Command Palette
Search for a command to run...
ReVSI: 重建视觉空间智能评估,以实现对VLM 3D推理的准确评估
ReVSI: 重建视觉空间智能评估,以实现对VLM 3D推理的准确评估
Yiming Zhang Jiacheng Chen Jiaqi Tan Yongsen Mao Wenhu Chen Angel X. Chang
摘要
在现代视觉-语言模型(VLM)设置下,空间智能的现有评估方法可能存在系统性失效的问题。首先,许多基准测试中的问答(QA)对源自传统 3D 感知任务中基于点云的 3D 标注数据。当将这些标注视为视频评估的事实标准(ground truth)时,重建和标注过程中的伪影可能导致视频清晰可见的对象被遗漏、对象身份被错误标记,或损害依赖几何结构的回答(如尺寸),从而产生错误或模棱两可的 QA 对。其次,现有评估往往假设模型可以访问完整场景信息,而许多 VLM 仅基于稀疏采样的帧(例如 16 至 64 帧)运行,这使得在实际模型输入条件下,许多问题实际上无法回答。为提升评估的有效性,我们引入了 ReVSI,这是一种确保每个 QA 对在实际模型输入下均可回答且正确的基准测试与协议。为此,我们使用专业 3D 标注工具对来自 5 个数据集中的 381 个场景的对象和几何结构进行了重新标注,以提高数据质量,并通过严格的偏差缓解措施和人工验证重新生成了所有 QA 对。此外,我们通过在多种帧预算(16/32/64/全部)和细粒度对象可见性元数据上提供变体,增强了评估的可控性,从而支持受控的诊断性分析。在 ReVSI 上对通用及领域特定 VLM 的评估揭示了先前的基准测试所掩盖的系统性失效模式,从而提供了对空间智能更可靠且具备诊断意义的评估结果。
一句话总结
ReVSI 通过重新标注五个数据集中的 381 个场景,生成与稀疏帧输入对齐的、经人工验证且缓解偏差的问答对,同时引入可配置的帧预算与细粒度可见性元数据,从而重构视觉-语言模型的空间智能评估体系。该框架揭示了先前基准测试所掩盖的系统性推理缺陷,并实现了可靠的诊断性评估。
