Command Palette
Search for a command to run...
基于语义进展函数的视频分析与生成
基于语义进展函数的视频分析与生成
Gal Metzer Sagi Polaczek Ali Mahdavi-Amiri Raja Giryes Daniel Cohen-Or
摘要
图像与视频生成模型产生的变换过程往往呈现出高度的非线性特征:即在长时间的内容几乎没有变化后,会出现突然且剧烈的语义跳跃。为了分析并修正这一行为,我们引入了“语义进度函数”(Semantic Progress Function),这是一种能够捕捉给定序列含义随时间演变过程的一维表示。对于每一帧,我们计算语义 embedding 之间的距离,并拟合出一条反映整个序列累计语义偏移的平滑曲线。该曲线偏离直线程度的大小,揭示了语义节奏的不均匀性。基于这一洞察,我们提出了一种语义线性化(semantic linearization)程序,通过对序列进行重参数化(或重新计时),使语义变化以恒定的速率展开,从而实现更平滑、更连贯的过渡。除了线性化之外,我们的框架还提供了一个与模型无关(model-agnostic)的基础设施,用于识别时间上的不规则性、比较不同生成器之间的语义节奏,并引导生成视频及真实世界的视频序列向任意目标节奏靠拢。
一句话总结
作者引入了一种语义进度函数,通过拟合语义嵌入距离的平滑曲线来捕捉语义演变,以揭示不均衡的步调,并提出了一种语义线性化过程,通过重定时序列以实现恒定的语义变化,从而产生更平滑的过渡。这为识别时间不规则性提供了模型无关的基础,并将生成和现实世界的视频序列引导至任意目标步调。
核心贡献
- 引入了一种语义进度函数,通过计算序列中语义嵌入之间的距离,将语义演变表示为一维曲线。该指标客观地量化了时间线性并揭示了不均衡的语义步调。
- 提出了一种语义线性化过程,以重新参数化视频序列,使语义变化以恒定速率展开。该方法通过语义进度函数测量的语义内容扭曲时间位置,从而产生更平滑和更连贯的过渡。
- 该框架为识别时间不规则性提供了模型无关的基础,并将生成和现实世界的视频序列引导至任意目标步调。这种方法能够将野外视频转换为恒定步调,而无需现有基于引导的方法所需的人工用户标注。
引言
生成式视频模型经常产生语义意义演变不均衡的过渡,导致在长静默期后出现突兀的跳跃,从而破坏了感知连贯性。虽然先前的工作解决了时间平滑性或潜在插值问题,但这些方法未能量化语义变化的速率或比较不同生成器之间的步调。为了解决这一问题,作者引入了语义进度函数,这是一种一维表示,通过测量累积语义偏移来识别不规则性。基于该指标,他们提出了一种模型无关的线性化过程,以重新参数化视频序列,确保变换以恒定速率展开,而无需微调。
方法
作者引入了语义进度函数(SPF)作为一种模型无关的公式,以捕捉随时间演变的语义。形式上,给定一个由 T 帧 {x1,x2,…,xT} 组成的视频,SPF 被定义为从帧索引 i 映射的标量值函数 Si∈R。该表示将复杂的视觉变换提炼为一维轨迹。构建过程分为两个阶段:首先计算帧之间的成对语义距离,然后将这些差异随时间积分。
