Command Palette
Search for a command to run...
上下文永远不够长:针对大规模长文档集的结构化推理可扩展问答研究
上下文永远不够长:针对大规模长文档集的结构化推理可扩展问答研究
Harshit Joshi Priyank Shethia Jadelynn Dao Monica S. Lam
摘要
现实世界中的文档问答任务极具挑战性。分析人员必须综合多个文档以及每个文档不同部分中的证据。然而,随着文档集的规模扩大,任何固定的 LLM 上下文窗口(context window)都有可能被超出。一种常见的权宜之计是将文档分解为若干分块(chunks),并从分块层级的输出中汇总答案,但这会引入聚合瓶颈:随着分块数量的增加,系统仍必须对日益庞大的提取证据体进行合并与推理。为此,我们提出了 SLIDERS,这是一个通过结构化推理实现长文档集问答的框架。SLIDERS 将显著信息提取到关系数据库中,从而实现通过 SQL 语言而非拼接文本,对持久化结构化状态进行可扩展的推理。为了使这种局部提取的表示在全局范围内保持一致,SLIDERS 引入了一个数据对账(data reconciliation)阶段,该阶段利用溯源(provenance)、提取依据(extraction rationales)和元数据(metadata)来检测并修复重复、不一致及不完整的记录。在三个现有的长上下文基准测试中,尽管所有测试用例均能容纳在强大的基础 LLM 上下文窗口内(其性能甚至超过了 GPT-4),SLIDERS 的表现依然优于所有基准模型,平均领先 6.6 分。此外,在两个分别为 3.9M 和 36M tokens 的新基准测试中,SLIDERS 分别比次优的基准模型高出约 19 分和 32 分。
一句话总结
斯坦福大学的研究人员提出了 SLIDERS,这是一个针对长文档集合的可扩展问答框架。该框架通过关系数据库进行结构化推理,取代了文本拼接的方式,并利用出处(provenance)、提取理由(extraction rationales)和元数据进行数据对账阶段,以确保全局一致性。最终,该框架在三个长上下文基准测试和两个新基准测试中均优于现有基准。
核心贡献
- 本文引入了 SLIDERS,这是一个针对长文档集合问答的框架,通过将显著信息提取到关系数据库中来实现结构化推理。
- 该工作提出了一个数据对账阶段,利用出处、提取理由和元数据来检测并修复重复、不一致或不完整的记录,以确保全局一致性。
- 实验结果表明,该框架在三个现有的长上下文基准测试中优于所有基准,平均超过 GPT-4.1 6.6 个点,并在两个新基准测试中表现出约 19 和 32 个点的显著提升。
引言
针对大规模文档集合进行有效的问答对于复杂的分析任务至关重要,但由于文档集往往超过大语言模型的固定 context window,这一任务仍然具有挑战性。虽然现有方法尝试通过对文档进行分块并聚合局部输出来解决此问题,但它们面临聚合瓶颈,即提取的证据量最终会使模型不堪重负。本文提出了 SLIDERS,这是一个通过将文档块转换为结构化关系数据库来克服这一限制的框架。通过利用数据对账阶段来解决不一致性,并利用 LLM 生成的 SQL 进行推理,SLIDERS 能够在数百万个 tokens 范围内实现可扩展、可审计且连贯的问答。
