Command Palette
Search for a command to run...
World-R1: 强化三维约束以实现文生视频生成
World-R1: 强化三维约束以实现文生视频生成
摘要
近期的视频基础模型在视觉合成方面展现出令人印象深刻的性能,但往往存在几何不一致的问题。尽管现有方法试图通过架构修改注入3D先验知识,但这些方法通常伴随着高昂的计算成本,并限制了可扩展性。我们提出了 World-R1,这是一个通过强化学习将视频生成与3D约束对齐的框架。为了促进这种对齐,我们引入了一种专为世界模拟定制的纯文本数据集。利用 Flow-GRPO,我们利用预训练的3D基础模型和视觉-语言模型提供的反馈来优化模型,从而在不改变基础架构的情况下确保结构连贯性。我们进一步采用周期性解耦训练策略,以平衡刚性几何一致性与动态场景的流畅性。广泛的评估表明,我们的方法在显著提升3D一致性的同时,保留了基础模型原有的视觉质量,有效弥合了视频生成与可扩展世界模拟之间的差距。
一句话总结
World-R1 是一个强化学习框架,通过 Flow-GRPO 优化专用的纯文本数据集,将文本到视频的生成与 3D 约束对齐。该框架利用预训练的 3D 基础模型和视觉语言模型的反馈,结合周期性解耦训练策略来强制执行结构连贯性。大量评估证实,该方法在保持基础模型原始视觉质量的同时,显著增强了 3D 一致性,从而支持可扩展的世界模拟。
核心贡献
- World-R1 引入了一个强化学习框架,在不修改架构或施加计算成本高昂的推理时约束的情况下,将视频生成与 3D 约束对齐。该框架利用 Flow-GRPO 通过判别性反馈优化生成器,使模型能够通过后训练直接内化空间感知与几何一致性。
- 构建了一个具有多类别和多级别相机控制的专用纯文本数据集,以促进后训练对齐。该数据集支持一个综合奖励系统,集成了预训练的 3D 基础模型和视觉语言模型;同时,周期性解耦训练策略在刚性几何一致性与动态场景流畅性之间取得了平衡。
- 大量评估表明,该框架在保持基础基础模型原始视觉保真度的同时,显著增强了三维重建一致性,有效弥合了视频生成与可扩展世界模拟之间的差距。
引言
