Command Palette
Search for a command to run...
通过再生进行优化:扩展修改空间可提升统一多模态模型中的图像优化效果
通过再生进行优化:扩展修改空间可提升统一多模态模型中的图像优化效果
Jiayi Guo Linqing Wang Jiangshan Wang Yang Yue Zeyu Liu Zhiyuan Zhao Qinglin Lu Gao Huang Chunyu Wang
摘要
统一多模态模型(Unified Multimodal Models, UMMs)在单一框架内集成了视觉理解与生成能力。在文生图(Text-to-Image, T2I)任务中,这种统一能力使得 UMMs 能够在初步生成后对输出进行优化,从而有望提升性能的上限。目前基于 UMMs 的优化方法主要遵循“通过编辑进行优化”(Refinement-via-Editing, RvE)范式,即 UMMs 生成编辑指令,以修改未对齐区域,同时保留已对齐的内容。然而,编辑指令往往只能粗略地描述提示词与图像之间的未对齐情况,导致优化不完整。此外,尽管像素级保留对于编辑操作是必要的,但它不必要地限制了优化的有效修改空间。为解决这些局限性,我们提出了“通过再生进行优化”(Refinement-via-Regeneration, RvR)框架,将优化问题重新定义为条件图像再生,而非编辑操作。RvR 不依赖编辑指令并强制严格的内容保留,而是基于目标提示词和初始图像的语义 token 来再生图像,从而实现更完整的语义对齐,并提供更大的修改空间。大量实验证明了 RvR 的有效性:Geneval 得分从 0.78 提升至 0.91,DPGBench 从 84.02 提升至 87.21,UniGenBench++ 从 61.53 提升至 77.41。
一句话总结
作者提出了再生式优化(Refinement via Regeneration, RvR)框架,该框架面向统一多模态模型,将优化任务重新定义为基于目标提示词与初始图像 semantic tokens 的条件再生过程。该方法摒弃了粗糙的编辑指令与严格的像素级保留策略,从而扩展了修改空间,并将 Geneval、DPGBench 和 UniGenBench++ 的得分分别从 0.78 提升至 0.91、84.02 提升至 87.21、61.53 提升至 77.41。
