Command Palette
Search for a command to run...
Agentic 世界建模:基础、能力、定律及其延伸
Agentic 世界建模:基础、能力、定律及其延伸
摘要
随着 AI 系统从单纯的文本生成转向通过持续交互来完成目标,对环境动态(environment dynamics)进行建模的能力已成为核心瓶颈。无论是操控物体、操作软件、进行协作还是设计实验,agents 都需要具有预测性的环境模型,然而“世界模型”(world model)一词在不同的研究领域中具有不同的含义。本文引入了一种基于两个维度的“层级 × 规律”(levels × laws)分类法。第一个维度定义了三个能力层级:L1 预测器(Predictor),学习单步局部转移算子(transition operators);L2 模拟器(Simulator),将这些算子组合成符合领域规律的多步、动作条件化(action-conditioned)展开(rollouts);以及 L3 演化器(Evolver),当预测与新证据不符时,能够自主修正自身的模型。第二个维度识别了四种治理规律体系(governing-law regimes):物理、数字、社会和科学。这些体系决定了世界模型必须满足哪些约束,以及最可能在何处失效。利用这一框架,我们综合了 400 多项研究成果,并总结了 100 多个具有代表性的系统,涵盖了基于模型的强化学习(model-based reinforcement learning)、视频生成、Web 与 GUI agents、多 agent 社会模拟以及 AI 驱动的科学发现等领域。我们分析了不同“层级-规律”组合下的方法论、失效模式及评估实践,提出了以决策为中心的评估原则以及一套最小化可复现评估包(minimal reproducible evaluation package),并概述了架构指导、开放性问题以及治理挑战。由此生成的路线图将此前相互孤立的研究社区联系在一起,并规划出了一条从被动的“下一步预测”向能够模拟并最终重塑 agents 所处环境的世界模型演进的路径。