视频基础模型正迅速演变为世界模拟器,这一能力对于自主系统、机器人技术与沉浸式媒体至关重要。尽管这些模型具备较高的视觉保真度,但其运行主要局限于二维空间,在复杂的相机运动期间极易产生几何幻觉或时序不一致性。此前通过向模型架构嵌入 3D 先验或施加推理时约束来修正该问题的尝试,往往需要消耗高昂的计算资源,限制模型的可扩展性,并损害生成多样性。针对上述挑战,本文提出 World-R1 框架,在不改变底层架构的前提下将视频生成与 3D 几何规律对齐。该方法利用精心筛选的纯文本数据集、由预训练 3D 基础模型与视觉语言模型驱动的双重奖励机制,结合 Flow-GRPO 优化算法,在保留原始模型高视觉质量的同时,有效赋予模型空间连贯性与动态流畅性。
数据集
数据集构成与来源
- 研究团队推出了一套专有的“纯文本数据集”,包含约 3,000 个独立条目,旨在将 3D 几何约束学习与开放域视频分布中固有的偏差解耦。
- 该数据集完全由合成数据构成,使用 Gemini-3 模型生成。该模型利用先进的指令遵循能力生成高质量场景描述,无需依赖存在噪声的图文对齐。
- 语料库按视觉领域和控制复杂度进行系统组织,以覆盖广泛的物理属性,范围从隐性运动到复杂的复合轨迹。
子集详情
- 自然景观: 聚焦于大规模刚性几何结构与流体动力学,细分为地貌、水体特征和天气变化。
- 城市与建筑: 强调透视正确性与消失点,涵盖户外环境与室内空间(如仓库、走廊和大厅)。
- 微观与静物: 针对小尺度物体与宏观观察,用于评估景深处理与纹理保真度。
- 奇幻与超现实主义: 引入非欧几何与违背物理规律的结构,以挑战模型的泛化能力。
- 艺术风格: 融入水彩、赛博朋克插画及梵高风格等风格化渲染,确保在满足 3D 约束的同时保持美学多样性。
- 动态数据子集: 专注于高熵场景与可变形物体的专业集合,包含瀑布、变形机器人与破碎玻璃,以缓解 3D 对齐过程中对非刚性动力学的抑制。
使用与处理
- 研究团队利用该数据集训练世界模拟能力,使模型能够学习符合物理规律的生成过程,涵盖不同难度级别与控制复杂度。
- 从训练数据中独立筛选出包含 30 个复杂提示词固定测试集,用于在多样化场景中压力测试世界建模性能。