核心贡献
- 提出再生式优化(RvR)框架,将文生图优化任务重新定义为条件图像再生,而非依赖现有“通过编辑进行优化”范式中粗糙的编辑指令。
- 以目标提示词与初始图像的 semantic tokens 作为生成条件,同时摒弃严格的像素级保留约束,从而扩展修改空间以实现更完整的语义对齐。
- 在多个基准测试中展现出显著的性能提升,Geneval 得分从 0.78 提升至 0.91,DPGBench 从 84.02 提升至 87.21,UniGenBench++ 从 61.53 提升至 77.41。
引言
统一多模态模型融合了视觉理解与图像生成能力,使文生图系统能够通过分析提示词与图像之间的不匹配问题来优化输出结果。该能力对于提升复杂场景下的对齐效果至关重要,但现有的优化策略主要依赖“通过编辑进行优化”范式,即生成指令以修改特定区域并强制实施严格的像素级保留。该方法存在固有局限:编辑指令通常只能对语义差距提供粗略描述,导致修正不完整;而僵化的内容保留策略会不必要地限制修改空间,阻碍必要的结构调整。作者提出了再生式优化(RvR)框架,将优化任务重新定义为条件图像再生而非编辑。RvR 以目标提示词与初始图像的 semantic tokens 作为生成条件,彻底摒弃了编辑指令与像素级一致性约束,从而扩展了有效的修改空间以实现更完整的语义对齐。该方法采用基于独立生成样本与语义 ViT 表示的训练方案,优先关注语义修正而非外观保留,在多个基准测试中取得了显著的性能提升。
数据集
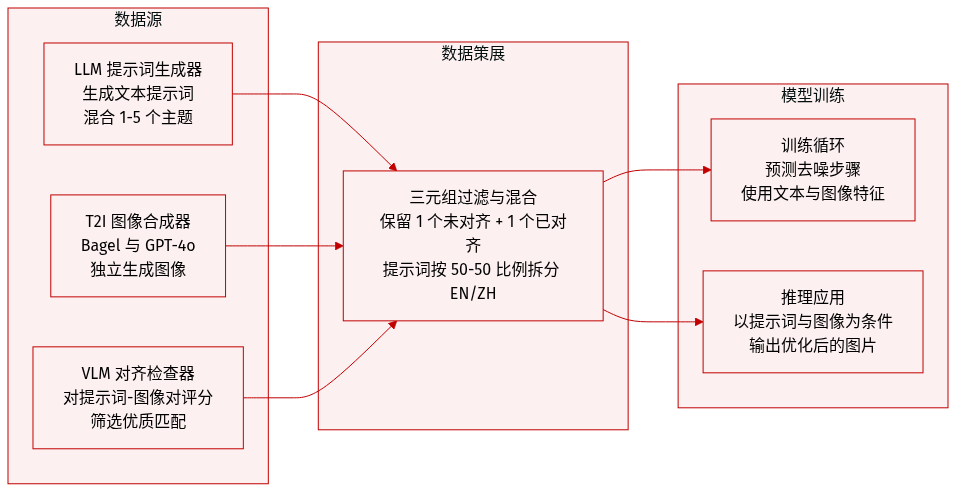
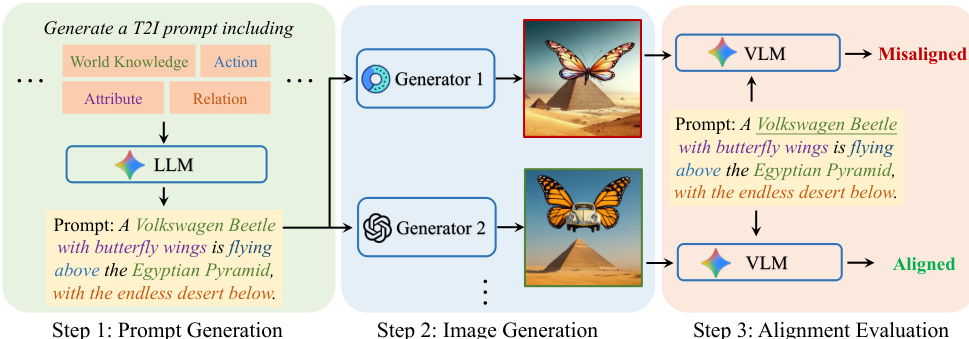
- 数据集构成与来源: 作者构建了一个统一的三元组训练集 ⟨I,I′,T⟩,将文本提示词(T)与未对齐图像(I)及提示词对齐图像(I')进行配对。提示词由大语言模型生成,图像由 Bagel 和 GPT-4o 等多种文生图生成器合成,对齐质量则通过视觉语言模型进行验证。
- 各子集关键细节: 数据集围绕单一精选集合构建,而非划分为独立子集,主要划分方式为英文与中文提示词按 1:1 混合,以支持双语优化。每个三元组均经过三步流水线筛选:提示词通过随机组合一至五个语义维度生成,候选图像针对每个提示词独立生成,视觉语言模型则根据语义对齐分数仅保留每个提示词对应的一个未对齐图像和一个对齐图像。