一句话总结
通过引入一种将能力分为三个层级并归纳为四种管理法(governing-law)体制的“层级 × 管理法”分类法,本研究综合了 400 多项工作和 100 多个代表性系统,为开发能够模拟并重塑其环境的 agentic world models 提供了全面的路线图。
核心贡献
- 本文引入了一种“层级 × 管理法”分类法,通过三个能力层级(Predictor、Simulator 和 Evolver)和四种管理法体制(物理、数字、社会和科学)对 world models 进行分类。
- 本研究综合了 400 多项研究工作,并总结了涵盖基于模型的强化学习、视频生成和 AI 驱动的科学发现等多个领域的 100 多个代表性系统。
- 研究提出了以决策为中心的评估原则和最小可复现评估包,以应对在不同“层级-体制”组合中分析失效模式和评估实践的挑战。
引言
随着 AI agent 从简单的文本生成转向复杂的任务达成,建模环境动态的能力已成为关键瓶颈。虽然“world model”一词被广泛使用,但研究在强化学习、计算机视觉和机器人学等不同社区之间仍然处于碎片化状态,导致定义不一致且评估指标无法比较。现有的综述往往无法捕捉不同模态下能力的演进,在理解从单纯的预测到真正的模拟的转变方面存在空白。
本文利用一种新颖的“层级 × 管理法”分类法来统一这些孤立的领域。提出了一个三层能力体系,包括 L1 Predictors(单步局部转移)、L2 Simulators(多步、动作条件的展开)和 L3 Evolvers(自主、证据驱动的模型修订)。该体系与四种管理法体制相对应:物理、数字、社会和科学世界。通过综合 400 多项工作,本文提供了一个以决策为中心的路线图,连接了不同的研究领域,并为构建能够模拟并最终重塑其环境的 agent 建立了通用语言。
