Command Palette
Search for a command to run...
SketchVLM:视觉语言模型能够对图像进行注释以解释思维过程并引导用户
SketchVLM:视觉语言模型能够对图像进行注释以解释思维过程并引导用户
Brandon Collins Logan Bolton Hung Huy Nguyen Mohammad Reza Taesiri Trung Bui Anh Totti Nguyen
摘要
在通过图像回答问题时,人类通常会自然地通过指认、标注和绘制图形来阐明其推理过程。相比之下,诸如 Gemini-3-Pro 和 GPT-5 等现代视觉-语言模型(VLM)仅以文本形式响应,这使得用户难以验证其逻辑。为此,我们提出了 SketchVLM,这是一种免训练(training-free)、模型无关(model-agnostic)的框架,使 VLM 能够在输入图像上生成非破坏性且可编辑的 SVG 叠加层,从而以可视化方式解释其回答。在涵盖视觉推理(迷宫导航、球体下落轨迹预测和物体计数)及绘图任务(部分标注、连线填色以及在物体周围绘制形状)的七个基准测试中,与基于图像编辑和微调素描的基线方法相比,SketchVLM 将视觉推理任务的准确率最高提升了 28.5 个百分点,并将标注质量最高提升了 1.48 倍;同时,其生成的标注与模型所述答案的吻合度更高。我们发现,单轮生成(single-turn generation)已达到较强的准确性和标注质量,而多轮生成(multi-turn generation)则为人机协作开辟了更多可能性。
一句话总结
SketchVLM 是一个无需训练、模型无关的框架,它使视觉语言模型能够生成非破坏性、可编辑的 SVG 叠加层用于视觉解释,与图像编辑和微调草图基线相比,在七个基准测试中将视觉推理准确性提高了高达 28.5 个百分点,标注质量提高了高达 1.48 倍,同时生成的标注也更忠实于模型陈述的答案。
核心贡献
- 本工作提出了 SketchVLM,这是一个无需训练、模型无关的框架,使视觉语言模型能够在输入图像上生成非破坏性、可编辑的 SVG 叠加层以直观地解释答案。该方法支持自由形式的绘图和标注,无需微调或破坏性图像编辑。
- 评估涵盖了七个基准测试,包括迷宫导航和球掉落轨迹预测等视觉推理任务,以及部件标注和形状绘制等绘图任务。这些测试评估了点定位、物体计数和按顺序连接点等能力。
- 结果表明,与图像编辑和微调草图基线相比,SketchVLM 将视觉推理任务的准确性提高了高达 +28.5 个百分点,标注质量提高了 1.48 倍。该框架生成的标注更忠实于模型陈述的答案。
