Command Palette
Search for a command to run...
DV-World:在真实世界场景中基准测试数据可视化智能体
请按照以上标准,使用中文回答!!
DV-World:在真实世界场景中基准测试数据可视化智能体 请按照以上标准,使用中文回答!!
摘要
现实世界的数据可视化(DV)需要原生环境感知、跨平台演进以及主动的意图对齐。然而,现有的基准测试往往受限于代码沙箱环境,仅包含单一语言的任务创建,且假设用户意图完美无缺。为了填补这些空白,我们引入了 DV-World,这是一个包含 260 个任务的基准测试,旨在评估 agent 在数据可视化真实专业生命周期中的表现。DV-World 涵盖三个领域:DV-Sheet,用于原生电子表格操作,包括图表和仪表板的创建以及诊断性修复;DV-Evolution,涉及适应和重构参考视觉工件,以使其适应不同编程范式下的新数据;以及 DV-Interact,用于通过与模拟真实场景中模糊需求的用户模拟器进行交互,实现主动的意图对齐。我们的混合评估框架结合了表格值对齐(Table-value Alignment)以确保数值精度,并采用基于标准的“多模态大模型即法官”(MLLM-as-a-Judge)方法来进行语义与视觉的评估。实验表明,当前最先进(SOTA)模型的整体表现低于 50%,这暴露出其在应对现实世界数据可视化复杂挑战方面的关键缺陷。DV-World 提供了一个真实的测试平台,以引导开发朝着企业工作流所需的通用专业知识方向前进。我们的数据和代码已在以下网址提供:https://github.com/DA-Open/DV-World{this project page}。
一句话总结
DV-World 是一个包含 260 个任务的基准测试,旨在评估数据可视化 Agent 在电子表格操作、跨平台适配以及主动意图对齐方面的表现。该基准通过混合评估框架实现,该框架结合 Table-value Alignment 以确保数值精度,并采用带评分标准的 MLLM-as-a-Judge 进行语义与视觉评估。
核心贡献
