Command Palette
Search for a command to run...
面向智能体 AI 的技能检索增强
面向智能体 AI 的技能检索增强
Weihang Su Jianming Long Qingyao Ai Yichen Tang Changyue Wang Yiteng Tu Yiqun Liu
摘要
随着大语言模型(LLMs)逐步演变为智能体(Agent)式的问题解决者,它们日益依赖外部、可复用的技能(skills)来处理超出其原生参数化能力(parametric capabilities)范围的任务。在现有的智能体系统中,集成技能的主导策略是在上下文窗口(context window)中显式枚举可用技能。然而,该策略难以扩展:随着技能语料库的扩大,上下文预算(context budgets)被迅速消耗,且智能体在识别合适技能方面的准确性显著下降。为此,本文提出了技能检索增强(Skill Retrieval Augmentation, SRA)这一新范式,在该范式下,智能体能够按需从庞大的外部技能语料库中动态检索、集成并应用相关技能。为了使该问题可量化评估,我们构建了一个大规模技能语料库,并引入了 SRA-Bench——首个针对完整 SRA 管线(pipeline)进行分解式评估的基准测试(benchmark),涵盖技能检索、技能集成以及最终任务执行三个环节。SRA-Bench 包含 5,400 个能力密集型测试实例和 636 个人工构建的“金标准”技能(gold skills),这些技能与从网络收集的回旋技能(distractor skills)混合,形成了一个包含 26,262 个技能的大规模语料库。广泛实验表明,基于检索的技能增强方法能显著提升智能体的性能,验证了该范式的巨大潜力。
一句话总结