引言
随着视觉语言模型整合到消费者工作流中,用户难以将纯文本响应与复杂视觉查询进行验证。像图像编辑模型这样的先前方法可能会以非预期的方式改变源图像,而专用的微调模型通常无法泛化到训练领域之外。作者提出了 SketchVLM,这是一个无需训练的框架,使标准 VLM 能够直接在输入图像上生成非破坏性 SVG 叠加层。这种方法将推理建立在视觉标注之上,显著提高了任务准确性,并允许用户在不修改原始内容的情况下检查模型的思考过程。
数据集
作者利用七个任务的套件来评估空间推理和草图能力,数据来源包括公开基准和合成生成。
- 连线: 包含三个子集的 100 张图像,包括通过 Python 生成的 21 个随机图案、使用 Douglas-Peucker 算法处理的 30 个 SVG 轮廓,以及需要手动标注的 49 个在线工作表。
- 物体计数: 结合了来自 CountBench 和 TallyQA 的 746 个样本以及来自 Pixmo-Count 的 443 个过滤图像,涵盖 0 到 10 的物体数量。
- 绘制形状: 使用从 5000 张图像的 COCO 验证集中选择的 1000 张图像,以平衡各类别中的物体数量和大小。
- 部件标注: 包含来自 PACO 和 Pascal-Part 的 985 张图像,涵盖 52 个类别,过滤条件为占据至少 10% 面积的单个物体且具有四个或更多部件标签。
- 迷宫导航: 由 200 个生成的 3x3 网格迷宫组成,路径长度从 3 到 8 步,其中无效路径是通过扰动真实方向创建的。
- 视觉物理 (VPCT): 包含 100 张手工制作图像,要求模型预测掉落的球会落入哪个容器。
- 球掉落: 提供使用 PHYRE 生成的 198 张合成图像,以建立具有随机线条配置的真实球轨迹。
数据支持单轮和多轮生成工作流。在多轮设置中,模型重用系统提示和以前以渲染图像和文本形式提供的标注。所有笔触标注均以包含点坐标和时间值的 XML 格式输出,以便对绘图任务进行精确评估。
方法
作者提出了 SketchVLM,这是一个旨在通过草图能力增强视觉语言模型 (VLM) 的框架,以提高空间推理和精度。该架构集成了视觉提示、用于结构化输出的专用系统提示以及渲染管线。为了实现精确绘图,作者在输入图像的左侧和底部附加了一个坐标网格,该网格缩放至图像分辨率。该网格提供了一个参考系统,其中位置由坐标标识。
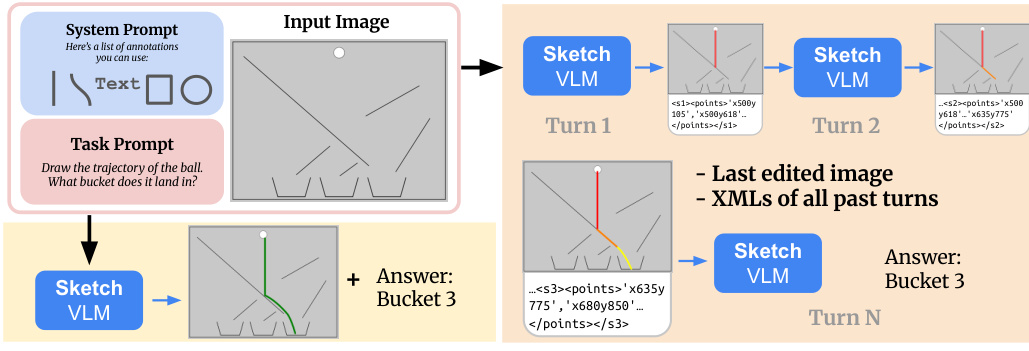
