Command Palette
Search for a command to run...
AgentSearchBench:一种针对野外场景下 AI agent 搜索能力的基准测试
AgentSearchBench:一种针对野外场景下 AI agent 搜索能力的基准测试
Bin Wu Arastun Mammadli Xiaoyu Zhang Emine Yilmaz
摘要
AI agent 生态系统的快速增长正在改变复杂任务的委派与执行方式,同时也带来了一个新挑战:如何针对给定任务识别出合适的 agents。与传统工具不同,agent 的能力通常具有组合性(compositional)且依赖于执行过程,这使得仅凭文本描述很难对其进行准确评估。然而,现有的研究和基准测试通常假设功能定义明确、候选池受控,或者仅包含可执行的任务查询,导致现实世界中 agent 搜索场景的研究尚不充分。我们推出了 AgentSearchBench,这是一个针对真实环境下 agent 搜索的大规模基准测试,由来自多个供应商的近 10,000 个真实 agent 构建而成。该基准测试将 agent 搜索形式化为在“可执行任务查询”和“高层级任务描述”两种场景下的检索(retrieval)与重排序(reranking)问题,并利用基于执行的性能信号(execution-grounded performance signals)来评估相关性。实验结果表明,语义相似度与 agent 的实际表现之间存在持续的差距,这暴露了基于描述的检索和重排序方法的局限性。我们进一步证明,引入包括执行感知探测(execution-aware probing)在内的轻量级行为信号,可以显著提升排序质量,从而凸显了在 agent 发现过程中整合执行信号的重要性。我们的代码已开源至:https://github.com/Bingo-W/AgentSearchBench。
一句话总结
为了应对现实世界中 AI agent 发现的挑战,作者引入了 AgentSearchBench。这是一个包含近 10,000 个 agent 的大规模基准测试,它将搜索形式化为一个检索与重排序问题,并通过基于执行的性能信号而非仅仅是语义相似度来评估相关性。
核心贡献
- 本文引入了 AgentSearchBench,这是一个包含来自多个供应商的近 10,000 个真实世界 agent 的大规模基准测试,旨在促进开放生态系统中的 agent 搜索。该基准测试将 agent 搜索形式化为一个检索与重排序问题,同时支持高层级任务描述和可执行任务查询。