数据集
本文利用多样化的基准测试来评估 agent 在不同管理法体制下的掌握程度。数据集组成分为以下领域:
- 物理世界领域: 包括用于样本高效 world-model 学习的 Atari 100k、用于机器人操作的 Meta-World,以及用于语言条件长程任务的 CALVIN。此外还引入了用于物理稳定性的 RoboCasa 和 RoboCasa365、用于结构稳定性的 BuilderBench,以及用于泛化操作的 ManiSkill3 和 RLbench。自动驾驶由 nuScenes 代表,而 3D 导航和家庭活动由 Habitat 系列、iGibson 2.0 和 BEHAVIOR-1K 涵盖。VBench 用于评估视频生成中的物理合规性。
- 数字世界领域: 通过 OSWorld、macOSWorld、SWE-bench、WebArena 和 Mind2Web 专注于 GUI grounding 和软件交互。移动操作系统约束通过 AppAgent 和 AndroidWorld 进行处理。GameWorld 被纳入用于可验证的多模态 agent 评估。
- 社会世界领域: 采用 ToMi、BigToM 和 OpenToM 等心理理论(Theory of Mind)基准来评估心理状态推理。社会模拟和角色扮演由 Sotopia 和 AgentBench 涵盖,而策略推理和欺骗通过 Werewolf 和 Avalon 等基于游戏的环境进行测试。
- 科学世界领域: 使用 ScienceWorld 进行基础推理,DiscoveryBench 进行假设验证,ChemCrow 进行化学合成,以及 FutureX 进行基于证据的预测。
- 开放世界环境: 通过 Minecraft、Crafter 和 NetHack 等程序化生成的世界结合多种管理法,以测试技能组合和长程规划。
本文将这些基准作为锚点来测试特定的边界条件。评估协议包括特定体制的约束验证、长程连贯性的退化曲线,以及用于衡量干预敏感性的反事实差异测试。