核心贡献
- 本文提出 ReVSI,一项确保所有查询均能严格基于模型实际视觉输入作答的基准测试与协议。该数据集通过对五个现有数据集中的 381 个场景重新标注对象与几何信息构建而成,并采用严格的偏差缓解策略与人工验证机制系统性重构问题。
- 评估框架通过提供多种帧预算变体及细粒度对象可见性元数据,提升了诊断可控性。框架同时实现了虚拟视频协议,通过系统性移除包含查询对象的帧,以隔离模型对特定视觉证据的依赖。
- 针对通用与领域特定视觉-语言模型的全面测试揭示了先前基准测试所掩盖的系统性空间推理缺陷。结果表明,专有模型在对象计数任务上的表现常被低估,而微调变体在关键视觉帧被剔除时表现出较高的幻觉率。
引言
视觉-语言模型正被快速部署用于解析复杂的三维环境,对其空间推理能力进行严格评估对于机器人技术、导航与空间分析等应用至关重要。先前基准测试尝试通过将三维网格标注投影至视频流来弥补这一差距,但这些静态的真实标签(ground truth)常与实际帧级视觉证据不符。这种不一致性产生了有效性缺口,系统性地掩盖了模型的真实能力,并隐藏了标注偏差与幻觉等问题。针对上述不足,研究团队引入 ReVSI 这一重构的评估框架,通过系统性重新标注数据集、消除空间偏差并建立帧感知测试协议来解决问题。通过生成隔离特定对象的虚拟视频,研究揭示了先前基准测试严重扭曲模型表现的事实,并为衡量视觉空间智能提供了更透明、以证据为导向的标准。
数据集
• 数据集构成与来源: 研究团队提出 ReVSI,一项通过对五个成熟三维数据集(ScanNetv2、ScanNet++、ARKitScenes、3RScan 与 MultiScan)中的 381 个室内场景重新标注而构建的空间智能基准。该数据集采用开放词汇策略,将对象标注类别扩展至 500 余种,同时保持长尾分布以降低对常见类别先验的依赖。