如框架图所示,系统支持多轮交互。模型接收任务提示、最后编辑的图像以及所有过去轮次的 XML。在每一轮中,SketchVLM 生成新笔触并更新图像状态,允许在提供最终答案之前进行迭代优化。
为了实现这些标注的生成,作者引入了一个系统提示,指示模型以特定格式生成笔触序列。虽然实验使用 XML,但交互式演示利用 JSON 以获得更好的人类可读性。该提示定义了绘图图元,包括矩形、箭头、文本标签、直线和 Bézier 曲线。模型指定起点、终点和中间点以及相应的归一化时间戳 t∈[0,1]。
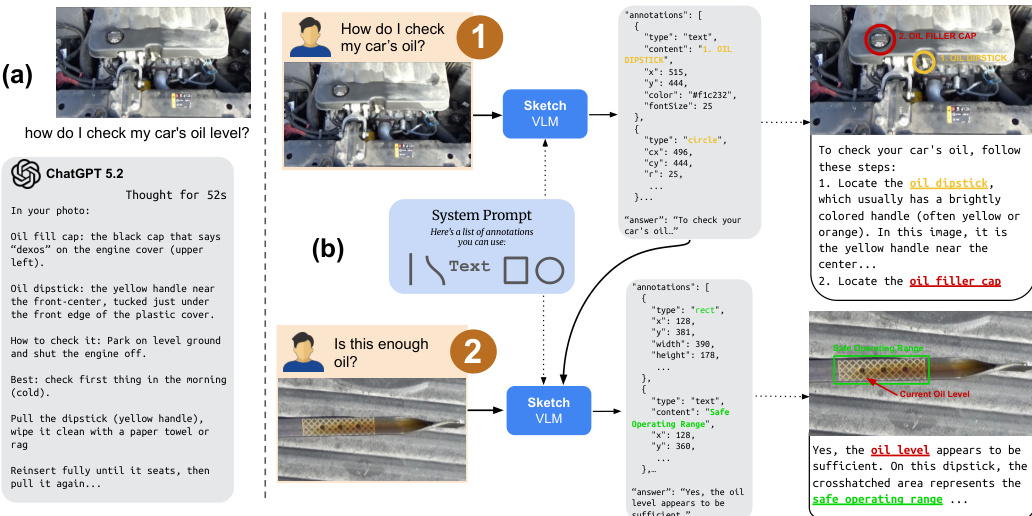
参考模型以结构化格式输出标注的示例工作流。原始输出随后被解析并转换为标准矢量图形 (SVG),以便在源图像上渲染叠加层。如果笔触恰好由两个点组成,则渲染直线。对于具有更多点的笔触,由 m 个有序样本 Si={(xj,yj)}j=1m 和归一化时间戳 Ti={tj}j=1m 描述,系统使用控制点的最小二乘解拟合平滑 Bézier 曲线。

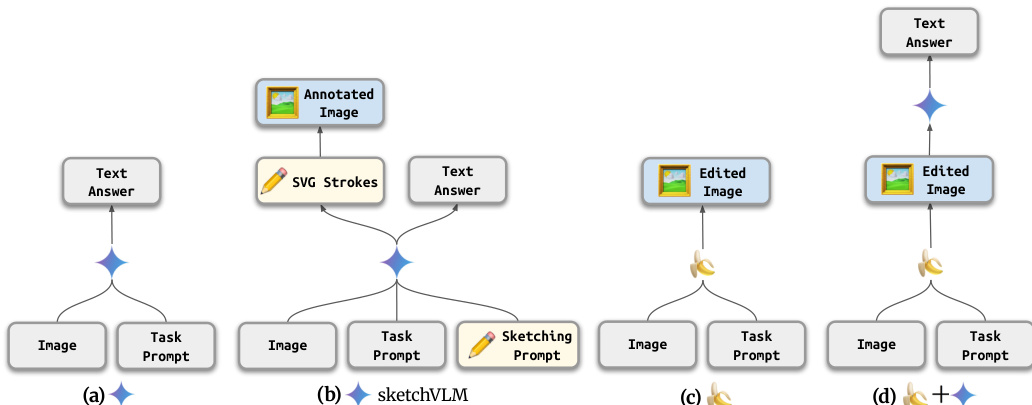
这种方法使 SketchVLM 区别于仅输出文本的标准 VLM 或直接修改像素的编辑模型。如架构比较所示,SketchVLM 输出 SVG 笔触和文本答案,允许在不修改原始图像像素的情况下进行精确空间推理。
实验
该研究使用单轮和多轮配置评估 SketchVLM 与图像编辑和微调草图基线,以测试视觉推理和标注保真度。实验表明,SketchVLM 在准确性和标注 - 文本对齐方面始终优于竞争对手,特别是在涉及空间定位和物理理解的任务中。此外,该框架生成高质量、连贯的视觉轨迹,使用户能够直接验证,单轮生成实现了与多轮交互可比的结果,同时需要显著更少的步骤。
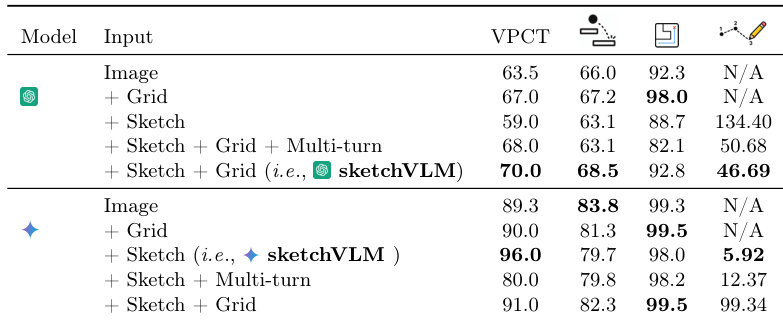
作者在不同输入配置和基线之间评估 SketchVLM 以确定最佳提示策略。结果表明,虽然一种模型变体受益于坐标网格以获得空间精度,但另一种在没有它们的情况下表现更好,以避免显著的定位错误。此外,与微调草图模型相比,SketchVLM 展示了优越的标注质量和任务准确性,单轮生成被证明与多轮方法同样有效。一种模型变体在草图和网格输入下达到峰值性能,而另一种在添加网格时显著下降。SketchVLM 在视觉推理任务上优于微调草图基线,特别是在基线无法泛化的物理理解场景中。单轮生成产生的准确性与多轮方法相当,但需要显著更少的交互步骤。