方法
agentic world modeling 的框架围绕三层能力体系——L1 Predictor、L2 Simulator 和 L3 Evolver——构建,并沿两个正交轴组织:能力层级和管理法体制。该体系描述了 world-modeling 能力从局部预测到证据驱动修订的演进,每一层在 agent 的决策过程中都承担不同的功能。管理法体制——物理、数字、社会和科学——定义了领域内的转移必须满足的约束和不变性,从而塑造了各语境下 world models 的设计和评估。该框架强调这些层级并非静态分类,而是代表 agent 根据任务需求在运行时调用的能力。单个部署系统可以同时在不同层级运行:L1 提供快速、反应性的单步预测;L2 实现用于规划和反事实推理的多步模拟;L3 在发生系统性失效时促进模型修订。这种运行时调度视角明确了 L3 并非 L1 或 L2 的替代品,而是一个治理层,在证据需要时提升整个技术栈,作为一个将自身模型资产视为修订对象的自适应系统运行。
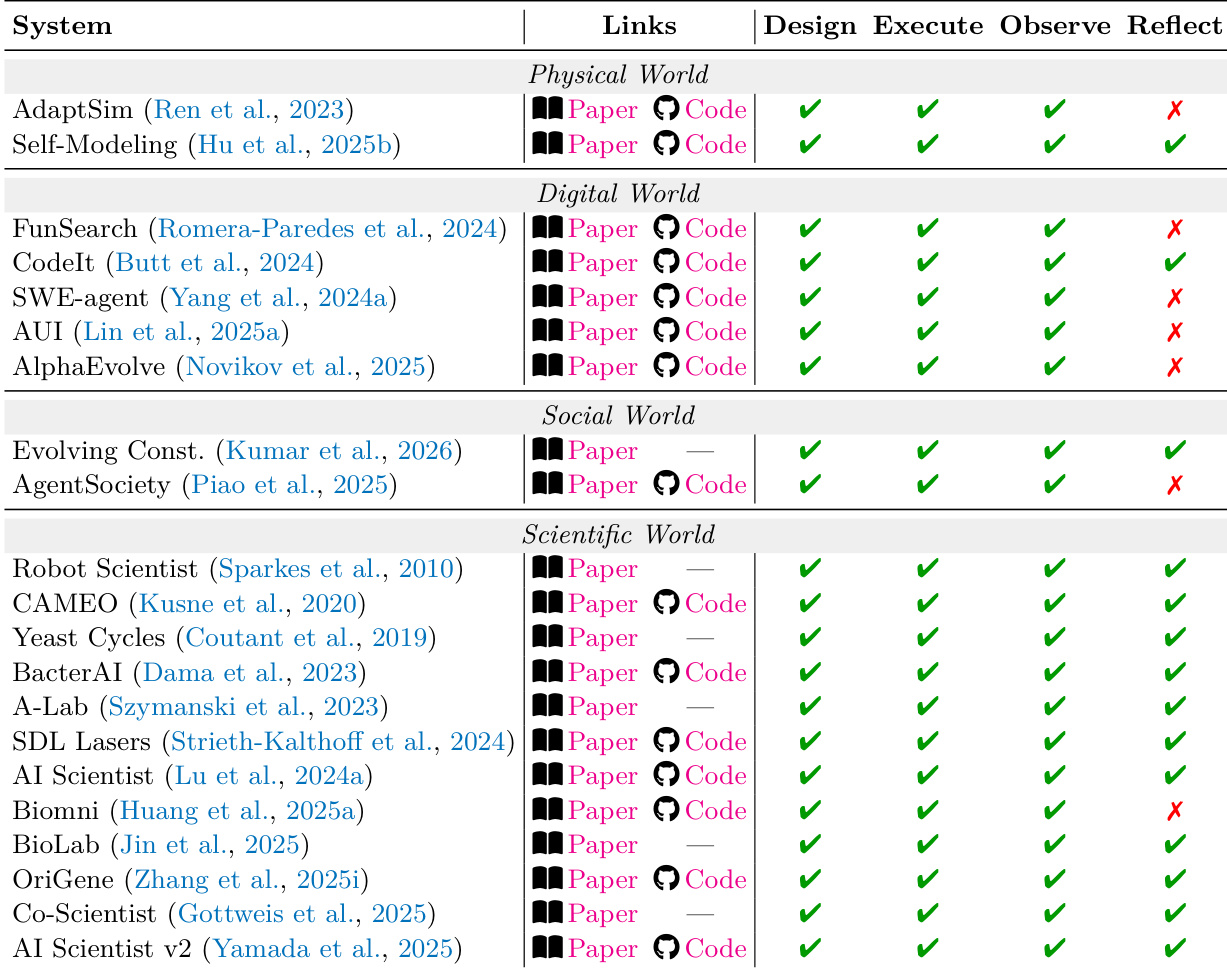
在基础层级,L1 Predictor 专注于局部预测算子,这些算子分解为四个组件:状态推理、前向动力学、观测解码和逆动力学。这些算子旨在实现训练分布下的单步准确性,但不保证多步连贯性。核心算子是前向动力学,它在给定动作的情况下建模从一个潜在状态到下一个状态的转移,而其他算子则支持推理和解码。L1 层级的特征是在学习到的潜在状态中具有马尔可夫性质,其中内部状态 zt 足以预测随后的局部步骤。该层级基于 POMDP 公式,其中 agent 维持对隐藏状态的信念,并制定策略以最大化累积奖励。L1 模型由其维持有意义的内部状态并使用局部预测机制来预测下一状态(包括潜在的观测或动作)的能力来定义。
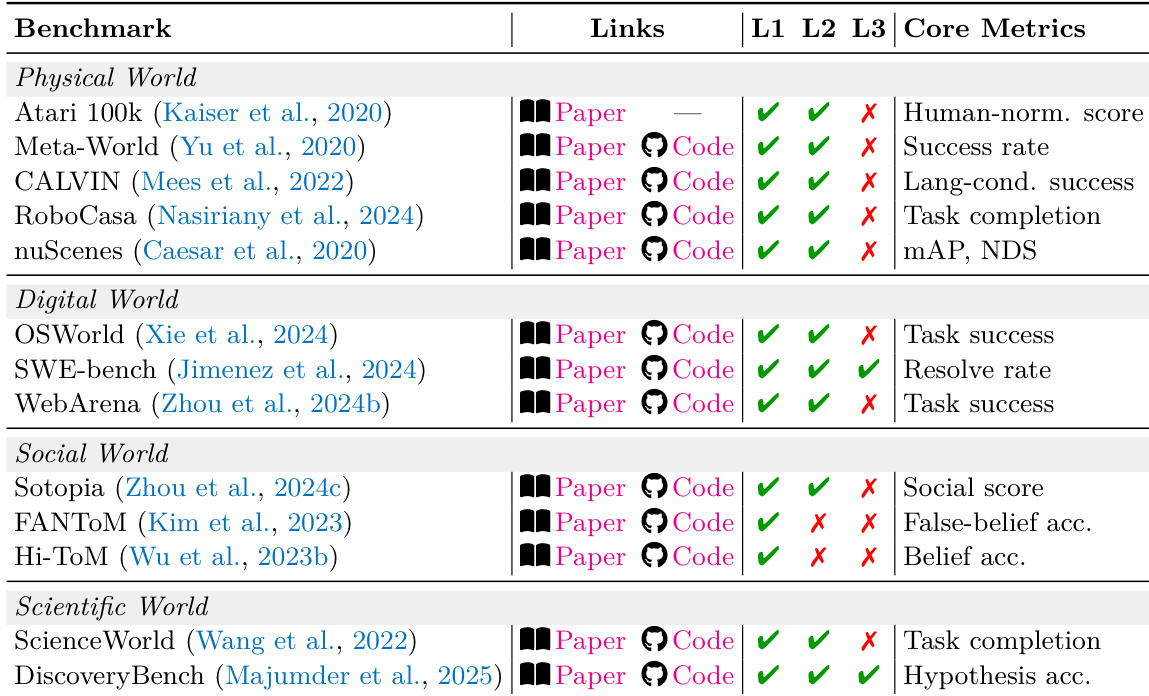