- 该工作建立了一个基于性能的评估框架,使用执行结果而非静态文本相似度来确定 agent 的相关性。实验表明,语义相似度与实际 agent 性能之间存在显著差距,表明基于描述的检索方法往往无法识别出能力最强的 agent。
- 研究表明,引入轻量级的行为信号(例如执行感知探测和更丰富的索引)可以显著提高排序质量。这些发现强调了使用执行信号来捕捉 agent 的组合性及依赖执行能力的必要性。
引言
随着 AI agent 生态系统的扩展,为复杂任务可靠地识别并选择合适的 agent,对于终端用户和自动化编排系统都变得至关重要。传统的工具检索方法在此背景下往往会失效,因为 agent 的能力具有组合性和执行依赖性,这意味着仅凭文本描述不足以预测实际性能。先前的研究通常依赖于具有定义明确接口的受控环境,或者假设相关性可以通过静态语义相似度来确定。作者通过引入 AgentSearchBench 解决了这些局限性,这是一个包含近 10,000 个真实世界 agent 的大规模基准测试。通过将 agent 搜索形式化为一个基于执行性能而非仅仅是文本匹配的检索与重排序问题,研究证明了引入轻量级行为信号可以显著提高高性能 agent 的发现效率。
数据集
-
数据集构成与来源:作者利用从 GPT Store、Google Cloud Marketplace 和 AgentAI Platform 等公共平台获取的近 10,000 个真实世界 agent 仓库构建了 AgentSearchBench。该集合包含 9,760 个 agent,其中 7,867 个提供可执行接口。
-
关键子集与细节:
- 任务查询 (Task Queries):基准测试包含 2,952 个可执行任务查询,这些查询可以是单 agent 任务或多 agent 任务。
- 任务描述 (Task Descriptions):共有 259 个高层级任务描述。每个描述平均关联 10 个具体的任务查询,以确保一致的能力评估。
- 多 agent 查询 (Multi-agent Queries):通过从能力对齐的集群中组合子任务来形成。只有当组合在语义上通过自然语言推理蕴含所有组成子任务时,该组合才会被保留。
-
处理与过滤:
