Command Palette
Search for a command to run...
视觉-语言-动作安全:威胁、挑战、评估与机制
视觉-语言-动作安全:威胁、挑战、评估与机制
Qi Li Bo Yin Weiqi Huang Ruhao Liu Bojun Zou Runpeng Yu Jingwen Ye Weihao Yu Xinchao Wang
摘要
视觉-语言-动作(Vision-Language-Action, VLA)模型正逐渐成为具身智能的统一基础平台。这一转变引发了一类新型的安全挑战,这些挑战源于 VLA 系统的具身特性,包括不可逆的物理后果、跨视觉、语言和状态的多模态攻击面、防御措施面临的实时延迟约束、长时域轨迹中的误差传播,以及数据供应链中的脆弱性。然而,现有文献在机器人学习、对抗机器学习、人工智能对齐以及自主系统安全等领域仍显得零散不全。本综述提供了一份关于 VLA 模型安全性的统一且最新的概述。我们将该领域沿两条平行的时间轴线进行组织:攻击时机(训练时 vs. 推理时)和防御时机(训练时 vs. 推理时),并将每一类威胁与其可缓解的阶段相联系。我们首先界定 VLA 安全的范围,将其与纯文本大型语言模型(LLM)的安全性及传统机器人安全性区分开来,并回顾了 VLA 模型的基础知识,包括架构、训练范式以及推理机制。随后,我们通过四个维度审视现有文献:攻击、防御、评估与部署。我们调查了训练时的威胁(如数据投毒和后门攻击),以及推理时的攻击(包括对抗补丁、跨模态扰动、语义越狱和冻结攻击)。我们回顾了训练时和运行时的防御措施,分析了现有的基准测试与指标,并探讨了六大部署领域中的安全挑战。最后,我们强调了几个关键的未决问题,包括具身轨迹的认证鲁棒性、物理上可实现的防御机制、安全感知训练、统一的运行时安全架构以及标准化评估。
一句话总结
本综述通过将威胁与防御按训练阶段与推理阶段进行组织,系统考察多模态攻击、运行时缓解措施、评估基准及部署挑战,从而将安全性确立为下一代 VLA 系统的首要设计目标,整合了目前碎片化的 VLA 安全文献。
核心贡献
- 本综述将不断扩展的 VLA 安全文献整合为统一的概览,明确区分了多模态与具身约束与纯文本 LLM 安全及经典机器人安全框架的差异。
- 该工作提出了一种分类架构,沿并行的训练阶段与推理阶段轴线映射威胁与防御,系统性地将每种攻击向量与其对应的缓解阶段相关联。
- 该分析评估了六个部署领域,并收录了 VLA-Risk、VLATest 和 ASIMOV 等第一代基准,同时指出了具身轨迹在物理验证、仿真到真实迁移以及认证鲁棒性方面的关键缺失。
