似度:
csij(u)=∣∣Zi(u)∣∣⋅ ∣∣Z^j(Pi,i(u))∣∣Zi(u)⊤Z^j(Pi,j(u)),嵌入残差被转化为光度形式:
rembed(u)=λembed2(1−csij(u)),其中 λembed=2。完整的嵌入相似度项为:
Eembed=u∑w(u)⋅rembed2(u).非关键帧位姿估计通过每条非关键帧到其两个最近关键帧的单向边连接实现,位姿通过光度对齐恢复,绕过逐帧深度估计并支持并行估计。开放词汇定位通过解码 3D 点的压缩 Radio 特征并将其投影到 SigLip 潜在空间以与文本查询匹配来实现。如最终可视化所示,该系统的设计使其能够在动态环境中实现实时性能与鲁棒性。
实验
在 TUM-RGBD 数据集上评估所提流水线以检验其在动态环境中的鲁棒性,并在 Replica 数据集上验证其实时开放词汇语义分割能力。实验表明,嵌入误差项和自适应鲁棒核能有效补偿运动引起的跟踪误差,在显著降低计算资源需求的同时,优于现有的动态 SLAM 方法。此外,该系统成功构建了语义感知地图,无需依赖标定位姿、深度输入或点云,其精度水平与利用真实几何监督的方法相当。总体而言,该方法在同步定位与语义映射方面被证明具有极高的效率和鲁棒性,尽管目前在对复杂背景中的结构元素进行分割时仍显示出一定的局限性。
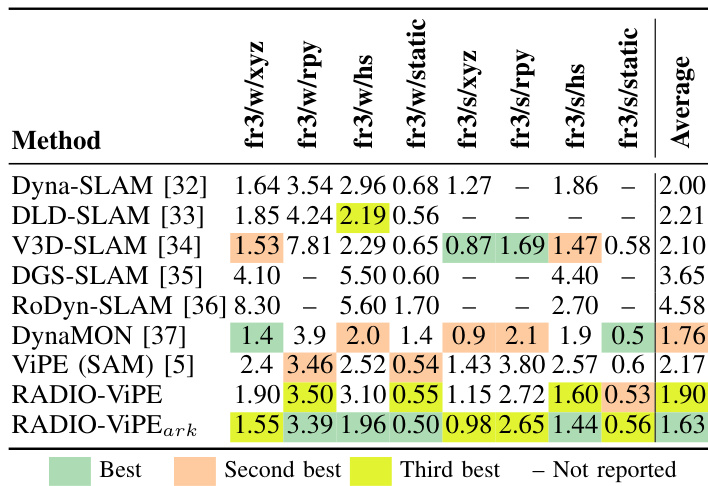
本文使用 TUM-RGBD 数据集评估其方法 RADIO-ViPE 的 SLAM 性能,并与几种现有方案进行比较。结果表明,RADIO-ViPE 在多项指标上实现了具有竞争力或更优的性能,特别是在平均轨迹精度方面,并在特定配置下优于其他方法。在 TUM-RGBD 数据集上,与其他方法相比,RADIO-ViPE 在平均轨迹精度方面取得了顶尖性能。该方法在各种配置下均表现出强劲的竞争力,在动态和静态场景中均有显著成果。在平均轨迹精度等关键指标上,RADIO-ViPE 优于包括 ViPE 和 DGS-SLAM 在内的几种现有 SLAM 方法。