- 论文的数据使用方式: 过滤后的三元组用于训练统一多模态模型以预测去噪速度。训练期间,模型输入 text tokens、从不齐图像中提取的视觉特征以及对齐图像的含噪潜在表示。推理时,系统基于提示词与未对齐图像作为条件,直接将噪声去噪为符合提示词要求的优化输出。
- 处理与元数据构建: 该流水线刻意移除了输入图像与输出图像之间的内容一致性及像素级编辑约束,鼓励模型学习语义转换而非保守更新。元数据围绕提示词维度标签与 VLM 对齐评估进行组织,而独立生成策略通过迫使模型从零开始修正不对齐问题,从而扩展了学习空间。
方法
作者采用统一多模态模型(UMM)架构,将图像理解、生成与编辑功能整合于单一框架内。该 UMM 使用语义视觉编码器(通常为 Vision Transformer, ViT)从输入图像中提取高级语义特征 ZViT,并使用变分自编码器(VAE)将图像映射为低级潜在 tokens ZVAE。这些表示由多模态主干网络 M 处理以支持多种任务。在图像理解方面,模型根据图像 I 与文本查询 T 生成文本响应 T^。在文生图方面,模型根据文本提示词 Tprompt 合成图像 I^。在图像编辑方面,模型根据编辑指令 Tedit 修改 I 以生成编辑后图像 I^′,并将 ZViT 与 ZVAE 均作为条件输入。
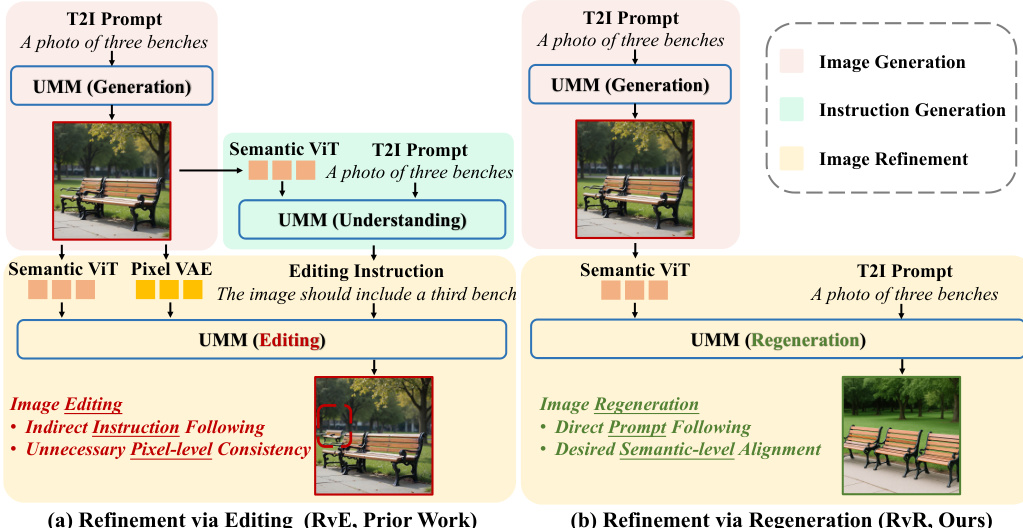
如图所示,现有的“通过编辑进行优化”(RvE)范式分为两个阶段:首先,通过比较输入图像与目标提示词生成编辑指令 T^edit;其次,使用该指令编辑原始图像。该方法继承了图像编辑的约束,例如对像素级一致性与内容保留的要求,而这些要求对于优化任务而言并非必需。依赖中间指令会引入潜在的误差累积,且修改空间仅限于保守的局部调整。
为克服上述局限,作者提出再生式优化(RvR),将优化任务重新定义为条件图像再生问题。该方法无需中间编辑指令,并移除了与源图像保持像素级一致性的约束。相反,RvR 直接以目标提示词与初始图像的 semantic tokens 作为条件。训练流水线包含系统提示词 Tsystem,用于指示模型分析不对齐问题并重新生成图像以符合用户提示词。模型被训练用于预测整流流的速度场,条件输入包括系统提示词、目标提示词 Tprompt 以及未对齐图像的语义 ViT tokens ZViT。值得注意的是,训练期间 VAE tokens ZVAE 被排除在条件上下文之外,从而允许更大且更灵活的修改。