- DV-World 提出了一个包含 260 个任务的基准测试,用于评估数据可视化 Agent 在原生电子表格操作(DV-Sheet)、跨范式代码演进(DV-Evolution)以及主动用户交互(DV-Interact)方面的能力。该基准测试涵盖迭代更新、诊断性修复与模糊意图处理,旨在反映超越静态复现的真实专业工作流。
- 混合评估框架将用于保证数值精度的 Table-value Alignment 协议与由专家标注评分标准指导的分层 MLLM-as-a-Judge 系统相结合。该方法在超越传统代码验证的同时,评估数据保真度与视觉语义。
- 实验结果建立了针对前沿模型的性能基线,显示当前 Agent 的整体准确率不足 50%。这些发现揭示了现有模型在管理原生对象模型、迁移可视化逻辑以及对齐迭代用户反馈方面存在关键缺陷。
引言
由大语言模型驱动的数据可视化 Agent 正在改变抽象数据集向可执行决策转化的方式,但其实际应用需要与真实软件生态系统和动态用户工作流无缝集成。以往的评估基准受限于理想化的纯代码沙盒,忽略了原生电子表格的约束条件,仅关注一次性图表生成,并假设提示词完全明确,未考虑现实世界中的模糊性。DV-World 是一个综合性基准测试,评估可视化 Agent 在原生电子表格操作、跨框架逻辑迭代演进以及基于对话的主动澄清方面的表现。该测试平台结合精确的数据对齐协议与专家指导的多模态评判的混合评估框架,旨在揭示关键性能差距,并引导 Agent 开发向具备全生命周期感知能力的健壮可视化系统发展。
数据集
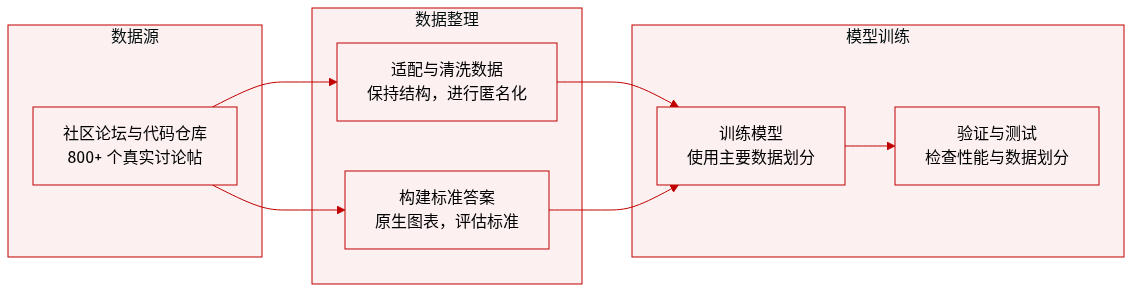
数据集构成与来源 DV-World 是一个包含 260 个任务的基准测试,旨在评估数据可视化 Agent 在真实专业工作流中的表现。该数据集从 ExcelForum、Kaggle、Chandoo.org、Excelguru 和 MrExcel 等社区收集的 800 多个问题讨论中精心整理而成。该集合优先采用真实场景,收集电子表格、表格、绘图代码和参考可视化图表,以捕捉自然用户语言、故障排除行为以及多样化的分析工作流。
子集详情
- DV-Sheet(160 个任务): 专注于原生电子表格数据定位,工作簿平均包含 36.53 列和 11,583 行。
- DVSheet-Crea(80 个任务): 评估图表与仪表板创建。任务按复杂度划分为直接可视化、需提取数据与多表推理。