本文在语义分割和 SLAM 任务上评估 RADIO-ViPE,并在 Replica 和 TUM-RGBD 数据集上将其与现有方法进行比较。结果显示,RADIO-ViPE 在这两项任务中均取得了具有竞争力的性能,尤其是在语义分割方面,它无需深度、位姿或标定输入等几何监督即可跻身顶级方法之列。在 Replica 数据集的语义分割任务中,RADIO-ViPE 取得了前三名的性能,且不依赖真实深度、位姿或标定输入。在 TUM-RGBD 序列的平均 ATE 方面,RADIO-ViPE 优于现有的动态 SLAM 方法。与其他方法不同,RADIO-ViPE 以在线模式运行,并支持开放词汇分割,无需已知相机参数或预定义类别。
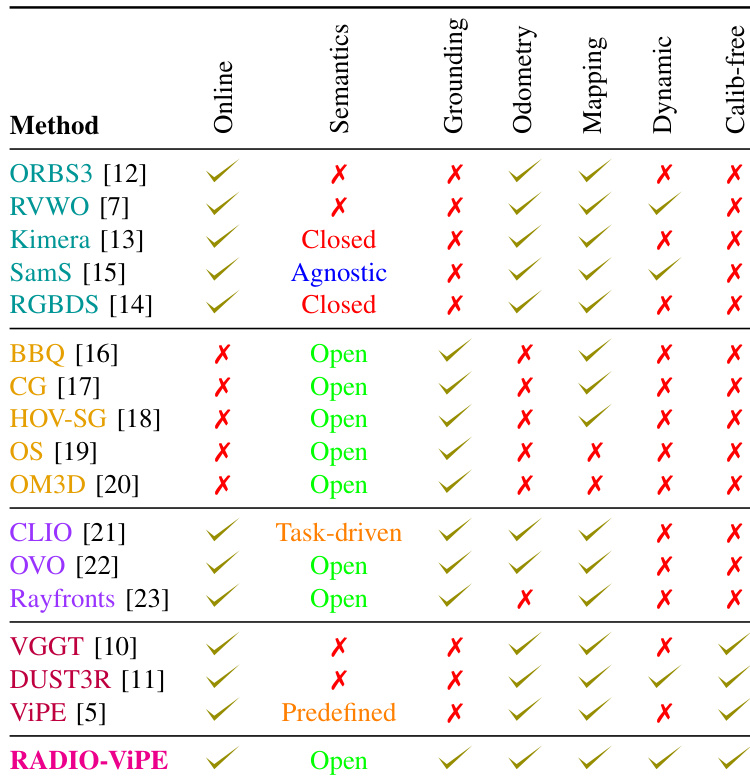
本文在语义分割和 SLAM 任务上评估所提方法 RADIO-ViPE,并与几种基线方案进行比较。结果表明,RADIO-ViPE 与现有方法相比取得了具有竞争力的性能,特别是在准确性和实时运行方面,且运行时无需标定、深度或位姿输入。即使去除真实深度、位姿和标定,该方法仍能保持高精度,表明其在实际场景中具有极强的鲁棒性和有效性。在语义分割基准测试中,RADIO-ViPE 取得了前三名的性能,且无需已知相机参数、位姿或深度输入。在去除真实深度、位姿和标定时,该方法的高精度仅出现微小下降,展现了出色的鲁棒性。与大多数对比方法不同,RADIO-ViPE 支持在线推理,且无需标定、深度或位姿输入即可运行。
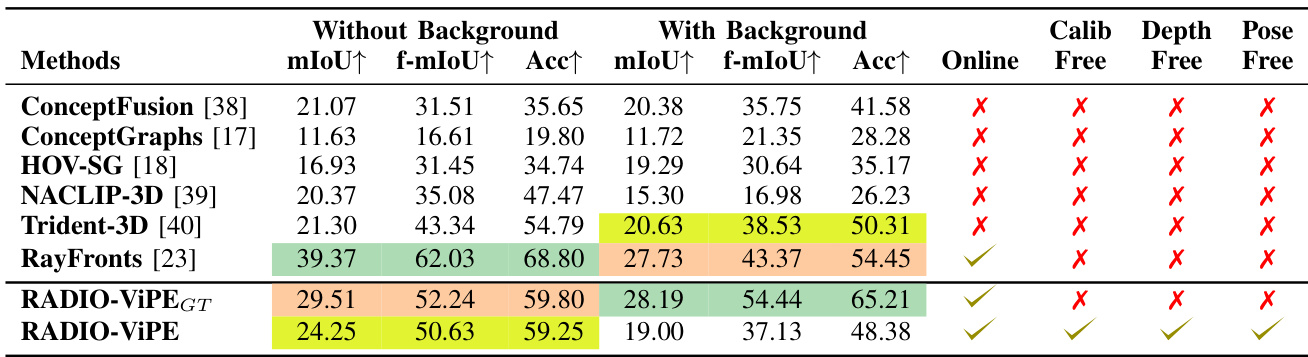
本文在 TUM-RGBD 和 Replica 数据集上评估 RADIO-ViPE,以检验其同步定位与建图能力及语义分割能力,并将该方法与几种成熟的基线进行基准测试。这些实验验证了该方法在完全无需真实深度、相机位姿或内参标定输入的情况下,仍能在静态和动态环境中保持稳健且具有竞争力的精度。结果证明,RADIO-ViPE 能够提供可靠的实时性能和开放词汇分割,确立了一种实用的免标定框架,摆脱了对显式几何监督或预定义对象类别的依赖。