- 生成流程采用分层提示词工程策略,其中大语言模型扮演专家摄影师角色,强制执行物理合理性约束及相机与场景的逻辑匹配。
元数据与结构
- 每个条目均格式化为 JSON 输出,包含四个关键字段:描述性提示词、选定的相机逻辑、视觉领域类别以及布局类型。
- 元数据将相机运动划分为三种拓扑类别:场景内探索、场景间转换以及静态观察。
- 动作空间由一套全面的基元分类法定义,包括 push_in、pull_out、orbit、pan 以及 pull_left 等复合序列。
方法
World-R1 框架将预训练的视频基础模型与强化学习相融合,旨在无需显式 3D 架构或专用训练数据的情况下,提升几何一致性与世界建模能力。整体流程始于文本提示词,通过提示词驱动的运动合成机制生成相机轨迹。该轨迹经由离散噪声传输过程嵌入初始噪声中,以隐式且无参数的形式,将视频生成过程条件化至目标相机运动。条件化后的噪声随后输入视频基础模型(Wan 2.1),生成候选视频片段。这些片段经过 3D 基础模型处理,以重建 3D 高斯溅射(3DGS)表示并估计生成的相机轨迹。生成的视频通过结合 3D 感知奖励与通用质量奖励的综合奖励系统进行评估。3D 感知奖励通过对比重建的 3DGS 表示与估计的相机运动和输入提示词及生成视频,评估几何完整性、渲染保真度及轨迹对齐程度。通用奖励则通过预计算的视频帧评分来评估视觉质量与美学吸引力。总奖励通过聚合这些组件计算得出,策略则使用 Flow-GRPO-Fast 进行优化。该强化学习算法利用随机采样与带有 KL 散度约束的截断代理目标,确保训练过程的稳定与高效。
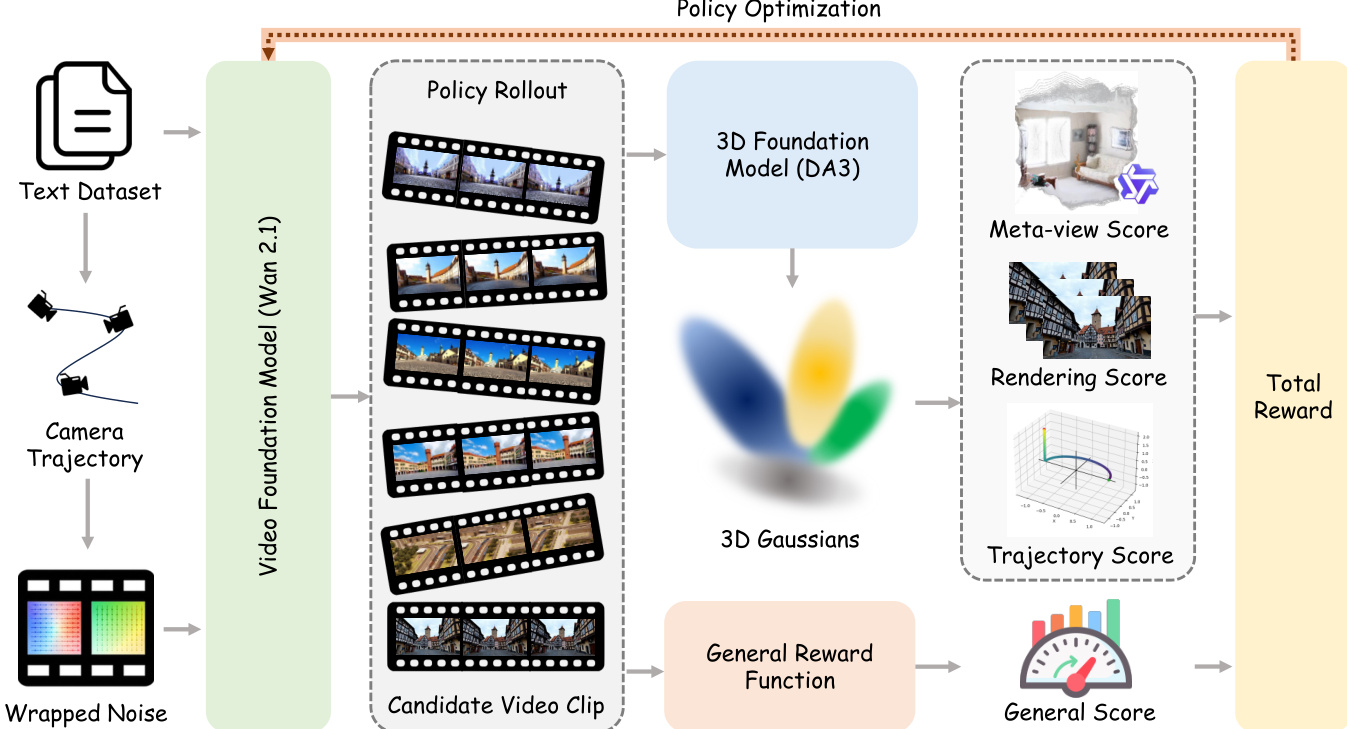
实验
评估框架基于重建的几何分析、多视图一致性评分以及盲测主观用户研究,将 World-R1 与领先的视频基础模型及专用相机控制方法进行基准对比。对比研究与用户研究验证了强化学习对齐策略在保持高美学质量与流畅非刚性动力学的同时,显著增强了三维一致性与相机轨迹遵循能力。消融实验进一步证实,特定的奖励组件与动态训练策略对于在严格几何约束与自然运动生成之间取得平衡至关重要。最终,定性可视化与综合分析表明,该模型能够维持严格的物体恒常性与结构稳定性,成功将创意视频生成与稳健的物理推理相衔接。