L2 Simulator 将单步预测能力提升为决策可用的多步模拟。它回答了这样一个问题:“如果 agent 在任务约束下执行候选动作序列,可能会展开什么样的未来轨迹?”该层级将每个边缘的 L1 算子缝合成完整的轨迹,使 agent 能够在投入行动之前展开候选计划并比较结果。L2 系统支持形式为 p^(τ∣z0,a1:H,c) 的轨迹级查询,其中 a1:H 表示动作序列,c 表示可选约束。干预结构化的展开与 Pearl 因果层级中的干预阶层一致,通过在管理法下的连贯多步展开而非仅仅是单步预测质量,将 L2 与 L1 区分开来。L2 层级对于基于模型的规划至关重要,其中合成训练数据的生成依赖于真实的物理状态转移以支持策略改进。

L3 Evolver 将 L2 从固定框架内的模拟扩展到证据驱动的模型修订。它对模型资产维持显式的更新循环,系统会对失效进行诊断,将修复方案提炼为可重用的资产,并在启用更新前进行验证。标记从 L2 向 L3 转变的三个边界条件是:基于证据的诊断、持久的资产更新和受控的验证。与 L2 的关键区别在于,模型本身成为了修订的对象,而不仅仅是一个被查询的固定框架。L3 系统运行在“设计–执行–观察–反思”的闭环循环中,通过主动获取新证据来在迭代中挑战并修订模型。这种表述紧密模仿了科学实践的结构,其中异常会导致模型更新,范围从增量改进到范式转移。L3 层级的特征是主动的试错,agent 充当实验设计者以生成最大化信息增益的数据。

World models 的架构设计涉及三个主要构建模块:表示(representation)、动力学(dynamics)和控制接口(control interface)。表示的选择范围从符号或程序化状态到潜在连续表示,每种选择在可解释性、灵活性和漂移敏感性方面都有不同的权衡。动力学模型包括随机潜在动力学、确定性价值感知动力学、自回归 token 动力学和基于扩散的动力学,每种模型在不确定性建模、多模态和动作可控性之间提供了不同的平衡。