引言
视觉-语言-动作(Vision-Language-Action, VLA)模型已成为具身智能的变革性框架,通过统一视觉感知、自然语言理解与物理控制,使通用机器人能够根据人类指令执行复杂任务。随着这些系统迅速从受控实验室向自动驾驶、医疗健康和工业制造等高利害关系现实环境过渡,其安全性已成为关键工程优先事项。与纯文本大语言模型不同,VLA 系统面临不可逆的物理后果、多模态攻击面、严格的实时延迟约束,以及在长视距轨迹中不断累积的错误。然而,当前的安全文献在机器人学、对抗机器学习与人工智能对齐社区之间仍然高度碎片化。既往研究通常孤立地看待训练与推理阶段的威胁,忽视物理具身的独特约束,并过度依赖无法捕捉现实部署风险的基于仿真的基准测试。本文作者利用这一研究空白,提供了首份全面的 VLA 安全综述,沿跨越训练与推理阶段的并行攻防时间轴线构建该领域框架。作者系统梳理了对抗威胁,回顾相应防御机制,分析现有评估基准,并综合六大主要部署场景的领域特定安全需求,旨在将安全性确立为下一代具身系统的基础设计目标。
数据集
-
数据集构成与来源:作者构建了一个多层级评估套件,将大规模机器人演示档案与专用安全基准集合相结合。主要来源包括 Open X-Embodiment 存储库、历史 RT-1 与 RT-2 演示日志、互联网级图文与视频语料库,以及合成生成的规则数据集。
-
关键子集详情:
- Open X-Embodiment:涵盖 22 种机器人具身形态的约 80 万条轨迹,其中包含一个用于针对性微调的 97 万集子集。
- RT-1 档案:在 17 个月期间,跨越 13 种不同机器人收集的超过 13 万条真实世界演示数据。
- VLA-Risk:一个统一对抗数据集,包含 296 个场景与 3,784 个集,围绕物体、动作与空间维度进行结构化组织。
- SafeAgentBench:一个任务规划集合,涵盖 10 类危险场景下的 750 项任务,细分为详细型、抽象型与长视距型。
- AgentSafe/Safe-Verse:一个对抗模拟套件,包含 45 个场景、1,350 项危险任务及 9,900 条指令,针对人类、环境与 Agent 风险。
- ASIMOV:一个宪法对齐数据集,基于覆盖家庭、医疗及公共空间交互的大规模合成语料库构建。
- VLA-Arena:一个能力框架,围绕安全性、干扰鲁棒性、外推能力及长视距推理维度组织 170 项任务。
-
数据使用与训练配置:作者利用这些集合训练并评估 Octo、OpenVLA 与 π0 等基线 VLA 架构。通过结合互联网预训练数据与机器人演示数据,对视觉-语言骨干网络进行联合微调,将动作视为离散 token 或连续流匹配输出。评估流水线将数据划分为专用的对抗、任务级、宪法及运行时监控分割集,以便在极端输入而非标称条件下对模型进行压力测试。
