Command Palette
Search for a command to run...
FlowAnchor:通过稳定编辑信号实现无反转视频编辑
FlowAnchor:通过稳定编辑信号实现无反转视频编辑
Ze Chen Lan Chen Yuanhang Li Qi Mao
摘要
我们提出了 FlowAnchor,这是一个无需训练(training-free)的框架,旨在实现稳定且高效的免反转(inversion-free)流式(flow-based)视频编辑。近期,免反转编辑方法通过利用编辑信号直接引导采样轨迹,在图像领域展现出了令人印象深刻的效率和结构保持能力。然而,将这一范式扩展到视频领域仍然面临挑战,在多物体场景或帧数增加时往往表现不佳。我们发现其根本原因在于高维视频潜空间(latent spaces)中编辑信号的不稳定性,这种不稳定性源于不精确的空间定位以及长度诱导的幅度衰减(magnitude attenuation)。为了克服这一挑战,FlowAnchor 显式地对“编辑位置”和“编辑强度”进行了锚定。它引入了空间感知注意力细化(Spatial-aware Attention Refinement)机制,以确保文本引导与空间区域之间保持一致的对齐;并引入了自适应幅度调制(Adaptive Magnitude Modulation)机制,以自适应地保持足够的编辑强度。这些机制共同稳定了编辑信号,并引导基于流的演化过程向预期的目标分布靠拢。大量的实验表明,FlowAnchor 在具有挑战性的多物体和快速运动场景下,能够实现更加忠实、时序连贯且计算高效的视频编辑。项目主页见:https://cuc-mipg.github.io/FlowAnchor.github.io/。
一句话总结
FlowAnchor 是一个无需训练的框架,用于实现稳定且高效的免反转(inversion-free)视频编辑。该框架利用空间感知注意力细化(Spatial-aware Attention Refinement)和自适应幅度调制(Adaptive Magnitude Modulation)来克服高维潜在空间中的信号不稳定性,从而在复杂的多物体和快速运动场景中确保时间相干性和精确的空间定位。
核心贡献
- 本文引入了 FlowAnchor,这是一个无需训练的框架,通过锚定空间定位和编辑强度,旨在稳定基于流(flow-based)的免反转视频编辑中的编辑信号。
- 本研究提出了空间感知注意力细化(SAR),该技术在 text token 和时空层面调制交叉注意力图,以确保文本引导与跨帧特定空间区域之间保持一致的语义对齐。
- 该方法结合了自适应幅度调制(AMM),通过使用归一化图来放大语义对比度并维持足够的编辑强度,从而防止编辑信号在高维视频潜在空间中消失。
引言