数据集
通过使用几个专门设计的基准测试来评估模型,这些基准测试旨在测试长上下文推理、多文档检索和复杂聚合:
-
基准测试组成与来源
- FinanceBench:一个单文档金融问答基准,包含 150 个关于上市公司的问答,证据来源于公开文件。
- Loong:一个多文档基准,涵盖金融(中英文)、法律(中文)和学术研究(英文)。每个实例平均包含约 11 个文档。
- Oolong:一个专注于聚合任务的长上下文推理基准。实验中专门使用了 Oolong-Synth 子集,并在 256K context window 下进行评估。
-
数据处理与元数据构建
- 上下文感知分块:为了确保每个块在进行忠实提取时都是自包含的,保留了原始文本以及结构化元数据。这包括文档标题、文档描述、块索引和完整的标题路径(例如,从 Header 1 到 Header 1.1.3)。
- 信息提取与归一化:使用 SLIDERS 提取结构化信息,随后进行人工验证。数据经过归一化处理,例如转换货币量级(例如,将 $1.23B 转换为 1230 million USD),并通过强制转换为声明的数据类型来确保类型安全。
- 主键管理:为了处理来自 PDF 等非结构化来源的提取错误和重复行,通过识别语义主键来实现。这使得对代表相同现实世界观测值的行进行分组、合并和规范化成为可能。
-
基准测试创建与使用
- 问题生成:问题源自种子查询(如 WikiCeleb100 或 FinQ100),并通过通过时间序列群体或聚合财务属性重新组合提取的信息来扩展。
- 标准答案标注:通过人工对齐提取的表格以创建统一的数据库表示,并为每个问题编写 SQL 查询。对于每个基准测试,专门保留了五个无法仅通过 SQL 解决的问题。
- 评估框架:对于非数值型问题,采用 LLM-as-a-judge 设置,根据理由来评估正确性。对于 Oolong 中的数值聚合,使用一种奖励与标准答案偏差较小的预测值的指标。
方法
SLIDERS 框架通过将非结构化文本转换为连贯的结构化关系数据库来处理长文档集合,从而实现准确且可审计的问答。整体架构由五个顺序任务组成,旨在解决将语言模型扩展到大规模、多文档推理时的关键挑战。
流程始于上下文分块(Contextualized Chunking),将输入的文档集分解为语义和结构连贯的块。每个文档都通过元数据进行增强,包括全局描述和局部结构信号,如章节标题、表格和图表说明。这种丰富的表示确保了块在局部是自包含的并保留了上下文,避免了标题脱离或段落孤立等问题。随后独立处理这些块,为后续提取奠定基础。
分块之后,**模式归纳(Schema Induction)**任务根据问题和文档元数据推导出结构化模式(schema)。该模式指定了要提取的实体、属性和关系,为信息提取过程提供蓝图。模式设计具有严格的类型要求和归一化规则,确保提取的值在所有块中都是标准化的。