控制接口从在线 MPC 风格的方法到树搜索与扩展、想象展开策略优化以及可重放环境接口不等,每种接口具有不同的计算需求和误差放大特性。管理法体制决定了哪些组合是可行的:物理世界系统倾向于将潜在或结构化 3D 表示与 MPC 或想象展开策略相结合;数字世界系统依赖于具有可重放环境的符号或基于 DOM 的状态;社会世界系统专注于连贯的 agent 身份和关系状态维护;科学世界系统则优先考虑证据链的有效性和可证伪性。实现路线图将这些设计权衡提炼为按能力层级和管理法体制组织的简洁指南,突出了每个单元的表示格式、动力学模型类别和主要工程瓶颈。
实验
评估将 L2 系统分为四个管理法体制,以分析不同的约束(如物理定律或社会规范)如何塑造模拟器需求。分析表明,长期稳定性更多地是由对这些底层约束的显式建模驱动的,而非提高感知逼真度。此外,研究结果表明,现实世界的应用通常跨越多个体制,因此需要一种整体方法来共同满足约束,以防止跨领域的连锁失效。
该表将不同领域的各种 L2 系统进行了分类,强调了它们在社会和科学世界中对形式化(formalizability)和可观察性(observability)等边界条件的遵循情况。它表明系统通常结合了多个约束家族,需要跨体制共同满足约束以确保连贯的性能。不同领域的系统在遵循形式化和可观察性约束方面存在差异,有些在某一领域表现出色,但在另一领域则不然。许多 L2 系统集成了多个约束家族,例如物理和社会约束,这需要跨体制的连贯性。L2 系统的架构通常涉及 LLM 与强化学习或模拟框架的结合,以处理复杂的约束交互。
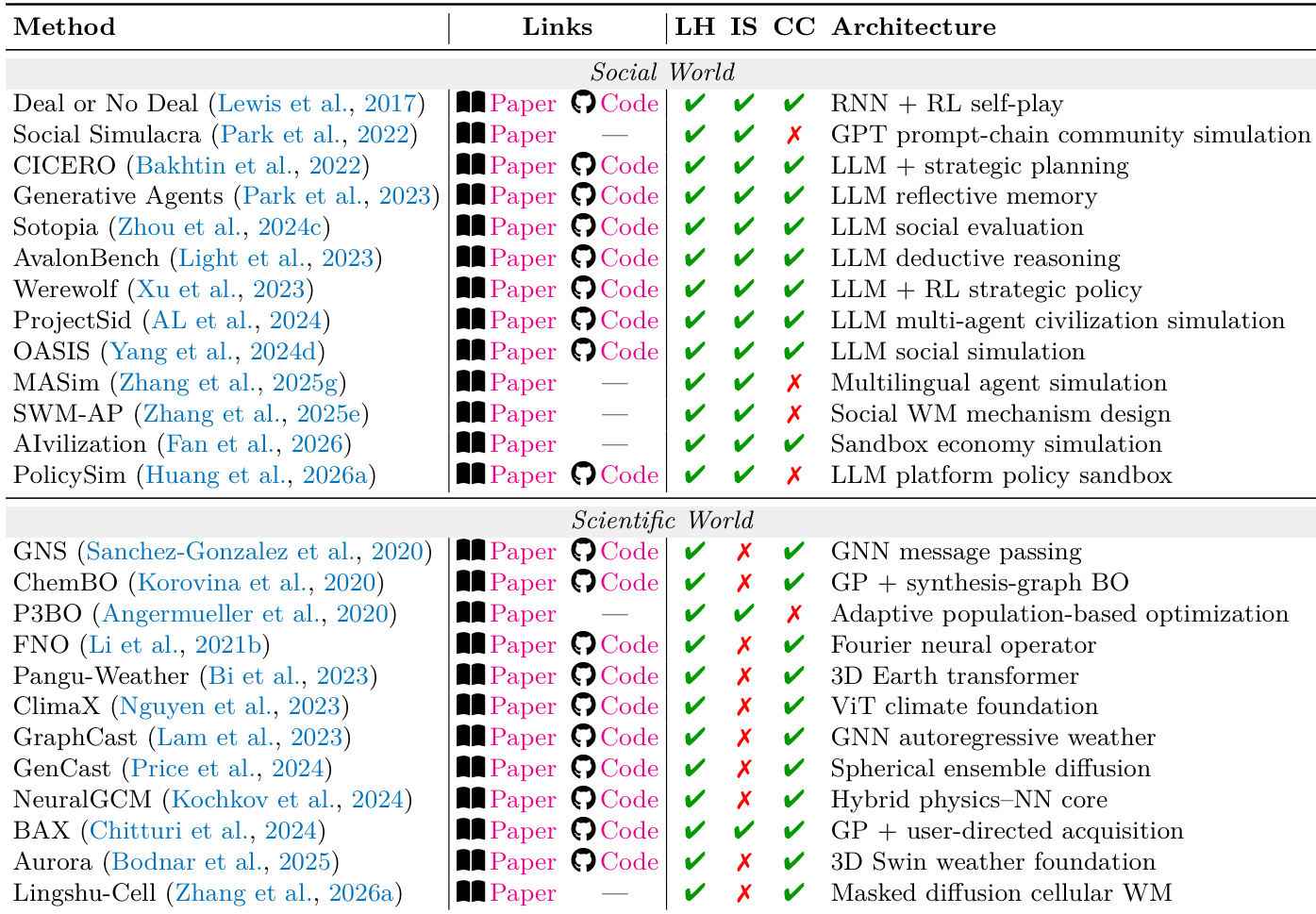
该表根据设计、执行、观察和反思的能力,将物理、数字、社会和科学四个领域的各种 L2 系统进行了分类。每个领域的系统表现出不同的约束满足模式,在处理失效模式和评估优先级方面存在显著差异,特别是在多个体制相互作用的跨领域场景中。不同领域的系统在设计、执行、观察和反思方面表现出不同的能力,有些在反思或观察等特定领域存在不足。跨领域系统通常需要共同满足约束,因为一个领域的违规可能会级联到其他领域,影响整个系统的连贯性。该表强调,无论在哪个领域,使约束显式化比提高感知逼真度更能提升长程稳定性。