- 查询生成:任务查询从 agent 文档中合成。为了控制评估成本,作者使用结合了 BM25、BGE 和 ToolRet 的混合评分函数,为每个查询检索一个 top-K 候选 agent 集合。
- 过滤规则:作者过滤掉了退化的查询,即那些要么没有 agent 成功,要么所有 agent 都成功的查询。
- 相关性标注:相关性通过基于执行的评估确定,使用 5 点制的 LLM-as-judge。对于检索任务,分数被转换为二元标签。对于多 agent 和高层级任务,相关性计算为所有关联子任务的平均完成分数。
- 偏差修正:为了考虑到文档与实际性能之间的差异,对于在没有文档记录能力的情况下完成任务的 agent,其相关性分数会受到折减。
-
数据使用:作者使用 66,740 次运行的执行结果(对每个查询评估 top-20 个 agent)来构建黄金排名 (golden rankings)。这使得能够通过检索和细粒度重排序任务两种方式来评估 agent 搜索。
方法
作者利用多阶段框架构建了 agent 搜索基准,重点关注基于任务性能的相关性和结构化的 agent 表示。流程始于任务查询生成,其中使用 agent 样本来生成初始任务查询。随后通过添加上下文信息并过滤掉闭卷任务来完善这些查询,从而产生可执行的任务查询。该框架通过从语义相关的查询集群中抽象高层级目标来生成任务描述,利用 LLM 为每个集群生成简洁的描述。为了将可执行查询与这些描述关联起来,基于准则的评判器从多个方面评估相关性,每个方面选择前 2 个查询,从而为每个任务描述形成一个候选查询池。
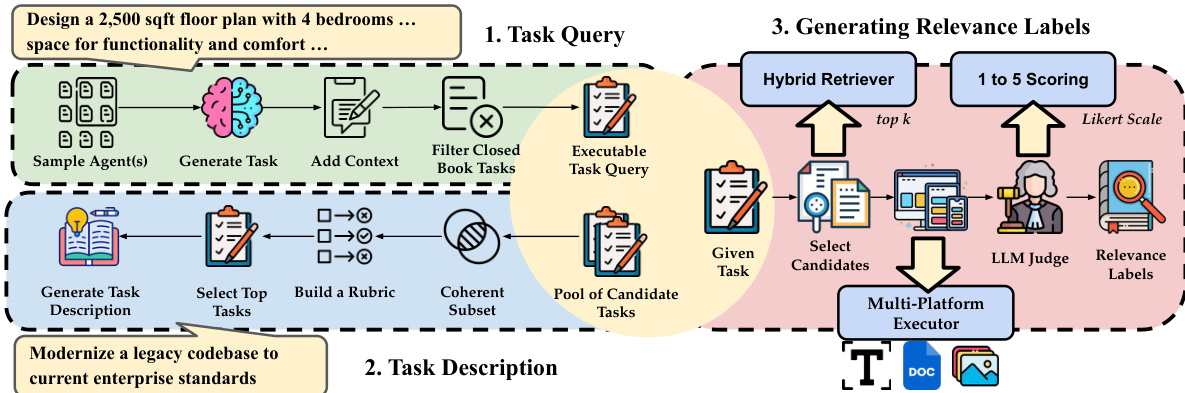
如下图所示:该框架集成了一个混合检索器,结合了词法、语义和工具感知检索信号,为每个任务查询选择 top-k 个 agent。检索函数定义为 s(a,Tq)=αslex+βssem+γstool,其中各组件经过 min-max 归一化,并使用学习到的权重进行聚合,权重之和为 1。检索到的 agent 随后由 LLM 评判器使用 Likert 量表评分系统(1 到 5 分)进行评估,以生成相关性标签,这些标签反映了任务完成性能以及文档与性能的一致性。该评分结合了通过 LLM-as-a-judge 机制评估的 agent 响应质量,以计算任务完成分数 y(a,Tq)=E(a,Tq)。对于任务描述 Td,相关性在其关联的查询上进行聚合:y(a,Td)=∣Q(Td)∣1∑Tq∈Q(Td)y(a,Tq),确保相关性衡量的是跨多个实例的一致性能。该框架还包含一个多平台执行器来评估 agent 并验证结果,确保基准测试构建过程的鲁棒性和可靠性。
