Command Palette
Search for a command to run...
扩散模板:一种用于可控扩散的统一插件框架
扩散模板:一种用于可控扩散的统一插件框架
Zhongjie Duan Hong Zhang Yingda Chen
摘要
可控扩散方法显著提升了扩散模型的实用价值,但它们通常被开发为孤立的、特定于骨干网络(backbone)的系统,其训练流程、参数格式和运行时钩子(runtime hooks)互不兼容。这种碎片化使得跨任务复用基础设施、跨骨干网络迁移能力,或在单一生成管线中组合多种控制信号变得十分困难。我们提出了“扩散模板”(Diffusion Templates),这是一个统一且开源的插件式框架,实现了基础模型推理与可控能力注入的解耦。该框架由三个核心组件构成:模板模型(Template models),用于将任意特定于任务的任务输入映射为中间能力表示;模板缓存(Template cache),作为能力注入的标准化接口;以及模板管线(Template pipeline),负责加载、合并并将一个或多个模板缓存注入到基础扩散运行时中。由于该接口是在系统层面定义的,而非绑定于特定的控制架构,因此相同的抽象层能够支持异构的能力载体,例如 KV-Cache 和 LoRA。基于这一设计,我们构建了一个涵盖结构控制、亮度调整、颜色调整、图像编辑、超分辨率、清晰度增强、美学对齐、内容参考、局部补全以及年龄控制等多种任务的多样化模型库(model zoo)。这些案例研究表明,Diffusion Templates 能够在保持模块化、可组合性以及针对快速演进的扩散骨干网络具备实际可扩展性的同时,统一广泛的受控生成任务。所有资源,包括代码、模型和数据集,均将开源。
一句话总结
本文作者提出了 Diffusion Templates,这是一种统一的插件化框架。该框架通过系统级接口标准化了 LoRA 和 KV-Cache 等异构载体,将基础模型推理与可控能力注入解耦,统一了结构控制、图像编辑和超分辨率等多种生成任务,同时在不断演进的扩散模型骨干网络中保持了模块化和可组合性。
核心贡献
- 本文介绍了 Diffusion Templates,一种统一的插件框架,将基础模型推理与可控能力注入解耦。该架构协调三个核心组件:将任务特定输入映射为中间表示的模板模型(Template model)、用于能力注入的标准化模板缓存(Template cache),以及将多个缓存加载并合并到基础扩散运行环境中的模板流水线(Template pipeline)。
- 通过建立能力注入的系统级接口,该框架使 KV-Cache 和 LoRA 等异构控制载体能够在单一抽象下运行。该设计消除了针对特定架构的适配需求,并支持在快速演进的扩散基础模型之间实现跨骨干网络的组合性。
