Command Palette
Search for a command to run...
大语言模型通过潜在蒸馏进行探索
大语言模型通过潜在蒸馏进行探索
Yuanhao Zeng Ao Lu Lufei Li Zheng Zhang Yexin Li Kan Ren
摘要
生成多样化的响应对于大语言模型(LLMs)在测试时的扩展至关重要,然而,标准的随机采样主要产生表层词汇层面的变化,限制了语义探索的深度。在本文中,我们提出了一种名为探索性采样(Exploratory Sampling, ESamp)的解码方法,该方法显式地鼓励在生成过程中实现语义多样性。ESamp 的设计动机源于神经网络的一个众所周知的特性:面对与先前经历过的输入相似的数据时,神经网络倾向于做出误差较低的预测;而面对新颖的输入时,则会产生较高的预测误差。基于这一特性,我们在测试时训练一个轻量级的蒸馏器(Distiller),用于从 LLM 的浅层表示预测其深层隐藏表示,从而建模 LLM 的深度表示转换过程。在解码阶段,该蒸馏器会根据当前生成语境持续适应由此诱导的映射关系。ESamp 利用预测误差作为新颖性信号,对基于当前前缀的条件化候选 token 扩展进行重加权,从而将解码过程偏向于较少探索的语义模式。ESamp 通过异步训练-推理流水线实现,最坏情况下的开销低于 5%(优化后的版本中仅为 1.2%)。实证结果表明,ESamp 显著提升了推理模型的 Pass@k 效率,其表现优于或媲美强大的随机采样和启发式基线方法。值得注意的是,ESamp 在数学、科学和代码生成基准测试中实现了稳健的泛化能力,并在创意写作任务中打破了多样性与连贯性之间的权衡。我们的代码已发布在:https://github.com/LinesHogan/tLLM。
一句话总结
本文提出探索性采样(Exploratory Sampling, ESamp),这是一种测试时解码方法。该方法通过训练轻量级 Distiller 从浅层表示预测深层表示,并将预测误差作为新颖性信号以重新加权候选 tokens,从而在数学、科学和代码基准测试中提升推理模型的 Pass@k 效率,同时打破创意写作中的多样性与连贯性权衡。
核心贡献
- 本文提出探索性采样(ESamp),这是一种解码框架,在生成过程中利用轻量级 Distiller 从浅层表示预测深层隐藏表示。Distiller 的预测误差作为新颖性信号重新加权候选 tokens,使采样偏向未充分探索的语义模式,而非表层词汇变化。
- 在数学、科学和代码生成基准测试中的评估表明,ESamp 显著提升推理模型的 Pass@k 效率,同时优于或匹敌强大的随机与启发式基线。该方法还在不牺牲生成质量的前提下解决了创意写作任务中的多样性与连贯性权衡问题。
- 异步训练-推理流水线将 Distiller 的在线适配与主语言模型的生成过程解耦。该设计将最坏情况下的吞吐量开销限制在 5% 以内,使其能够高效集成到标准服务场景中。
引言