本文提出了技能检索增强(SRA),使 agent 能够从外部语料库中动态检索、整合和应用技能,而不是显式枚举,并引入了 SRA-Bench,这是首个用于分解评估检索、整合和执行能力的基准,包含 5,400 个能力密集型测试实例和 26,262 个技能(包括 636 个黄金技能),以证明基于检索的增强能显著提高 agent 性能。
核心贡献
- 这项工作将技能检索增强(SRA)形式化为一种新范式,其中 agent 根据需求从大型外部语料库中动态检索、整合和应用相关技能。该形式化为研究 agent 系统中可扩展技能增强作为一个独立问题提供了具体基础。
- 该研究构建了一个包含 26,262 个技能的大规模技能语料库,并引入了 SRA-Bench 作为首个用于分解评估完整 SRA 流水线的基准。该资源包含 5,400 个能力密集型测试实例和 636 个手动构建的黄金技能,混合了网络收集的分心技能。
- 大量实验表明,当正确访问和利用相关能力时,基于检索的技能增强可以显著提高 agent 性能。该工作建立了 SR-Agents 作为系统实证研究的基线家族,并验证了该范式的潜力。
引言
随着大型语言模型演变为代理问题求解器,它们越来越依赖外部可重用技能来处理超出其原生参数能力之外的任务。现有的 agent 系统通常在上下文窗口内枚举可用技能,但随着技能语料库的扩展,这种策略无法扩展并迅速消耗上下文预算。为了克服这一限制,作者提出了技能检索增强(SRA),这是一种新范式,其中 agent 根据需求从大型外部语料库中动态检索、整合和应用相关技能。他们构建了一个大规模技能语料库,并引入了 SRA-Bench,这是首个专为分解评估完整 SRA 流水线而设计的基准。他们的实验验证了基于检索的技能增强的潜力,同时揭示了当前 agent 在需求感知技能加载和有效整合方面存在困难。
数据集
-
数据集组成和来源
- 作者从三个组件构建 SRA-Bench:能力密集型测试实例、手动注释的黄金技能和一个大型外部技能语料库。