免反转视频编辑是一个关键的研究领域,旨在实现快速且保持结构的视频修改,而无需承担传统反转方法的高昂计算成本。虽然这些技术在图像上效果良好,但将其扩展到视频时,由于高维潜在空间中编辑信号的不稳定性,往往会导致性能下降。具体而言,先前的工作面临空间定位不精确的问题(导致多物体场景中的语义泄漏)以及幅度衰减问题(即编辑强度随视频长度增加而减弱)。
通过显式锚定编辑的位置和强度,FlowAnchor 框架被用于稳定这些信号。该框架引入了空间感知注意力细化,以确保文本引导与特定空间区域之间的精确对齐,并结合了自适应幅度调制,动态重新缩放编辑信号以保持强度一致。这些机制共同实现在涉及快速运动和多个物体的复杂场景中进行更忠实、时间相干且高效的视频编辑。
数据集
本文引入了 Anchor-Bench,这是一个专门设计的基准测试,用于评估复杂多物体场景下的细粒度局部视频编辑。数据集详情如下:
- 数据集组成与来源:该基准测试由从互联网收集的 74 对文本-视频编辑对组成。这些视频具有多样化的真实世界环境,其特征包括杂乱的背景、快速运动和多个物体。
- 子集与类别:数据被分为三种局部编辑类型:颜色编辑、材质编辑和物体替换(涵盖刚性和非刚性物体)。
- 提示词构建与元数据:对于每个源视频,提供一个源提示词和多个目标提示词。利用 GPT-5 生成初始候选提示词,随后通过人工进行语义准确性优化。为了解决包含多个相似物体的场景中的歧义,提示词中加入了颜色、相对位置或周围上下文等判别性线索。
- 处理与掩码:为了便于局部评估,每个目标提示词都配有一个编辑掩码序列。这些掩码通过在第一帧上手动标注目标区域,并利用光流将选择传播到其余帧来创建。
- 技术规格:基准测试中的视频长度最高可达 81 帧,分辨率为 480p。
方法
基于 FlowEdit 方法,本文利用 Rectified Flow 框架实现了免反转的文本到视频编辑。核心方法涉及构建一个编辑轨迹 Ztedit,该轨迹从源图像 Xsrc 向由新提示词 P∗ 引导的目标分布演化。这是通过迭代估计作为编辑信号的速度差分场 ΔVti 来实现的。在每个时间步 ti,通过源图像与噪声之间的线性插值生成伪源状态 Ztisrc,同时将目标状态 Ztitar 定义为 Ztiedit+Ztisrc−Xsrc。随后使用文本条件模型计算这两个状态的速度场 V(Ztisrc,ti,P) 和 V(Ztitar,ti,P∗),其差值即产生编辑信号 ΔVti。该信号引导编辑轨迹的演化,Zti−1edit=Ztiedit+(ti−1−ti)ΔVti。 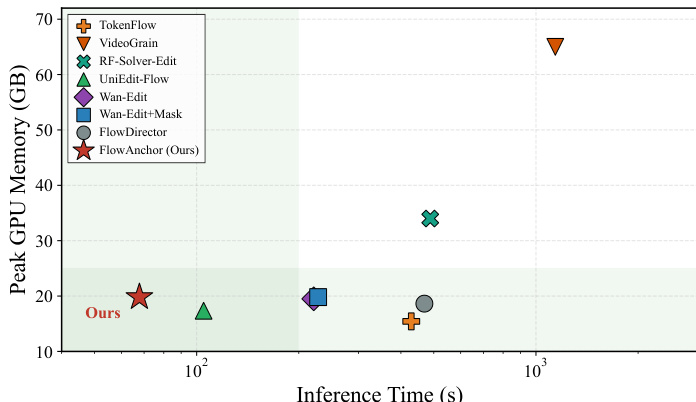
解决的主要挑战是视频编辑中编辑信号的定位不精确和幅度减弱问题。为了解决定位问题,提出了空间感知注意力细化(SAR),这是一种对控制文本与视觉 token 对齐的交叉注意力(CA)图进行两步细化的过程。该过程应用于去噪早期阶段的所有 CA 层。第一步是 text-token 调制,通过使用调制强度 β1,将掩码内每个时空视频 token 的目标 token Jtar 的注意力权重拉向最大响应,并将非目标 token 推向最小响应,从而增强对目标 text token 的注意力并抑制预定编辑区域 M 内的非目标 token。第二步是时空调制,通过调节整个视频序列中目标 token 的注意力权重来强制执行全局时间相干性。它放大每个目标 token 的最大注意力响应并抑制最小响应,从而减少跨帧闪烁。此步骤使用调制强度 β2。细化后的注意力图随后用于计算编辑信号更准确的目标速度场 Vtitar。