- DVSheet-Fix(50 个任务): 评估诊断性修复。采用受控的反向注入策略,由专家在已验证的健康工作簿中引入数据绑定失败、坐标轴缩放问题及类型不匹配等错误。该子集包含 74.5% 的噪声数据。
- DVSheet-Dash(30 个任务): 测试使用混合参考文件的仪表板构建。指令遵循三种用户原型:高管指令、技术规格与临时查询。
- DV-Evolution(80 个任务): 衡量在 Python、ECharts、Vega-Lite、D3.js 和 Plotly.js 等五种框架中的视觉优化能力。任务涉及使用保持模式的偏移与模式突变等对抗性数据扰动来适配原子子图。
- DV-Interact(80 个任务): 评估通过多轮对话实现主动意图对齐的能力。在基础查询中注入指标、时间与聚合维度的模糊性。由九个 LLM 驱动的用户模拟器提供反馈,分为导师、普通用户与高难度客户三类。
数据处理与使用 DV-World 严格作为评估基准使用。采用结合 Table-value Alignment 与多维评分标准 MLLM-as-a-Judge 的混合评估框架,分别用于数值精度与语义视觉评估。
- 适配协议: 所有数据均经过三步处理流程:保留结构以维持合并单元格与不规则布局,值扰动以在保持统计分布的同时重新归一化数值,以及元数据匿名化以替换可识别实体。
- 标准答案构建: 针对 DV-Sheet,使用 openpyxl 运行 Python 脚本生成具有明确数据绑定的原生 Excel 图表对象作为标准答案,确保可追溯性。逆向工程被用于恢复 Fix 任务的健康文件。
- DV-Evolution 处理: 严格执行无硬编码策略,要求解决方案必须从输入数据中动态推导视觉元素。同时执行原子子图隔离,将复杂复合图表分解为聚焦的编辑单元。
- DV-Interact 处理: 通过记录问答模式与修正策略构建交互轨迹。定义隐藏的真实意图与反应规则以控制模拟器响应,确保与最优代码解决方案对齐。
- 元数据: 构建内容包含用于数值验证的基准表格、用于视觉参考的基准图表,以及涵盖保真度、逻辑性、美观度与专业性的二元标准任务特定评分表。
方法