系统的核心是**结构化提取(Structured Extraction)**任务,它根据归纳的模式从每个块中提取信息。为了最大限度地减少幻觉,采用了两阶段过程:首先由相关性门控(relevance gate)确定该块是否包含与模式相关的证据,只有在门控通过时才进行提取。这防止了将错误的正例注入数据库。提取模型通过上下文学习(in-context learning)实现,生成 JSON 对象形式的结构化输出,捕捉值、出处和提取理由。提取过程通过逐个处理块并利用块之间的并行性来实现高效扩展。
提取的表格随后进行数据对账(Data Reconciliation),以解决整个文档集中的冲突、冗余和不一致问题。该任务利用了提取数据的关系结构:行按主键进行分组,主键通过分析模式和样本行的 LLM agent 来识别。在每个组内,对账 agent 迭代应用去重、冲突解决、聚合和规范化等操作,并使用出处和理由来指导决策。Agent 生成 SQL 程序来执行这些操作,确保过程保持可审计。对账过程旨在处理同一实体在不同文档中描述不同的情况(例如名称或日期的变化),通过在整合信息之前先通过规范化解决这些差异。
最后,**问答(Question Answering)**任务通过在对账后的数据库上生成并执行 SQL 查询来综合答案。一个 SQL 编码 agent 迭代生成查询、执行它们,并在需要时优化查询,直到产生满意的答案。这种方法确保答案是从全局连贯且一致的数据库中获取的,而不是直接从可能出错的非结构化文本中生成。
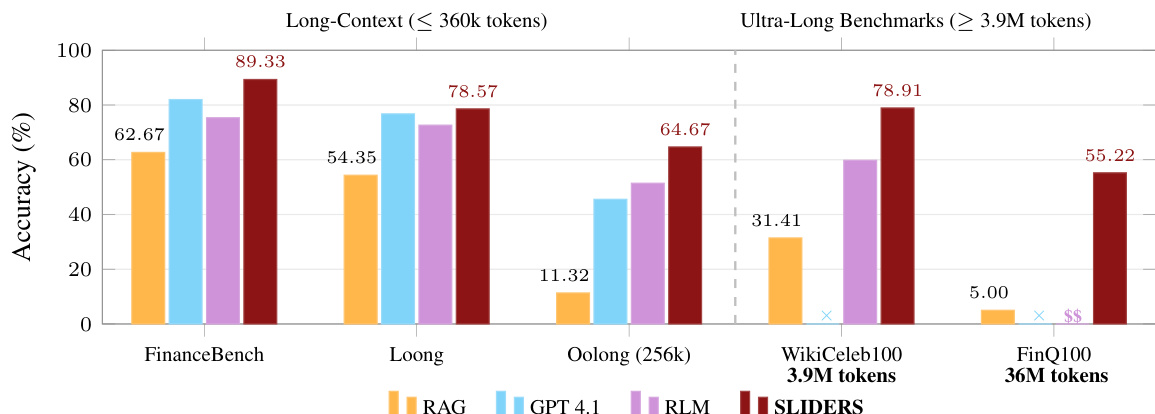
实验
SLIDERS 在上下文受限和超长文档基准测试中,针对包括 GPT-4.1 等前沿模型及各种基于 RAG 的方法进行了评估。实验表明,SLIDERS 通过利用结构化推理和数据对账来克服聚合瓶颈,显著优于现有方法。最终,该框架证明了高度的可扩展性和成本效益,即使在输入规模达到数千万个 tokens 时也能保持高准确率。
在长上下文和超长基准测试上对用于长文档集合结构化推理的框架 SLIDERS 进行了评估。结果显示,SLIDERS 在所有基准测试中均优于包括检索增强生成和递归语言模型在内的各种基准,即使在输入符合前沿模型 context window 的情况下也表现出持续的增益。该框架在超长文档集上实现了高准确率,超过了其他方法的性能,并随着文档规模的增加保持了可扩展性。SLIDERS 在长上下文和超长基准测试中优于所有基准,达到了比 GPT-4.1 和其他方法更高的准确率。即使输入超过了前沿模型的上下文限制,SLIDERS 在超长文档集上仍保持高准确率。该框架的结构化推理方法实现了跨大规模文档集合的、可扩展且可靠的证据聚合。
在长文档问答任务上,将 SLIDERS 与包括 RLM 和基于 GPT 的模型在内的多个基准进行了对比。结果显示,SLIDERS 在两个基准测试中均优于所有基准,准确率有显著提升,特别是在需要跨大上下文进行聚合的场景中。该框架的结构化推理方法即使在输入规模增加时也能保持一致的性能,展示了超越单个模型上下文限制的可扩展性。SLIDERS 在两个基准测试上的准确率均高于所有评估的基准,证明了在长文档问答方面的卓越性能。该框架在不断增加的输入规模下保持了一致的性能,展示了超越单个语言模型上下文限制的可扩展性。在聚合密集型任务中,SLIDERS 以大幅领先的优势超过了基准,突显了结构化推理相对于自由格式生成的有效性。