- 测试实例选自六个现有基准,包括 THEOREMQA、LOGICBENCH、TOOLQA、MEDCalc-Bench、CHAMP 和 BIGCODEBENCH。
- 外部语料库通过爬取 GitHub、Skills.sh 和 Hugging Face Hub 等公共网络来源形成。
-
每个子集的关键细节
- 该基准包含 5,400 个测试实例,关联 636 个独特的黄金技能。
- 源数据集经过过滤以确保能力强度,例如从 THEOREMQA 中移除依赖图像的问题,并从 TOOLQA 中排除 GSM8K。
- 最终技能语料库总计 26,262 个文档,其中仅 2.4% 是黄金技能,混合了 25,626 个噪声分心项。
-
用途和混合
- 该数据集用作评估基准而非训练集,测试系统从噪声语料库中检索和应用正确能力的能力。
- 每个测试实例基于源数据中的结构化信号(如定理名称或库导入)链接到一个或多个黄金技能。
- 评估要求模型从大型语料库中识别正确技能并执行它,以提高下游任务性能。
-
处理与元数据构建
- 黄金技能通过两阶段过程创建,涉及 LLM 起草以及随后的专家修订,以确保通用性和正确性。
- 技能存储为包含过程内容、适用条件和可运行资源(如 Python 实现)的标准 Markdown 工件。
- 泄露控制措施包括用新构建的示例替换重叠示例,并移除特定于基准的常数,以防止评估变得过于简单。
方法
作者将技能检索增强(SRA)的核心操作流程形式化为一个多阶段过程,分离相关技能的检索、将其整合到活跃问题解决状态以及将其最终应用于任务性能。该框架旨在按需增强 agent 的相关外部能力,而不是依赖一组固定的预暴露技能。
标准技能被定义为一种可重用的能力包,使 agent 能够解决一类重复出现的问题。形式上,令 C={s1,s2,…,sN} 表示包含 N 个技能的技能语料库。每个技能 si∈C 表示为一个元组:
si=(ni,ri,ci,πi),其中 ni 是作为语义标识符的名称,ri 是简短描述,ci 是包含指令和约束的主要内容,πi 是可执行负载,如代码或工具。
整体架构遵循下图所示的三阶段流水线。
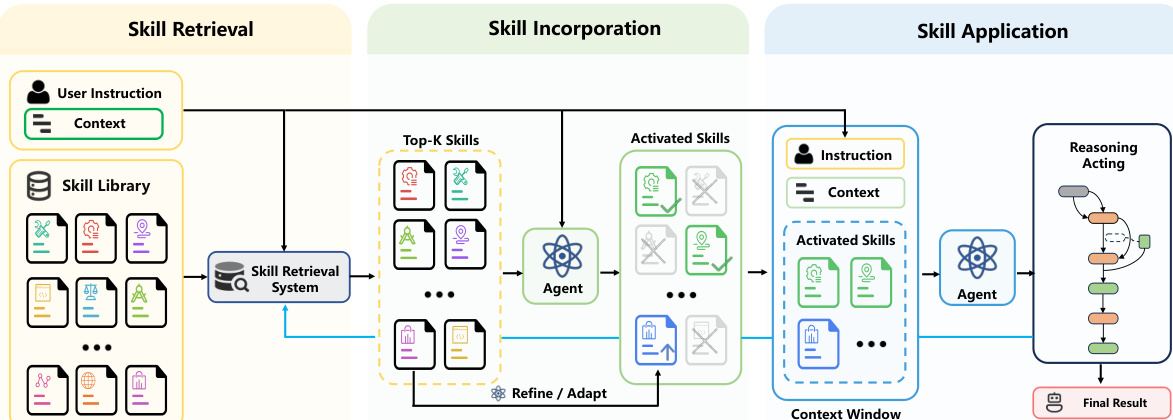
第一阶段是技能检索。检索器 R 将用户查询 q 和技能语料库 C 映射为候选技能的排名列表:
Lk=R(q,C)=[s(1),s(2),…,s(k)],s(j)∈C, k≪N.该阶段将巨大的外部能力空间减少为可管理的排名列表,其中较早的位置表示与当前任务的相关性更高。
第二阶段是技能整合。给定检索到的候选项 Lk,agent 确定是否应使用外部技能以及如何将它们整合到活跃问题解决状态中。该过程表示为:
S=G(q,Lk;M),其中 M 是底层基础语言模型,S 表示为下游求解准备技能表示。这些表示可以是检索技能的选择子集,或是转换变体,如重写或模型适应形式。重要的是,如果 agent 确定其参数能力足够或没有检索到的技能被认为有用,S 可能为空。
最后阶段是技能应用。以整合技能 S 为条件,agent 在任务求解过程中应用相应能力以产生最终响应:
A^=F(q,S;M).该阶段评估整合的技能是否被有效利用以改善下游行为,包括正确调用、整合到推理中以及行为适应。成功整合并不保证成功应用,因为模型必须在求解过程中正确操作技能。
实验
这项系统研究使用各种 LLM 和技能使用策略(如全注入和渐进式披露)在六个基准上评估可扩展技能增强。结果表明,虽然外部技能显著提高性能,但增益严重依赖于受控利用而非仅检索。agent 证明对检索噪声脆弱,并且在加载技能时通常缺乏相关性或需求感知,表明鲁棒增强需要可靠的机制来进行选择性技能整合。