测试时扩展(Test-time scaling)通过聚合多个候选解来增强大语言模型的推理能力,但标准随机采样经常产生语义冗余的输出。这些输出尽管在表层词汇上存在差异,却共享相同的底层逻辑。这种冗余会削弱选择机制,而现有的替代方案(如结构化搜索)会带来难以接受的延迟,启发式约束也无法激发真正新颖的推理策略。本文提出探索性采样(Exploratory Sampling),这是一种解码方法,利用在线训练的轻量级 Distiller 来近似浅层与深层隐藏表示之间的映射关系。该方法将高预测误差视为语义新颖性的信号,通过重新加权 token 概率,引导生成过程朝向未充分探索的推理模式。此策略在各类基准测试中显著提升了 Pass@k 效率,且吞吐量开销微乎其微,从而有效将语义多样性与计算成本解耦。
数据集
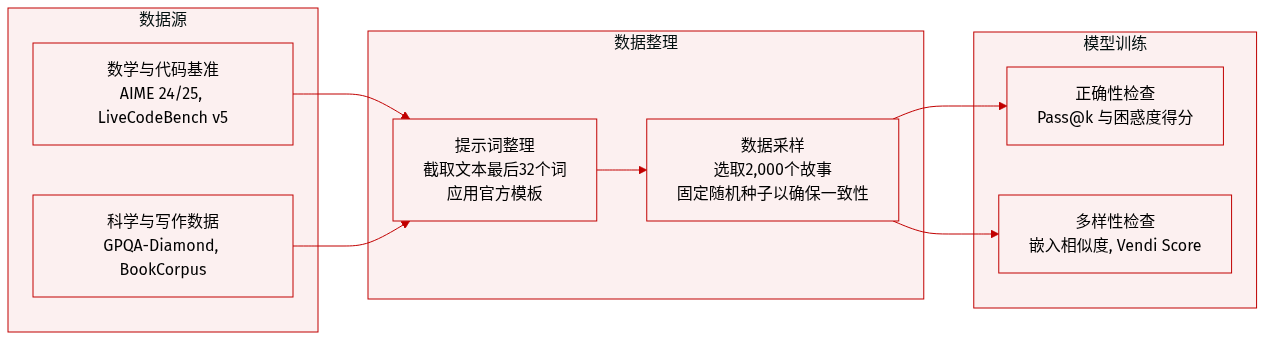
- 数据集构成与来源: 本文使用四个独立的基准测试来评估模型在数学、编程、科学推理和创意写作方面的性能。数学评估依赖于官方的 AIME 2024 和 AIME 2025 数据集。代码生成测试采用 LiveCodeBench v5,该数据集整合了来自 LeetCode、AtCoder 和 Codeforces 的时效性竞赛编程题目。科学推理通过 GPQA-Diamond 子集进行评估,包含经专家验证的生物学、物理学和化学问题。创意写作多样性使用托管在 HuggingFace 上的清洗版 BookCorpus 进行测量。
- 子集详情与规模: 数学和代码基准测试使用官方发布版本,未进行规模调整,而科学基准测试仅聚焦于最高质量的 Diamond 层级。BookCorpus 子集包含约 51,442 部经典文学作品。受计算资源限制,本文从该集合中精确采样 2,000 个故事,并在所有生成与评估步骤中使用固定的随机种子 42。
- 使用与处理策略: 数据仅保留用于评估,不用于训练或微调,且未应用任何混合比例或训练划分。所有基准测试提示词均遵循 lighteval 框架提供的官方模板,该框架同时负责评估脚本。模型输出使用 Pass@k 评估正确性,使用嵌入相似度和 Vendi Score 评估语义多样性,并使用困惑度评估语言流畅度。
- 裁剪与元数据处理: 由于该 BookCorpus 版本缺乏源文本分隔符或标准元数据,本文实施特定的裁剪策略。每段文本被对半拆分,提取前半部分的最后 32 个词作为生成提示。该方法可避免非叙事性输出,且在未使用聊天模板的情况下应用,以保留故事连贯性。
方法
本文提出探索性采样(ESamp),这是一种旨在促进语言模型生成过程中语义探索的解码方法。该方法的核心是潜在 Distiller(Latent Distiller, LD),这是一个在线训练的轻量级模块,用于建模语言模型从早期层到晚期层隐藏表示的变换过程。这使得系统能够检测并惩罚语义冗余的生成,即使表层文本发生变化。
整体框架通过将 LD 集成到生成流水线中来运行,且避免了显著的计算开销。在每一步生成中,模型通过其 Transformer 层处理输入。第一层的输出 ht1 被 LD 用于预测对应的深层表示 h^tL。该预测异步计算,允许其与主模型的前向传播并行运行。随后,真实的深层表示 htL 用于计算标准的语言建模 logits πref。LD 预测的 logits qdist 通过将 h^tL 投影到冻结的语言模型头部得到。