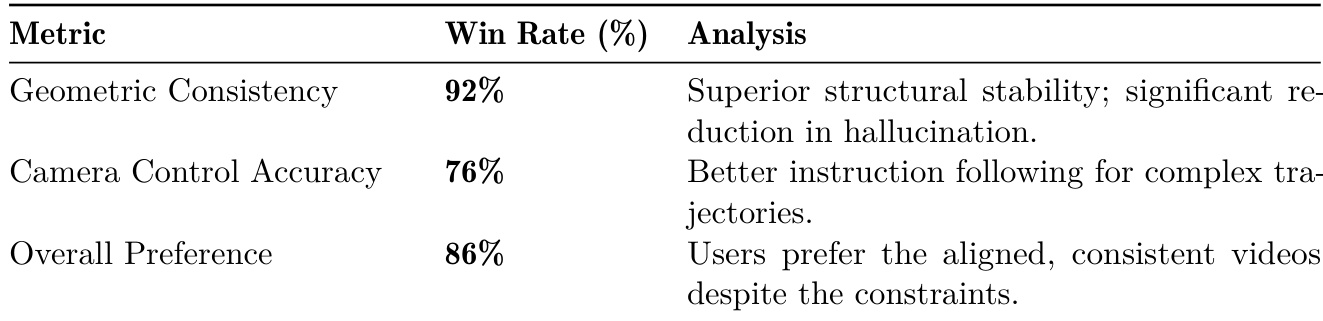
研究团队开展了一项用户研究,以评估 World-R1 相对于基线模型的性能,重点关注几何一致性、相机控制精度及整体视觉质量。结果表明,World-R1 在维持结构稳定性与遵循复杂相机指令方面显著优于基线模型,尽管增加了约束条件,仍获得了用户的强烈偏好。该模型在保持 3D 一致性与生成高质量视频方面展现出鲁棒性,即使在严格几何约束下亦表现稳定。World-R1 在几何一致性方面取得 92% 的胜率,表明其具备强大的结构稳定性并减少了幻觉现象。在相机控制精度方面,模型达到 76% 的胜率,显示出对复杂相机轨迹更好的遵循能力。在 86% 的测试案例中用户更倾向于 World-R1,凸显了其在平衡几何一致性与整体视觉质量方面的优势。
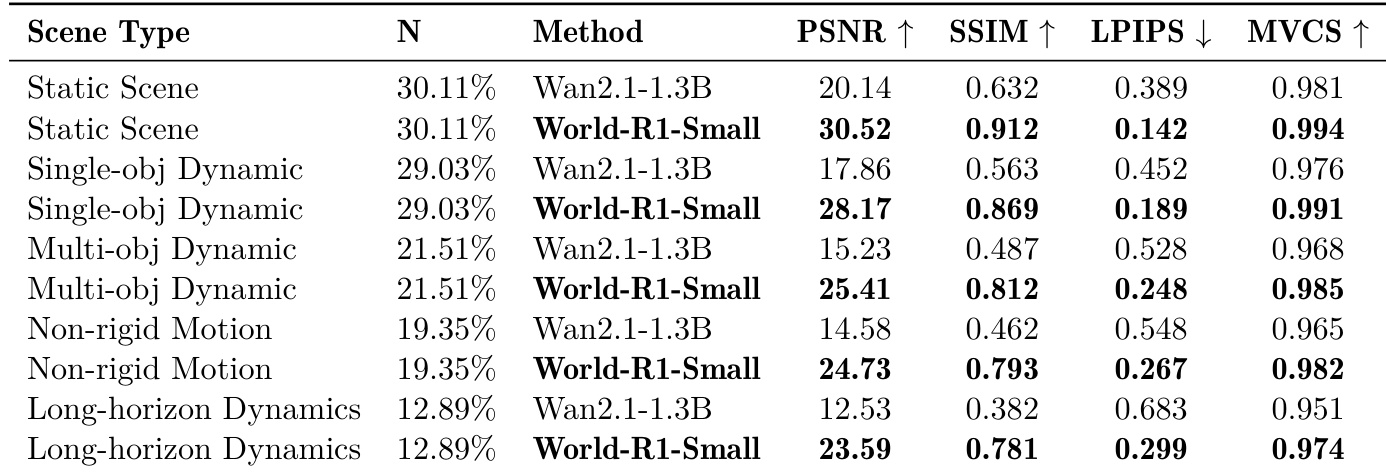
研究团队评估了 World-R1-Small 在不同场景类型下的性能,并将其与基线模型进行对比。结果表明,World-R1-Small 在 PSNR、SSIM 和 MVCS 等 3D 一致性指标上持续优于基线模型,尤其在复杂动态场景中表现突出。在非刚性与长时序动力学方面,改进最为显著,模型在保持运动保真度的同时维持了结构完整性。与基线模型相比,World-R1-Small 在所有场景类型中均实现了更高的 3D 一致性。该模型在 PSNR 和 SSIM 指标上展现出显著提升,特别是在非刚性与长时序动态场景中。World-R1-Small 保持了强劲的多视图一致性,表明其具备稳健的 3D 重建能力与场景稳定性。
研究团队采用与重建无关的指标,评估了模型变体相对于基线视频生成模型的多视图一致性。结果表明,所提模型获得了更高的多视图一致性得分,其中较大变体表现最佳。这说明模型生成的视频具有更强的跨视图一致性与改善的几何稳定性。World-R1 模型的多视图一致性高于基线模型。World-R1 的较大变体展现出最高的多视图一致性得分。结果证实生成视频在几何稳定性与跨视图一致性方面得到提升。

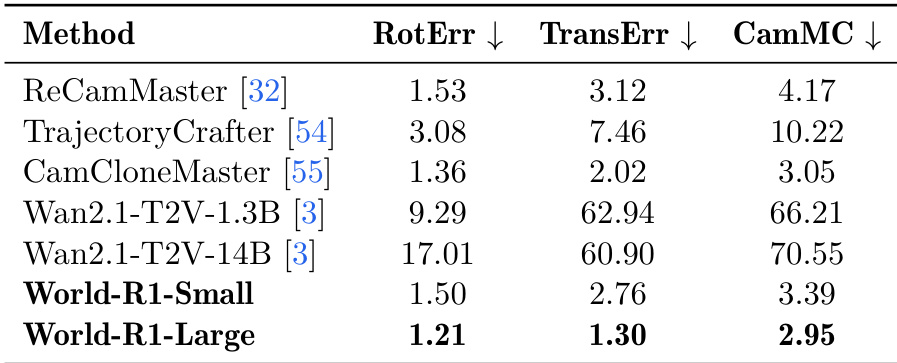