为了应对第二个失效模式——长视频中编辑信号幅度的衰减,引入了自适应幅度调制(AMM)。该机制根据信号的内在对比度自适应地增强信号。在每一步中,通过对编辑信号 ΔVti 应用最大-最小归一化来导出对比度图 Cti,从而创建一个突出语义变化剧烈区域的软重要性掩码。随后,对比度图与帧自适应放大因子 γF=γ⋅log(F)/log(F0) 相结合,其中 F 是实际视频长度,F0 是模型的默认最大长度。该因子确保较长的视频能获得与长度引起的信号减弱成比例的更强补偿。最终的调制编辑信号 ΔVtiAMM 通过逐元素相乘获得:(1+γF⋅Cti)⊙ΔVti。这选择性地放大了高对比度区域,同时使背景噪声基本保持不变。细化后的编辑信号驱动轨迹演化。
整体框架 FlowAnchor 将这些组件集成到一个统一的流水线中。如框架图所示,源视频和目标视频 token 被输入到带有自注意力层的 DiT 块中。编辑过程始于采样伪源状态并定义目标状态。计算速度场,其差值形成初始编辑信号。随后该信号通过 SAR 进行处理以增强空间定位,并通过 AMM 进行处理以自适应增加其幅度。最终的调制信号被添加到当前状态,以产生编辑轨迹中的下一个状态。该过程在时间上向后迭代,直到获得最终编辑后的视频。通过定性比较证明了该框架的有效性,结果显示 FlowAnchor 与基准方法相比,产生了更准确且时间一致的编辑效果。
实验
所提方法在 FiVE-Bench 和新引入的 Anchor-Bench 上进行了评估,以验证其在物体替换、颜色修改和材质变化等局部视频编辑任务中的性能。消融研究和超参数分析表明,SAR 和 AMM 模块对于在不损害结构保真度的前提下实现精确的语义定位和足够的编辑强度至关重要。结果显示,该框架在文本对齐、时间一致性和效率方面优于最先进的基准方法,同时对不同粒度的掩码保持高度鲁棒。
通过推理时间和峰值 GPU 显存占用量,将该方法与几种最先进的基准方法进行了比较。结果显示,该方法在所有对比方法中实现了最低的推理时间,同时保持了具有竞争力的显存消耗,表明在效率和性能之间取得了良好的权衡。该方法实现了比所有基准方法更低的推理时间。该方法使用了具有竞争力的峰值 GPU 显存,展示了高效的资源利用。该方法在速度和显存消耗之间提供了理想的权衡。
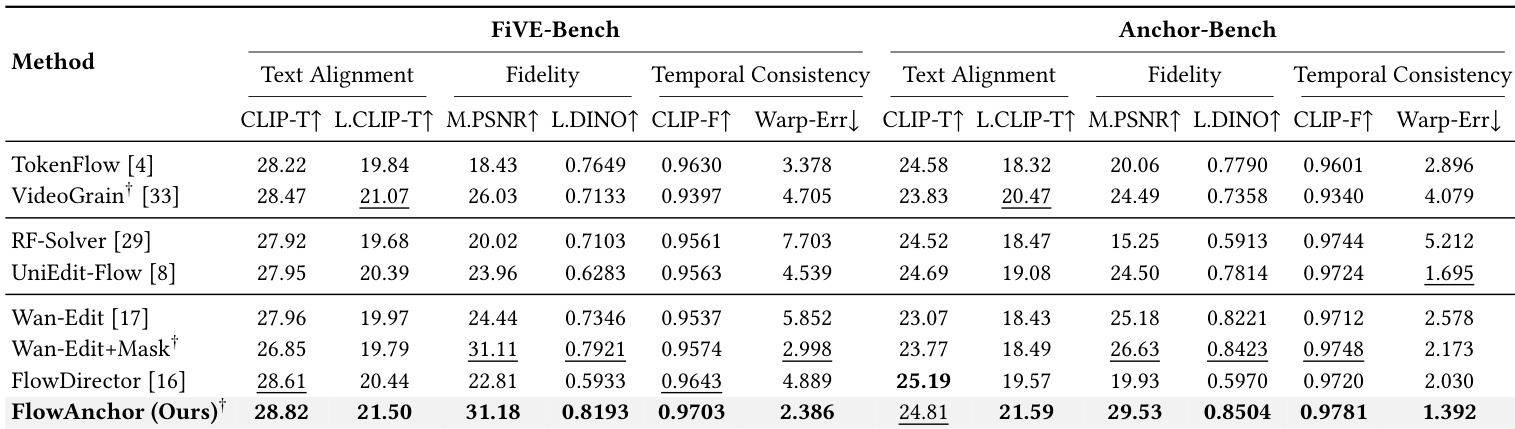