该框架解决三大核心可视化挑战:原生电子表格制图、可视化演进与交互式可视化。整体架构整合了针对各任务领域定制的专业 Agent 与评估协议。针对聚焦原生电子表格制图的 DV-Sheet,系统支持三个子任务:DVSheet-Crea(Agent 生成具有动态范围绑定的新图表)、DVSheet-Fix(诊断并修复缺陷图表)以及 DVSheet-Dash(Agent 通过排列多个图表与表格构建专业仪表板)。Agent 在沙盒环境中运行,使用 openpyxl 和 xlwings 等电子表格操作库,确保所有输出均为原生 Excel 图表对象。该流程包含迭代观察、提议、修订与执行,Agent 借助工具调用直接修改工作簿状态。框架实施严格约束以防止使用外部绘图库,并强制要求所有图表在电子表格内创建为可编辑、可交互的对象。

针对 DV-Evol,任务涉及通过逻辑合成将视觉资产转化为可执行代码,其模型为将参考图像、新数据集与修改要求转化为功能绘图代码及对应数据表。该过程由逻辑合成流水线支持,对参考图像的视觉语义进行逆向工程,并输出 Python、Vega-Lite 或 D3.js 等目标语言代码。评估涵盖三个维度:完整性(确保数据迁移正确与代码功能正常)、一致性(衡量设计语义与视觉结构的保留程度)以及美观度(评估输出的专业质量与可读性)。框架支持多种可视化库,并强制执行摄入、归一化、渲染与序列化的确定性流程,同时利用 matplotlib 的面向对象 API 实现细粒度控制。
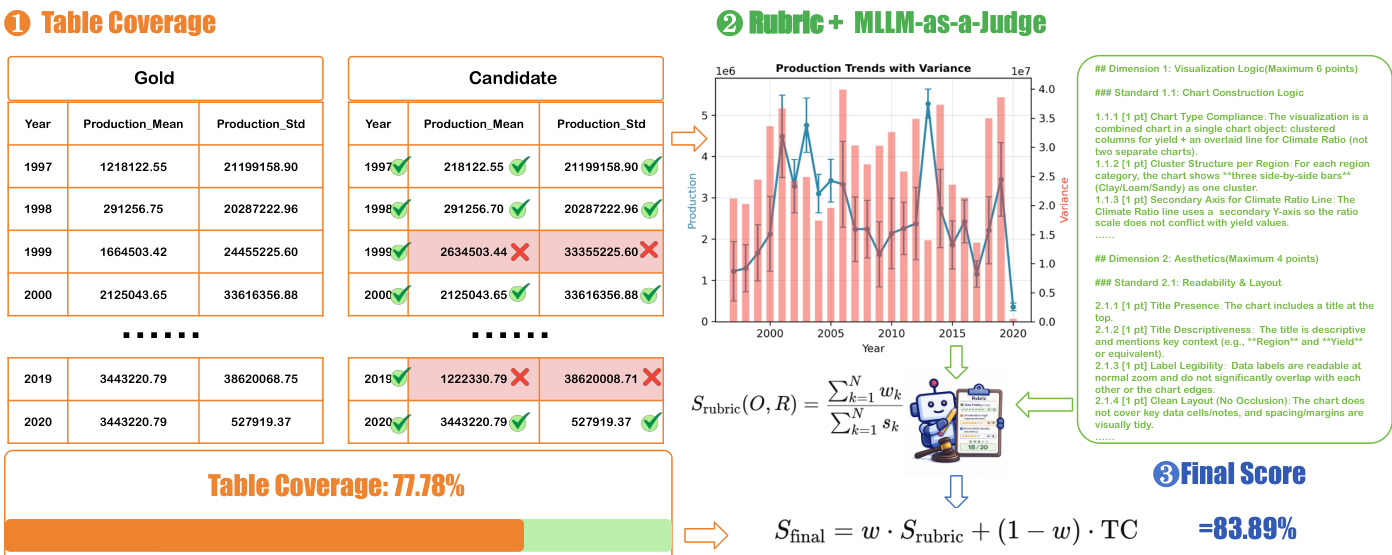
DV-Inter 聚焦多轮交互式可视化,Agent 从模糊的自然语言查询中生成可视化代码。该任务评估交互能力,要求 Agent 识别缺失信息、提出简明且具信息量的问题,并迭代完善规格说明。框架采用双阶段用户模拟器以确保推理真实性并防止信息泄露。模拟器包含网关模块,用于过滤不当请求(如实现代码或内部架构细节),以及生成器,基于用户潜在意图提供基于事实的非技术性回复。交互成功率通过计算澄清请求、拒绝与成功轮次等指标得出,旨在鼓励主动且高效的对话。评估涵盖交互、准确性与美观度三个维度,评分基于将任务分解为需求与子标准的结构化评分表。
实验