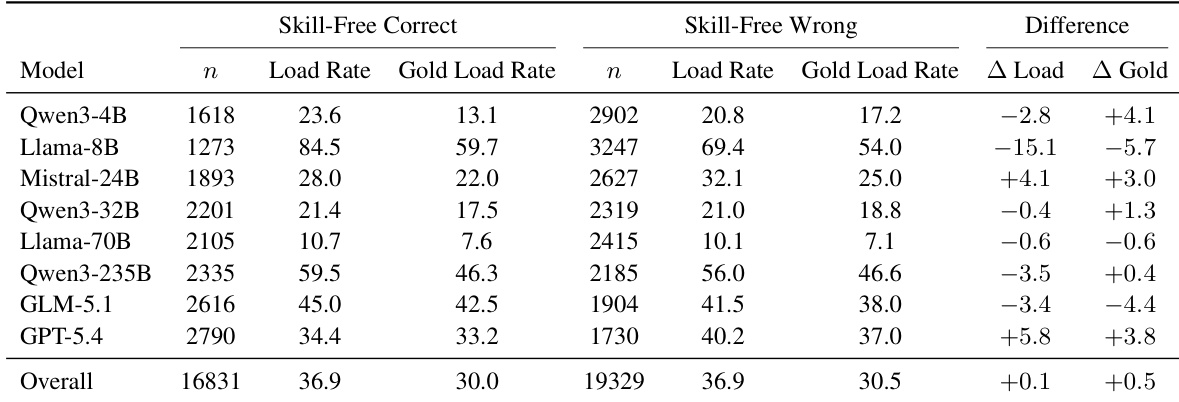
作者通过比较模型能够原生解决的任务与不能解决的任务上的加载率,评估语言模型是否表现出需求感知技能加载。结果表明,大多数模型在面对无法在无协助情况下解决的任务时,并未显著增加其技能加载频率,表明技能加载在很大程度上仍然是无差别的而非补偿性的。虽然一些前沿模型在将加载行为与需求对齐方面显示出适度改善,但总体趋势指向能力差距与使用外部技能决定之间的脱节。原生解决任务与失败任务之间的技能加载率总体差异可忽略不计,表明模型普遍缺乏需求感知。虽然一些前沿模型显示任务难度与加载频率之间存在正相关,但几个开源模型表现出负差异,即在失败时较少加载技能。对黄金技能加载率的分析表明,即使正确技能可用,模型也不一致地优先在缺乏原生能力的实例期间更多地加载它。
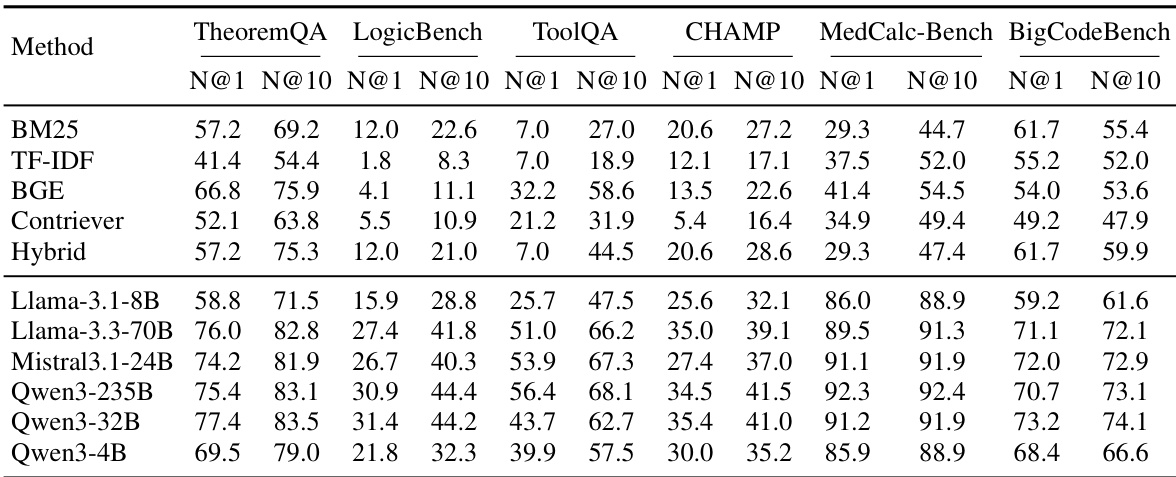
该实验比较了传统检索方法与基于 LLM 的重新排序器在六个基准上的表现,以评估技能检索质量。结果表明,基于 LLM 的重新排序显著提高了相对于标准检索器的排名性能,较大模型通常取得更好结果。然而,有效性因数据集而异,表明检索难度取决于任务。基于 LLM 的重新排序器在排名相关技能方面始终优于传统检索器,如 BM25 和 BGE。较大模型通常获得更高排名分数,尽管性能在不同特定基准间有所变化。MedCalc-Bench 产生最高检索分数,而 LogicBench 呈现最具挑战性的检索任务。
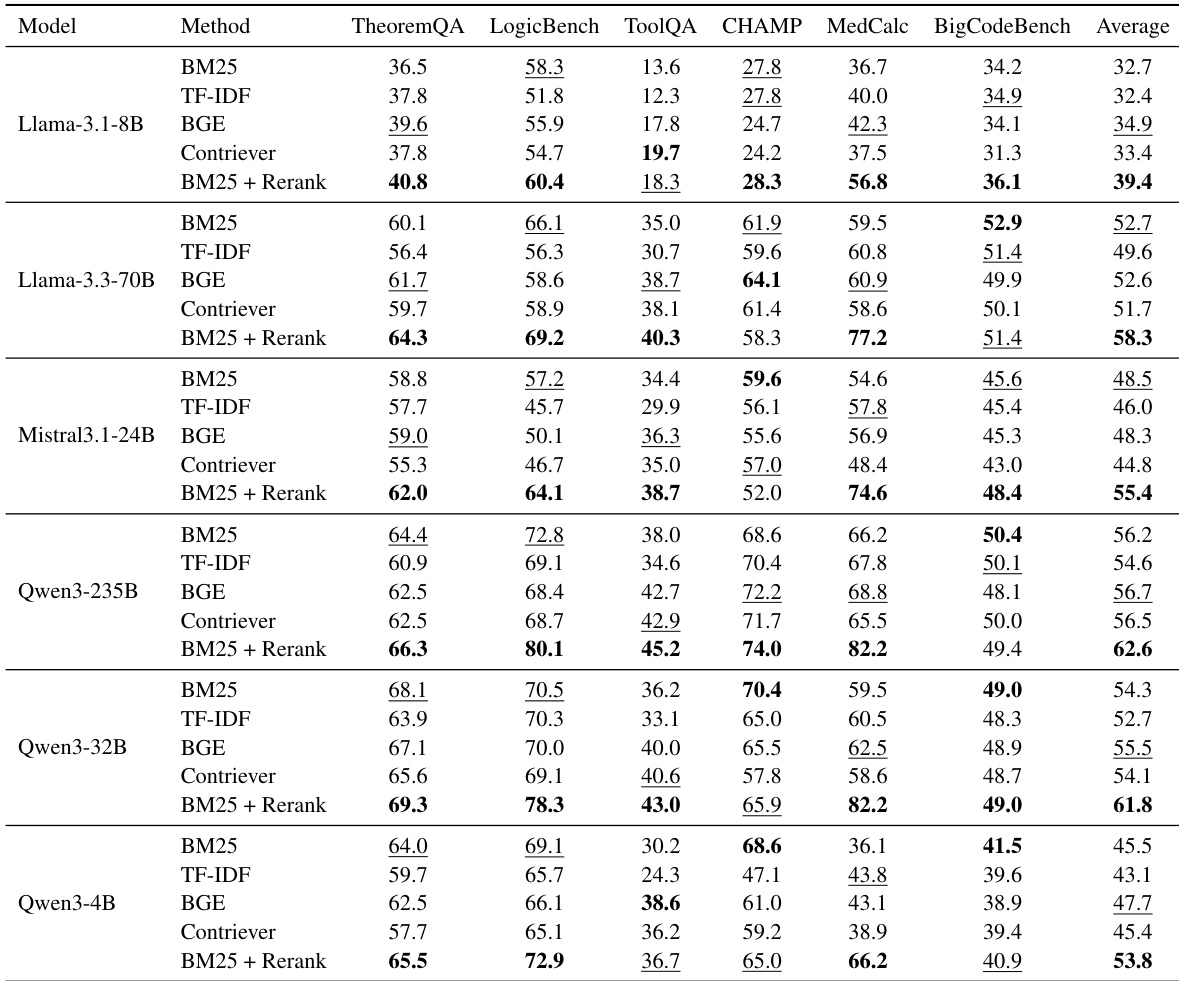
作者评估了不同检索策略对六个 LLM 和六个基准上最终任务性能的影响。结果表明,与独立的稀疏或密集检索方法相比,结合 BM25 检索与重新排序步骤始终产生最高平均性能。这一趋势在各种模型大小间成立,表明精确技能选择对有效增强至关重要。BM25 + Rerank 方法在所有评估模型家族中获得最高平均分数。独立检索基线表现出更多可变性能,密集方法如 BGE 通常落后于重新排序方法。无论底层模型规模如何,从较小到较大参数计数,重新排序的性能优势持续存在。