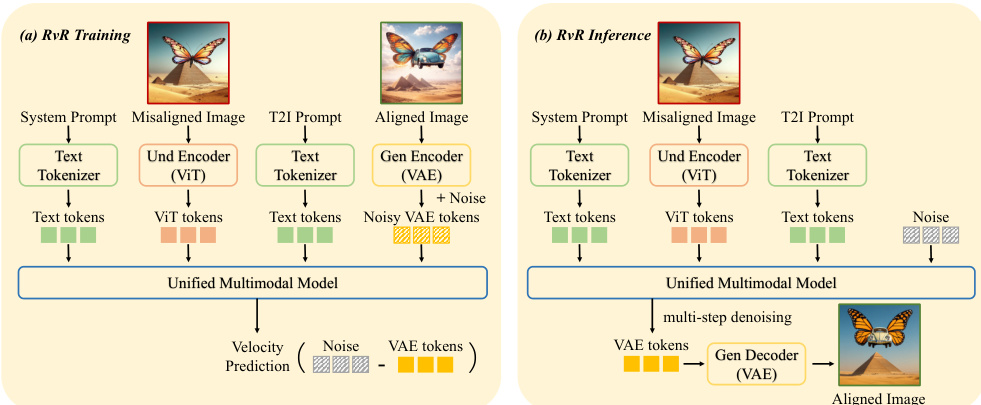
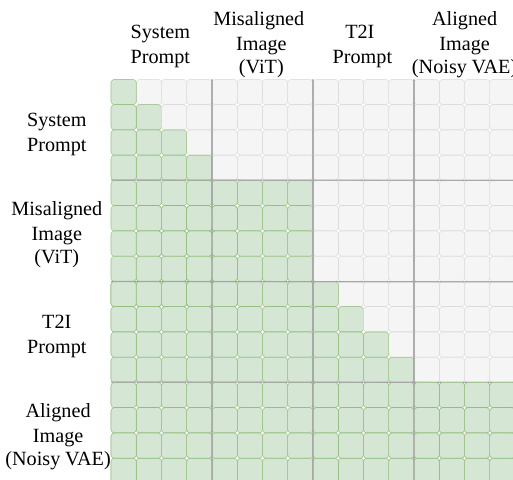
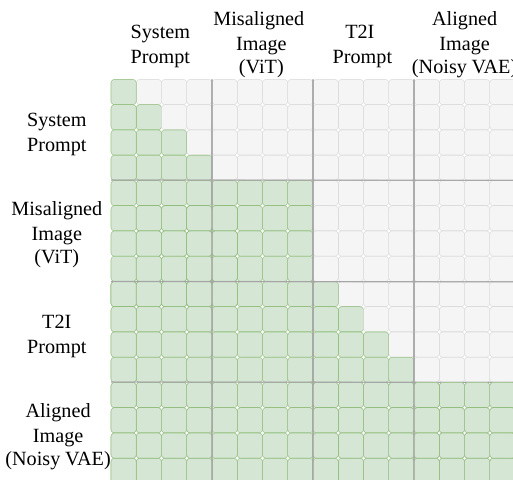
推理阶段,给定提示词 Tprompt 与未对齐图像 I,模型基于从 I 提取的 semantic tokens ZViT 作为条件,再生出优化后的图像 I^′。这种直接遵循提示词的方式绕过了易出错的指令生成步骤,并移除了不必要的内容保留约束,从而实现更有效的优化。RvR 的注意力机制对 text tokens(系统提示词与文生图提示词)使用因果注意力,对 image tokens(ViT 与 VAE)使用全注意力,具体如注意力掩码所示。
实验
在标准文生图基准测试中,RvR 流水线与具有代表性的基于再生与基于编辑的基线方法进行了对比评估,旨在验证其精确语义修正能力。定性与迭代评估证实,该模型通过利用优先关注语义对齐而非严格像素保留的扩大修改空间,持续优于现有方法,使其能够在多次优化轮次中成功解决复杂不对齐问题,且不会降低已准确内容的质量。此外,鲁棒性测试与消融研究表明,RvR 能有效复用初始图像中的兼容元素并丢弃冲突元素,结果证实这些性能提升直接源于基于再生的训练策略,而非像素级约束或标准微调。
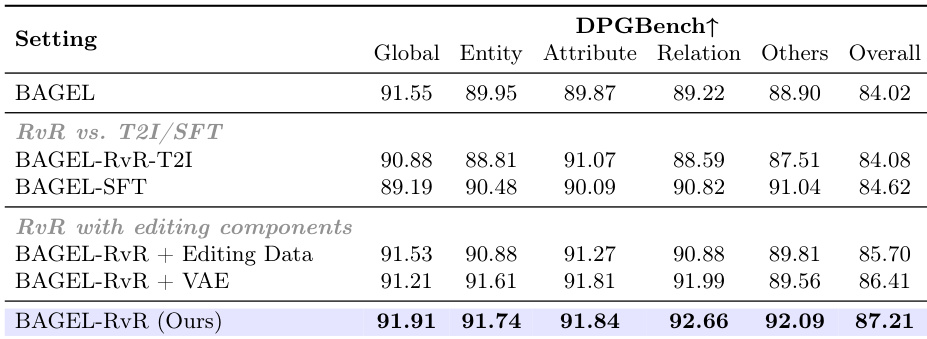
作者在 DPGBench 基准上将其 RvR 模型与多种基线及消融变体进行对比,重点考察优化性能。结果表明,提出的 RvR 方法取得了最高的综合得分,优于文生图(T2I)与基于优化的方法,在实体与属性级对齐方面的提升尤为明显。消融研究表明,引入编辑数据或 VAE 特征会导致性能下降,凸显了基于再生优化机制的重要性。RvR 在 DPGBench 上实现了最佳整体性能,超越 T2I 与基于优化的方法。与基线相比,该模型在实体与属性对齐上表现出显著改进。引入编辑数据或 VAE 特征会降低性能,表明严格的像素级一致性约束对语义优化具有负面影响。
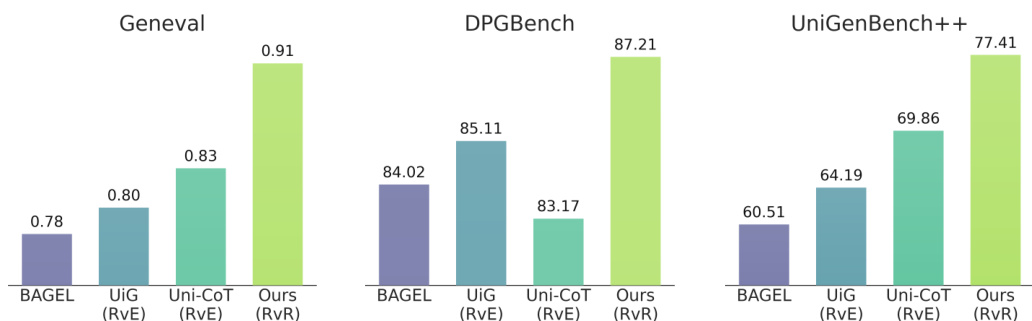