评估采用混合框架,结合专家整理的定性评分表与定量数据保真度检查,以评估前沿语言模型在三个独立可视化领域的表现。DV-Sheet 验证揭示了精确数据定位与错误修正方面持续存在的缺陷,Agent 频繁生成结构合理但缺乏数值准确性或专业布局标准的图表。DV-Evol 测试凸显了跨框架适配方面的重大瓶颈,代码复杂度的增加持续导致语义迁移与布局一致性下降。最后,DV-Inter 实验暴露了主动推理与多轮对齐方面的根本性弱点,表明模型在解决模糊用户意图时难以避免未经证实的假设或认知执行断层,这共同凸显了加强数据验证与迭代查询能力的必要性。
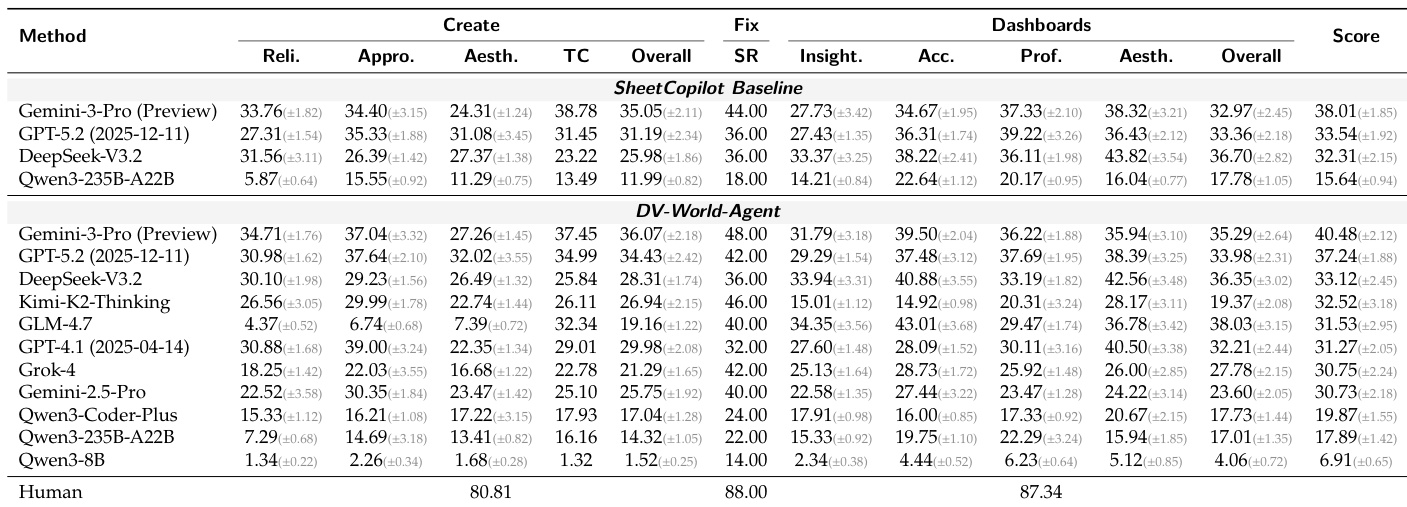
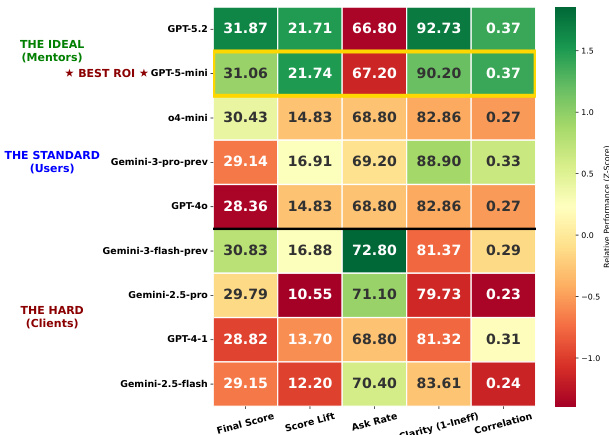
实验在涵盖创建、修复与仪表板生成的数据可视化任务上评估了多种模型。结果显示,即使表现最佳的模型也难以达到人类水平。该基准测试凸显了数据准确性、视觉保真度与任务执行方面持续存在的挑战,尤其在需要多步推理与交互对齐的复杂场景中。不同任务类型的性能差异显著,最先进模型在特定领域得分最高,但仍低于人类基线。顶级模型在特定任务中得分较高,但整体表现持续落后于人类基准。数据准确性与视觉保真度在所有任务与模型类型中仍是主要难题。交互式与复杂仪表板任务展现出最大的性能差距,表明多步推理与专业设计仍存在困难。
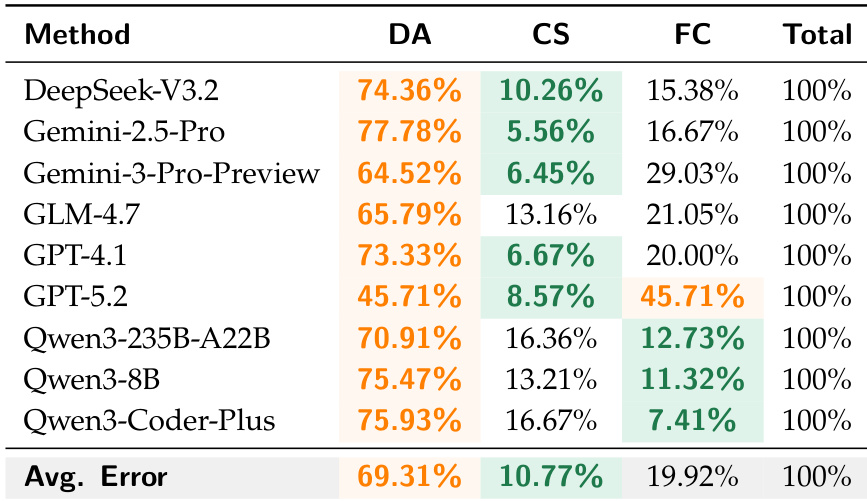
表格对比了不同方法在三项评估指标(DA、CS 与 FC)上的表现,每项方法的总分均为 100%。结果凸显了各指标间性能差异,部分方法在 DA 上得分较高,另一些则在 CS 或 FC 上表现更优。表格同时提供了所有方法的平均错误率,以反映整体性能水平。各方法在 DA、CS 与 FC 指标上表现各异,无单一方法在所有领域均占优势。所有方法的平均错误率分别为:DA 69.31%、CS 10.77%、FC 19.92%。GPT-5.2 在 FC 上取得最高分 45.71%,而 DeepSeek-V3.2 在 DA 上得分最高,为 74.36%。