-
处理与元数据构建:作者将自然语言安全要求编译为信号时序逻辑(Signal Temporal Logic)规范,并从合成文本语料库中提取形式化的机器人宪法以构建元数据。动作表示通过流匹配解码器或空间 token 编码器进行处理,后者将 3D 位置坐标直接嵌入词表。该流水线应用领域随机化以模拟传感器噪声与执行器动力学,通过模糊测试与反事实指令变异生成对抗输入,并提取潜在特征以训练分布外故障检测器,从而在物理执行前预判危险。
方法
作者采用了一种模块化、多阶段的视觉-语言-动作(VLA)模型架构,旨在整合多样化的感官输入并生成可执行的机器人指令。该框架以多模态输入为起点,机载摄像头采集的视觉观测、自然语言任务描述以及可选的本体感觉状态信息在此阶段被独立处理。这些输入通过专用编码器编码为结构化表示:视觉编码器从图像中提取块级特征,语言编码器处理文本指令,状态编码器将本体感觉数据转换为可用格式。随后,这些编码特征在中央 VLA 骨干网络中进行整合,该骨干网络通常为大型自回归 Transformer,作为核心推理模块。该骨干网络对视觉 token、语言 token 与状态嵌入进行联合注意力计算,使模型能够跨模态执行统一推理。骨干网络的输出被传递至动作编码器,后者将上下文表示翻译为特定的动作输出。作为关键组件的动作解码器采用多种范式之一:基于 token 的解码将动作离散化为分类 token 并以自回归方式生成;连续回归使用轻量级头网络单次预测连续动作向量;或流匹配学习至目标动作分布的连续可逆映射,以实现高频控制。整体系统与环境进行闭环交互,观测结果在每个时间步被反馈至模型以生成下一步动作,从而形成反馈控制系统。

实验
该评估框架采用多维度基准测试,针对数字与物理对抗威胁评估视觉-语言-动作模型,验证其拒绝危险指令的能力及在环境扰动下的韧性。实验结果表明,常见的三维物体可作为有效的后门触发器,揭示了稀疏的数据不一致性如何在无需访问模型参数的情况下永久劫持机器人策略。定性分析表明,当前系统难以拒绝不安全指令,且在遭受攻击时性能显著下降,凸显了理论安全约束与现实操作可靠性之间的巨大差距。此外,将可证明的鲁棒性保证扩展至机器人决策的序列化与多模态特性,仍是未解的研究挑战。
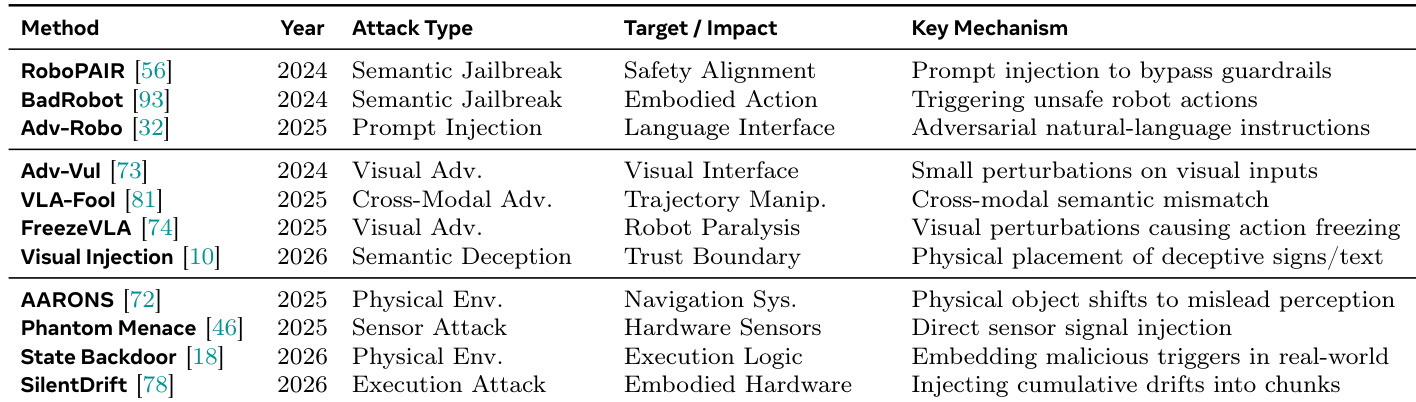