实验
评估通过使用可执行任务查询和高层级任务描述来检查 agent 检索与重排序性能,以识别不同模型系列捕捉 agent 能力的效果。结果表明,虽然工具感知模型和稠密模型在具体查询上表现良好,但在处理抽象描述时存在显著的语义与性能差距,这是由于文档与实际执行之间存在不匹配。研究进一步证明,引入行为信号(如使用示例和基于执行的探测)可以通过提供 agent 真实功能能力的证据,有效地提高排序准确性。
作者对比了不同的 agent 搜索基准,强调 AgentSearchBench 同时包含可执行和不可执行的任务类型,而其他基准主要侧重于可执行任务。评估显示,不同基准在候选数量和真实感方面存在差异,AgentSearchBench 提供了更广泛的范围,包括不可执行的任务类型。AgentSearchBench 与仅关注可执行任务的其他基准不同,它包含了可执行和不可执行的任务类型。候选数量在不同基准之间差异显著,AgentSearchBench 的候选池比其他基准更大。一些基准包含真实的任务类型,而另一些则不包含,这表明评估真实感存在差异。

作者在可执行任务查询和高层级任务描述下评估了 agent 搜索方法,重点关注检索和重排序性能。结果显示,工具感知检索器在任务查询上优于其他方法,而稠密检索器在任务描述上更具竞争力,尽管所有方法在完整性方面都面临挑战,尤其是在抽象需求下。重排序方法在任务查询上的表现相似,但在任务描述上,基于 decoder-only 和 LLM 的方法表现有所提升,尽管完整性仍然有限。工具感知检索器在任务查询上优于稠密和稀疏基准,而稠密检索器在任务描述上更具竞争力。所有方法都表现出较低的完整性,特别是在高层级任务描述下,这表明识别具有全面任务解决能力的 agent 存在困难。Decoder-only 和基于 LLM 的重排序器在任务描述上表现更强,表明其生成能力有助于推断隐含需求。