研究分析了交互策略对 Agent 性能的影响,重点考察主动澄清如何影响任务质量与总体得分。结果表明,有效澄清率较高的模型性能更佳,而依赖无效或高频交互却未带来改进的模型则出现收益递减现象。交互频率与质量的关系在不同模型间差异显著,部分模型因针对性提问而受益,另一些则因查询质量差而受噪声干扰。有效澄清显著提升任务质量,模型在提出相关问题时成功率更高。高频交互并不能保证性能提升,部分模型因无效或冗余查询导致性能下降。交互质量与最终得分的相关性各不相同,表明策略性使用澄清机制比单纯增加交互次数更为重要。
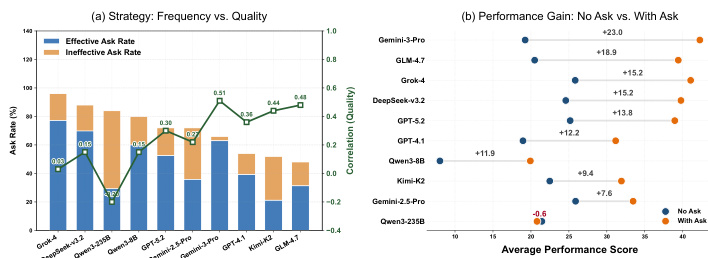
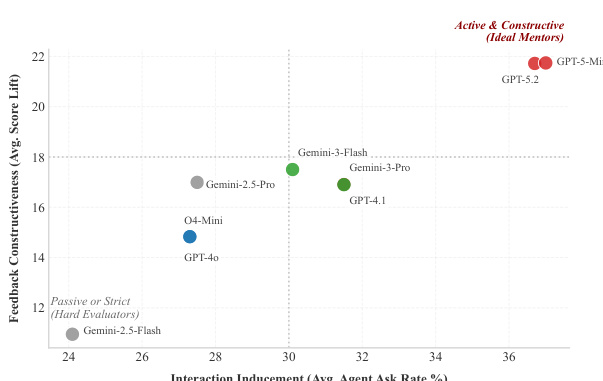
图表展示了不同模型的交互诱导与反馈建设性之间的关系,显示 Agent 提问率较高的模型往往能实现更大的分数提升。GPT-5.2 与 Gemini-3-Flash 位于右上象限,表明其交互频率高且反馈建设性强;Gemini-2.5-Flash 与 GPT-4.0 位于左下象限,反映其交互与反馈指标较低。较高交互率的模型通常能实现更大的分数提升。GPT-5.2 与 Gemini-3-Flash 表现出高交互与高反馈建设性。Gemini-2.5-Flash 与 GPT-4.0 则呈现低交互与低反馈指标。
实验在涵盖基于电子表格的图表创建、演进与交互优化等多项任务上评估了数据可视化 Agent。结果显示,即使表现最佳的模型在错误修正、精准数据绑定与一致性的可视化演进方面仍面临困难,模型与人类基准之间存在性能差距。评估框架结合基于评分表的评判与定量指标,以评估视觉质量与数据保真度。顶级模型在视觉质量与数据保真度上得分较高,但仍不及人类基准。不同任务的性能差异显著,图表演进与交互对齐构成主要挑战。该评估框架展现出良好的鲁棒性,在不同参数设置下模型排名保持稳定。
评估采用结合评分表与定量指标的框架,在涵盖创建、错误修正与交互式仪表板生成的数据可视化任务上检验了多种 AI 模型。主实验验证了顶级模型在复杂场景中持续落后于人类基准,凸显了数据准确性与视觉保真度方面持续存在的困难。对 Agent 交互的次级分析证实,主动澄清能显著提升任务质量,表明针对性提问优于高频但无效的沟通。综合结果表明,推进自动化可视化发展需优先关注策略性反馈机制与多步推理,而非单纯追求交互数量。