请参考下方的框架图以获取该过程的可视化表示。
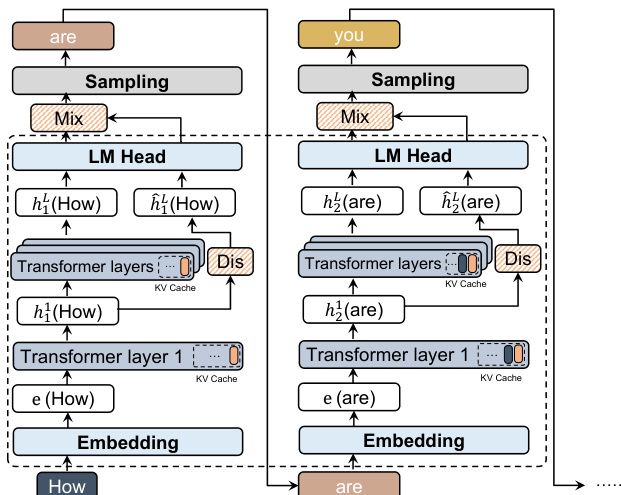
随后,该方法计算一种鼓励探索的新型采样分布。这通过定义内在奖励 r(s,z) 实现,该奖励是参考分布与 Distiller 预测分布之间针对候选 token z 的对数似然比。该奖励被纳入 KL 正则化策略中,从而生成与 πref(z∣s)⋅exp(β⋅r(s,z)) 成正比的新采样分布。该公式在几何上可解释为 logit 空间中参考 logits 与蒸馏 logits 的线性组合,其中 logits 的变化与潜在误差向量 et=htL−h^tL 成正比。该误差向量的模 ∥et∥2 量化了当前上下文的新颖性,而误差向量与 token 嵌入 wz 之间的余弦相似度则作为方向引导,以促进语义上截然不同的生成轨迹。

ESamp 的一个关键特征是其并行生成中的协作探索能力。LD 使用批次中所有序列的隐藏表示进行在线更新,作为共享通信通道。当某一序列探索新的语义区域时,LD 会学习相应的表示映射,导致该区域的新颖性奖励在所有后续序列中降低。这形成了一种隐式的“先到先得”机制,抑制冗余探索,并迫使集体生成产生发散,从而高效覆盖语义空间。该协调机制通过异步流水线实现。Distiller 的前向传播在 LLM 第一层之后立即启动,与受内存带宽限制的中间层重叠。Distiller 的训练步骤(涉及反向传播和权重更新)被推迟到后处理间隔期,该阶段受 CPU 限制且通常利用率较低,从而允许其在不阻塞 token 生成关键路径的情况下运行。
实验
实验在数学、科学、代码生成和创意写作基准测试中评估 ESamp,以检验其引导 LLM 解码朝向未充分探索语义区域的能力。在多种模型架构上的验证表明,该方法能有效扩展测试时探索,始终与基线持平或超越基线,并成功打破传统生成质量与有意义语义多样性之间的权衡。对解码动力学的分析确认,并行序列在整个生成过程中保持持续发散,效率评估则显示异步流水线引入的计算开销微乎其微。总体而言,研究结果确立了 ESamp 作为一种稳健且实用的解决方案,可在不牺牲语言连贯性或部署效率的前提下,提升候选解覆盖范围与推理路径多样性。
本文对比了两组生成的数学解,一组由 ESamp 生成,另一组由基础采样(vanilla sampling)生成,重点考察解题方法的多样性。结果表明,ESamp 在建模、启发式方法、单位处理和逻辑路径方面生成了多样性显著提升的响应,同时保持高质量评分。相比之下,基础采样生成的解更为单一且变化较少,通常收敛于单一标准方法。与基础采样相比,ESamp 在建模、启发式方法和逻辑路径方面生成了更多样化的数学解。基础采样生成的解更为统一,通常依赖单一标准化方法。ESamp 在保持高解质量的同时,实现了解题策略多样性的显著提升。

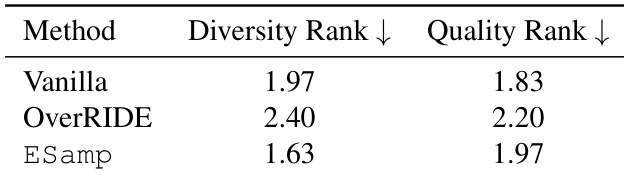