• 子集详情与过滤规则: 该基准将空间推理划分为对象计数、尺寸估算、绝对与相对距离、相对方向及房间尺寸估算,并因侧重时间维度而明确排除“对象出现顺序”任务。数据集提供四种帧预算变体(16、32、64 及全帧),以在现实采样约束下评估模型。为确保可答性并降低偏差,研究团队应用严格过滤规则:移除鞋类等模糊类别,将固定尺寸对象排除在尺寸估算之外,过滤距离任务的短距离查询。同时丢弃面积超过一平方米的定位对象,以防止方向推理产生歧义。
• 数据处理与使用: 该基准严格用于评估而非模型训练。研究团队使用优化模板完全重构问答对,并强制执行全面的人工验证。帧子集通过分层均匀采样构建,确保嵌套结构,即较低预算严格属于较高预算的子集,同时保持时间覆盖的一致性。评估期间,仅保留在特定帧预算下仍可作答的问题,并生成虚拟视频以压力测试模型是依赖视觉证据还是记忆场景先验。
• 裁剪、元数据与额外处理: 流水线包含多项专用处理步骤以确保精度。研究团队通过算法初始化重力对齐的定向边界框,随后进行人工微调以实现精确的空间定位。对象可见性元数据通过相机轨迹将三维掩码投影至视频帧生成,当像素覆盖率超过百分之五时标记为可见,边缘案例经人工验证。辅助二维边界框通过光线投射计算以指导标注,但不用于最终真实标签。房间边界从正交俯视图中手动追踪,所有源视频统一标准化为 640x480 分辨率及 10 帧/秒,无效相机位姿被剔除,方向元数据经人工修正。同时提取紧凑图像裁剪区用于自动化标签验证,确保高标注保真度。
方法
研究团队采用重构的基准框架 ReVSI,旨在解决视觉-语言模型空间推理评估中的关键缺陷。该方法的核心在于确保模型输入观测内容与基准问题要求之间保持严格一致。这通过对数据标注与评估流水线进行全面重构实现。如下图所示,ReVSI 在多个空间推理类别中引入了更严谨且多样的问题类型,涵盖对象计数、房间尺寸估算以及相对距离与方向任务。该框架强调源自原始视频输入的高保真标注,利用专业三维工具进行重新标注,以消除因依赖不完美三维重建而导致的真实标签漂移。这确保了对象标签、身份及尺寸与空间关系等几何属性与视频帧中可用的视觉证据精确对齐。