作者在三个基准上评估了 RvR 方法,展现出相对于基线模型与现有优化方法的稳定性能提升。结果表明,RvR 优于仅生成模型与基于编辑的方法,尤其在处理复杂语义提示词时表现突出,并在不同评估指标上均保持强劲性能。该方法支持迭代优化,能有效利用初始图像中的兼容语义并丢弃冲突语义。RvR 在所有三个基准上持续优于基线模型与现有优化方法。通过再生而非像素级保留提供更大的修改空间,RvR 取得了优于基于编辑方法的结果。RvR 支持迭代优化,在保留已对齐正确语义的同时,于后续轮次中进一步修正不对齐问题。
作者在图像优化任务上评估了 RvR 模型,将其与多种基线模型(包括仅生成模型、统一多模态模型及基于优化的方法)进行对比。结果表明,RvR 在多个基准上持续优于其他方法,在修正语义不对齐及保持复杂提示词对齐方面展现出卓越性能。该模型在复用初始图像兼容语义并丢弃冲突语义方面表现出强鲁棒性,且支持迭代优化而不会降低先前正确结果的质量。与仅生成模型和基于优化的模型相比,RvR 在多个基准上均取得一致的领先性能。通过再生而非像素级保留实现更大的修改空间,RvR 优于基于编辑的方法。RvR 支持多轮优化,在保留前轮正确结果的同时进一步修正不对齐语义。
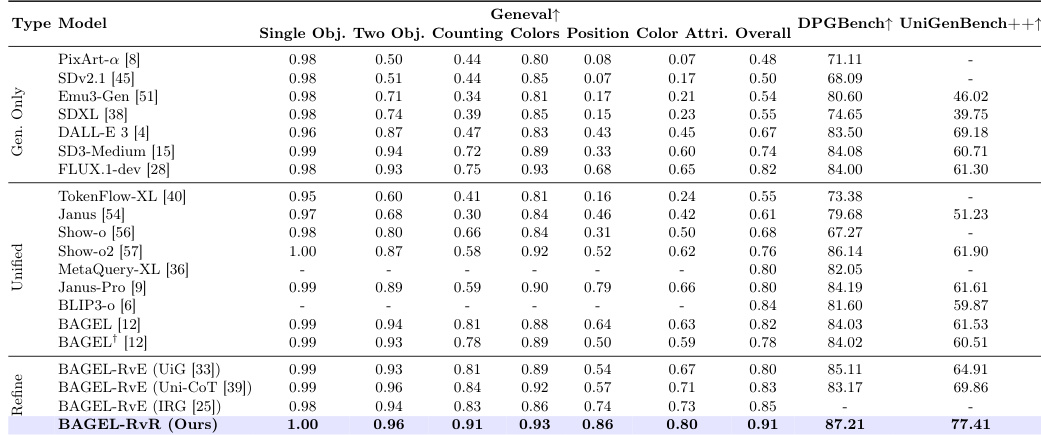
作者提出了一种名为 RvR 的图像优化方法,该方法在多个基准上优于现有的仅生成与基于编辑的方案。该方法利用基于再生的策略修正语义不对齐,在复用初始图像兼容语义并丢弃冲突语义方面表现出强鲁棒性,同时支持迭代优化以进一步提升结果。RvR 通过将修改空间扩展至像素级约束之外,实现了更有效的语义修正,从而取得卓越性能。在多个基准上,RvR 通过支持更广泛的语义修正,优于仅生成与基于编辑的方法。该方法支持迭代优化,在后续轮次中进一步改善不对齐语义并保留正确结果。RvR 在再生过程中复用初始图像兼容语义并丢弃冲突语义,展现出良好的鲁棒性。
作者在多个图像优化基准上评估了基于再生的 RvR 模型,将其与仅生成、基于编辑及现有优化方法进行对比,并辅以消融研究。实验验证了以再生机制替代严格像素级编辑可显著提升语义对齐效果,尤其在复杂提示词的实体与属性一致性方面。定性结果表明,该方法能稳健地保留初始图像中的兼容语义并丢弃冲突细节,有效支持迭代优化以逐步修正不对齐问题,且不会降低先前结果的质量。总体而言,本研究得出结论:基于再生的优化提供了更优的修改空间,在语义修正任务中持续优于传统基线方法。