本文使用 LLM-as-judge 排名评估生成响应的多样性与质量,并在创意写作任务中对比不同方法。结果表明,ESamp 在保持与 Vanilla 相当质量的同时获得了更高的多样性排名,表明其能在不牺牲连贯性的前提下促进有意义的变化。相比之下,OverRIDE 的多样性和质量均低于 ESamp。与 Vanilla 和 OverRIDE 相比,ESamp 实现了更高的多样性与更优的质量排名。ESamp 在不降低连贯性的情况下促进了生成响应的有意义变化。OverRIDE 的多样性与质量排名均低于 ESamp 和 Vanilla。
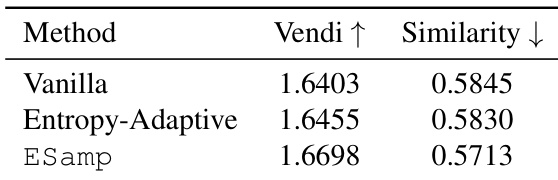
本文使用下表对比不同解码方法,以评估生成响应的多样性与质量。结果表明,ESamp 获得了更高的 Vendi 分数,显示出更高的语义多样性,同时保持较低的语义相似度,表明生成的响应既丰富又独特。该表支持了 ESamp 能在不损害生成质量的前提下促进有意义语义探索的主张。与基础采样和熵自适应方法相比,ESamp 实现了更高的语义多样性。ESamp 保持较低的语义相似度,表明生成的响应更加独特。ESamp 在保留生成质量的同时提升了多样性,打破了典型的质量-多样性权衡。
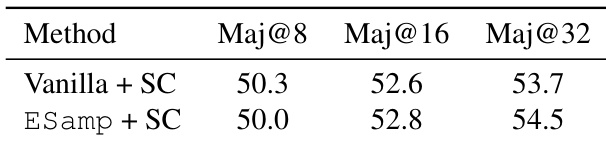
本文在推理任务中评估了 ESamp 与 Self-Consistency 结合的性能,并将其与结合 Self-Consistency 的 Vanilla 采样进行对比。结果表明,在较小的采样预算下,ESamp 的表现相当或略低,但在较大预算下展现出一致的改进,表明其在考虑多个候选解时能有效提升解的覆盖范围。该方法在多样性与质量之间保持了具有竞争力的平衡,尤其在高采样预算场景中表现突出。结合 Self-Consistency 的 ESamp 在较小采样预算下与结合 Self-Consistency 的 Vanilla 表现相当。在较大采样预算下,ESamp 持续优于 Vanilla,尤其在 Maj@32 指标上。ESamp 与 Self-Consistency 的结合在显著提升解覆盖范围的同时,未对质量造成明显影响。
本文在相同条件下对比了 ESamp 与优化版 vLLM 基线的吞吐量,结果显示 ESamp 在开销极小的情况下保持了近乎等效的性能。结果表明,ESamp 的异步实现保持了高效率,吞吐量比率接近 1.0,说明与基线相比计算成本微乎其微。这证明 ESamp 能够高效部署,且不会导致显著的性能下降。ESamp 实现了与优化版 vLLM 基线近乎等效的吞吐量,比率接近 1.0。ESamp 的异步设计导致计算开销极小,从而保持了高效率。该方法即使在繁重的工作负载下也能维持高性能,表明其具备实际可扩展性。

实验在数学推理、创意写作和语义生成任务中将 ESamp 与标准基线进行对比,以验证其打破传统质量-多样性权衡的能力。结果表明,该方法在保持连贯性的同时持续生成更多样且独特的输出,在新颖性与可靠性方面均优于竞争性方法。当与自我一致性(self-consistency)结合时,它在较大采样预算下进一步提升了解的覆盖范围,且其异步实现确保了实际部署中的计算开销微乎其微。