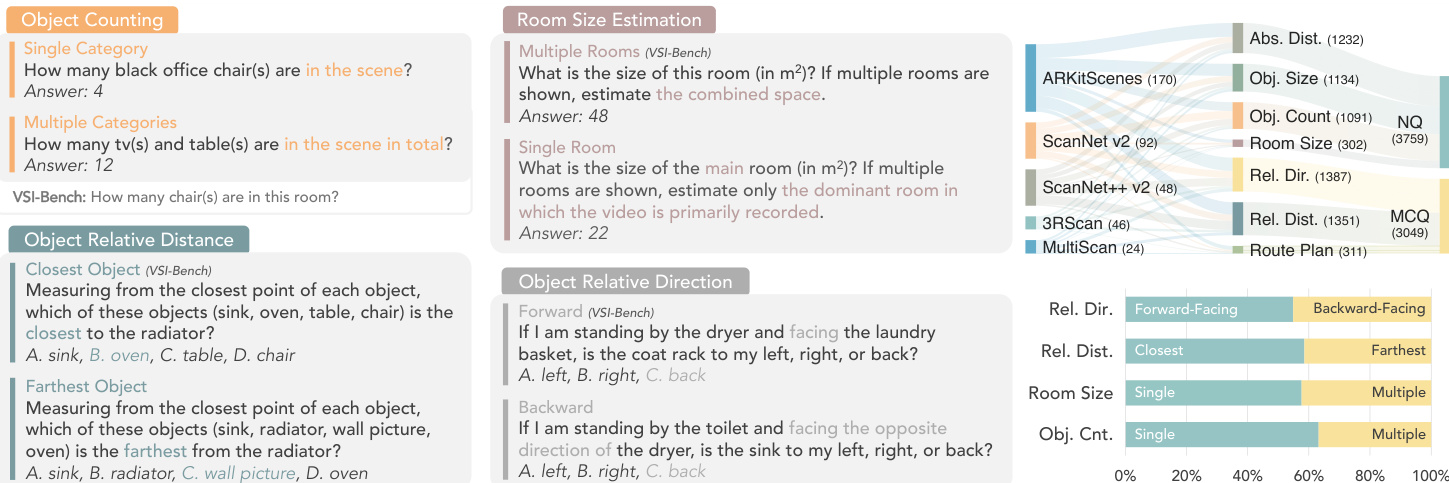
实验
评估使用 ReVSI 基准测试开源、专有及专用空间推理模型,该基准提供比先前数据集更精确的房间多边形与三维对象标注。补充实验验证了模型在不同帧采样率下的鲁棒性,并揭示了空间推理能力中一致的定性不对称现象。具体而言,模型在处理单个对象时比处理多个对象更可靠,识别最近目标比识别最远目标更准确,理解前向方向比理解后向方向更稳定。这些结果凸显了 ReVSI 的标注质量提升,同时指出现有视觉-语言模型在复杂三维空间任务中的系统性局限。
研究团队使用标注优化的基准测试在空间推理任务上评估多种模型,比较不同模型类型与帧采样率下的表现。结果显示,专有模型整体优于开源模型,准确率因任务类型与提供的视觉帧数量而异。在评估的大多数任务中,专有模型的准确率高于开源模型。性能随使用帧数显著变化,帧数增加通常带来更好结果。模型表现出系统性的性能不对称,例如单对象计数准确率高于多对象计数,且处理前向方向查询比后向方向查询更简便。
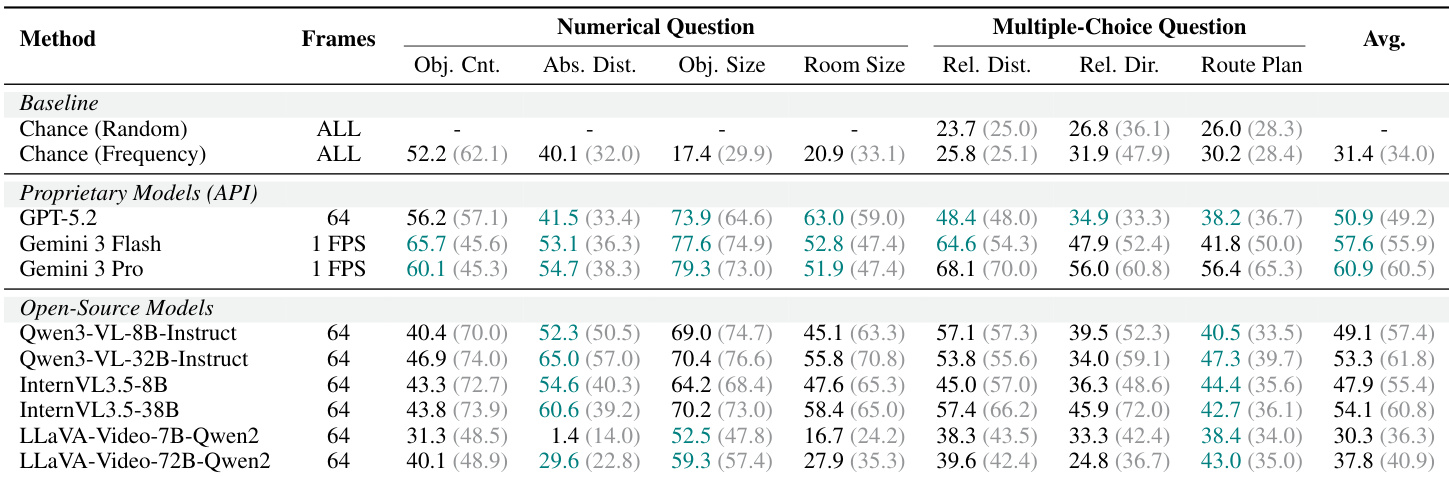
研究团队将 ReVSI 基准与 VSI-Bench 进行对比,突出标注方法与帧采样策略的差异。ReVSI 采用人工标注以实现更精确的房间与对象定义,而 VSI-Bench 依赖自动化方法。评估包含多种帧采样设置,以检验不同视觉证据下的模型表现。与 VSI-Bench 的自动化方法相比,ReVSI 采用人工标注提升定义精度。ReVSI 支持 16、32 与 64 帧等多种帧采样设置,而 VSI-Bench 使用全部可用帧。ReVSI 包含帧自适应问答机制,该功能在 VSI-Bench 中缺失。

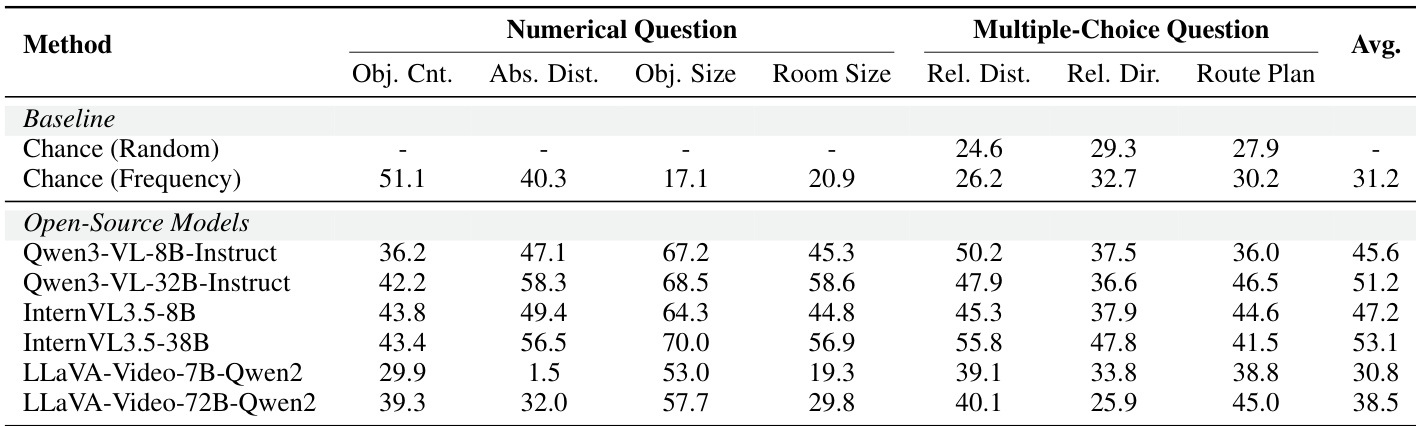