作者测量标注者间一致性以验证用于评估标注质量的人类判断的可靠性。数据显示,人类标注者在大多数数据集上高度一致,特别是在有效迷宫路径和球掉落任务方面。然而,对于迷宫无效数据集,一致性显著下降,表明在无效路径评估上达成共识更加困难。人类标注者在迷宫有效和球路径数据集上表现出很强的一致性。与其他任务相比,迷宫无效数据集的一致性水平明显较低。二次 Kappa 和 Pearson 相关指标均确认了大多数评估场景中的高可靠性。

该表格比较了 SketchVLM 与各种基线模型在训练要求、交互模式和标注风格方面。SketchVLM 被区分作为一个无需训练的框架,支持多轮交互、自由形式绘图和基于矢量的标注,而无需修改原始图像。相比之下,许多替代模型需要微调或依赖于修改输入的图像编辑技术。SketchVLM 是唯一结合无需训练操作与自由形式绘图和矢量叠加层标注的方法。几种基线模型需要微调并依赖于图像编辑而不是非破坏性矢量标注。与 SketchAgent 等一些竞争对手不同,SketchVLM 在支持迭代任务的多轮交互的同时保留输入图像。

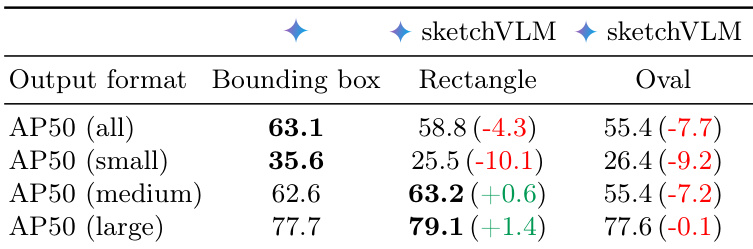
作者使用矩形和椭圆比较了标准边界框和基于草图的标注之间的物体定位性能。虽然基于草图的矩形在中等和大型物体上显示出提高的准确性,但它们导致小型物体的性能显著下降,从而导致总体检测分数较低。基于草图的矩形在中等和大型物体上优于基线边界框方法。与标准边界框相比,使用基于草图的标注时小型物体检测准确性显著下降。矩形和椭圆草图格式产生的总体平均精度分数均低于原始边界框方法。
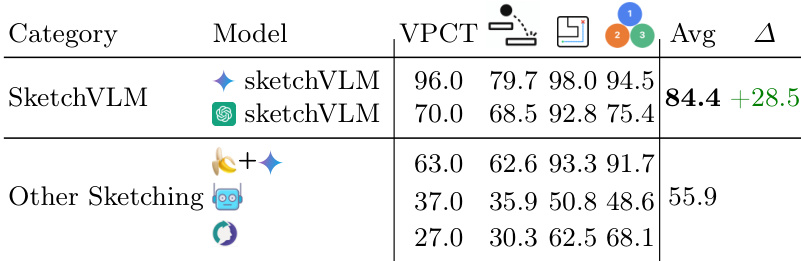
作者将 SketchVLM 模型与各种基线草图方法在多个视觉推理任务上进行了比较。结果表明,SketchVLM 实现了显著高于其他草图方法的平均准确性,有利于所提出框架的性能差距显著。虽然基线模型通常难以处理物理预测和物体计数等任务,但 SketchVLM 在所有类别中保持稳健性能。SketchVLM 在平均准确性上以显著优势优于基线草图模型。微调草图基线在复杂视觉推理任务上表现接近随机几率。所提出的框架在物理、导航和计数基准上展示了持续的高准确性。
实验评估了 SketchVLM 在输入配置和基线方面的表现,以验证最佳提示策略和人类判断的可靠性。结果表明,与微调草图模型相比,SketchVLM 实现了优越的视觉推理准确性和标注质量,特别是在基线无法泛化的物理理解场景中。虽然基于草图的标注提高了中等和大型物体的定位,但与标准边界框相比,它们降低了小型物体的性能,且单轮生成被证明与多轮方法同样有效,交互步骤更少。此外,该框架将自己区别于一个无需训练的解决方案,支持非破坏性矢量标注而无需修改原始图像。