- 该框架将十余种不同的生成任务整合至单一模型库中,涵盖结构控制、图像编辑、超分辨率和美学对齐。所有相关代码、模型和数据集均已公开,以支持在不同扩散架构上进行模块化部署。
引言
扩散模型已成为高质量视觉生成的基石,但实际应用要求对结构、风格和内容进行精确控制。这一需求催生了大量控制技术的发展,包括 LoRA 等参数高效适配方法和 ControlNet 等条件控制模块,这些技术对于高级图像合成与编辑任务至关重要。然而,这些方法通常作为孤立且针对特定骨干网络部署的系统,其训练流水线、参数格式和运行时钩子互不兼容。这种碎片化现象造成了系统层面的瓶颈,阻碍了基础设施的复用、跨骨干网络的能力迁移以及多重控制的组合,往往需要复杂的手工工程来解决条件路径中的冲突。本文作者基于插件化抽象提出了 Diffusion Templates,这是一个统一的框架,通过包含模板模型、模板缓存和模板流水线的标准化接口,将基础模型推理与能力注入解耦。通过将 KV-Cache 和 LoRA 等异构能力载体视为可插拔模块,该框架允许将任务特定输入转换为中间表示,这些表示可被独立加载、合并与注入,从而在不修改底层扩散架构的前提下实现模块化组合。
方法
Diffusion Templates 框架为可控扩散生成提供了一种统一的插件架构,将基础模型推理与控制能力注入解耦。该框架通过三个核心组件运行:模板缓存(Template cache)、模板模型(Template model)和模板流水线(Template pipeline)。模板缓存作为表示模型能力的标准化接口,其约束仅限于基础模型扩散流水线所接受的部分输入参数。该设计契合现有扩散框架的工程抽象,使得新能力可通过扩展流水线参数而非重写去噪内部逻辑来集成,同时在插件与基础流水线之间建立了稳定的契约。在候选接口中,KV-Cache 是最具实用性且被推荐使用的类型,因其具备强大的表征能力、对生成行为的直接影响,以及对序列级拼接的原生支持,这在多个模板同时激活时至关重要。然而,该框架并未限制缓存格式,允许支持 LoRA 等轻量级参数化等替代表示形式。
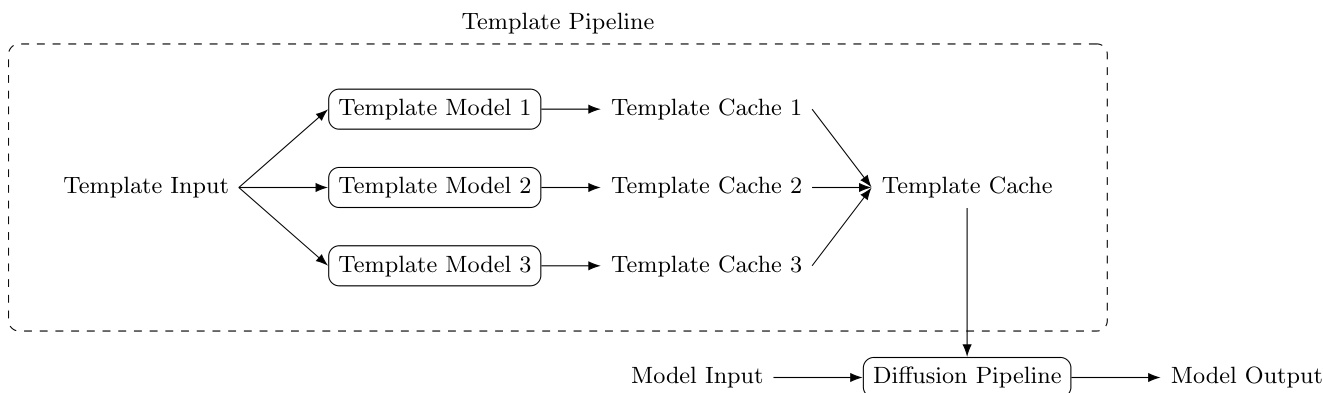
模板模型(Template model)是指将任意输入映射至标准化模板缓存格式的任何模型。其架构不受限制,可作为本地目录打包或托管于远程模型仓库。每个模板模型提供两个接口:processInputs 用于无梯度预处理与特征准备,forward 用于生成模板缓存输出的梯度相关计算。这种接口划分在保持模型灵活性的同时确保了框架级兼容性,使异构架构能够在统一运行时环境中运行。