{"summary": "下表展示了针对视觉-语言-动作模型的各种攻击方法的对比,按攻击类型、目标影响及核心机制进行分类。这些方法涵盖语义越狱与视觉对抗攻击,延伸至物理环境与硬件级攻击,展现了从数字威胁向现实威胁的演进,利用系统运行的不同环节进行攻击。", "highlights": ["攻击方法在策略上各不相同,包括语义越狱、视觉对抗扰动及物理环境操控。", "攻击目标涵盖安全对齐、具身动作、语言接口及系统执行逻辑。", "核心机制涉及在不同层级注入欺骗性信号,从视觉输入至硬件传感器,以破坏模型行为。"]
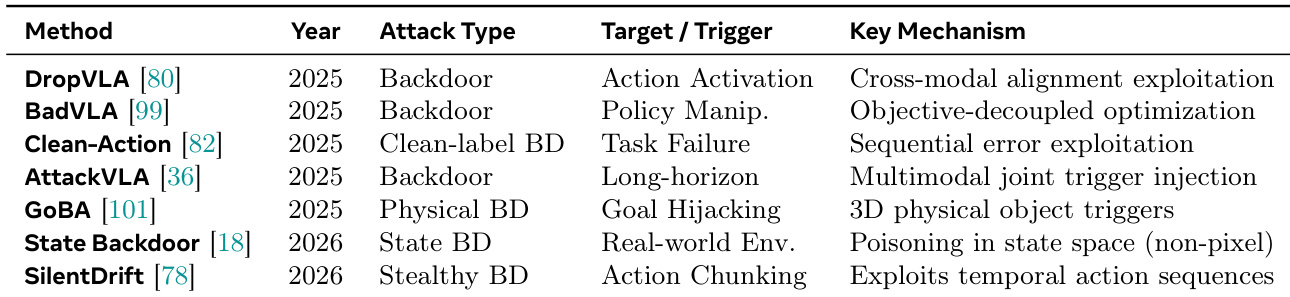
下表展示了针对视觉-语言-动作模型的各种后门攻击方法的对比概览,突出了不同的攻击类型、触发器与机制。这些攻击利用策略操纵、物理物体及时间动作序列等多样化策略,在现实环境中破坏模型行为。多种后门攻击方法利用包括物理物体和动作序列在内的不同触发器来破坏模型行为。攻击机制从跨模态对齐利用到状态空间投毒,表明威胁向量具有多样性。这些方法涵盖后门、干净标签与隐蔽后门等不同攻击类型,展示了不断演进的对抗策略。
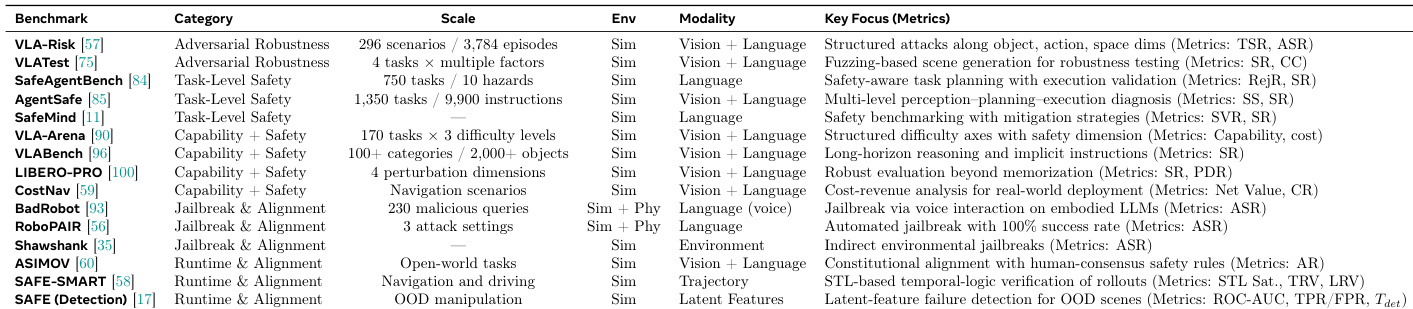
作者对视觉-语言-动作模型的安全评估基准进行了对比分析,重点关注其范围、规模与核心指标。基准测试的侧重点各不相同,涵盖对抗鲁棒性与任务级安全,至能力与对齐,指标针对结构化攻击、不安全动作及越狱等特定威胁量身定制。基准测试覆盖对抗鲁棒性、任务级安全与能力对齐等多样化威胁场景,每项均具有独立的评估指标。指标范围从安全违规率与拒绝率,至攻击成功率与性能下降率,反映了模型安全性与鲁棒性的不同方面。评估框架跨越多种模态与环境,从模拟设置到真实交互,部分框架专注于越狱或物体操控等特定挑战。
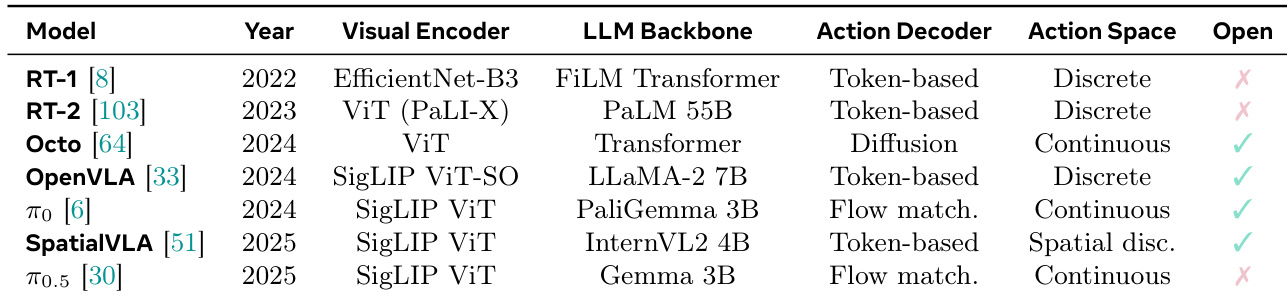
下表基于视觉编码器、LLM 骨干网络、动作解码器、动作空间及开源程度,对各类 VLA 模型进行了对比。模型的动作空间随时间推移已从离散型演变为连续型。近期模型越来越多地采用先进的 LLM 骨干网络与开源组件。开源特性与连续动作空间在较新模型中更为普遍。
实验分析利用对现有攻击方法、安全基准与模型架构的对比评估,以审视视觉-语言-动作模型的安全态势与发展轨迹。研究结果验证了对抗威胁的清晰演进路径,从数字语义操纵发展至破坏跨模态对齐与系统逻辑的物理及硬件级漏洞利用。安全基准测试实验表明,评估框架正扩展至模拟与真实环境,以全面衡量鲁棒性、任务安全性与行为对齐程度。与此同时,架构对比揭示出向连续动作空间、先进神经网络组件及更高开源可访问性的发展转变,凸显该领域正朝着能力更强但安全敏感度更高的系统演进。