在大小和复杂度各异的多个基准测试上评估了用于长文档集合结构化推理的框架 SLIDERS。该框架优于多个基准,包括检索增强生成和 chain-of-agents 方法,特别是在需要跨文档聚合的任务上,并展示了在使用开源语言模型时的鲁棒性。SLIDERS 在超长文档集上保持了一致的性能,尽管输入规模超过了前沿模型的上下文限制,仍实现了高准确率。SLIDERS 在长文档问答任务上优于多个基准,尤其是那些需要跨文档聚合的任务。该框架在超长文档集上实现了高准确率,即使输入超过了前沿模型的 context window。SLIDERS 在使用开源语言模型时保持了强劲的性能,表明其优势源于结构化推理框架,而非依赖于专有模型。
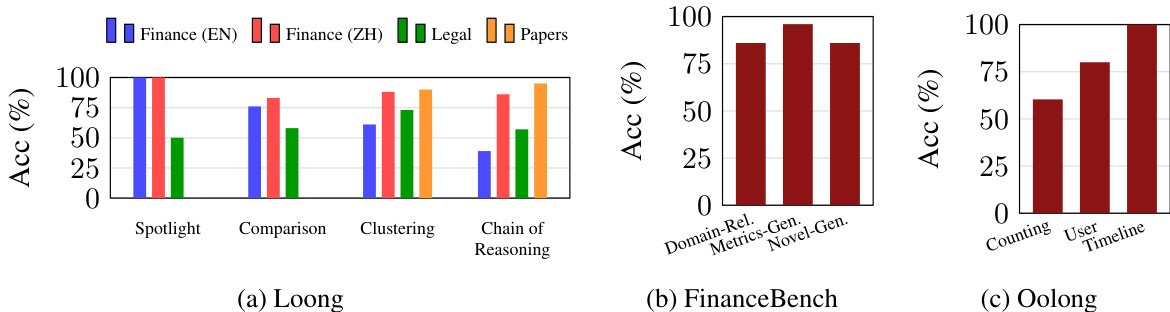
实验通过多个问答基准测试评估了 SLIDERS 的性能,并将其与各种基准进行了比较。结果显示,SLIDERS 在长文档任务上始终优于所有基准,即使输入符合前沿模型的 context window,在聚合密集型问题上也观察到了准确率的显著提升。该框架在不同问题类型和领域中表现出鲁棒性,在金融和传记数据集上取得了显著改进。SLIDERS 在超过模型上下文限制的超长文档集上也保持了高准确率,突显了其处理大规模多文档推理的可扩展性和有效性。SLIDERS 在长文档问答任务上优于所有基准,即使在输入符合大语言模型 context window 的情况下也达到了更高的准确率。该框架在多种问题类型上表现出强劲性能,在领域相关、新颖和时间线问题上准确率尤为突出。SLIDERS 在超过模型上下文限制的超长文档集上保持了高准确率,证明了其在大规模多文档推理中的可扩展性和有效性。
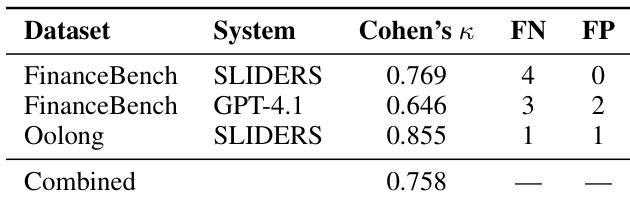
通过在多个基准测试上将其性能与多个基准进行对比,评估了用于长文档结构化推理的框架 SLIDERS。结果显示,SLIDERS 在所有基准测试中均优于所有基准,即使在输入符合前沿模型 context window 的情况下也实现了更高的准确率,并在超过当前模型限制的超长文档集上展示了鲁棒的性能。SLIDERS 在所有基准测试中均优于所有基准,包括那些输入符合前沿模型 context window 的测试。SLIDERS 在超过当前模型上下文限制的超长文档集上实现了高准确率,证明了其可扩展性。该框架的结构化推理方法实现了大规模文档集合中证据的有效聚合与对账。
通过在各种长上下文和超长文档基准测试上评估 SLIDERS 框架,验证了其执行结构化推理和证据聚合的能力。结果表明,SLIDERS 始终优于检索增强生成、递归模型以及 GPT-4 等前沿模型,特别是在需要复杂信息综合的任务上。该框架被证明具有高度的可扩展性和鲁棒性,即使在文档规模超过单个语言模型的上下文限制或使用开源模型时,也能保持高准确率。