作者使用基于执行的相关性在任务描述上评估了重排序方法,对比了包括 cross-encoders、工具特定模型、decoder-only 模型和基于 LLM 的方法在内的各种模型系列。结果显示,虽然不同方法在具体任务查询上达到相似的性能,但基于 LLM 的重排序器在高级任务描述上表现更强,尽管所有方法的完整性仍然有限。评估强调了模型排名与实际执行性能之间持续存在的差距,表明 agent 文档与现实世界有效性之间存在不匹配。基于 LLM 的重排序器在高层级任务描述上优于其他方法,表明其具有推断隐含需求的能力。所有方法都显示出较低的完整性,表明识别能够完全满足复杂任务要求的 agent 存在困难。模型排名与黄金执行排名之间存在显著差距,反映了文档与实际 agent 性能之间的不匹配。
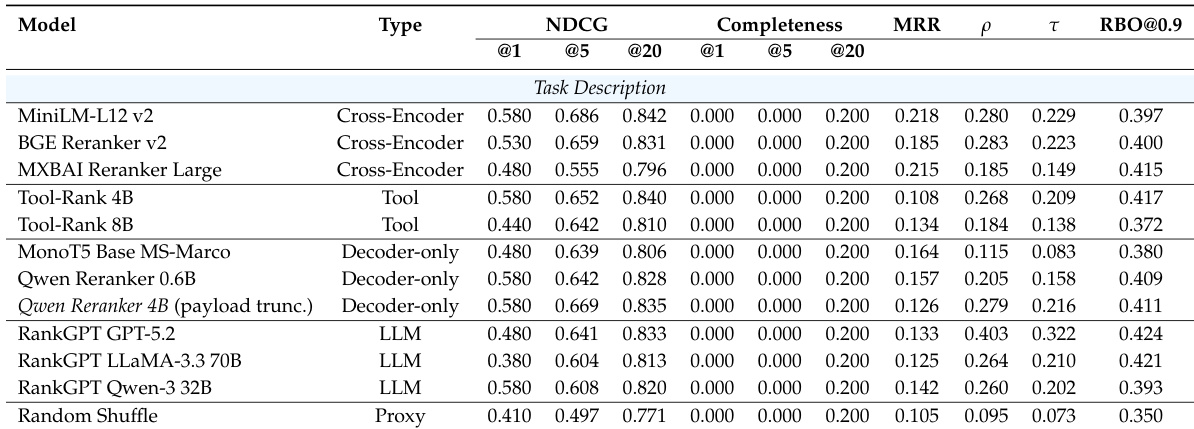
作者在不同的任务规范下评估了 agent 检索和重排序方法,对比了检索模型和重排序模型的性能。结果显示,工具感知和稠密方法在可执行查询上表现良好,而 decoder-only 和基于 LLM 的重排序器在高层级任务描述上表现出更强的性能,尽管所有方法的完整性仍然有限。工具感知和稠密检索模型在可执行任务查询上优于其他方法,而稠密模型在高层级任务描述上变得更具竞争力。Decoder-only 和基于 LLM 的重排序器在高级任务描述上实现了更强的性能,表明其具有推断隐含需求的能力。所有方法的完整性仍然较低,表明 agent 文档与实际执行性能之间存在持续差距。
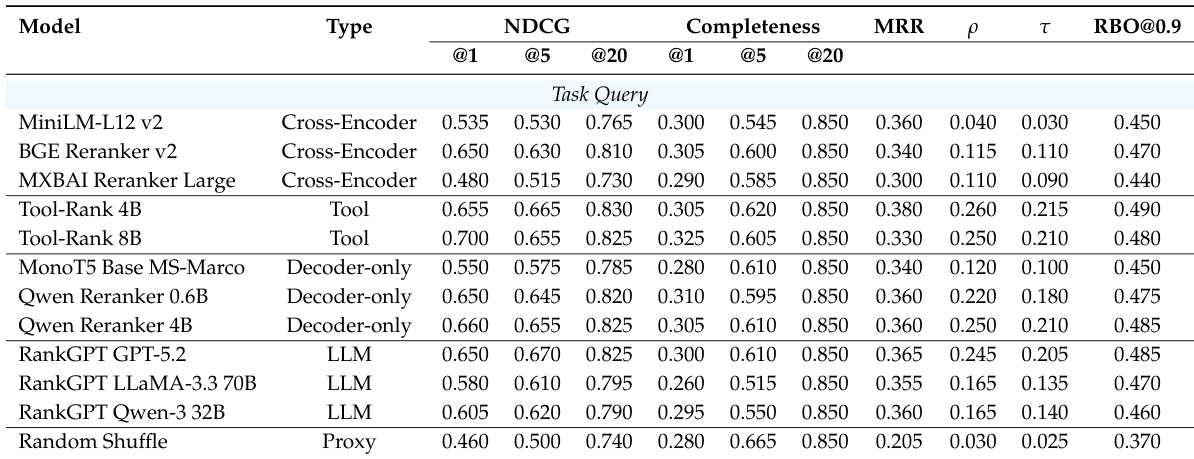
作者在两个基准测试中评估了检索模型,重点关注可执行任务查询与高层级任务描述之间的性能差异。结果显示,工具感知和稠密模型在任务查询上表现良好,而稠密模型在任务描述上更具竞争力,尽管整体完整性仍然较低,这表明在对齐文档与执行有效性方面存在挑战。工具感知和稠密模型在可执行任务查询上优于稀疏方法,而稠密模型在高层级任务描述上变得更具竞争力。从可执行查询转向高层级描述时,性能显著下降,所有方法的完整性均较低。Decoder-only 和基于 LLM 的重排序器在任务描述上表现出更强的性能,表明其能更好地处理隐含需求。
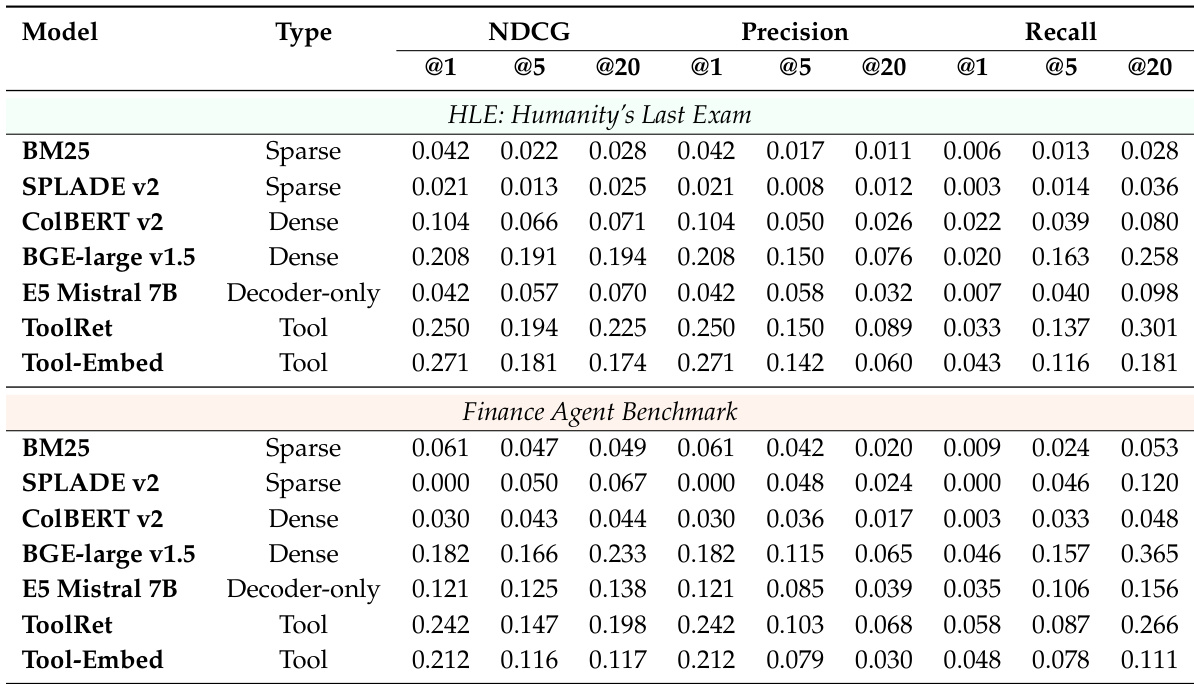
作者利用多样化的 AgentSearchBench,在一系列可执行和高层级任务规范下评估了 agent 搜索基准及检索-重排序方法。虽然工具感知和稠密检索器在处理具体任务查询方面表现出色,但基于 LLM 的重排序器在推断抽象任务描述中的隐含需求方面展现了卓越的能力。尽管这些优势各异,所有方法在完整性方面都面临困难,并显示出 agent 文档与实际执行性能之间持续存在的不匹配。