作者评估了多种大型语言模型和基准上的各种技能使用策略,以确定外部技能是否改善 agent 性能。结果表明,虽然提供黄金技能始终产生最佳结果,但实用的基于检索的方法如 LLM Selection 可以有意义地优于没有外部支持的直接提示。Oracle Skill 在所有测试模型家族和基准上始终实现最高性能。LLM Selection 在平均分数上通常优于 Full-Skill Injection 和 Progressive Disclosure。LLM Direct 基线性能始终低于技能增强方法,证实了外部知识的价值。
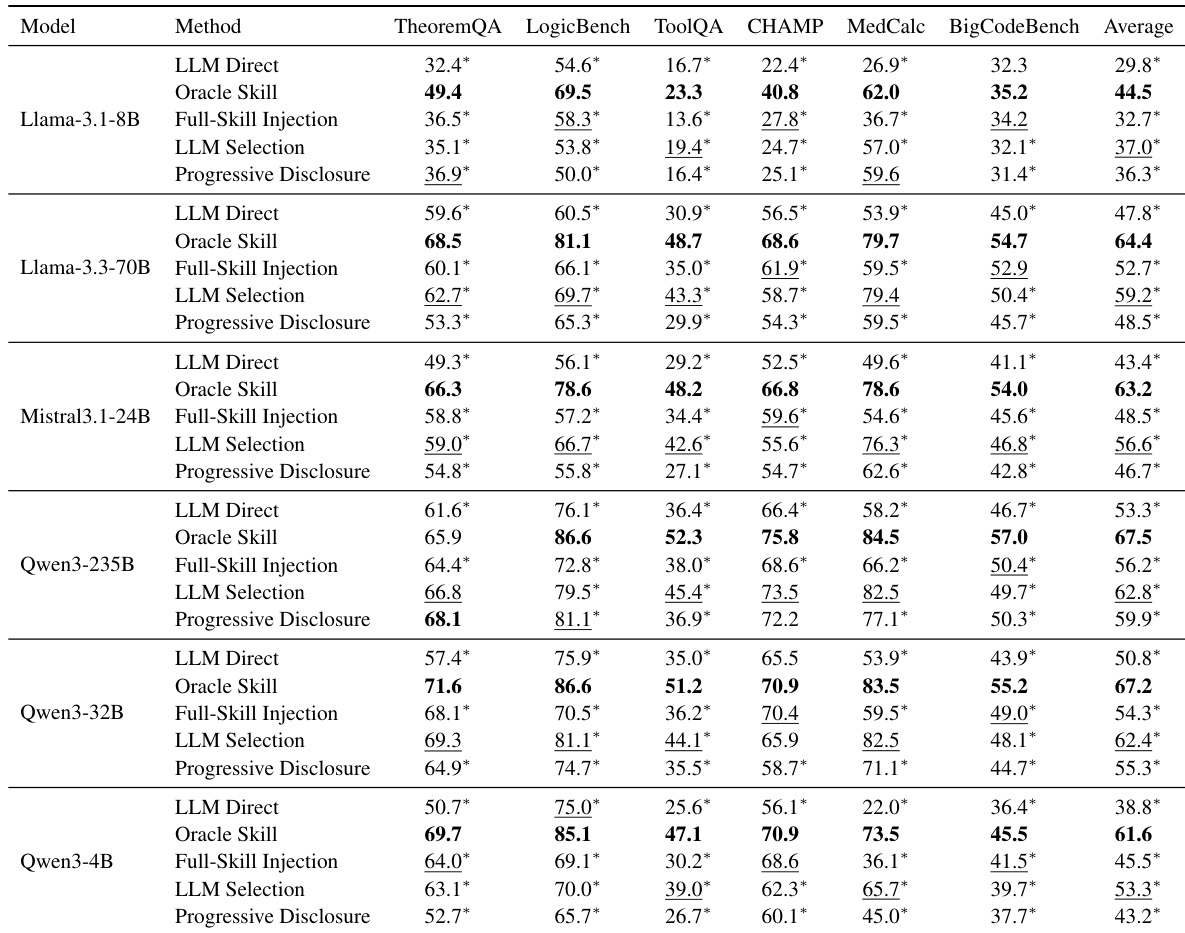
作者评估了六个不同基准上的多个大型语言模型,以评估技能检索增强对 agent 性能的影响。结果表明,虽然提供正确技能显著提升了能力,但实用的检索方法产生不均匀的增益,这严重取决于技能如何暴露给模型。基于选择的策略通常证明比直接注入或渐进式披露方法更鲁棒和有效。提供正确的外部技能始终优于仅使用原生参数知识。基于选择的技能暴露策略比其他方法更可靠地将检索结果转化为下游增益。性能改进在不同模型和任务域间差异显著,突出了鲁棒技能利用的挑战。
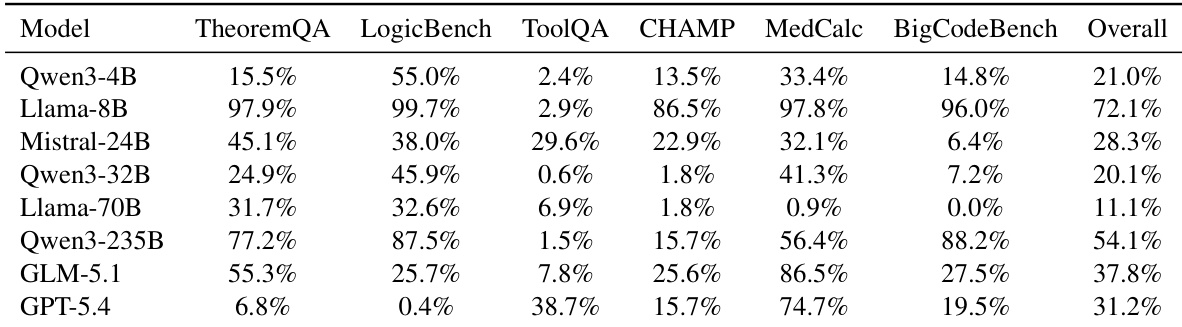
实验评估了多个大型语言模型和不同基准上的技能加载感知、检索质量和技能使用策略。结果表明,大多数模型缺乏需求感知,因为在原生能力不足时未能优先外部技能,尽管基于 LLM 的重新排序器和组合检索策略显著优于传统方法。此外,基于选择的技能暴露证明比直接注入更鲁棒,但总体性能增益仍然取决于特定模型和任务域。