模板流水线(Template pipeline)负责编排多个模板模型的加载、执行与组合。在推理阶段,给定一个或多个已启用的模板模型,流程分为三步:首先,各模板模型处理其输入以生成模板缓存;其次,根据缓存类型进行合并,KV-Cache 采用直接拼接方式;最后,合并后的缓存与常规生成参数一同传入基础扩散流水线。由于 KV-Cache 支持拼接,多个模板模型可协同运行而无需修改基础去噪逻辑。模板模型在迭代去噪过程之外执行,因此运行时开销保持较低,推理效率得以维持。在实际应用中,当配置大量模板时,可采用轮询调度结合懒加载的方式安排模板推理,以降低峰值内存占用。
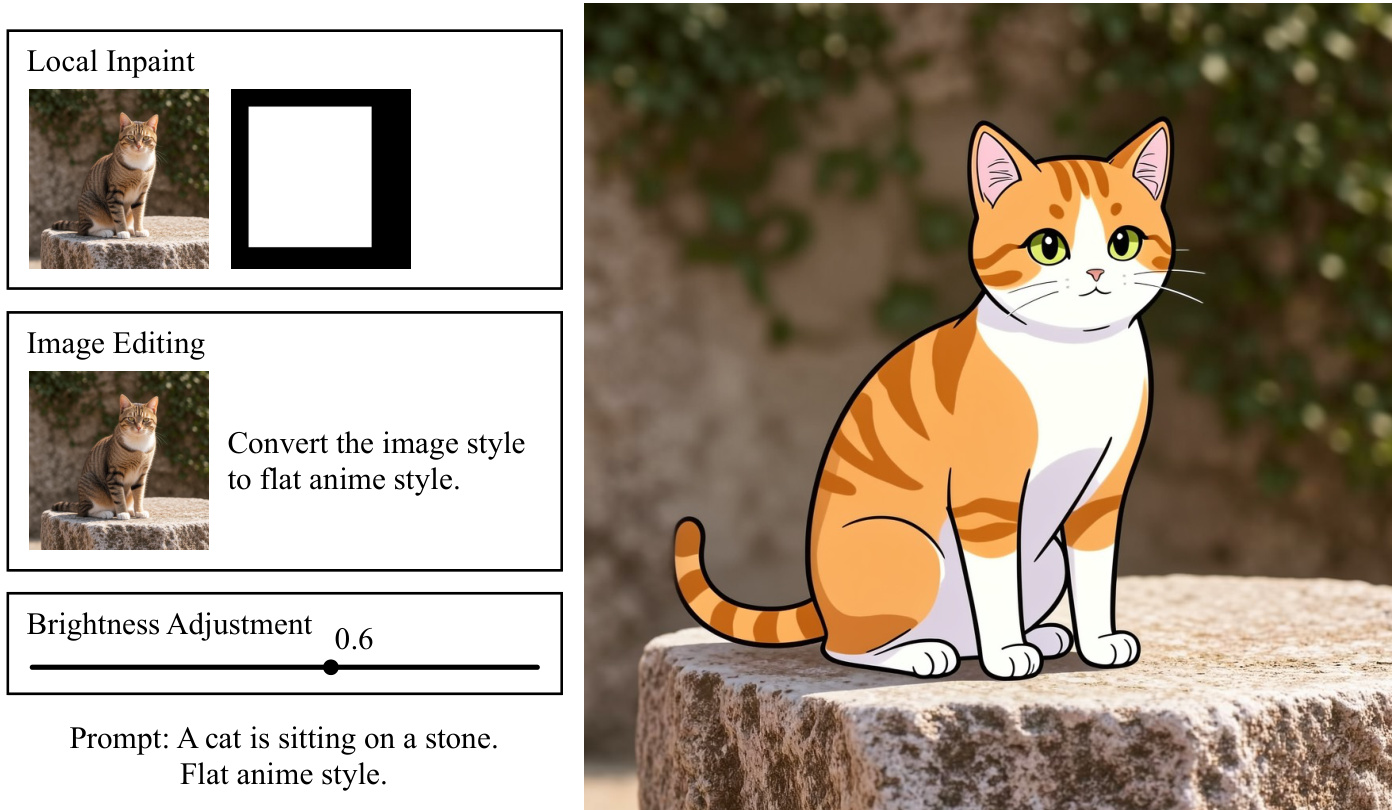
模板模型采用与 ControlNet 和 LoRA 相似的标准范式进行训练,即可训练侧分支被附加至预训练基础模型上,且基础模型的所有参数保持冻结。优化过程以基础模型的原始预训练损失为目标针对新分支进行,在保留学习目标的同时,将任务特定能力迁移至模板路径中。训练分为两个阶段:阶段一在无梯度流水线中执行输入处理,以生成可复用且可充分缓存的中间特征;阶段二将优化限制在基于模板缓存定义的训练目标下的梯度相关前向路径中。这种分离减少了冗余计算并提升了训练效率。训练框架基于 DiffSynth-Studio 构建,支持标准化的 processInputs 和 forward 接口。模板模型可针对多种任务进行训练,包括结构控制、亮度与色彩调整、图像编辑、超分辨率和本地图像修复,每种任务均采用针对控制需求量身定制的独立架构设计。例如,结构控制模型采用类似 ControlNet 的架构,但通过 KV-Cache 而非残差分支传递控制信号;亮度与色彩调整模型则遵循包含位置编码和全连接层的轻量级设计。图像编辑和超分辨率模型采用与结构控制模型相似的架构,将编辑与放大能力迁移至模板路径中。本地图像修复模型提供软控制,并与流水线级别的硬约束相结合,以强制保留掩码区域外的内容。多个模板模型可在单一生成流水线中有效融合,融合策略取决于缓存格式:KV-Cache 模型通过沿序列维度拼接缓存进行融合,而基于 LoRA 的模型则通过沿秩维度拼接参数进行融合。当不同模型以异构格式输出缓存时,其模块可无需转换直接同时启用,从而实现按需加载,并支持在不显著增加 GPU 内存占用的前提下融合任意数量的能力。
实验
通过在基础扩散架构上使用标准化生成参数训练多种模板模型,实验验证了该框架在多个控制领域的表达能力与可扩展性。清晰度控制通过边缘密度代理实现了感知细节的可靠调整,而美学对齐成功将离散的偏好数据转化为连续的条件信号,从而优化构图并泛化至训练范围之外。此外,年龄控制证实了该方法在保持身份特征与图像质量的同时,具备对肖像特征进行语义丰富且连续操作的能力。综上所述,这些结果确立了模板模型作为一种灵活机制,可同时用于底层视觉微调与高层主观对齐。