为了测量语义差异,该方法利用预训练语义图像嵌入器,如 SigLIP。每个视频帧 xi 被映射到语义嵌入 zi∈Rd。帧 i 和 j 之间的语义距离使用嵌入空间中的角度度量计算: dij=arccos(zi⊤zj) SPF 向量 S∈RT 被估计为使其成对时间差异近似这些语义距离。这被公式化为正则化加权最小二乘目标: minS∈RT(AS−b)⊤W(AS−b)+λS⊤S 其中 A 编码帧对的线性约束,b 收集距离,W 是 favoring 时间局部约束的对角加权矩阵。
如下图所示,SPF 有效地可视化了语义步调。顶部图表描绘了原始输入视频的 SPF,其中猫突然转变为狮子。函数在过渡点处的斜率急剧增加,反映了语义不连续性。底部图表说明了重定时后的 SPF,其中语义进展显得显著更平稳。
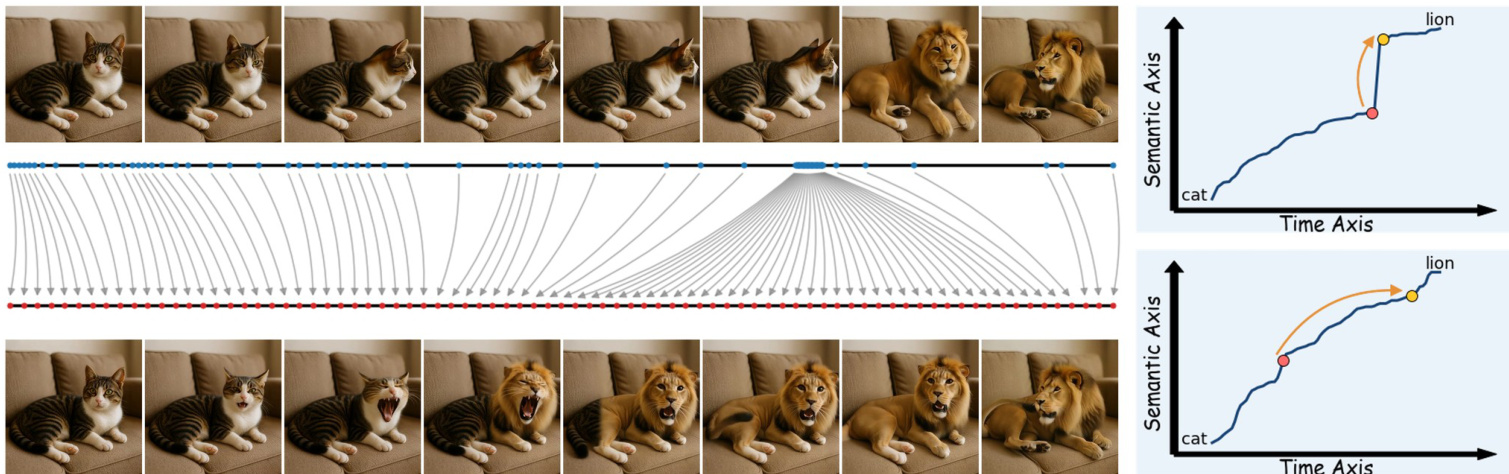
基于此分析,作者提出了通过 ReTime 进行语义线性化,以重新参数化时间,使语义变化以恒定速率进展。对于生成的视频,这是通过扭曲模型的时间位置编码来实现的。SPF S 被归一化到 [0,1],并通过反演计算扭曲的时间位置 τk: τk=S−1(T−1k) 这在快速语义变化区域拉伸时间,并压缩稳定区域。由于现代视频扩散 Transformer 采用旋转位置编码(RoPE),作者引入了频率感知扭曲。低频带控制长程结构,被更强地扭曲,而高频带保持更接近线性时间以保持局部运动平滑度: pt(b)=(1−αb)t+αbτt 扭曲强度 αb 在不同频带之间呈指数衰减。此外,时间步依赖调制在去噪过程早期应用更强的扭曲,以在结构形成期间集中语义校正。
对于生成不可控的现有视频,该方法使用分段最小二乘法将 SPF 分割为分段线性组件。这隔离了近乎恒定语义速度的区域。参考框架图以了解此过程在电影片段上的示例,其中分段 SPF(虚线)指导时间容量的重新分配以平滑突兀的过渡。
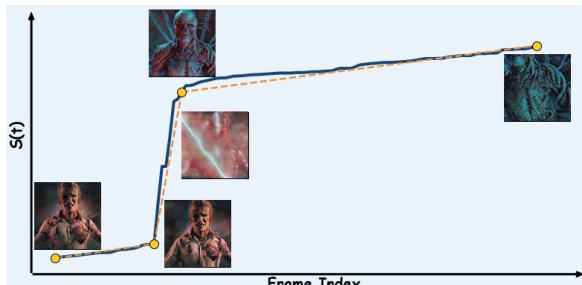
随后为每个片段重新生成中间片段以确保均匀步调。每个片段的第一个和最后一个帧作为重生成的语义关键帧。这种方法允许使用各种开源或闭源模型,只要它们可以以关键帧或首尾帧为条件,确保每个片段的持续时间与其边界帧之间语义变化的幅度成比例。
实验
评估套件通过将重定时策略与基线进行比较、将该方法应用于真实的电影镜头,并通过受控合成实验验证准确性来验证该框架。定性结果表明,直接在模型特征上操作可防止重影伪影和外部质量瓶颈,从而实现基线方法无法解决的平滑语义过渡。合成基准测试证实语义进度函数准确跟踪步调曲线,独立于像素运动,而消融研究确定 SigLIP 是捕捉语义偏移的最优嵌入器。最后,定量指标和用户研究表明,该方法在保持视觉保真度的同时显著改善了语义步调。
作者通过使用 VBench 指标比较 Wan2.2 和 LTX-2 模型的原始和重定时输出,评估了其重定时框架的视觉保真度。结果表明,重定时视频在美学、运动和时间维度上保持的质量水平与原始生成几乎相同。这证实了所提出的时间操作保留了基础模型的内在视觉能力。重定时视频的美学质量分数与原始模型输出相当。运动平滑度和时间保真度指标显示原始序列和重定时序列之间的偏差可忽略不计。评估证实重定时过程保留了底层生成模型的视觉保真度。
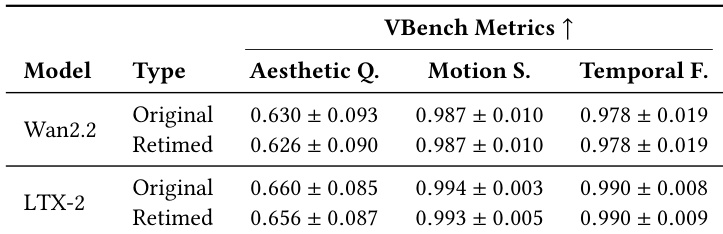
作者通过使用 VBench 指标比较 Wan2.2 和 LTX-2 模型的原始和重定时输出,评估了其重定时框架的视觉保真度。结果表明,重定时视频在美学、运动和时间维度上保持的质量水平与原始生成几乎相同。这证实了所提出的时间操作保留了基础模型的内在视觉能力。