在 FiVE-Bench 和 Anchor-Bench 两个基准测试上,将 FlowAnchor 与几种最先进的基准方法进行了比较,评估了其在文本对齐、保真度和时间一致性方面的表现。结果显示,FlowAnchor 在大多数指标上获得了最高分,特别是在局部文本对齐和时间相干性方面,同时也展示了卓越的效率。该方法在不同的掩码粒度下均保持了强劲的性能,表明对不精确的用户输入具有鲁棒性。与所有基准方法相比,FlowAnchor 在两个基准测试的局部文本对齐和时间一致性方面均获得了最高分。FlowAnchor 展示了卓越的效率,具有最低的推理时间,同时在编辑质量方面保持了竞争力的表现。该方法在各种掩码粒度下均保持有效,从紧凑掩码到粗略边界框均表现出一致的结果,表明对不精确的用户输入具有鲁棒性。
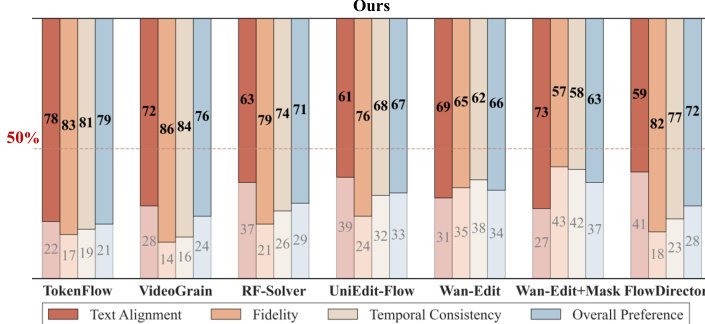
通过多个指标将该方法与几种基准方法进行比较,包括文本对齐、保真度、时间一致性和整体偏好。结果显示,该方法在文本对齐和整体偏好方面持续优于基准方法,同时在保真度和时间一致性方面保持了强劲性能。该方法在大多数类别中获得了最高分,特别是在文本对齐和用户偏好方面,并展示了卓越的效率。与所有基准方法相比,该方法在文本对齐和整体偏好方面获得了最高分。该方法在所有评估指标的保真度和时间一致性方面均保持了强劲性能。该方法展示了卓越的效率,在所有对比方法中实现了最低的推理时间。
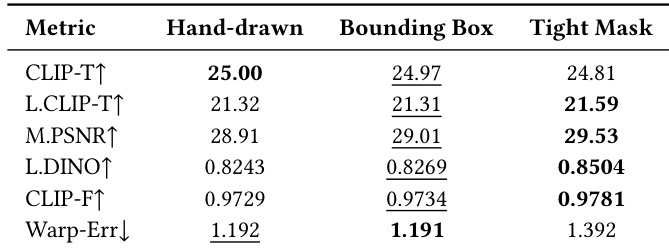
在基准测试中,评估了该方法对不同掩码粒度(包括手绘掩码、边界框和紧凑掩码)的鲁棒性。结果显示,该方法在所有掩码类型下均保持了强劲的性能,其中紧凑掩码在时间一致性和结构保持方面获得了最佳的综合评分。无论掩码精度如何,该方法都表现出一致的编辑质量,表明对不精确的用户输入具有很高的容忍度。该方法在手绘、边界框和紧凑掩码下均实现了性能一致,显示出对掩码粒度的鲁棒性。紧凑掩码在大多数指标上获得了最高分,尤其是在时间一致性和结构保持方面。即使使用粗略或不精确的掩码,该方法仍保持了强大的文本对齐和保真度,表明其在交互式编辑中的实际可用性。
进行了消融研究,以分析不同组件和超参数对方法性能的影响。结果表明,所提出的 SAR 和 AMM 模块显著提高了编辑质量,特定的配置在定位、保真度和时间一致性之间实现了最佳平衡。该方法在各种设置下均表现出鲁棒的性能,即使在掩码精度变化时也能保持高效。SAR 和 AMM 模块对于实现精确且强大的编辑信号至关重要,特定的超参数设置可带来最优性能。该方法在不同的掩码粒度下均保持了高性能,表明对不精确的用户输入具有鲁棒性。所提出的方法在编辑质量和计算效率之间取得了良好的权衡,在两项指标上均优于基准方法。
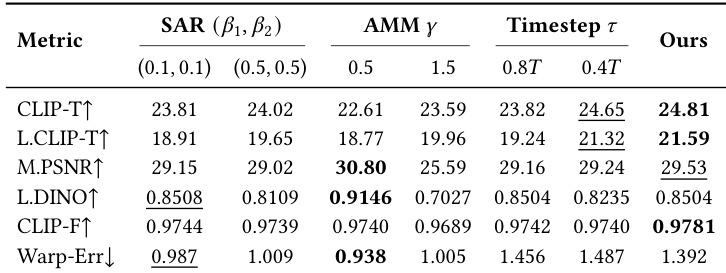
使用多个基准测试将 FlowAnchor 与最先进的基准方法进行对比,以评估其效率、编辑质量以及对不同掩码粒度的鲁棒性。结果表明,该方法在实现高文本对齐、时间一致性和用户偏好得分的同时,提供了速度与显存使用的卓越平衡。此外,消融研究证实,所提出的 SAR 和 AMM 模块对于高质量编辑至关重要,且模型在面对不精确的用户输入时仍保持鲁棒。