该研究将 L2 系统分为物理、数字、社会和科学四个管理法体制,并根据核心指标和边界条件评估其性能。该表显示,每个体制中的系统在论文和代码链接的使用上各不相同,有些在 L1 和 L2 阶段取得成功,但在 L3 阶段失败,这表明在泛化能力或长程稳定性方面存在局限性。物理和数字世界的系统表现出一致的 L1 和 L2 性能,但在 L3 阶段经常失败,这表明在扩展到更复杂任务时面临挑战。社会世界系统实现了较高的 L1 和 L2 性能,但在 L3 阶段失败,表明在处理长期社会动态方面存在困难。在科学世界中,系统在所有三个层级都取得了成功,突显了结构化评估和假设验证的重要性。
研究对物理和数字世界的 L2 模拟器进行了对比分析,根据它们对形式化和可观察性相关管理法的遵循情况对方法进行了分类。该表强调,成功的模拟器通常优先考虑显式的约束建模而非感知逼真度,不同体制在架构和评估重点方面存在显著差异。物理和数字世界的模拟器都优先考虑约束的形式化和可观察性,而非感知逼真度。物理世界的方法通常使用几何或物理动力学,而数字世界的方法依赖于基于代码或状态转移的模型。跨体制系统由于一个领域的约束违反另一个领域的约束而面临级联失效的挑战。
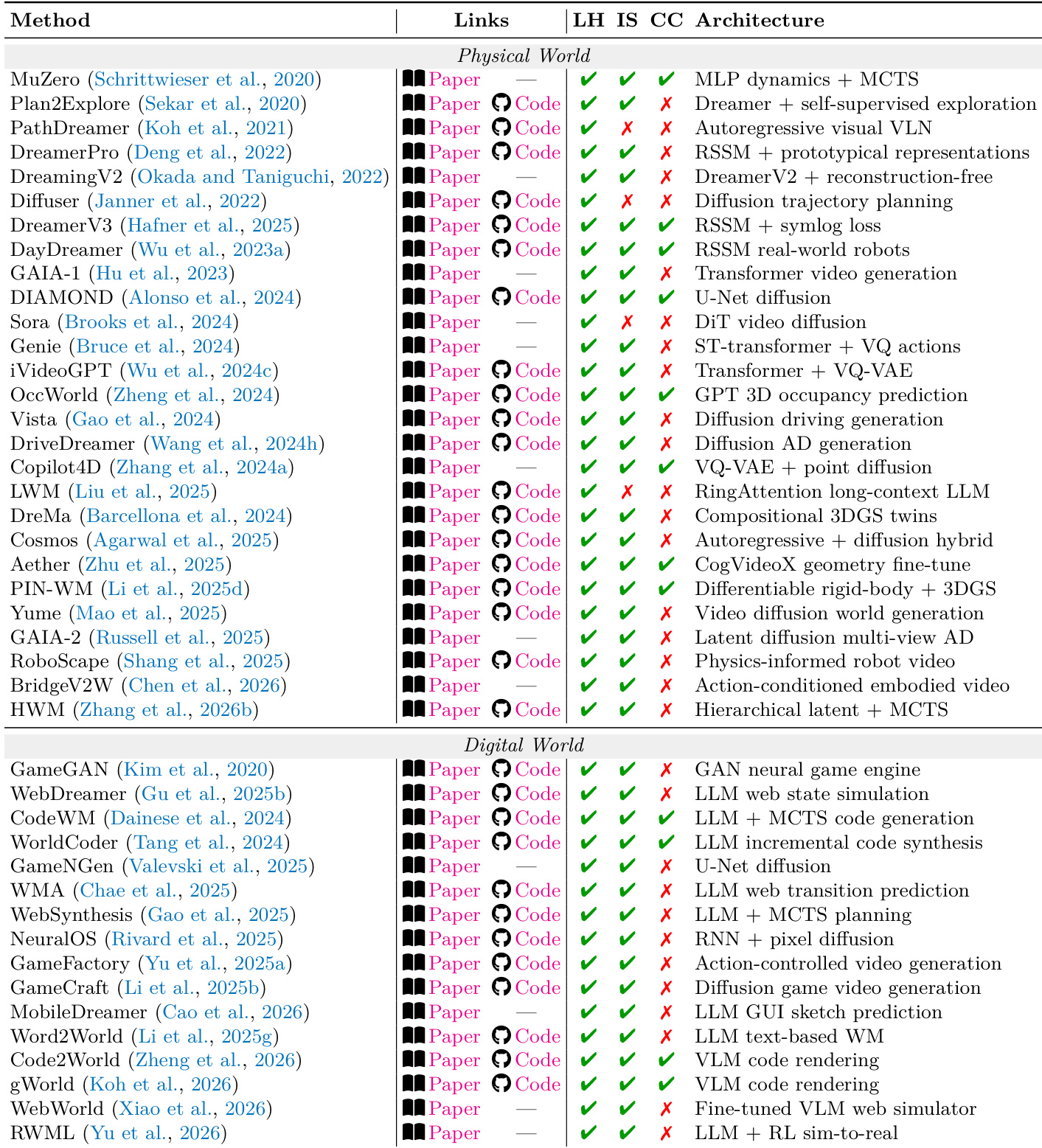
评估将 L2 系统分为物理、数字、社会和科学领域,以评估它们通过设计、执行、观察和反思来满足管理法的能力。研究结果表明,虽然系统在处理特定边界条件的能力方面存在差异,但成功的性能通常取决于显式的约束建模,而非仅仅是感知逼真度。此外,分析表明,保持跨体制的连贯性至关重要,因为许多系统在应对复杂的、多领域的交互时,在长程稳定性和级联失效方面表现挣扎。