研究团队利用旋转误差、平移误差及相机运动一致性等指标评估相机控制精度,并将所提模型与现有方法进行对比。World-R1-Large 在所有指标上均取得最低误差值,展现出对指定相机轨迹的卓越遵循能力。World-R1-Small 同样具备竞争力,尤其在平移与相机运动一致性方面表现优异;而基线 Wan2.1 模型则显示显著更高的误差,表明其对相机运动的控制能力较弱。World-R1-Large 在相机控制精度上取得最佳性能,旋转、平移及相机运动一致性误差均为最低。World-R1-Small 展现出强劲的相机控制性能,尤其在平移与相机运动一致性方面优于 Wan2.1 基线模型。Wan2.1 模型表现出显著更高的误差,表明与 World-R1 及专用控制方法相比,其与请求的相机运动对齐效果较差。
研究团队使用一套综合评估指标(涵盖通用视频质量与 3D 一致性),将 World-R1-Small 与 CogVideoX、Wan2.1 等多项先进视频生成模型进行对比。结果表明,World-R1-Small 在美学质量、成像质量与主体一致性方面表现卓越,优于基础模型及其他控制方法。该模型展现出与相机轨迹的高度对齐能力,并维持了几何连贯性,多项评估标准的高分充分印证了这一点。World-R1-Small 在美学质量、成像质量与主体一致性上超越基础模型与其他控制方法。该模型在运动平滑度与背景一致性上取得高分,表明其具备稳健的相机控制能力与结构稳定性。World-R1-Small 在各项指标上均表现强劲,证实了其生成高几何保真度与高质量视频的能力。
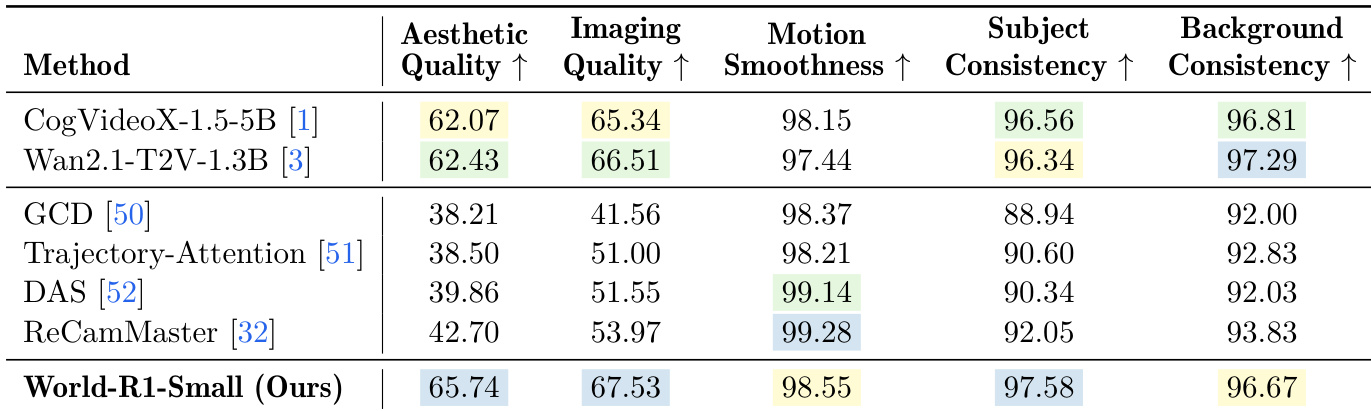
实验通过用户研究、多视图一致性测试以及跨多样化场景类型的相机控制评估,将 World-R1 及其变体与既定基线模型进行对比。这些评估验证了模型在具有挑战性的动态环境中,仍能维持稳健的三维结构完整性、精确遵循复杂相机轨迹并保持跨视图几何稳定性的能力。定性反馈与综合质量评估一致表明,该框架在视觉保真度、运动平滑度及整体用户偏好方面显著优于现有方法。最终,研究结果证实,所提方法在严格几何约束与高质量视频生成之间取得了有效平衡,且未牺牲美学或结构连贯性。