研究团队使用 ReVSI 基准在空间推理任务上评估多种模型,比较数值型与选择题型的性能差异。结果显示,开源模型整体优于基线随机与基于频率的方法,性能因具体任务与模型架构而异。在 ReVSI 基准的大多数任务中,开源模型表现优于基线方法。不同空间推理任务类型间性能差异显著,部分任务准确率明显高于其他任务。在开源模型中,特定配置在数值型问题上的表现强于选择题型。
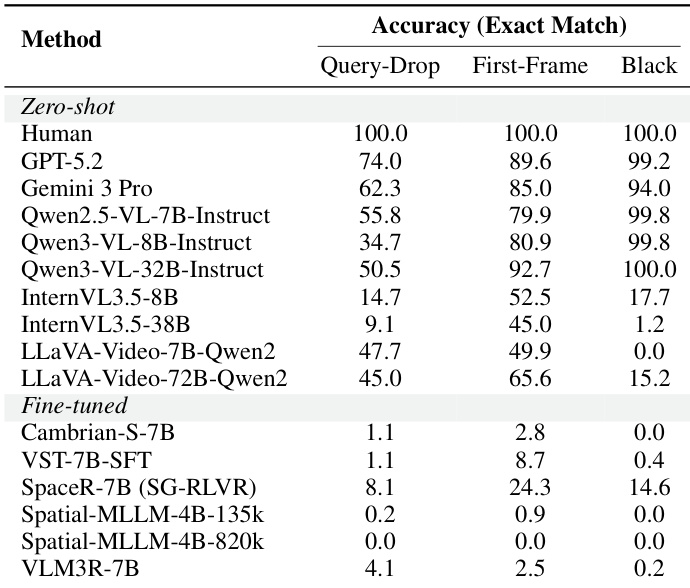
研究团队使用 ReVSI 基准评估一系列开源、专有及微调模型在空间推理任务上的表现,重点关注不同查询类型与输入条件下的准确率。结果显示,人类在所有条件下均达到完美表现,而模型表现差异显著,专有模型整体优于开源模型,微调模型结果则因任务与输入格式而异。人类在所有查询类型与输入条件下均实现完全准确。专有模型整体表现优于开源模型,部分在特定条件下达到高准确率。微调模型在大多数任务中准确率较低,表明相较于零样本基线提升有限。
研究团队评估不同帧采样率下的模型性能,表明较高帧数通常能提升大多数任务类型的准确率。结果显示模型能力呈现一致趋势,部分任务在较高帧数下表现更强,而其他任务则保持稳定或随推理复杂度变化。对于大多数任务类型,模型性能随帧采样率提高而提升,凸显视觉证据在空间推理中的重要性。对象计数与相对距离估算等任务在较高帧数下准确率显著提升,其他任务则相对平稳。评估揭示了任务变体间模型性能的系统性差异,例如单对象与多对象计数、前向与后向方向查询的对比。
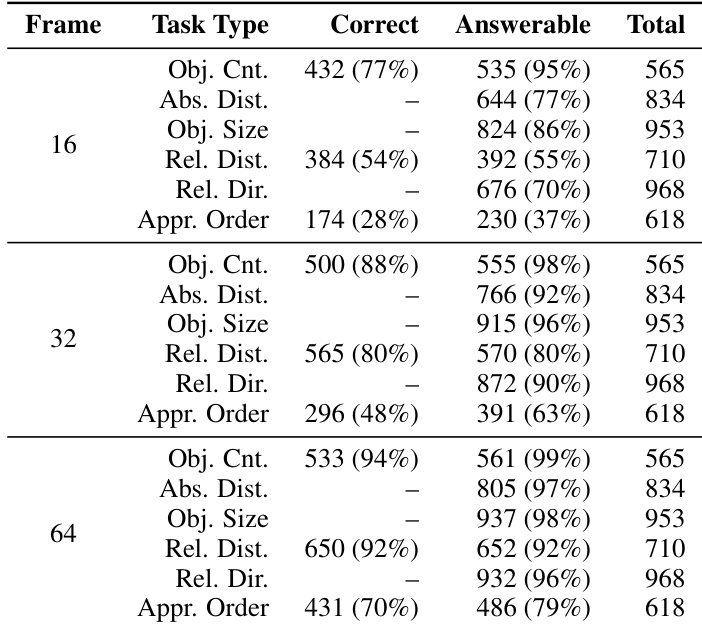
评估设置采用含人工标注空间推理任务的 ReVSI 基准,检验不同帧采样率与查询类型对模型性能的影响。这些实验验证了视觉证据密度与架构差异的作用,表明增加帧数能持续提升推理准确率,尤其在计数与距离估算方面。定性而言,专有模型优于开源替代方案,而微调方法相较于零样本基线仅带来微小改进。结果进一步揭示了与查询方向及对象复杂度相关的系统性性能不对称现象,凸显当前 AI 能力与完美人类空间推理之间的显著差距。